
- 1如何在Linux CentOS部署宝塔面板并实现固定公网地址访问内网宝塔_centos 7 安装宝塔
- 2NLP学习之bigrams函数"generator object bigrams at 0x000001D32A95A678"问题解决
- 3基于阿里云的快照介绍_阿里云 创建极速快照
- 4AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.10-2024.03.15_大语言模型 机器翻译 论文
- 5TTS合成技术中的语音合成和人工智能和自然语言生成_语音合成 tts 应用
- 6[emerg] the “ssl“ parameter requires ngx_http_ssl_module in /usr/local/nginx/conf/nginx.conf:35_nginx: [emerg] the "ssl" parameter requires ngx_ht
- 7时序数据库:TDengine整体架构
- 8云服务器8核32G配置报价大全,腾讯云、阿里云和京东云
- 9GeoTrust SSL证书有什么优势?
- 10软件架构的风格与分类_云架构属于虚拟机风格 仓库风格
天猫用户重复购买预测(速通一)_天猫复购预测-挑战baseline用户信息表、用户行为表、用户购买数据表查看整体数据
赞
踩
赛题理解
1、评估指标



2、赛题分析
本赛题要求预测新用户在6个月内再次从同一店铺购买商品的概率,是一个连续值,不过因为购买商品只有购买和不购买两种结果,而且评测指标是典型的二分类评测指标AUC,所以这是一个二分类问题。
常见的分类模型:


对于本赛题,一个初步的思路是其数据量不大,一般用不到深度学习。根据赛题特点,集成算法,尤其是XGBoost, LightGBM, CatBoost 等算法的效果会比较好。
最后为了让模型的效果更好,提升预测精确度,还可以加上模型融合,这是竞赛中常用的技巧。不过在实际工业项目场景中,需要综合考虑模型预测时间、模型效果以及工程环境的时间和并发等方面的要求。
解题思路:

理论知识
1.缺失值处理
拿到数据的第一步当然是对数据进行查看,判断其是否存在缺失数据,以及字段缺失数据的占比大概是多少。
我们可以使用Pandas 中count()函数及shape()函数进行统计: count()函 数可以统计不为空
数据的个数: shape()函 数则可以统计数据样本的个数;将shape()函数与count()函数做差就可
以得到数据的缺失个数,再用缺失的个数除以样本的个数来计算样本中此字段的缺失率。
在统计查看完数据的缺失值及缺失率之后,我们需要根据不同情况对相应的缺失数据进行处理,Pandas 包中包含了一些处理缺失值的函数。

数据中可能存在隐藏缺失值的情况,这时就要理解数据集内容的含义,比如在某些情况下,0代表缺失值。
对于数据缺失特别严重的数据,我们一般将其删除处理,一方面由于数据缺失过大所蕴含的信息较少;另一方面,缺失率过大的数据可导致用户在建模中产生偏差,而这在后续查找中比较难以追溯,不过这些都需要根据数据和实际的业务场景来定。
针对缺失值较少的情况,一般采用下面几种处理方法,如下表所示:

对一些常用的缺失值填充方法进行补充汇总:

2.不均衡样本
在分类任务中,不同类别的训练样例数目常存在差异很大的情况,这时样本不均衡往往会出现模型对样本数较多的类别过拟合、对较少的类别欠拟合的现象,即总是将样本分到样本数较多的分类类别中。
对过多的样本进行欠采样或者对过少的样本进行过采样,常用的采样方法有以下几种:
随机欠采样
例如,数据中有正样本50例,负样本950例,正样本的占比为5%。随机欠采样就是在负样本中随机选出10%,为95例,与正样本组成新的训练集(95+50)。 这样,正样本所占的比例为50/145-35%,比原来的5%有了很大增加。随机欠采样的优点是在平衡数据的同时减小了数据量,加速了训练;缺点是数据减少会影响模型的特征学习能力和泛化能力。
随机过采样
例如,数据中有正样本50例,负样本950例,正样本的占比为5%。随机过采样就是将正样本复制10次,为500例,与负样本组成新的训练集(500+950)。这样,正样本所占的比例为500/1450-35%。随机过采样的优点是相对于欠采样,其没有导致数据信息的损失;缺点是对较少类别的复制增加了过拟合的可能性。
说明:采用上面简单的方法通常可以解决绝大多数样本分布不均衡的问题。
基于聚类的过采样方法
图2-2-1举例说明了这种方法的实现。基于聚类的过采样方法通过聚类作为中介,不但在一定程度 上缓解了类间的样本不平衡问题,同时还缓解了类内的不平衡问题。但是和一般的过采样方法一样,该方法容易使模型对训练数据过拟合。
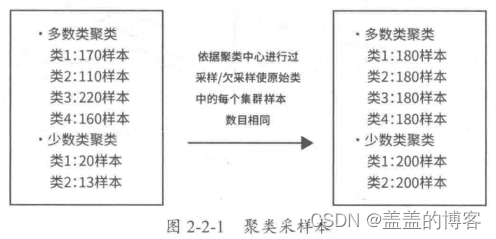
SMOTE算法
SMOTE ( Synthetic Minority Oversampling Technique,合成少数类过采样技术)是基于随
机过采样的一.种改进方法。由于随机复制少数样本来增加样本训练的模型缺少泛化能力,因
此SMOTE算法采用对少数样本进行人工合成的方式将新样本加入训练集中,从而使模型训
练更具有泛化能力,如图2-2-2所示。SMOTE算法的主要步骤如下:

