
热门标签
热门文章
- 1【译】使用Java编写Oracle Tuxedo应用
- 23D建模师的角色表:15个顶级提示_sd常用提示词建筑视图
- 3CNN, RNN, Transformer关于特征提取的对比分析_rnn为什么不具有特征学习能力
- 4tensorflow:使用mask-RCNN训练自己的数据集_maskrcnn怎么把json文件
- 5【无聊数学】总结一下我们在开发中踩到的那些坑儿_使用transporter 上传app不显示图标 invalid app store icon. t
- 6BERT可视化工具bertviz体验
- 7微信小程序与idea后端如何进行数据交互_微信小程序和idea
- 8智媒AI伪原创工具:超越想象的创作利器
- 9AIGC创作系统ChatGPT源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图_gpt4 turbo 国内使用
- 10SAP 生产订单缺料下达_co_zf_order_read
当前位置: article > 正文
如何理解attention中的Q、K、V_qkv矩阵
作者:菜鸟追梦旅行 | 2024-03-31 00:53:12
赞
踩
qkv矩阵
参考网址:知乎
Q:Query
K:Key
V:Value
这三个变量代表什么?
其实是三个矩阵,矩阵如果表示为LxD,L是句子中词的个数,D是嵌入维度,在自注意力机制里,QKV是表示同一个句子的矩阵,否则KV一般是来自一个句子,而Q来自其他句子
如何计算QKV
我们直接用torch实现一个SelfAttention来说一说:
- 首先定义三个线性变换矩阵,query, key, value:
class BertSelfAttention(nn.Module):
self.query = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.key = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.value = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
- 1
- 2
- 3
- 4
可以通过这三个线性变换query,key,value得到我们想要的QKV,其中三个变换的输入都是768维,输出都是768维
- 假设句子是“我想吃酸菜鱼”,嵌入维度是768,那么该句子表示成矩阵就是6x768维

将该矩阵输入上面的三个线性转换,就可以得到三个矩阵KQV,(6x768)X(768x768)=(6x768),维度其实没有改变。
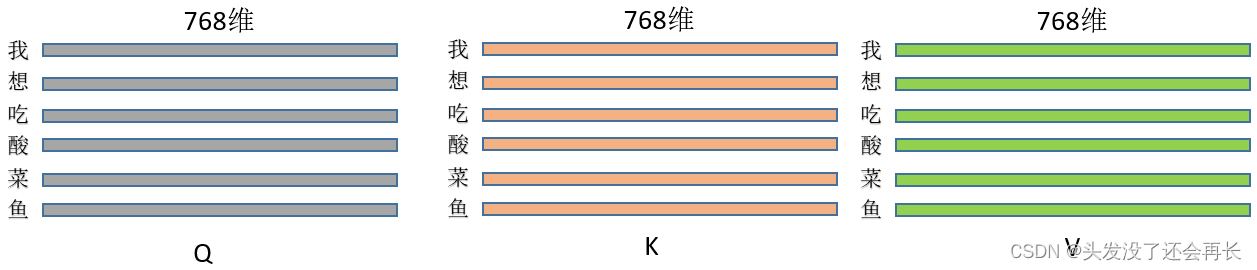
代码表示为:
class BertSelfAttention(nn.Module):
def __init__(self, config):
self.query = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.key = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.value = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
def forward(self,hidden_states): # hidden_states 维度是(L, 768)
Q = self.query(hidden_states)
K = self.key(hidden_states)
V = self.value(hidden_states)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
如何计算attention?
