
- 1会议论文出版社、出版地、引用格式_ijcai出版商地址
- 2vulnhub靶场之driftingblues-2
- 3Python数据分析中文本分析的重要技术点,包括文本预处理、特征提取、情感分析_python文本分析
- 4OpenHarmony软总线总体功能简要介绍
- 5下载wp-config.php,wp-config.php
- 6【MindStudio训练营第一期】垃圾分类案例代码详解_aclliteresource
- 7linux 线程同步(二)_linux之线程同步二头歌
- 8Transformer详解(附代码)_transformer模型代码
- 9预训练模型与传统方法在排序上有啥不同?
- 10AIGC创作系统ChatGPT源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图_gpt4 turbo 国内使用
通俗解读NLP中几种常见的注意力机制_注意力机制有哪些
赞
踩
1 前言
注意力机制在NLP领域中有广泛的应用,诸如机器翻译、智能对话、篇章问答等。在模型设计中使用注意力机制,可以显著提升模型的性能。然而,对于初识注意力机制的朋友来说,可能会有这样的疑问:自然语言处理中说的注意力机制到底是啥?它与我们大脑中的注意力有何联系?它是如何实现的?面对诸多疑问,本文将用通俗的语言来解开这些困惑。本文首先简单介绍一下认知神经学中的注意力。接着,详细解说NLP领域常见的三种注意力机制:Bahdanau注意力、Luong注意力和自注意力(self-attention)。最后,对几种注意力机制进行归纳梳理,揪出它们的核心思想,分析它们的异同。
2 认知神经学中的注意力
在日常生活中,我们通过视觉、听觉、触觉等方式接收大量的感觉输入,而人脑在有限的资源下还能有条不紊地工作,是因为人脑可以有意或无意地从这些大量输入信息中选择小部分有用信息来重点处理,并忽略其他信息。这种能力就叫作注意力。注意力一般分为两种:
1)聚焦式注意力:自上而下的有意识的注意力。它是指有预定目的、主动有意识地聚焦于某一对象的注意力。例如,一个人在一个嘈杂的环境中与朋友聊天时,他还是可以听到朋友的谈话内容,而忽略其它声音。
2)基于显著性的注意力:自下而上的无意识的注意力。基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关。例如,一个人正在认真工作,忽然身后有人叫他名字,他会中断当前的工作,转头往后看看是谁在叫他。
当前NLP领域中的注意力机制大多是模拟认知神经学中的聚焦式注意力,即让模型根据当前状态,有目的地聚焦于某些信息。简单地说,NLP中注意力机制的核心思想就是让模型根据当前状态,从众多信息中选择当前所需要的最重要的信息。举个简单例子,一个人在房间里找一把银色钥匙,那么可以把当前状态理解为找银色钥匙,把信息定义为房间里的东西。根据找银色钥匙这个状态,那么{金属类物品,银色物品,形状像钥匙的物品}就成为注意力所关注的物品。那NLP中注意力机制中的当前状态到底是什么呢,下面通过几个例子来说明。
3 Bahdanau注意力与Luong注意力
- Bahdanau注意力
Bahdanau注意力机制是Bahdanau等人在论文Neural machine translation by jointly learning to align and translate中提出的。Bahdanau指出,在基于Encoder-Decoder结构中,传统的做法是,Encoder对句子进行编码,得到一个固定维度的向量表示给Decoder使用。因为维度固定,对于长句子来说,这种做法会造成较大的信息丢失。Bahdanau认为这个问题是神经机器翻译性能提升的瓶颈。于是他在论文中提出了注意力机制。他的做法是,Decoder不是“平等”地编码句子中的各个词,而是根据前一时刻状态,让Encoder对句子中重要的单词给予较高权重,对于不重要单词给予较低权重,权重的大小反映了当前状态所关注的句子中的信息。下面举个英译汉的例子来说明。
有一RNN Encoder,如图下半部分所示。每个时刻输入一个单词,输出一个隐状态。图中上半部分是一个RNN Decoder。它的输入包括三部分:前一时刻的解码输出、当前时刻Decoder状态
以及上下文向量(context vector)
。如下图中所示的第三个时刻,Decoder利用前一时刻的输出(作品)、当前时刻Decoder状态
和上下文向量
进行解码翻译,输出当前时刻的翻译结果。

而论文中计算上下文向量就采用了注意力机制。
等于Encoder各个时刻隐状态的加权和,如公式(1)所示。
(1)
从公式中可以看出,在第三个时刻,、
和
的权重较大,也就是说Decoder的注意力主要集中在了piece、conveys和feeling这三个单词所在时刻的表示信息上。那么权重是怎么得到的呢。论文中采用一个打分函数,让Decoder的前一个时刻状态
与Encoder各个隐藏状态
计算一个分数{
},如公式(2)所示。
(2)
其中为Decoder前一时刻的状态,
