
- 1【MySQL新手入门系列五】:MySQL的高级特性简介及MySQL的安全简介_mysql除了关安全模式还要干嘛
- 2OpenCV 验证码图像增强处理 一、滤波增强_opencv 边缘增强
- 3Vue3全家桶 - Vue3 - 【2】声明响应式数据(ref + reactive + toRef + toRefs)
- 4微信开发中两种access_token的区别和不同用处总结_如何将测试正式的微信access_token 区分开
- 5Android 插件化开发(五)—— Replugin内部插件开发
- 6将.Net Framework 程序升级到.NetCore_.net framework升级.net core
- 7Linux centos7安装postgresql12_linux postgres 12 客戶端下载
- 8Python实现学生信息管理系统_利用python语言中的组合数据类型对学号和姓名进行存储,并实现利用学号访问姓名和
- 9homebrew安装及使用nginx_brew install nginx
- 10ASO专家绝不会分享的高级应用商店优化秘密!(2)
RAG一文读懂!概念、场景、优势、对比微调与项目代码示例_rag开源引擎
赞
踩
本文结合“基于 ERNIE SDK+LangChain 搭建个人知识库”的代码示例,为您讲解 RAG 的相关概念。
01 概念
在2020年 Facebook AI Research(FAIR)团队发表一篇名为《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》的论文。这篇论文首次提出了 RAG 概念(目前大语言模型领域的一个重要概念),并对该概念进行详细介绍和解释。
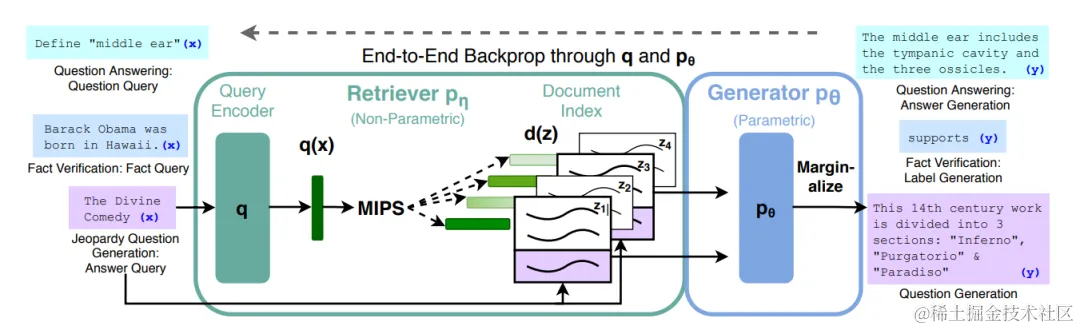
此图是 FAIR 团队的方法概述。结合了一个预先训练的检索器(查询编码器+文档 Index),并进行端到端微调。对于查询 x,作者使用最大内积搜索(MIPS)查找前 K 个文档 zi 对于最终预测 y,并将 z 视为一个潜在变量,并在给定不同文献的 seq2seq 预测上进行边缘化。
RAG 模型结合了语言模型和信息检索技术。具体来说,当模型需要生成文本或者回答问题时,它会先从一个庞大的文档集合中检索出相关的信息,然后利用这些检索到的信息来指导文本的生成,从而提高预测的质量和准确性。
其中,“检索”、“利用”、“生成”是 RAG 的关键部分。那如何才能更直观地理解这三个部分呢?