其优点是通过人造相似样本取代直接复制的方法减弱了过拟合,也没有丢失有用的信息;缺点是在进行,人工合成样本时,由于没有考虑到近邻样本可能来自不同类别,因此导致增大类别间的重叠。
基于数据清洗的SMOTE


3.常见的数据分布

数据探索
(导包 – 读取数据 – 数据集样例查看 – 查看数据类型和数据大小 – 查看缺失值 – 观察数据分布 )
探查影响复购的各种因素
1.对店铺分析
用户复购可能受到店铺、用户、用户性别、用户年龄等因素的影响。
(1)分析不同店铺与复购的关系,并可视化显示:
print('选取top5店铺\n店铺\t购买次数')
print(train_data.merchant_id.value_counts().head(5))
#取出top5的商店 进行复购次数统计
#首先复制数据
train_data_merchant = train_data.copy()
#增加一列名为top5,如果是top5标为1,否则标为0
train_data_merchant['TOP5'] = train_data_merchant['merchant_id'].map(lambda x: 1 if x in[4044,3828,4173,1102,4976] else 0)
train_data_merchant
#通过top5这列的标记取出数据
train_data_merchant = train_data_merchant[train_data_merchant['TOP5'] == 1]
#可视化top5
plt.figure(figsize=(8,6))
plt.title('merchant VS label')
ax = sns.countplot('merchant_id',hue = 'label',data = train_data_merchant)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

可以看出,不同店铺有不同的复购率,可能与店铺售卖的商品及运营有关。
(2)查看店铺的复购分布
merchant_repeat_buy = [rate for rate in train_data.groupby(['merchant_id'])['label'].mean() if rate <= 1 and rate > 0]
plt.figure(figsize = (8,4))
ax = plt.subplot(1,2,1)
sns.distplot(merchant_repeat_buy, fit = stats.norm)
ax = plt.subplot(1,2,2)
res = stats.probplot(merchant_repeat_buy,plot = plt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

可以看出,不同店铺有不同的复购概率,为0~0.3。
2.对用户分析
#查看用户复购概率分布
user_repeat_buy = [rate for rate in train_data.groupby(['user_id'])['label'].mean() if rate <= 1 and rate > 0]
plt.figure(figsize = (8,4))
ax = plt.subplot(1,2,1)
sns.distplot(user_repeat_buy, fit = stats.norm)
ax = plt.subplot(1,2,2)
res = stats.probplot(user_repeat_buy,plot = plt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

可以看出,近6个月用户的复购概率很小,基本以买一次为主。
3.对用户性别的分析
(1)分析用户性别与复购的关系,并可视化显示。
#查看性别与复购的关系
train_data_user_info = train_data.merge(user_info,on = ['user_id'],how = 'left')
plt.figure(figsize=(8,8))
plt.title('gender VS label')
ax = sns.countplot('gender',hue = 'label',data = train_data_user_info)
for p in ax.patches:
height = p.get_height()
- 1
- 2
- 3
- 4
- 5
- 6
- 7

(2)查看用户性别复购的分布。
#可视化
repeat_buy = [rate for rate in train_data_user_info.groupby(['gender'])['label'].mean()]
plt.figure(figsize = (8,4))
ax = plt.subplot(1,2,1)
sns.distplot(repeat_buy, fit = stats.norm)
ax = plt.subplot(1,2,2)
res = stats.probplot(repeat_buy,plot = plt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

可以看出,男女的复购概率不同。
4.对用户年龄的分析
(1)分析用户年龄与复购的关系,并可视化显示。
#年龄与复购的关系
plt.figure(figsize = (8,8))
plt.title('age VS label')
ax = sns.countplot('age_range',hue = 'label',data = train_data_user_info)
- 1
- 2
- 3
- 4

(2)查看用户年龄复购的分布。
#可视化
repeat_buy = [rate for rate in train_data_user_info.groupby(['age_range'])['label'].mean()]
plt.figure(figsize = (8,4))
ax = plt.subplot(1,2,1)
sns.distplot(repeat_buy, fit = stats.norm)
ax = plt.subplot(1,2,2)
res = stats.probplot(repeat_buy,plot = plt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
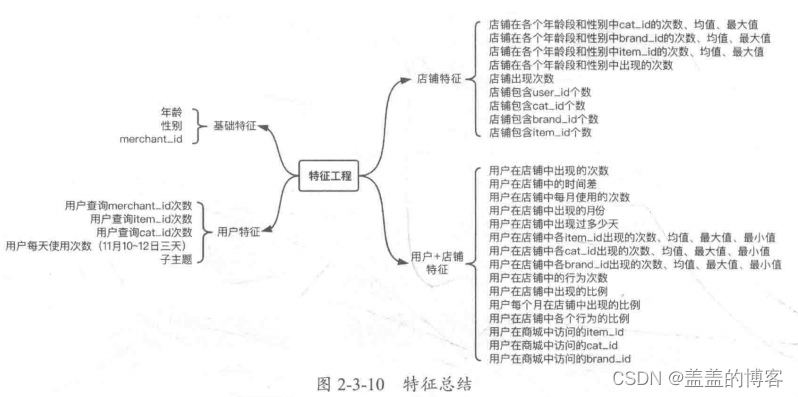
特征工程

