
- 1微信小程序(日历/日期)选择插件_小程序日历选择范围
- 2PVE 安装 windows10_pve安装win10
- 3GPT-4 AII 免费开源!本地部署,免翻墙_gpt4all-installer-win64
- 4Windows 安装 Redis_windows安装redis
- 5[计算机网络] 高手常用的几个抓包工具(下)_http debugger pro
- 6(Datawhale)Java Task04:面向对象编程基础_huggingface_hub.utils._errors.repositorynotfounder
- 7电子宠物系统一_设计一个电子宠物系统,包含狗狗(昵称、品种)和企鹅(昵称、性别),输入宠物昵称和宠
- 8GEE计算遥感生态指数(RSEI)--Landsat 8为例_gee里function remove_water(img)
- 9华为ensp中nat server 公网访问内网服务器
- 10项目管理工具之Git/GitHub/Gitee/Gitlab_github项目管理工具
XAI有什么用?探索LLM时代利用可解释性的10种策略
赞
踩
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
每天给大家更新可用的国内可用chatGPT资源

更多资源欢迎关注

你是否也好奇,在大模型时代,可解释性人工智能技术(XAI)有怎样的使用价值?近日,来自佐治亚大学、新泽西理工学院、弗吉尼亚大学、维克森林大学、和腾讯 AI Lab 的研究者联合发布了解释性技术在大语言模型(LLM)上的可用性综述,提出了 「Usable XAI」 的概念,并探讨了 10 种在大模型时代提高 XAI 实际应用价值的策略。

论文题目:Usable XAI: 10 Strategies Towards Exploiting Explainability in the LLM Era
论文链接:https://arxiv.org/pdf/2403.08946.pdf
代码链接:https://github.com/JacksonWuxs/UsableXAI_LLM
这些策略涵盖两方面:(1)如何利用 XAI 来更好地理解和优化 LLM 与 AI 系统;(2)如何利用 LLM 的独特能力进一步增强 XAI。此外,研究团队还通过具体的案例分析说明如何获取和使用大模型的解释。

可用的大模型解释技术
Usable XAI in LLMs
从深度学习兴起至今,XAI 一直受到关注。人们希望通过 XAI 了解模型是否按预期工作,并利用这些解释来设计更好的模型。尽管 XAI 在技术上已有显著的进步,但如何有效使用 XAI 技术以满足人们的期待还有待探索。发展「可用的解释性技术」(Usable XAI)有两大阻碍,其一是 AI 自动化和人类介入之间存在冲突,其二是不同技术背景的用户对于解释的需求并不一致。
针对 LLM 的 Usable XAI 又面临更多新挑战:(1)LLM 庞大的参数量对于解释性算法的复杂度提出了限制;(2)LLM 擅长于生成式任务而非传统的分类任务,这对传统的解释性算法设计提出新的要求;(3)LLM 广泛的应用场景也让研究者在设计和使用大模型解释性算法的时候需要考虑道德因素和社会影响。另一方面,LLM 也可能在 XAI 的一些环节中替代人类的作用,从而提高解释性算法的可用性,降低人工成本。
