
- 1MySQL8.0 优化器介绍(一)_greatsql和mysql的关系
- 2使用人工智能将扫描地图中的数据数字化_qgis 插件 bunting labs
- 3实验题 用类建立职工工资管理数据库,计算总工资并排序输出 统计并输出总工资最高的职工姓名和工资_计算员工的总工资,并按总工资进行排名。
- 4AI在软件测试行业中的应用_ai在软件测试中的应用
- 5Unity和Android的交互_unity android 交互
- 6Unzip安装_unzip安装包
- 7观测云产品更新 | 监控、场景仪表板、查看器、服务管理、DQL等
- 8Rust语言中文版教程_rust中文教程
- 9VCRUNTIME140_1.dll丢失是怎么回事,如何修复VCRUNTIME140_1.dll缺失?_计算机中丢失vcruntime140-1.dll
- 10数据结构_二维数组a[20][10]采用列优先的存储方法,若每个元素占2个存储单元,且第1个元素的
出现线程不安全问题的原因及解决方法_线程不安全的原因
赞
踩
目录
有些代码在多线程环境下执行时会出现bug,这样的问题就被称为“线程不安全”问题。
线程不安全问题出现的原因:
1、抢占式执行
多个线程在调度执行过程中,可以视为“全随机”的,无法确定先执行哪一个线程,后执行哪一个线程,这是线程不安全的万恶之源!
由于这个机制是操作系统内核实现的,如果我们想要从这里下手解决线程不安全问题是做不到的。
2、多个线程同时修改一个变量
如果是a.一个线程修改一个变量 || b.多个线程同时读取一个变量 || c.多个线程同时修改不同变量,都不会出现线程安全问题,但当这三个条件同时满足时,就可能出现线程不安全问题:多个线程&&同时修改&&一个变量。
解决方法:调整代码,让上述三个条件不能同时满足。
3、操作指令不是原子的
由于线程是在CPU上调度执行的,而CPU在执行指令时,都是以“一个指令”为单位进行执行,但是有些简单的操作本质上是多个CPU指令,例如temp++这个操作,本质上是三条CPU指令:load、add、save(先把temp的值从内存中读取到CPU寄存器上,然后进行add操作,最后再把寄存器上的值写会到内存上),此时就可能出现线程不安全的问题。
举个栗子:创建两个线程,让两个线程同时对temp进行5万次自增操作,预期temp的结果是10万。
- public class Test {
- public static int temp = 0;
- public static void main(String[] args) throws InterruptedException {
- Thread t1 = new Thread(() -> {
- for (int i = 0; i < 50000; i++) {
- temp++;
- }
- });
- Thread t2 = new Thread(() -> {
- for (int i = 0; i < 50000; i++) {
- temp++;
- }
- });
- t1.start();
- t2.start();
-
- t1.join();
- t2.join();
-
- System.out.println("temp = " + temp);
- }
- }

代码无论执行多少次,temp的结果都不是预期的10万

由于多个线程的调度顺序是不确定的,所以上面两个线程在执行temp++操作时,可能会出现多种情况:
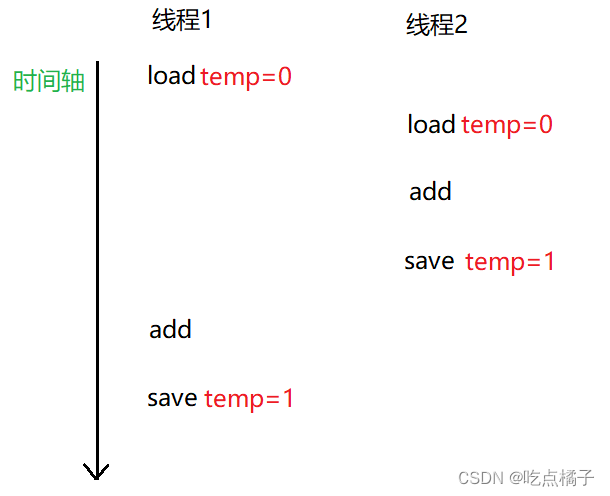