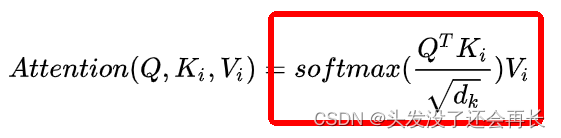
拿自注意力来举例(QKV都是同一个句子的矩阵)
① 首先是Q和K矩阵乘,(L, 768)*(L, 768)的转置=(L,L),看图:
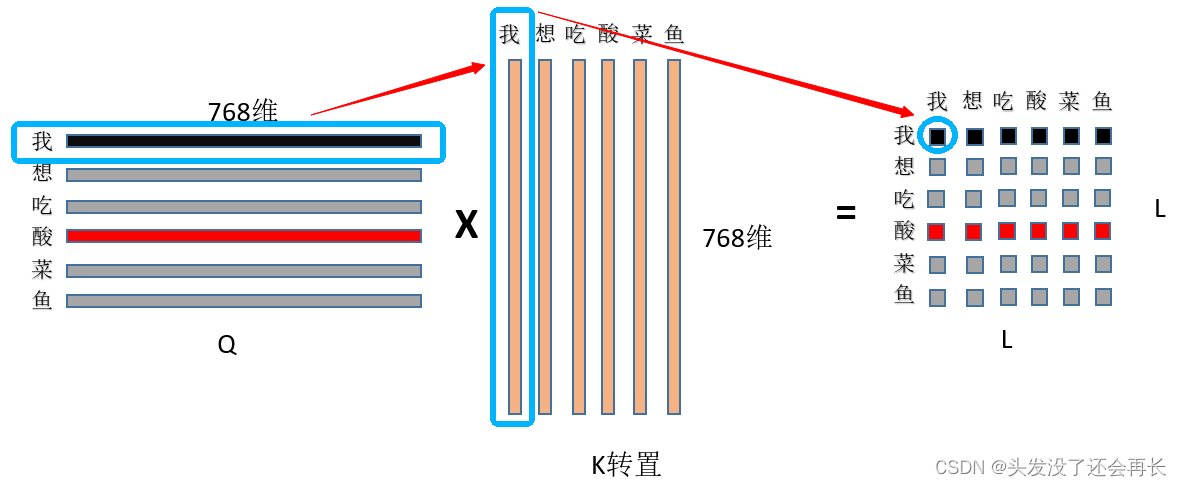
最后得到(LxL)的矩阵,其中图中蓝色圈圈代表的就是“我”对“我”的注意力值,其他位置的值亦然。
② 然后是除以根号dim,这个dim就是768,至于为什么要除以这个数值?主要是为了缩小点积范围,确保softmax梯度稳定性,再用softmax进行归一化操作(一种解释是为了保证注意力权重的非负性,同时增加非线性)
③ 然后就是刚才的注意力权重和V矩阵乘了,如图:
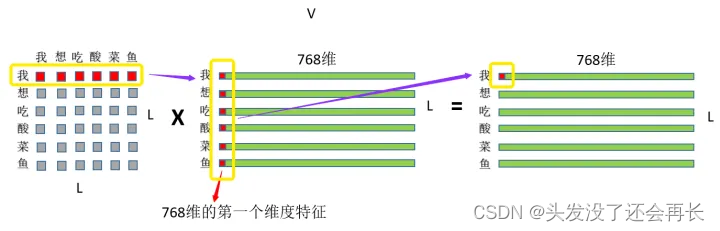
首先是“我”这个字对“我想吃酸菜鱼”这句话里面每个字的注意力权重,和V中“我想吃酸菜鱼”里面每个字的第一维特征进行相乘再求和,这个过程其实就相当于用每个字的权重对每个字的特征进行加权求和,然后再用“我”这个字对对“我想吃酸菜鱼”这句话里面每个字的注意力权重和V中“我想吃酸菜鱼”里面每个字的第二维特征进行相乘再求和,依次类推最终也就得到了(L,768)的结果矩阵,和输入保持一致
代码:
class BertSelfAttention(nn.Module): def __init__(self, config): self.query = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768 self.key = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768 self.value = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768 def forward(self,hidden_states): # hidden_states 维度是(L, 768) Q = self.query(hidden_states) K = self.key(hidden_states) V = self.value(hidden_states) attention_scores = torch.matmul(Q, K.transpose(-1, -2)) attention_scores = attention_scores / math.sqrt(self.attention_head_size) attention_probs = nn.Softmax(dim=-1)(attention_scores) out = torch.matmul(attention_probs, V) return out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/342520
推荐阅读
相关标签

