
- 1EMNLP 2023 | 阅读顺序很重要:蚂蚁联合复旦提出全新多模态文档信息抽取模型
- 2机器学习—深度学习之基础理论算法原理推导逻辑回归(Logistic Regression)算法原理推导_深度学习中logistic是怎么得来的
- 3小程序播放音乐_微信小程序上方出现音乐和音频
- 4264.【华为OD机试真题】最长子字符串的长度(二)(动态规划DP-Java&Python&C++&JS实现)_od 最长子字符串的长度(二)
- 5内网安全——域信息收集&应用网络凭据&CS插件AdfindBloodHound
- 6大模型系列:OpenAI使用技巧_使用助手API(GPT-4)和DALL·E-3创建幻灯片_openai写ppt
- 7Github 学生优惠包 -- 最新防踩坑指南_github教育优惠包
- 8如何使用 ONLYOFFICE API 转换办公文档格式_onlyoffice接口文档
- 9机器学习-决策树(XGBoost、LightGBM)_决策树 指示函数
- 10部署基于docker和cri-dockerd的Kubernetes1.24_wget下载安装最新版的cri-dockerd
JUC集合类 ConcurrentLinkedQueue源码解析 JDK8_juc下以concurrent开头的集合类有哪些
赞
踩
前言
ConcurrentLinkedQueue是一种FIFO(first-in-first-out 先入先出)的无界队列,底层是单链表,一般来说,队列只支持队尾入队、队头出队,但此类还支持从内部删除某个特定的节点。使用非阻塞算法来处理并发操作,这也意味着实现里充满了CAS和自旋。
概述
- 既然是队列,自然有
head和tail分别指向first live node和last node。- live node指的是item不为null的节点,因为item为null代表节点逻辑上被删除。first live node就是指队列中第一个live node。
- 按照惯性思维,
head和tail可能需要时刻保持指向正确,但在ConcurrentLinkedQueue却不是这样,它反而允许head和tail偏离first live node和last node。因为常用做法需要两个volatile写才能完成(比如入队时,首先需要CAS修改last node的next指针,然后需要CAS修改tail),但CAS操作都是独立的,没法将两个CAS操作绑定在一起,所以干脆抛弃惯性思维,然后允许head和tail处于不一致的状态。另一个方面,CAS操作是一种很耗资源的操作,应该尽量减少这种操作尤其是在非阻塞算法中,所以ConcurrentLinkedQueue的做法是:检测到head和tail偏离了一定程度后,才修正head和tail。- 当偏离程度达到2时(比如
tail距离last node为2,形如... tail ⇒ 某节点 ⇒ last node),才会进行修正。但注意,这个修正只是一次CAS尝试,不管结果是成功还是失败。偏离程度在注释中原称为松弛阀值slack threshold。 - 如下图,允许head偏离first live node、tail偏离last node。
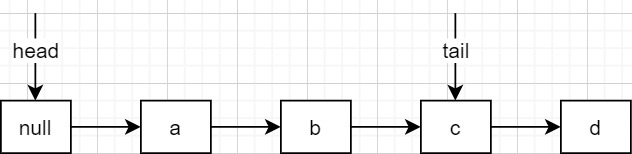
- 当偏离程度达到2时(比如
- 一个节点被删除,会先后有两种状态:1. item域设置为null 2. next域指向自身(第二步可能有)。
- 虽然
head和tail可能会偏离它们本该指向的位置,但这不会影响到队列的正确使用。简单的说,只要能保证节点之间的next指针依次连接着就行。 - ConcurrentLinkedQueue使用“不变式”和“可变式”来保证队列的正确性,函数实现都将会遵循这些“不变式”和“可变式”。
- 由于
head和tail的修改是完全独立,有时会出现head在tail之后的情况。
不变式
基本不变式
- 队列中只能有一个节点的
next为null,当然它就是我们说的last node。一般情况下,我们从tail出发就能以O(1)的复杂度找到last node,不过有时,需要调转到head继续遍历,此时需要O(N)的复杂度。 - 从
head出发能找到所有item域非null的节点。这个可达性即使在head被并发修改的情况下,也一定会保持。一个已出队节点可能会因为迭代器的使用或失去了执行时间片的poll()动作,而保持使用状态。
head
head的定义:从head出发可以以O(1)的复杂度到达first live node。
head的不变式:
- 所有活着的节点,都能从head出发然后调用
succ()被找到。 - head不能指向null。
(tmp = head).next != tmp || tmp != head,其实就是head的next不会指向自身。
head的可变式:
- head的item域可能为null,或非null值。
- tail可以早于head,但此时从head就已经不能找到tail了(此时tail已经脱离了队列了)。
tail
tail的定义:从tail出发可以以O(1)的复杂度到达last node。
tail的不变式:
- last node总是从tail出发通过succ()到达。
- tail不能指向null。
tail的可变式:
- tail的item域可能为null,或非null值。
- tail可以早于head,但此时从head就已经不能找到tail了(此时tail已经脱离了队列了)。
- tail的next指针可能会指向自身。
初始化
队列初始化
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
- 1
- 2
- 3
默认初始化时,队列的head和tail都指向一个dummy node。可见,队列初始化时,是符合所有不变式的。
Node初始化
