
- 1算法:链表(力扣+牛客经典题)_牛客网和力扣网算法
- 2flask配置SSL证书,实现https服务 & Nginx实战(推荐使用Nginx配置)_flask ssl
- 3SQL NOT EXISTS讲解 (详例助理解)
- 4fatal: early EOF fatal: index-pack failed
- 5IDEA整合git使用_idea拉取git项目
- 6新研究突破!斯坦福提出 Octopus v2模型让AI代理在手机上运行更快、更准确_octopus v2 运行
- 7MySQL 修改数据
- 8【leetcode面试经典150题】52. 有效的括号(C++)
- 9(附源码)SSM失物招领平台 毕业设计 271621_失物招领平台的设计与实现
- 10Web 开发 6:Redis 缓存(Flask项目使用Redis并同时部署到Docker详细流程 附项目源码)_flaskredis
一文带你快速爬取网易云音乐,就是这么简单!_网易云音乐url
赞
踩
大家好,我是不温卜火,是一名计算机学院大数据专业大三的学生,昵称来源于成语—不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只在csdn这一个平台进行更新,

PS:如有侵权联系小编删除!著作权归作者所有!
前几篇博文,爬取的都是比较常规的网站。大家是不是都有点腻了呢?如果大家感觉腻了的话,博主此次带来的比较新奇的内容。如果大家没有腻的话,当我没说。话不多说,网抑云时间到了!

一、URL分析
在此,博主爬取的是网易云网页版,因为一般网页版都是最好爬取的,不要问我为什么,问就是不会!

网易云网页版链接:https://music.163.com/
歌手信息链接:https://music.163.com//discover/artist
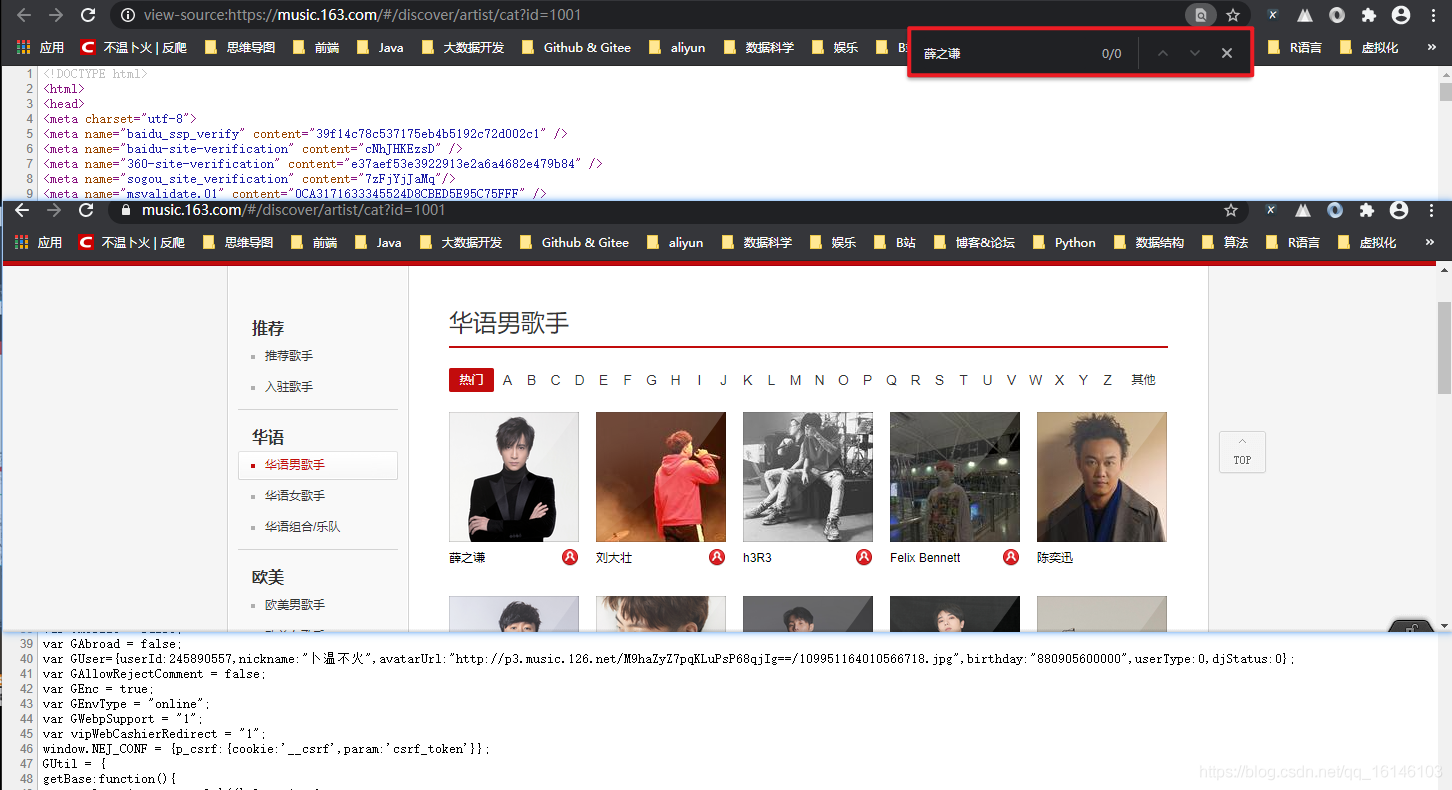
但是由上图我们可以看出,虽然直接给出了网页链接,但是我们通过查看网页源代码,发现我们想要爬取的信息并没有在这个网页中。
这个时候,我们就需要通过Sreach查找歌手信息,从而得到我们所需要的各种信息。
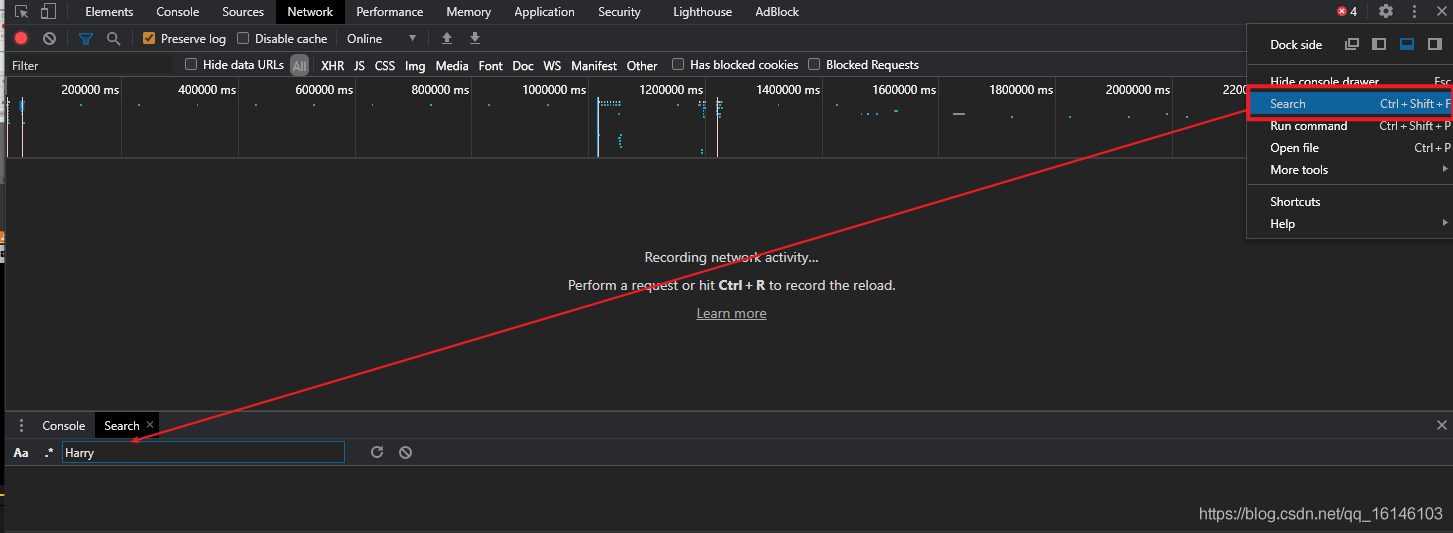
我们首先就以薛之谦为例
通过上图,我们可以知道我们所需要的爬取内容的网址:

我们可以多尝试几次,然后就会发现每个分类代表其中一个id
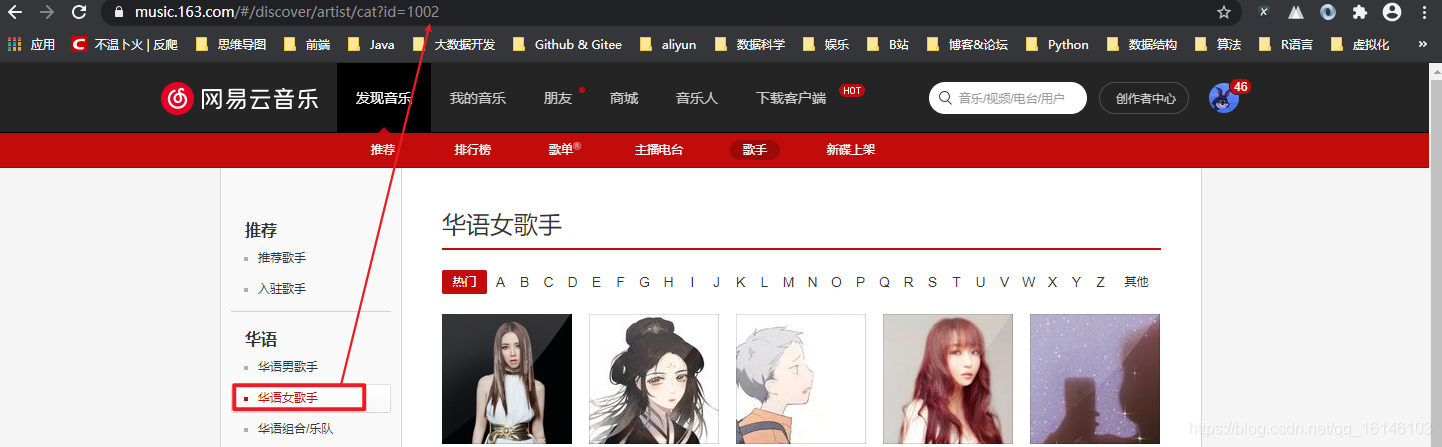
规律来了,那么我们是不是就可以使用xpath进行解析提取了呢? 我们可以先试验一下:
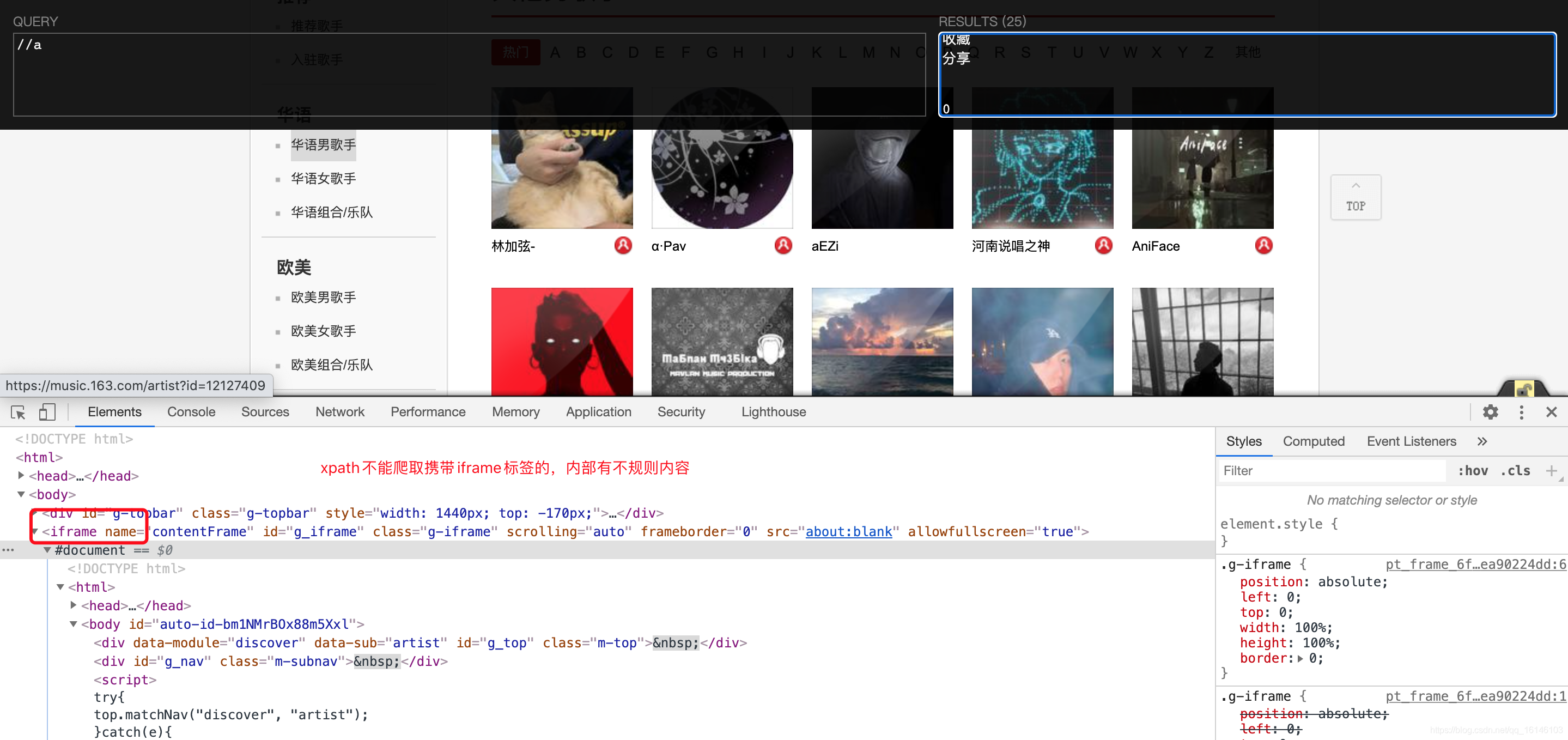
我们发现这个页面是不能直接使用xpath进行解析得,xpath只能解析html标签。因为该网页携带有iframe标签,内容有不规则内容。

既然出现问题了,那么我们首先要想的就是要解决xpath不能进行解析这一问题。
通过验证我们发现,虽然在页面插件中不能访问,但是我们发现向另一个url发送请求依然可以获取数据,且里面没有iframe,可以直接使用xpath。
测试代码如下:
import requests
from lxml import etree
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
}
base_url = "https://music.163.com/discover/artist/cat?id=1001"
