
热门标签
热门文章
- 1【wsl2】常用命令及ext4硬盘扩展与压缩_wsl 硬盘扩容
- 22023最好用的mac苹果电脑清理软件_clear mac disk
- 3《Android3D游戏开发技术详解与典型案例》笔记1_android游戏3d推箱子开发框架
- 4Python:request爬虫爬取网站数据时urlopen出现403原因及解决办法_python urlopen 403
- 5【Java书笔记】:《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》第2部分-自动内存管理,第3部分-虚拟机执行子系统,第5部分-高效并发_java本机序列化允许由有效负载利用易受攻击的库和类执行未经验证的字节码引起的远
- 6Angular 装饰器 HostListener 监听DOM事件 使用指南_@hostlistener('window:
- 7双电池串联使用,硬件设计_vbat_sense
- 8如何彻底清除Android Studio_android studio清理
- 9Mac必备软件13款,强烈推荐_类似cleanmymac
- 10[转]Android系统文件夹结构解析(五)--/system/lib_library "/system/lib/libhi_tv_jni.so" ("/system/li
当前位置: article > 正文
微软语音合成(tts)服务申请和调用_微软官网申请接口key和region
作者:菜鸟追梦旅行 | 2024-03-21 04:13:56
赞
踩
微软官网申请接口key和region
1、申请账户:
https://azure.microsoft.com/zh-cn/free/
这里有个视频教程,根据此完成申请流程:
https://www.bilibili.com/video/BV15a4y1W7re?vd_source=bf07f28d37849885d215dc3aea189eba
申请完成后,就可以到这里申请资源:
https://portal.azure.com/#home
点击资源组,里面就有部署好的服务了
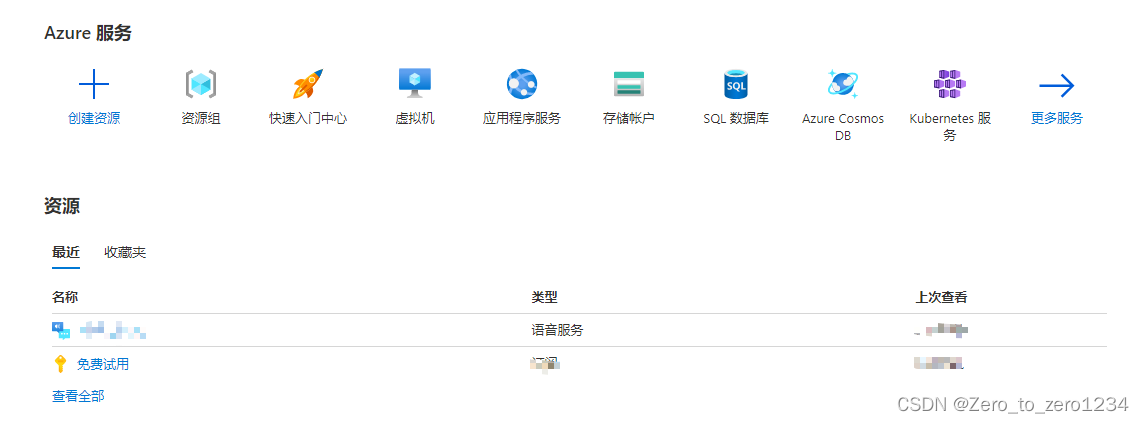

点击这里,可以获取 subscription_key,另外还有个就是位置service_region (上图就是east asia),这两个后面会用到。
2、调用服务
在完成微软azure服务账号申请后,就可以进行调用了。代码:
'''
After you've set your subscription key, run this application from your working
directory with this command: python TTSSample.py
'''
import os, requests, time
from xml.etree import ElementTree
# This code is required for Python 2.7
try: input = raw_input
except NameError: pass
'''
If you prefer, you can hardcode your subscription key as a string and remove
the provided conditional statement. However, we do recommend using environment
variables to secure your subscription keys. The environment variable is
set to SPEECH_SERVICE_KEY in our sample.
For example:
subscription_key = "Your-Key-Goes-Here"
'''
if 'SPEECH_SERVICE_KEY' in os.environ:
subscription_key = os.environ['SPEECH_SERVICE_KEY']
else:
print('Environment variable for your subscription key is not set.')
exit()
class TextToSpeech(object):
def __init__(self, subscription_key):
self.subscription_key = subscription_key
self.tts = input("What would you like to convert to speech: ")
self.timestr = time.strftime("%Y%m%d-%H%M")
self.access_token = None
'''
The TTS endpoint requires an access token. This method exchanges your
subscription key for an access token that is valid for ten minutes.
'''
def get_token(self):
fetch_token_url = "https://westus.api.cognitive.microsoft.com/sts/v1.0/issueToken"
headers = {
'Ocp-Apim-Subscription-Key': self.subscription_key
}
response = requests.post(fetch_token_url, headers=headers)
self.access_token = str(response.text)
def save_audio(self):
base_url = 'https://westus.tts.speech.microsoft.com/'
path = 'cognitiveservices/v1'
constructed_url = base_url + path
headers = {
'Authorization': 'Bearer ' + self.access_token,
'Content-Type': 'application/ssml+xml',
'X-Microsoft-OutputFormat': 'riff-24khz-16bit-mono-pcm',
'User-Agent': 'YOUR_RESOURCE_NAME'
}
xml_body = ElementTree.Element('speak', version='1.0')
xml_body.set('{http://www.w3.org/XML/1998/namespace}lang', 'en-us')
voice = ElementTree.SubElement(xml_body, 'voice')
voice.set('{http://www.w3.org/XML/1998/namespace}lang', 'en-US')
voice.set('name', 'en-US-Guy24kRUS') # Short name for 'Microsoft Server Speech Text to Speech Voice (en-US, Guy24KRUS)'
voice.text = self.tts
body = ElementTree.tostring(xml_body)
response = requests.post(constructed_url, headers=headers, data=body)
'''
If a success response is returned, then the binary audio is written
to file in your working directory. It is prefaced by sample and
includes the date.
'''
if response.status_code == 200:
with open('sample-' + self.timestr + '.wav', 'wb') as audio:
audio.write(response.content)
print("\nStatus code: " + str(response.status_code) + "\nYour TTS is ready for playback.\n")
else:
print("\nStatus code: " + str(response.status_code) + "\nSomething went wrong. Check your subscription key and headers.\n")
print("Reason: " + str(response.reason) + "\n")
def get_voices_list(self):
base_url = 'https://westus.tts.speech.microsoft.com/'
path = 'cognitiveservices/voices/list'
constructed_url = base_url + path
headers = {
'Authorization': 'Bearer ' + self.access_token,
}
response = requests.get(constructed_url, headers=headers)
if response.status_code == 200:
print("\nAvailable voices: \n" + response.text)
else:
print("\nStatus code: " + str(response.status_code) + "\nSomething went wrong. Check your subscription key and headers.\n")
if __name__ == "__main__":
app = TextToSpeech(subscription_key)
app.get_token()
app.save_audio()
# Get a list of voices https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/rest-text-to-speech#get-a-list-of-voices
# app.get_voices_list()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
参考文档:
https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/
https://github.com/Azure-Samples/Cognitive-Speech-TTS/blob/28681c8292c95aebb36d3696b8822b4cd17c3c45/Samples-Http/OLD/Python/TTSSample.py
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/278347
推荐阅读
相关标签