Node(E item) {
//在构造Node时,使用putObject,这是没有volatile语义的写动作。
UNSAFE.putObject(this, itemOffset, item);
}
- 1
- 2
- 3
- 4
在构造Node时,使用putObject,这是没有volatile语义的写动作。之所以没有必要使用this.item = item这样的volatile写,是因为没有必要在此时(刚构造,还没有入队)就让所有线程看到,反正这个node还没有入队,别的线程也不可能通过队列找到这个node。
而等到它入队时,使用的是casNext来入队,这个动作是个volatile写动作,而在每一个 volatile 写操作前面,都会插入一个 StoreStore 屏障。而StoreStore 屏障:它保证在 volatile 写之前,其前面的所有普通写操作,都已经刷新到主内存中。也就是说,casNext成功入队后,所有线程自然都能看到这个node的item了。
这样,又减少了volatile写的次数。
add/offer 入队操作
首先要知道入队操作的目的就是找到last node,然后把新节点接在其后面。
- 从
tail出发来找到last node肯定是最快捷的,但循环中不可能每次现去读取tail域(因为它是易变的),所以都是使用局部变量t作为锚点,在必要的时候使用t = tail更新一把(初始化t也是用的t = tail)。 - 而局部变量
p则是循环变量,它以t为锚点向后移动,由于t都是通过t = tail得到的,所以可以通过p的后继q与t的距离来判断偏离程度,发现偏离程度大于等于2时,则尝试更新tail为最新的last node(当入队成功时),或者执行t = tail更新锚点以便获得最新的tail从而更快地找到last node。
而下面有个三目表达式我得提前讲一下,就是这个p = (t != (t = tail)) ? t : head,它等价于:
newTail = tail;
p = (t != newTail) ? newTail : head;
t = newTail;
- 1
- 2
- 3
硬要解释的话,就是执行顺序从左往右,第一个t执行后,不等号左边就是只能是旧的t值了;(t = tail)这个赋值语句的返回值是tail,所以不等式其实就是旧t != tail;第三个t的值肯定就是前面的赋值语句所获得的值了。
此函数的返回值只能为true,因为是无界队列。
public boolean add(E e) { return offer(e); } public boolean offer(E e) { checkNotNull(e); final Node<E> newNode = new Node<E>(e); for (Node<E> t = tail, p = t;;) { Node<E> q = p.next; //如果p的后继为null,说明p是last node if (q == null) { if (p.casNext(null, newNode)) {//尝试入队, //last node的next指向了新节点,这就保证了队列能访问到新节点 if (p != t) // 不相等说明p和t之间距离至少为1,现在p后面加了个新节点,那t与last node距离至少为2,需要更新tail了 casTail(t, newNode); //更新失败是允许的 return true;//成功入队,返回true } // CAS不成功说明别的节点抢先入队了,必须重试 } //如果p后继指向自身(recycled node) else if (p == q) //如果p后继指向自身,说明p是已删除节点,循环变量p已经不在队列上了。 //1. 如果此时tail没有变化,说明我们已经无计可施,只好将p跳转到head,从头遍历。 //2. 如果此时tail发生了变化,说明有人替我们干了上面的脏活,并且更新好了tail,那么 // 我们直接p置为新tail即可。 p = (t != (t = tail)) ? t : head; //如果p既不是last node也不是recycled node else // 这种情况则需要继续移动循环变量p了,当然也得检查与锚点t的距离 p = (p != t && t != (t = tail)) ? t : q; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
执行过程在开头一段和注释都解释得很清楚了。简单的说,就是锚点t从tail得来,循环变量p根据t往后移动,必要时把t和p都更新最新的tail(重置),以便快速找到last node,最后入队。
这里我用表格把p = (t != (t = tail)) ? t : head的逻辑分解一下:检测到p是recycled node,说明循环变量p已经脱离队列了,现在需要回到队列上去。
| 前提条件 | 条件 | 结果1 | 不变结果 | 解释 |
|---|---|---|---|---|
| 检测到p是recycled node | t≠当前的tail | p赋值为新tail | t赋值为新tail | 当前p已不在队列上,但有人已帮忙找到了最新的tail |
| 检测到p是recycled node | t=当前的tail | p赋值为head | t赋值为tail(不变) | 当前p已不在队列上,但没人帮忙,自己老实的从head遍历 |
p = (p != t && t != (t = tail)) ? t : q的逻辑也分解下:检测到p既不是last node也不是recycled nod,说明p需要前进,但不同情况下前进的效果不同。
| 前提条件 | 条件1 | 条件2 | 结果1 | 结果2 | 解释 |
|---|---|---|---|---|---|