response = requests.get(url=base_url, headers=headers)
html = response.content.decode("utf-8")
print(html)
1234567891011
我们通过查找iframe,发现里面没有包含iframe,这里就可以直接使用xpath进行解析了
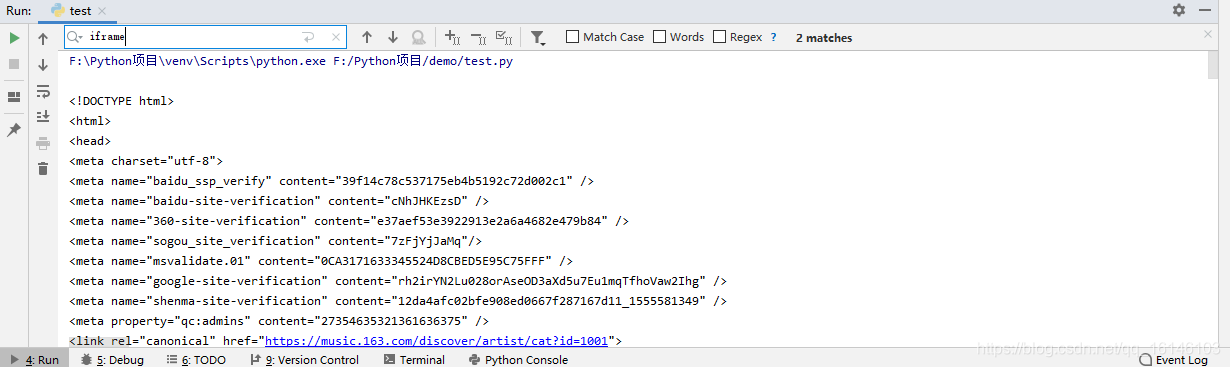
查找华语男歌手
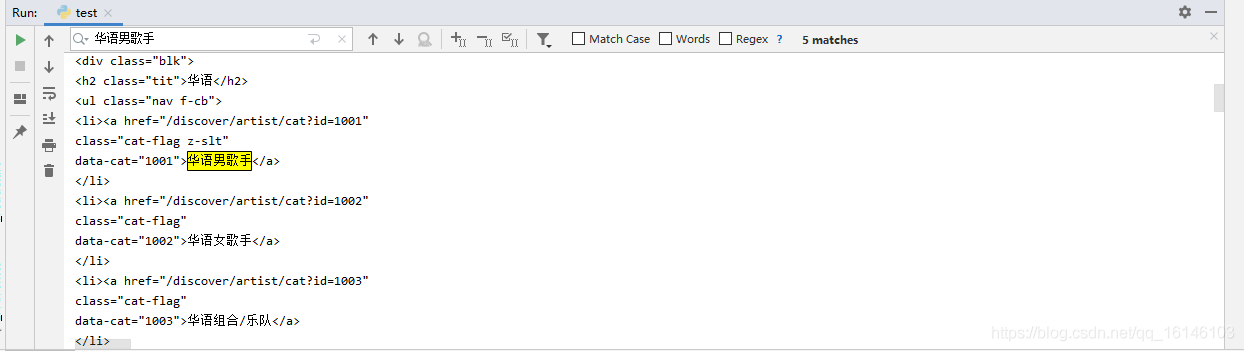
先把华语男歌手这一部分复制出来
<li><a href="/discover/artist/cat?id=1001" class="cat-flag z-slt" data-cat="1001">华语男歌手</a> </li> 1234
我们先来尝试使用xpath进行解析
# 只有华语男歌手
ret = etree_obj.xpath('//a[@class="cat-flag z-slt"]/text()')
print(ret)
123


Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