还有很多种无法正确执行temp++操作的情况......
而只有出现以下两种情况时,才会正确地执行temp++操作:
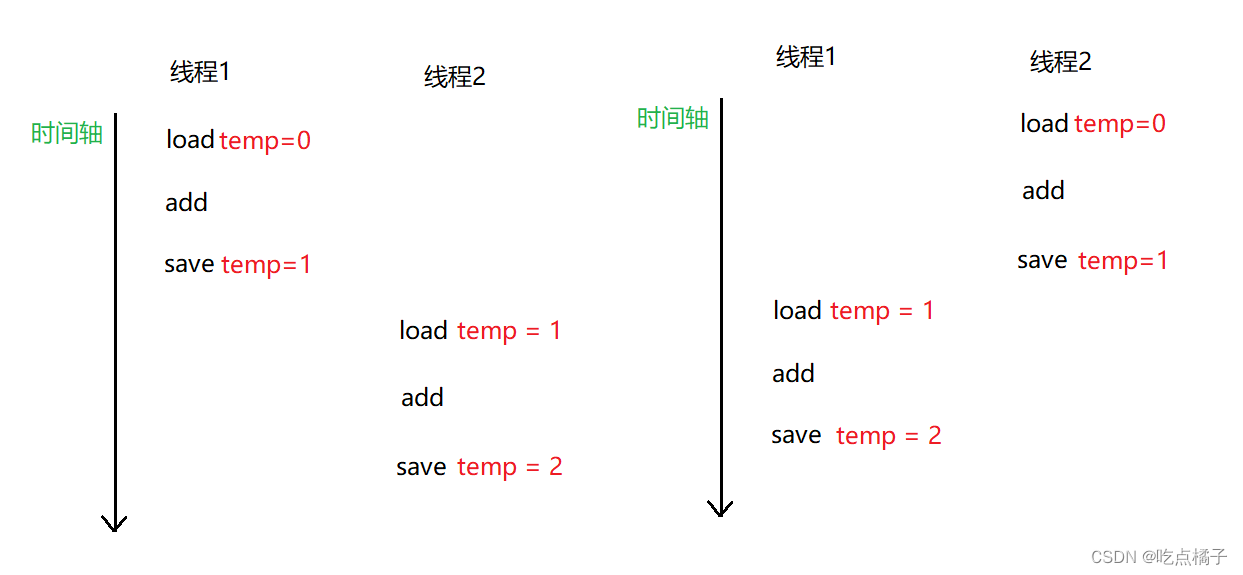
解决方法:把多个CPU指令打包成一个原子操作,使用synchronized关键字对可能出现线程不安全问题的代码进行加锁操作。
synchronized关键字详情:戳这里→
4、内存可见性问题
我们的代码在经过编译时,编译器可能会对其进行优化,而在多线程环境下,编译器优化后的代码可能就会和原来的代码逻辑有所不同,运行时出现了我们预期之外的结果,这就是内存可见性问题。
举个例子: t1线程中循环判断count的值是否为0,t2线程中修改count的值:
- public class Test {
- static class Counter{
- public int count;
- }
- public static void main(String[] args) {
- Counter counter = new Counter();
- Thread t1 = new Thread(() -> {
- while (counter.count == 0){
-
- }
- System.out.println("t1线程结束");
- });
- t1.start();
-
- Thread t2 = new Thread(() -> {
- System.out.println("修改count的值");
- Scanner scanner = new Scanner(System.in);
- counter.count = scanner.nextInt();
- System.out.println("count = " + counter.count);
- });
- t2.start();
- }
- }
代码运行结果:
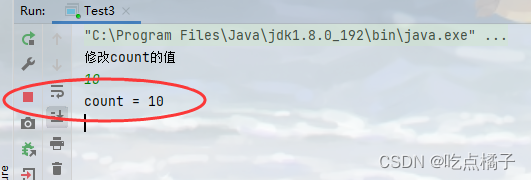
无论我们输入什么数值,t1线程中的while循环都不会结束……
原因:
因为t1线程中的while循环里没有什么任何操作,所以编译器这个小机灵鬼就会认为count的值是不会发生改变的,既然count不会改变,那么只需要在内存中读取一次就行了,不必每次执行count == 0时都从内存中读取,这样太浪费时间了;
于是编译器在优化之后,count只有在第一次执行count == 0比较的时候是从内存中读取的,之后的每次都是从CPU寄存器的缓存中读取,这样一来就节省了许多的时间。(从寄存器中读取数据的速度比从内存中读取数据的速度快了成千上万倍)
但是编译器并没有想到我们会通过其他线程来修改count的值,所以当我们在t2线程中修改count的值后,t1线程并没有感知到,因此代码便陷入了死循环。
解决方法:使用volatile关键字来修饰count,此时编译器就不会对count进行“只读一次内存”的优化了,所以volatile可以保证“内存可见性”问题。
此时我们的代码就可以正确地执行了:

补充:
谈到volatile,就需要知道JMM——Java Memory Model(Java内存模型),它把CPU中的寄存器和缓存统称为工作内存(work memory),把真正的内存称为主内存(main memory)。
站在JMM的角度来看volatile:
(1) 正常的程序在运行过程中,每次都会先把主内存的数据读取到工作内存中,再进行一系列操作;
(2) 编译器优化后的一些程序在运行过程中,可能并不会每次都从主内存中读取数据,而是直接读取工作内存中的缓存数据,这就可能导致内存可见性问题的出现;
(3) volatile的作用就是保证程序在运行过程中,每次都是从主内存中读取数据。
5、指令重排序
指令重排序也是编译器优化所带来的问题,有些单个的操作可以分为多个CPU指令(例如count++,就分为三个CPU指令),经过编译器优化后,这些指令的顺序可能会发生改变,在多线程环境下,就可能出现bug,即带来线程不安全问题。
单例模式中的“懒汉模式”就可能因为指令重排序的问题出现bug:
- class Singleton{
- private static Singleton instance = null;
-
- //封装构造方法
- private Singleton(){
-
- }
-
- public static Singleton getInstance(){
- if(instance == null){
- synchronized (Singleton.class){
- if(instance == null){
- instance = new Singleton();
- }
- }
- }
- return instance;
- }
- }
原因:
new一个对象的操作本质上又可以分为三个步骤:
(1) 申请一块内存,得到内存首地址(这一步还可以细分);
(2) 调用构造方法初始化实例;
(3) 把内存的首地址赋值给instance引用。
此时,编译器可能会进行指令重排序的优化,因为在单线程角度下,第二步和第三步的执行顺序是可以调换的,先执行哪一步后执行哪一步,最终结果是一样的。
然而,在多线程角度下,就可能会出现问题:
假设代码在经过编译器优化后出现了指令重排序的问题,并且按照1、3、2的顺序来执行new操作。如果t1线程执行完第一步和第三步后,此时的instance对象是一个不完全的对象,只是有内存,但是内存上的数据无效;当t1在执行第二步之前,t2线程调用了getInstance()方法,那么它就会认为(instance == null)的条件为假,直接返回当前这个不完全的instance对象,那么bug就出现了~
解决方法:使用volatile关键字,就可以禁止编译器进行指令重排序的优化。