| 检测到p既不是last node也不是recycled node | p≠t | t≠当前的tail | p赋值为新tail | t赋值为新tail | 有人帮忙找到了最新的tail,那就t和q都更新(重置) |
| 检测到p既不是last node也不是recycled node | p≠t | t=当前的tail | p赋值为q | t赋值为tail(不变) | 当前锚点依旧是对的,那就老实的后移p |
| 检测到p既不是last node也不是recycled node | p=t | 短路,不执行 | p赋值为q | t不变 | p还都没有离开锚点,那就后移p,不用去检测锚点是否为当前的tail |
即使从单线程环境来执行,tail也不是每次入队都更新的,它其实每隔一次才尝试CAS更新tail。由于head和tail的更新完全是独立的,所以下图就只画出tail的位置。

注意,不变式中从来没有提到过,tail到last node的距离不会大于等于2。由于casTail(t, newNode)只是尝试更新,特殊的线程并发顺序也有可能导致tail距离last node的距离大于等于2。
出队操作
poll
poll()返回first live node,并出队。锚点h从head取得,循环变量则是p它以h作为锚点,移动p以寻找到first live node,如果找到就将其出队,根据偏离程度来决定是否更新head。
final void updateHead(Node<E> h, Node<E> p) { if (h != p && casHead(h, p))//CAS是允许失败的 h.lazySetNext(h);//这里没有volatile语义 } public E poll() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { E item = p.item; if (item != null && p.casItem(item, null)) { //进入分支说明成功执行了出队操作 if (p != h) //h与p距离已经至少为1了,现在p的item也被置null, //说明h与p的后继 的距离至少为2,所以需要更新head。 //这里需要保证p的后继存在,才更新为p的后继; //否则更新为p本身,因为p后面没有节点了 updateHead(h, ((q = p.next) != null) ? q : p);//CAS是允许失败的 return item;//返回的肯定是非null值 } //执行到这里,有两种情况: //1. p的item发现为null //2. p的item发现不为null,但CAS失败。说明别的线程抢先了出队操作,那么p的item也会为null的 //如果p是last node,说明找到最后都没有找到有效节点(p就是那个dummy node) else if ((q = p.next) == null) { //更新head为dummy node updateHead(h, p); return null;//返回null,代表出队失败,没有节点可以出队 } //如果p的后继指向自身,说明p已经脱离队列。重新读取head else if (p == q) continue restartFromHead; //移动循环变量,继续寻找有效节点 else p = q; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
同样的,即使从单线程环境来执行,head也不是每次出队都更新的,它其实每隔一次才尝试CAS更新head。

从上图可以看出,出队b时,由于没有更新head,所以也不会将出队元素的后继指向自身(不然队列就断了)。
h.lazySetNext(h)这句话没有volatile语义,因为这没必要让所有线程马上看到,它只要之后能被GC检测到就行。
同样,由于casHead(h, p)只是尝试更新,特殊的线程并发顺序也有可能导致head距离first live node的距离大于等于2。
peek
peek()返回first live node的item,不执行出队动作。peek()和poll()的逻辑很像,可以说是poll()的简化版,因为它不需要执行出队。
public E peek() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { E item = p.item; //找到了first live node,或dummy node(此时队列中只有它) if (item != null || (q = p.next) == null) { updateHead(h, p); return item;//可能返回null和非null } //此时脱离了队列,重新读取head else if (p == q) continue restartFromHead; //还没找到,所以后移p else p = q; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
拆分一下if (item != null || (q = p.next) == null)的逻辑,就好理解多了。
| 条件1 | 条件2 | 结果1 | 结果2 | 解释 |
|---|---|---|---|---|
p.item≠null | 短路不执行 | - | updateHead(h, p) | 找到了第一个item不为null的节点,返回这个item |
p.item=null | p.next=null | 获得了p的后继q(虽然是个null) | updateHead(h, p) | 看来只能找到了dummy node了(队列中没有live node),此时返回null |