研究者考虑大模型时代下的 「Usable XAI」包括两个方面:(1)使用 XAI 来增强 LLM 和 AI 系统,(2)使用 LLM 来提升 XAI 框架。进一步,研究者具体讨论了 10 种策略来实现 Usable XAI 技术(见图 1),其中包括 7 种使用解释来提升 LLM 的策略,以及 3 种使用 LLM 来提升解释性技术的策略。对于某些策略,研究者提供了案例分析来强调策略的有效性或局限性。
策略 1:归因解释用于诊断 LLM
归因解释(attribution methods)旨在量化每个输入单词对模型输出的影响。传统上,归因解释分为四种主要方法:基于扰动、基于梯度、基于代理模型和基于模型解耦。在这些方法中,基于梯度的方法仍然适用于 LLM。图 2 是一个输入 - 输出词对间的的归因解释热力图,亮度越高代表当前输入词对于当前输出词的影响越大。


通过归因解释,能够更加深入地理解 LLM 的运行机制。因此,论文作者们设计了一套流程,通过归因得分来分析模型行为(见图 3)。流程开始于指定一个目标 LLM 及其一个输入输出样本对,然后计算输入和输出单词之间的归因影响。因此,可以利用这些量化的归因影响以及人类对于某个任务的先验知识构造特征向量。最后,基于这些特征向量训练一个轻量级的模型用于模型行为的诊断。两个具体的案例研究进一步展示了如何应用这一策略。
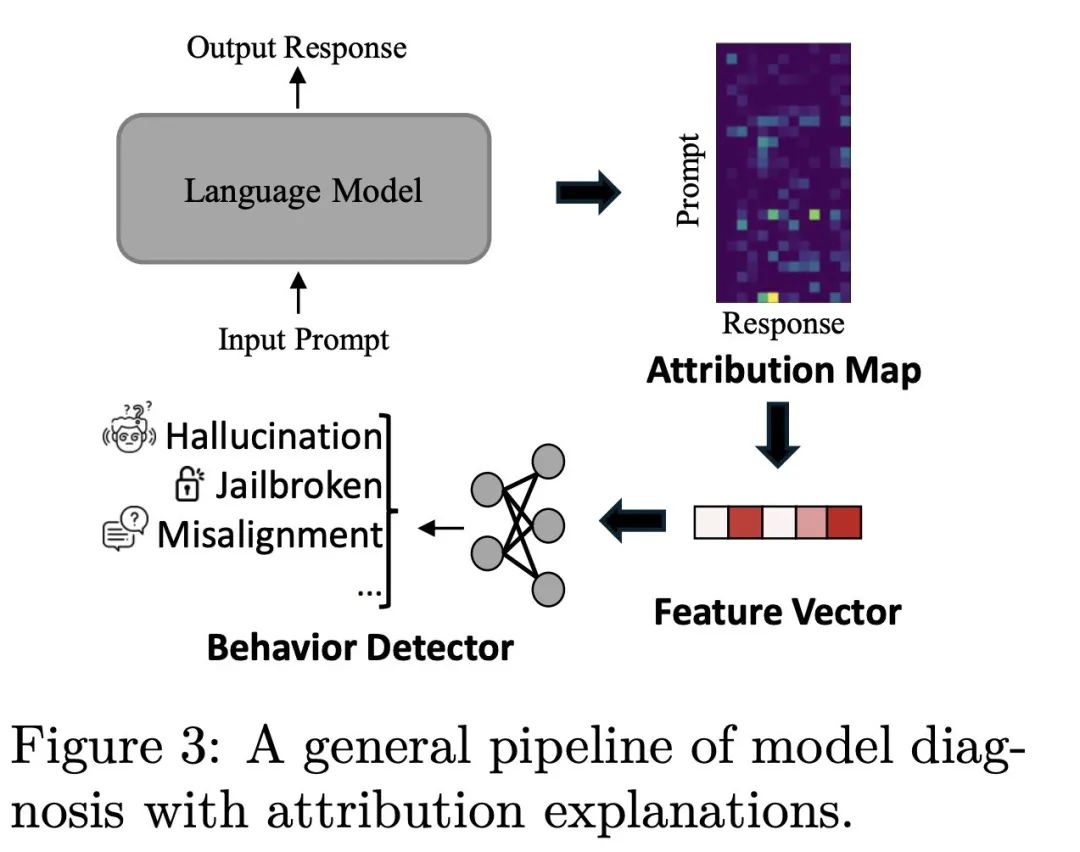
Case Study-1: 使用归因解释评估模型回答质量
考虑一个机器阅读理解场景,即输入一段文章以及一个问题,研究团队希望判断分析模型生成的回答质量。理想情况下,一个高质量的回答应该是依赖于文章中相关的内容得到的。于是,先通过归因解释抽取模型所依赖的原始文章段落,而后训练一个分类器基于抽取的段落判断回答是否正确。
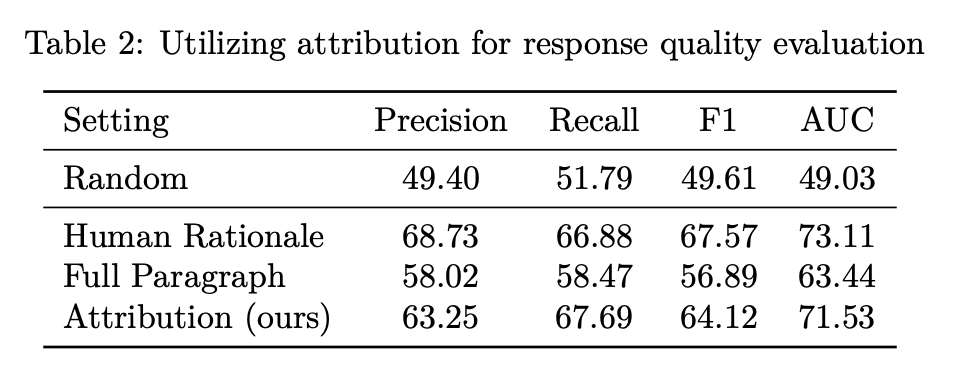
表 2 的使用结果说明,通过归因解释抽取的段落可以有效地判断答案的质量,并且取得了接近于人工标注的效果,证明了归因解释在验证模型答案质量方面的应用价值。
Case Study-2: 使用归因解释检测幻觉回答
LLM 可能会产生事实错误的回答,这种现象称为 「幻觉」(hallucination)。一个可能的原因是模型过于关注用户指令而忽视相关实体。例如,「请给我一个关于 Renoit 国王的故事」这个用户请求,Vicuna 模型会将《三个火枪手》里国王的故事安插给 Renoit 国王。
然而 Renoit 国王是一个虚构的角色,并不存在相应的故事。在这个例子中,模型太执着于执行指令 「请给我一个 xxx 的故事」,却忽略了指令实体 「Renoit 国王」。于是,作者提出通过统计输入指令中不同词性的单词的平均归因解释得分作为特征向量构建出一个幻觉回答检测器。

表 3 的实验结果表明,即使是较小模型(Vicuna/Mistral-7B)产生的归因解释也能有效识别大模型(ChatGPT 3.5)的幻觉回答,证明了这种方法的有效性。
策略 2:内部模块解释用于诊断和提升 LLM
LLM 主要构建于 Transformer 架构之上,其包括自注意机制(Self-Attention)和前馈网络(Feed-Forward Networks)。对于自注意机制,一个基本的解释方法是通过分析注意力矩阵来理解输入和输出之间单个样本词对的关系。除此以外,近期也有更深入的新技术出现,例如 Transformer Circuits 理论或者将模型权重投影到静态词向量,进而揭示具体权重的行为。这些技术帮助研究者设计出更好、更高效的自注意力结构。