举个简单的例子:
你正在写一篇关于小狗的文章,但你对小狗的知识有限。这时,你很可能会进行以下操作:
1.检索(Retrieval):首先,你打开电脑,输入关键词为“小狗”的搜索请求,在互联网上检索了大量的关于小狗的文章、博客和信息。
2.利用(Utilization):接下来,你会分析这些搜索结果,并提取其中的重要信息,包括狗狗的种类、行为习惯、饲养方式等等。你将这些信息整理成一个知识库,这个知识库就像一本百科全书,里面包含了各种关于小狗的知识点。
3.生成(Generation):现在,你需要写文章。在文章的开头,通过一个问题引入:“小狗的寿命有多长?”随后,便可以使用之前检索和整理的信息来回答问题,或者生成文章的段落。这一步不仅仅是简单地复制粘贴,而是根据上下文和语法规则生成自然流畅的文本。
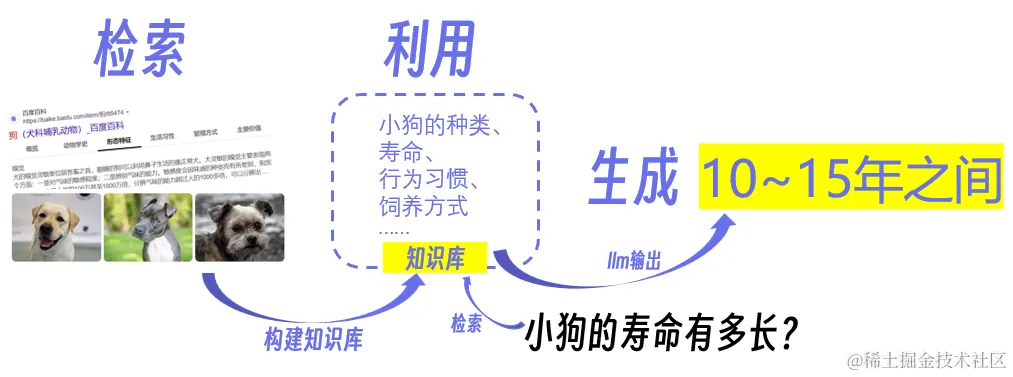
其实上述“你”的工作流就是“RAG”的工作流,可以将“你”当作一个 RAG 模型,即“检索”、“利用”、“生成”。
了解了 RAG 的基本工作流之后,可能会思考:RAG 主要在什么场景下使用呢?
如果它们在这些场景中进行“检索”,“利用”和“生成”,具体的工作内容又是什么呢?
02 场景
RAG 技术可以在以下一些常见的自然语言处理任务中发挥作用:
1.问答系统(QA Systems):RAG 可以用于构建强大的问答系统,能够回答用户提出的各种问题。它能够通过检索大规模文档集合来提供准确的答案,无需针对每个问题进行特定训练。
2.文档生成和自动摘要(Document Generation and Automatic Summarization):RAG 可用于自动生成文章段落、文档或自动摘要,基于检索的知识来填充文本,使得生成的内容更具信息价值。
3.智能助手和虚拟代理(Intelligent Assistants and Virtual Agents):RAG 可以用于构建智能助手或虚拟代理,结合聊天记录回答用户的问题、提供信息和执行任务,无需进行特定任务微调。
4.信息检索(Information Retrieval):RAG 可以改进信息检索系统,使其更准确深刻。用户可以提出更具体的查询,不再局限于关键词匹配。
5.知识图谱填充(Knowledge Graph Population):RAG 可以用于填充知识图谱中的实体关系,通过检索文档来识别和添加新的知识点。
03 优势
以上是 RAG 一些常见的应用场景。明晰了 RAG 的应用范围后,可能会产生疑问:为什么这些场景需要使用 RAG,而不是进行微调或者通过其他方法来实现呢?
接下来,我们进一步了解 RAG 的优势。
以下为 RAG 的具体优势:
1.外部知识的利用:RAG 模型可以有效地利用外部知识库,它可以引用大量的信息,以提供更深入、准确且有价值的答案,这提高了生成文本的可靠性。
2.数据更新及时性:RAG 模型具备检索库的更新机制,可以实现知识的即时更新,无需重新训练模型。说明 RAG 模型可以提供与最新信息相关的回答,高度适配要求及时性的应用。
3.回复具有解释性:由于 RAG 模型的答案直接来自检索库,它的回复具有很强的可解释性,减少大模型的幻觉。用户可以核实答案的准确性,从信息来源中获取支持。
4.高度定制能力:RAG 模型可以根据特定领域的知识库和 prompt 进行定制,使其快速具备该领域的能力。说明 RAG 模型广泛适用于的领域和应用,比如虚拟伴侣、虚拟宠物等应用。
5.安全和隐私管理:RAG 模型可以通过限制知识库的权限来实现安全控制,确保敏感信息不被泄露,提高了数据安全性。
6.减少训练成本:RAG 模型在数据上具有很强的可拓展性,可以将大量数据直接更新到知识库,以实现模型的知识更新。这一过程的实现不需要重新训练模型,更经济实惠。
04 对比微调
接下来,通过对比 RAG 与微调,帮助大家根据具体的业务需求,选择合适的策略:
-
任务特定 vs 通用性:微调通常是为特定任务进行优化,而RAG是通用的,可以用于多种任务。微调对于特定任务的完成效果好,但在通用性问题上不够灵活。
-
知识引用 vs 学习:RAG 模型通过引用知识库来生成答案,而微调是通过学习任务特定的数据生成答案。RAG 的答案直接来自外部知识,更容易核实。
-
即时性 vs 训练:RAG 模型可以实现即时的知识更新,无需重新训练,在及时性要求高的应用中占优势。微调通常需要重新训练模型,时间成本较高。
-
可解释性 vs 难以解释性:RAG 的答案可解释性强,因为它们来自知识库。微调模型的内部学习可能难以解释。
-
定制 vs 通用性:RAG 可以根据特定领域进行定制,而微调需要为每个任务进行特定微调,需要更多任务特定的数据。
结合上面的比较,我们可以清楚的看到 RAG 的优势在于通用性、知识引用、即时性和可解释性,而微调在特定任务上可能更适用,但同时需要更多的任务特定数据和训练。选择使用哪种方法,应根据具体的应用需求和任务来决定。
05 项目示例
那 RAG 具体怎么实现呢?