p.item=null | p.next≠null | 获得了p的后继q(不是null) | 走下一个if分支 | 没有找到first live node之前,利用这个组合条件来获得p的后继q |
可以看到执行updateHead(h, p)时,并没有根据偏离程度来做决定,而是一定会执行updateHead(h, p)。这一点和poll()不同。
first
Node<E> first() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { boolean hasItem = (p.item != null); if (hasItem || (q = p.next) == null) {//这里的逻辑其实一样的 updateHead(h, p); return hasItem ? p : null; } else if (p == q) continue restartFromHead; else p = q; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
first函数类似peek(),但是它直接返回队头节点。逻辑几乎完全一样。
//比如peek可以这么实现
public E peek() {
Node<E> node = first();
E item;
while((item = node.item) != null)//防止返回后被并发地删除了(item置为null)
node = first();
return item;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意不能将peek()的实现简单改成调用first,因为这样还需要多执行一次对item域的volatile读操作,而且考虑到poll()的线程竞争,有可能first返回节点的item域被并发修改为null了。
remove 删除操作
该函数可以删除处于队列中任意位置的live node,如果真的存在这样的live node,将其删除后返回true;如果找不到,返回false。
final Node<E> succ(Node<E> p) { Node<E> next = p.next; return (p == next) ? head : next;//如果脱离了队列(发现后继是本身),就返回head,以便从头遍历;否则就返回其后继 } public boolean remove(Object o) { if (o == null) return false; Node<E> pred = null; for (Node<E> p = first(); p != null; p = succ(p)) { E item = p.item; if (item != null && o.equals(item) && p.casItem(item, null)) {//如果删除操作成功 Node<E> next = succ(p); if (pred != null && next != null) pred.casNext(p, next);//从队列中移除掉空节点,CAS可能失败 return true;//删除成功返回true } pred = p; } return false;//循环执行完了都没找到,返回false }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这句pred.casNext(p, next)是有可能执行失败的,但是执行失败也是有别人帮忙做了这个CAS操作才导致的。从ConcurrentLinkedQueue的全代码中搜索,执行casNext且第一个参数不是null的地方,除了这里就只有迭代器的advance函数里有,但advance里也是在做同样的事情:从队列中移除掉空节点。所以说失败了也没关系。
下图简单演示了删除过程,不过断开链接的最后一步不一定会去做。

注意,即使队列中间某个节点的item域为null了,也不会影响入队出队的。上图最后一个状态,倒数第二个节点的next指针还是指向d的,只是没画出来,不用画出来是因为它即将被GC掉,因为没有引用在引用它了。
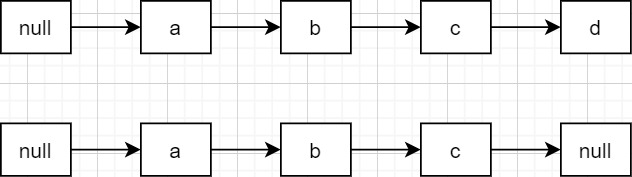
如上图,如果last node刚好是live node,现在调用remove方法删除d节点,由于if (pred != null && next != null)的限制,会导致last node非live。
remove的bug
Repeated offer and remove on ConcurrentLinkedQueue lead to an OutOfMemoryError
上图的这种情况可能导致内存泄漏,当你反复入队并删除最后一个节点时,会形成... null ⇒ null ⇒ null ⇒ null的队列,从而造成内存泄漏。
size 弱一致性的方法
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
return count;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
由于并发的存在,size返回的数字其实并不准确,但这没关系,因为size方法只需要有弱一致性就行。
另外一点,由于ConcurrentLinkedQueue没有成员用来存储size,而是遍历一遍整个队列来得到size,所以效率也不是很高。
addAll
该函数将传入集合的节点本地构成一个单链表,然后将其附在tail后面。