在前馈网络方面,主流工作主要依赖于 key-value memories 理论。最新的研究致力于减轻由于神经元的多义性(polysemantic)导致的解释性难题,比如引入 PCA 分解或者字典学习的技术。这些解释性算法已经被尝试应用于模型知识编辑、生成内容控制、和模型剪枝等领域。
策略 3:基于(训练)样本的解释用于调试 LLM
基于样本的解释方法旨在通过分析训练样本来解释模型对于特定测试样本的响应。影响函数(Influence Function,IF)是这方面的核心技术之一,它通过评估移除特定训练样本并重新训练模型后,模型对测试样本响应的变化来量化该训练样本的影响力。这种方法不仅可以揭示 LLM 的回答依据何种训练文档,还有助于了解 LLM 如何在广泛知识领域内进行推广。
尽管影响函数的理论在 LLM 调试中极具潜力,但由于在大型模型上计算 Hessian 矩阵的复杂度,目前还缺乏实证这一技术在 LLM 上有效性的开源实现。因此,研究团队提供了一个案例分析来强调 IF 在 LLM 上的适用性,具体的代码可以在开源 Github 仓库中找到。
Case Study-3: 基于 EK-FAC 近似实现 LLM 影响函数解释
在本案例中,研究团队采用 Grosse 等人(2023)提出的 EK-FAC 近似理论来实现 influence function,验证其对于 LLM 的适用性,又选取 SciFact 数据集中的 5183 篇论文摘要作为训练语料,对包括 GPT2-1.5B、LlaMA2-7B、Mistral-7B 和 LlaMA2-13B 在内的一系列大模型进行了进一步预训练。
为了确保模型能记住每个训练文档,每个 LLM 均在该语料库上训练了 2 万步。通过随机选取某个训练文档的前三个句子作为输入,并收集模型的输出,研究团队使用 IF 估计了每个训练文档对于该输入输出对的重要性,并据此对训练文档进行排序。表 4 报告了对应的原始文档在前 5 或 10 个文档中的召回率,理想情况下,原始训练文档应该排在尽可能前面。
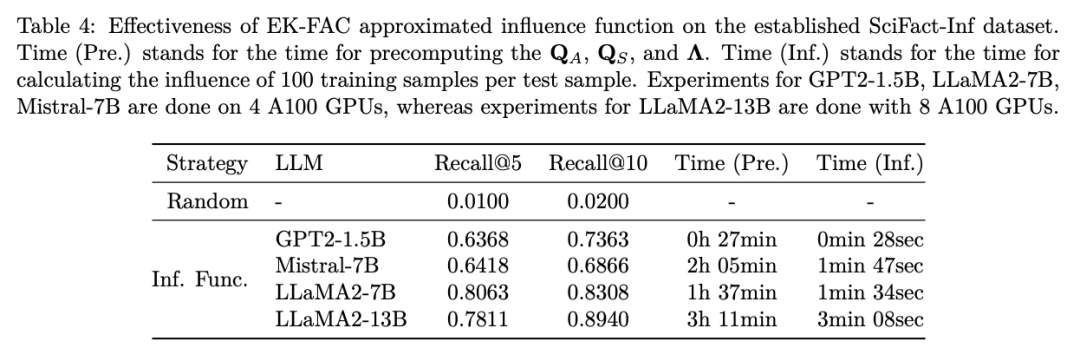
实验结果显示,作者的方法在召回率上显著优于随机选择策略,这表明 EK-FAC 近似的影响函数对于 LLM 是有效的。有趣的是,尽管模型对这些训练语料过度拟合,召回率仍未达到 100%,暗示了大型语言模型在预测时不仅仅依赖单一样本(可能还包括他们预训练阶段学习到的知识),而是展现出了强大的泛化能力。
策略 4:利用解释性技术提高 LLM 可信赖性和对齐度
相较于之前着重于提升模型性能的策略,本策略专注于如何运用可解释性技术提升模型的可信度(Trustworthiness)和使其与人类价值观对齐(Human Alignment)。随着 LLM 在医疗、金融、法律和教育等关键领域的广泛应用,确保这些模型能够遵守人类的道德准则和安全标准变得尤为重要。
本策略综合了近几年利用可解释性技术来增进语言模型在安全性、隐私保护、公平性、无害性及真实性五个维度的研究成果。虽然使用解释性技术提升模型可信度的方向已受到部分学界关注,但当前依旧缺乏有效的监测与缓解措施。这为发展更先进的 LLM 可解释性技术提出了新的挑战和期待。
策略 5:可解释的提示技术(prompts)用于提升 LLM