我们用一个简单的代码示例来举例:基于 ERNIE SDK 和 LangChain 搭建个人知识库。
▎安装ERNIE Bot
!pip install --upgrade erniebot
测试embedding
import erniebot
erniebot.api_type = "aistudio"
erniebot.access_token = "<你的token>"
response = erniebot.Embedding.create(
model="ernie-text-embedding",
input=[
"我是百度公司开发的人工智能语言模型,我的中文名是文心一言,英文名是ERNIE-Bot,可以协助您完成范围广泛的任务并提供有关各种主题的信息,比如回答问题,提供定义和解释及建议。如果您有任何问题,请随时向我提问。" ])
print(response.get_result())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
▎引入 Chromadb 向量数据库
!pip install chromadb
- 1
▎自定义嵌入函数
定义一个自定义的嵌入函数,用于将文本内容转换为嵌入向量。其中使用 ERNIE Bot 库来创建文本的嵌入,并且通过 Chromadb 库来管理这些嵌入向量。
import os import erniebot from typing import Dict, List, Optional import chromadb from chromadb.api.types import Documents, EmbeddingFunction, Embeddings def embed_query(content): response = erniebot.embedding.create( model="ernie-text-embedding", input=[content]) result = response.get_result() print(result) return result class ErnieEmbeddingFunction(EmbeddingFunction): def __call__(self, input: Documents) -> Embeddings: embeddings = [] for text in input: response = embed_query(text) try: embedding = response[0] embeddings.append(embedding) except (IndexError, TypeError, KeyError) as e: print(f"Error processing text: {text}, Error: {e}") return embeddings chroma_client = chromadb.Client() chroma_client = chromadb.PersistentClient(path="chromac") #数据保存硬盘位置 可选 collection = chroma_client.create_collection(name="demo", embedding_function=ErnieEmbeddingFunction()) print(collection)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
▎导入数据集
选用课程内容作为知识库:
https://aistudio.baidu.com/datasetdetail/260836
▎文档切割
使用 LangChain 库来处理和分割文本文档
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
loader = TextLoader('./AI大课逐字稿.txt',encoding='utf-8')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=600, chunk_overlap=20)
docs = text_splitter.split_documents(documents)
docs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
▎Embedding 嵌入
将分割后的文档列表转换为嵌入向量,以便进行进一步的分析和处理。
import uuid
docs_list=[]
metadatas=[]
ids=[]
for item in docs:
docs_list.append(item.page_content)
metadatas.append({"source": "AI大课逐字稿"})