1、特征工程介绍
特征归一化
通过梯度下降求解的模型,归一化会对收敛速度产生影响,因此在通常情况下都需要归化。
这些模型包括线性回归、逻辑回归、支持向量机、神经网络等,但对于决策树模型一般不需要进行归一化处理。
类别型特征的转换

高维组合特征的处理

当引入ID类型的特征时,通常需要降维。
可以发现,当用户uid 有10000 个,商品item 有10000 个时,其组合特征维度为
10000*10000=100000000维,由于这个维度异常高,因此必须通过其他办法把特征维度及拟合的参数维度降下来。我们可以采用SVD ( Sigular Value Decormposition, 奇异值分解)类隐向量方法,其在降低参数的同时,还可以增加参数的迭代拟合数量,有效防止过拟合。
特征组合

#特征组合进行业务特征提取
# 点击次数
all_data_test = user_col_cnt(all_data_test, ['seller_path', 'item_path'], '0', 'user_cnt_0')
# 不同店铺个数
all_data_test = user_col_nunique(all_data_test, ['seller_path', 'item_path'], '0', 'seller_nunique_0')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
文本表示模型
1、词袋模型

2、N-gram模型
N-gram模型是一种语言模型,对于由N个词组成的语句片段,我们假设第N个词的出现与否只与前N-1个词相关,整个语句出现的概率就是这N个词概率的乘积。
3、主题模型
词袋模型和N-gram模型都无法识别两个不同的词或词组是否具有相同的主题,而主题模型可以将具有相同主题的词或词组映射到同一维度上,映射到的这一维度表示某 个主题。
4、词嵌入
词嵌入是一类将词向量化的模型的统称,核心思想是将每个词都映射到低维空间(K为50~300)上的一个稠密向量。
2、工程思路
特征主要基于基础特征、用户特征、店铺特征、用户+店铺四个方面。
利用Countvector和TF-IDF提取特征
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, ENGLISH_STOP_WORDS from scipy import sparse # cntVec = CountVectorizer(stop_words=ENGLISH_STOP_WORDS, ngram_range=(1, 1), max_features=100) tfidfVec = TfidfVectorizer(stop_words=ENGLISH_STOP_WORDS, ngram_range=(1, 1), max_features=100) # columns_list = ['seller_path', 'cat_path', 'brand_path', 'action_type_path', 'item_path', 'time_stamp_path'] columns_list = ['seller_path'] for i, col in enumerate(columns_list): all_data_test[col] = all_data_test[col].astype(str) tfidfVec.fit(all_data_test[col]) data_ = tfidfVec.transform(all_data_test[col]) if i == 0: data_cat = data_ else: data_cat = sparse.hstack((data_cat, data_))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
#特征重命名 特征合并
df_tfidf = pd.DataFrame(data_cat.toarray())
df_tfidf.columns = ['tfidf_' + str(i) for i in df_tfidf.columns]
all_data_test = pd.concat([all_data_test, df_tfidf],axis=1)
- 1
- 2
- 3
- 4
嵌入特征
import gensim # Train Word2Vec model model = gensim.models.Word2Vec( all_data_test['seller_path'].apply(lambda x: x.split(' ')), vector_size=100, #此处按照书上size报错,可能是由于版本差异,1、可将传入参数格式进行修改:size 改为 vector_size;iter 改为 epochs。2、降低gensim库的版本 window=5, min_count=5, workers=4) # model.save("product2vec.model") # model = gensim.models.Word2Vec.load("product2vec.model") def mean_w2v_(x, model, size=100): try: i = 0 for word in x.split(' '): if word in model.wv.vocab: i += 1 if i == 1: vec = np.zeros(size) vec += model.wv[word] return vec / i except: return np.zeros(size) def get_mean_w2v(df_data, columns, model, size): data_array = [] for index, row in df_data.iterrows(): w2v = mean_w2v_(row[columns], model, size) data_array.append(w2v) return pd.DataFrame(data_array) df_embeeding = get_mean_w2v(all_data_test, 'seller_path', model, 100) df_embeeding.columns = ['embeeding_' + str(i) for i in df_embeeding.columns]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
# embeeding特征和原始特征合并
all_data_test = pd.concat([all_data_test, df_embeeding],axis=1)
- 1
- 2
Stacking分类特征
略