不同于传统的机器学习模型,LLM 的一大优势是其对于输入输出形式的高度灵活性。以情感分类任务为例,传统模型仅能输出一个表示情绪倾向的数值,而 LLM 能够提供包含理由的文本输出,这种输出方式本质上增加了模型解释行。其中,「思维链提示」(Chain-of-Thoughts,CoT)技术不仅提高了决策过程的透明度,还提高了模型下游任务的性能。这一方法成功催生了更多类似技术,如思维树(Tree-of-Thoughts)和思维图(Graph of Thoughts)。
尽管如此,这个框架的一个关键前提 —— 模型输出的文本真的可以作为其预测的解释 —— 还未经验证。因此,这篇综述通过案例分析探讨了 CoT 解释的忠实性。
Case Study-4: CoT 是否真的提高了 LLM 的可解释性?
作者针对复杂的多跳问答任务进行了案例分析,这类任务需要整合多个信息源才能解决问题。例如,询问 「中国百米跑第一名来自哪里?」需要结合关于 「中国百米跑第一名是谁」和 「该人物出生地」的信息。在这种多跳问答场景中,任何一环的错误都可能导致最终答案的错误。
为考查忠实性,研究团队选择了包括 2 跳、3 跳和 4 跳问题各 1000 个 的MQUAKE-CF 数据集,以考察 CoT 的忠实性。具体而言,研究团队首先收集模型生成的初始思维链和最终答案,然后故意修改思维链中的信息为错误知识,基于这个错误思维链让模型给出新的最终答案,并希望模型产生错误的答案。

实验结果表明,对于新一代的 LLM(如 Vicuna-v1.5, LLaMA2-7B, Falcon-7B, Mistral-v0.1/0.2-7B),它们会拒绝基于错误的思维链做出预测,这意味着还不能确定 CoT 对于这些新模型是否构成有效解释。然而,对于早期的 LLM(如 GPT-2, GPT-J, LLaMA-7B),较大的模型生成的 CoT 在忠实性方面表现较好,可以被视作有效的预测解释。
策略 6:利用知识增强的提示技术用于提升 LLM
区别于思维链等提示技巧,知识增强的提示依靠引入外部知识以提高模型回答的准确性和丰富度,这种方法通常被称为检索增强生成(Retrieval-Augmented Generation, RAG)。
RAG 技术主要分为两个步骤:首先,使用搜索引擎从外部知识库中检索相关信息;接着,将这些检索到的知识整合到提示中,与 LLM 共同工作。这种方式引入的外部知识对人类来说是可理解的,因此也被视为一种推理阶段的解释性技术。
在本综述中,研究者细致梳理了几种运用 RAG 技术来增强模型性能的应用场景,如减少幻觉现象、引入最新知识、以及融合特定领域的专业知识。
策略 7:将解释结果用于数据增强
数据增强是提升机器学习模型性能的一种经典方法,关键在于增加生成数据的多样性和确保这些数据与特定任务紧密相关。大型语言模型(LLM)的解释性技术为这一挑战提供了新的解决方案。通过解释性技术揭示模型的内部工作机制,不仅能够指导数据增强的过程,以便生成与任务更为契合的特征,还能避免模型学习到不当的捷径。
此外,借助 LLM 的高度可控生成能力和先前讨论的解释性技术,可以直接生成具有更高多样性的数据集,从而进一步提高模型的鲁棒性和性能。这种方法不仅扩展了数据增强的应用范围,也为提升模型理解能力和处理能力开辟了新途径。
策略 8:利用 LLM 生成用户友好的解释