ids.append(str(uuid.uuid4()))
collection.add(
documents=docs_list,
metadatas=metadatas,
ids=ids
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
▎检索
query = "讲师说见VC有两种错误的思维方式,分别是什么" results = collection.query( query_texts=[query], n_results=2 ) content=results['documents'][0] [ ] prompt=f""" 用户问题:{query} <context> {content} </context> 根据<context>里的知识点回答用户问题 """ response = erniebot.ChatCompletion.create(model="ernie-4.0", messages=[{"role": "user", "content": prompt}]) print(response.get_result()) #讲师说见VC有两种错误的思维方式,分别是: ##1. 用过去的方式套今天的人工智能,比如比喻成OS。一旦比喻成操作系统,就得出结论全世界两套到三套,你觉得必然会被垄断、没有机会了,这种是典型的刻舟求剑。 #2. 人容易对已经成功的事委曲求全,对于创新的新生代创业者容易求全责备。特别是有些做VC容易犯这个错误,比如OpenAI做成了,已经证明了,是个傻子都能看到OpenAI做的很成功,我们容易对它顶礼膜拜,恨不得跪下。对创业者很多还不成形的想法,因为八字没有一撇,光看到了你的很多缺点,这种价值观是不对的,容易Miss掉一些有潜力的项目。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
▎封装函数
包含了之前步骤中存储的文本嵌入向量。函数的目的是接收用户的查询,从数据库中检索相关信息,并生成一个回答。
def main(query): results = collection.query( query_texts=[query], n_results=2 ) content=results['documents'][0] prompt=f""" 用户问题:{query} <context> {content} </context> 根据<context>里的知识点回答用户问题 """ response = erniebot.ChatCompletion.create(model="ernie-4.0", messages=[{"role": "user", "content": prompt}]) return response.get_result() query=input("请输入您要查询的问题:") print(main(query))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
代码地址:
https://aistudio.baidu.com/projectdetail/7431640
显然,RAG 的应用不仅仅满足于此,目前也诞生了各种 RAG 的高阶用法。
通过不断优化 RAG,使其具有更强大的信息理解能力,理解问题更加透彻,找到与问题高度匹配的信息后,生成更为精准的答案。比如针对“讲一下金毛犬的特点”这一指令,高级 RAG 模型可以理解这是一个关于小狗特定品种的问题,将从知识库中提取金毛犬的细节信息,如体格、性格、历史等,以对齐问题的颗粒度,提供详细的回答。
在优化 RAG 的过程中,也产生了一系列相关的方法。
在信息检索和搜索引擎优化领域,通过实施一系列策略可以显著提升检索系统的性能。索引优化通过提升数据粒度、优化索引结构、添加元数据信息、对齐优化和混合检索等方法,可以提高检索的准确性和效率。向量表征模型的优化通过微调和动态嵌入技术,增强了模型对特定领域或问题的理解能力。检索后处理策略如重排序和 Prompt 压缩,进一步提升了检索结果的相关性和用户满意度。递归检索和搜索引擎优化通过递归检索和子查询等技术,实现了更复杂和精确的检索需求。最后,RAG 评估通过独立评估和端到端评估方法,确保了检索系统在各个方面都能满足用户的需求。这些策略的实施,共同推动了检索技术的进步,为用户提供了更加高效和精准的信息服务。
具体参考下图:
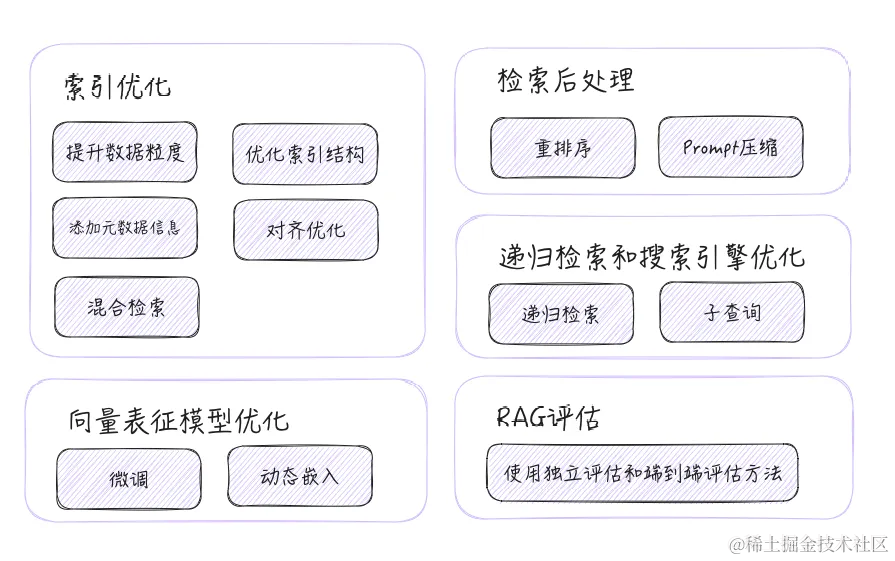
除了以上5种方法,还有其他很多高级的 RAG 用法,大家可以针对感兴趣的部分自行查阅相关论文,进行学习了解。
——————END——————
推荐阅读
教不会你算我输系列 | 手把手教你HarmonyOS应用开发
云上业务一键性能调优,应用程序性能诊断工具 Btune 上线