为Encoder各个时刻的隐状态。这里的打分函数score()可以采用向量内积方式来计算。
接着,对进行softmax操作,得到权重
,如公式(3)所示。
(3)
- Luong注意力
Luong等人在论文Effective Approaches to Attention-based Neural Machine Translation中也采用注意力机制来解决机器翻译任务中的对齐问题。Luong注意力与Bahdanau注意力主要有两点不同。一是打分函数所使用的查询向量不同。Bahdanau在打分函数中所用的查询向量是Decoder前一时刻状态,而Luong在打分函数中所用的查询向量是Decoder当前时刻状态
,如下图所示,

两种注意力的打分函数如下方公式所示,其中为Decoder上一时刻的状态,
为Decoder当前时刻的状态,
为Encoder各个时刻的隐状态。
Bahdanau打分函数:
Luong打分函数:
第二个不同是,Luong提出了三种不同的打分函数,如下面公式所示。
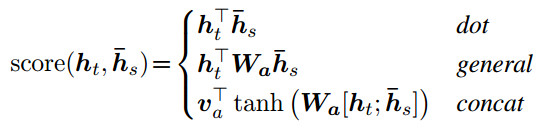
上式中,第一个函数用向量点积来计算分值,其中为解码器的当前状态。
为Encoder的隐状态。第二个函数采用了一个参数矩阵
,参数矩阵是可学习的,这个函数有个专业的名称叫双线性打分函数。第三个函数是加性打分函数,其中
、
是可学习的参数向量。三个函数的核心思想都是求Decoder当前状态与Encoder各时刻隐状态之间的关系。
4 自注意力(self-attention)
在唠叨自注意力机制之前,先说一下三个专有名词。其实,如果用土话能说明白的东西,我一般不会用专业术语去说,因为我更喜欢用接地气的话来沟通。然而这个部分绕不开这三个专有名词,它们分别是:查询向量(Query)、键向量(Key)和值向量(Value)。以找银色钥匙为例,简单理解一下这三个向量。如果把找银色钥匙这个状态编码为一个向量,那它就是查询向量。物品的各种颜色、形状和材质所表示的向量可以认为是键向量。这样就可以根据当前找银色钥匙这一状态计算不同颜色、不同形状、不同材质的分值权重。房间物品的向量表示就是值向量,综合房间某物品的颜色、形状和材质可得到一个对这个物品的关注度,即权重。不过在NLP中,键向量和值向量常常是相同的,或是从同一个向量经过不同的线性变换得到。为下文表述方便,查询向量用Q表示,键向量用K表示,值向量用V表示。Q、K、V也可以是二维矩阵。
在Luong注意力中,我们把Decoder当前时刻状态称为查询向量,Encoder各个时刻的隐状态
既是键向量,也是值向量。也就是说,用查询向量
和键向量
计算权重分布
,然后用
和值向量
计算加权和。
Bahdanau注意力和Luong注意力分别是用RNN、LSTM作为Encoder和Decoder的组件。而RNN、LSTM最明显的不足有两个,一是对长序列的反向传播容易造成梯度消失或梯度爆炸,二是RNN和LSTM必须得一个时间步一个时间步地进行编码和解码,每个时间步输入一个单词,不能并行计算。针对RNN和LSTM的这两点不足,Ashish在论文Attention Is All You Need中提出自注意力机制(self-attention)。简单来说,自注意力机制就是句子通过自己跟自己比较,来计算单词之间的相关性。那么,自己和自己怎么比较呢,具体细节如下图所示。
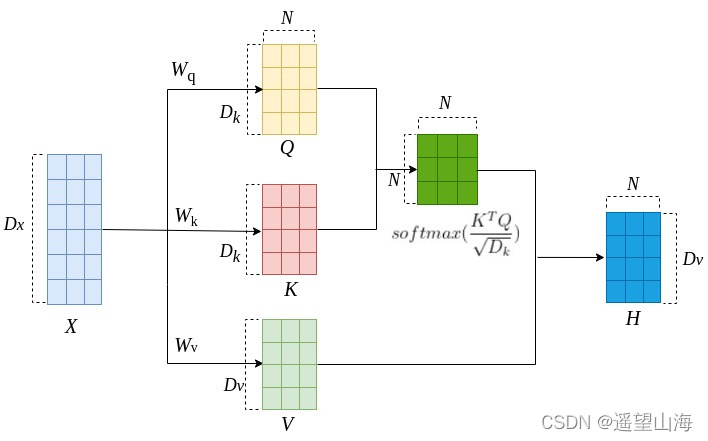
图中,X是输入序列,可以把每一列看作是单词的向量表示。、
、
是三个参数矩阵,它们将X映射到三个不同的向量空间:
、
、
。
叫查询向量矩阵,
叫键向量矩阵,
叫值向量矩阵。
如上图所示,查询向量矩阵和键向量矩阵
经过缩放点积运算,得到分值
,然后再对分值进行softmax操作,得到权值分布矩阵(图中绿色方阵)。最后再将值向量矩阵V与权值矩阵相乘,得到输出序列H.如下方公式所示。
5 总结
总的来说,不管是Bahdanau注意力、Luong注意力,还是自注意力,它们的作用都是做信息筛选,从输入信息中选取相关的信息。实现这个信息筛选的过程可以分为两步:一是计算注意力分布,二是根据
来计算输入信息的加权平均。
[参考文献]
[1] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate." arXiv preprint arXiv:1409.0473 (2014).
[2] Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. "Effective approaches to attention-based neural machine translation." arXiv preprint arXiv:1508.04025 (2015).
[3] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[4] 邱锡鹏. 神经网络与深度学习[M]. 北京: 机械工业出版社, 2021.