传统的解释性技术常常依赖于数字结果作为解释的基础,这对普通用户来说并不友好。因为普通用户难以高效地审视并汇总大量数字信息。对于大部分人而言,理解和汇总大量数字信息是一项挑战。相对而言,文本描述形式的解释更能帮助人们理解和接受解释性结果,这对于提升解释性技术的实用性和接受度至关重要。综述总结了近年来如何利用 LLM 重构解释性算法的输出,以提高其对用户的友好度的相关工作。
策略 9:利用 LLM 设计可解释的 AI 系统
在 XAI 领域,设计原理上具有可解释性(intrinsically interpretable)的人工智能模型一直是一个核心目标,目的是根本上增加系统的透明度。传统机器学习中的决策树,以及深度学习中的概念模型(concept bottleneck models)和解耦模型都是可解释性较高的系统示例。
在综述中,研究团队总结了两种利用 LLM 来辅助设计可解释 AI 系统的方法:一是利用 LLM 模拟人类专家的角色,为任务定义所需的概念;二是构建由多个 LLM 组成的系统,其中每个 LLM 承担特定的功能,从而提升整个系统的可解释性。
策略 10:利用 LLM 扮演人类在 XAI 中的角色
类在开发可解释性 AI 模型的过程中扮演着关键角色,包括采集有人类标注的数据集进行模型训练,以及评估模型生成的解释。然而,人类参与的过程往往耗费大量的时间和金钱,限制了 XAI 的发展规模。
综述中探讨了如何利用 LLM 模拟人类能力以缓解这一问题的可能性。相关研究指出,通过整合基于主动学习的数据标注策略,LLM 可以在保持数据质量的同时,模拟人类标注者的角色,为采集高质量的人类标注数据集提供辅助。
未来展望
-
规避模型可解释性与准确性之间的矛盾:在传统的 XAI 研究中,通常需要在透明度和模型性能之间做出权衡。然而,随着 LLM 的发展,直接识别可解释性模块变得更加复杂。因此,论文作者建议 XAI 研究者放弃这种基于权衡的思维模式,转而寻求同时增强模型的解释性和准确性。这正是论文中 Usable XAI 旨在实现的核心目标。
-
数据驱动 v.s. 解释性驱动:当前,数据驱动的 AI 技术占主导地位,其通过利用大规模数据集构建强大的「黑箱」模型,强调结果而非决策过程。然而,随着高质量数据资源的逐渐枯竭,解释性驱动的 AI 技术有望迅速发展,推动通过解释性增强模型和更高效地利用数据的新范式。
-
设计可解释性的目标:LLM 时代,XAI 技术的重要性相对发生了根本变化,LLM 强大的能力使得研究者们无需关注为什么模型没有生成一个连贯的句子,而是开始追求解释 LLM 是否依赖于事实信息构建输出之类的问题。鉴于 LLM 强大的能力和复杂性,或许解释性目标需要转变为一个更具体、并切实可行的方面,例如为某个特定的任务或者场景定制的可解释性目标。
-
评估 LLM 的可解释性面临新挑战:传统的 XAI 已经建立了完善的问题分类体系,但无法直接移植到 LLM 时代的 XAI 研究。因为在 LLM 的背景下,某些可解释性问题变得不那么突出,同时某些方法变得过于复杂。此外,LLM 内部机制的研究已经呈现出多样化的趋势,如研究模型的「撒谎」、「礼貌」 和 「催眠」等行为。这些因素都导致解释 LLM 的方法尚未形成统一的方法论,从而使评估变得具有挑战性。
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站https://ai.hzytsoft.cn/
每天给大家更新可用的国内可用chatGPT资源
更多资源欢迎关注