public boolean addAll(Collection<? extends E> c) { if (c == this) // 不允许自己加自己 throw new IllegalArgumentException(); // 本地构造出一个单链表来 Node<E> beginningOfTheEnd = null, last = null; //前者是链表头节点,后者是链表尾节点 for (E e : c) { //使用尾插法 checkNotNull(e); Node<E> newNode = new Node<E>(e); if (beginningOfTheEnd == null) beginningOfTheEnd = last = newNode; else { last.lazySetNext(newNode); last = newNode; } } if (beginningOfTheEnd == null) return false; // 尝试把本地链表的头节点附在last node后 for (Node<E> t = tail, p = t;;) { Node<E> q = p.next; if (q == null) {//如果p是last node // p is last node if (p.casNext(null, beginningOfTheEnd)) {//成功将本地链表入队 // 入队后理论上新tail应是last,所以CAS设置成它 //1. 如果CAS成功直接返回,因为别的线程做了 //2. 如果CAS失败进入分支,可能再次尝试 if (!casTail(t, last)) { t = tail; // 如果last还是队列中唯一的那个next指针为null的节点, // 说明last还是tail if (last.next == null) casTail(t, last); } return true; } // Lost CAS race to another thread; re-read next } else if (p == q)//脱离队列 p = (t != (t = tail)) ? t : head; else//需要移动p p = (p != t && t != (t = tail)) ? t : q; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
首先要明确,即使不设置新tail,队列也是能正确工作的。函数中如果第一次casTail失败,还会进行第二次casTail,这仅仅是一种优化,因为我们可能一次性加了很多节点,让tail更加靠近last node则有利于我们的入队工作,所以进行了第二次尝试。
迭代器
这个迭代器也是弱一致性的,因为放到nextNode的节点,即使之后从队列中被删除(节点的item会变成null),nextItem也会继续维持引用,然后调用next()依旧能返回这个item。
public Iterator<E> iterator() { return new Itr(); } private class Itr implements Iterator<E> { //下一个返回的节点。即使节点放到nextNode后马上被删除,也会返回这个节点 private Node<E> nextNode; //nextNode的item域 private E nextItem; //上一个返回过的节点,用来支持删除操作 private Node<E> lastRet; Itr() { advance();//初始化要保证,nextNode nextItem不为空,如果队列中有live node } //前进迭代器,返回下一个节点,获得下下个节点存起来 private E advance() { lastRet = nextNode; E x = nextItem;//将准备好的nextItem放到局部变量存起来,之后返回用 Node<E> pred, p; if (nextNode == null) {//如果是初始化 p = first(); pred = null; } else {//如果是初始化以后 pred = nextNode; p = succ(nextNode); } for (;;) { if (p == null) {//迭代器遍历到头了,设置nextNode nextItem为null nextNode = null; nextItem = null; return x;//返回之前存起来的局部变量 } E item = p.item; if (item != null) {//确实item不为null nextNode = p; nextItem = item; return x;//返回之前存起来的局部变量 } else { Node<E> next = succ(p);//获得p的后继 if (pred != null && next != null)// 跳过非live node,并断开链接,这和remove方法里一样 pred.casNext(p, next); p = next;// 后移p } } } public boolean hasNext() { return nextNode != null; } public E next() { if (nextNode == null) throw new NoSuchElementException(); return advance(); } public void remove() { Node<E> l = lastRet; if (l == null) throw new IllegalStateException(); // 懒删除,依赖之后的遍历才能真正删除 l.item = null; lastRet = null; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
remove是懒删除的,这可能会造成内存泄漏,除非有另一个迭代器遍历、或者出队时head经过了这个逻辑删除节点。
总结
- ConcurrentLinkedQueue队列中总是有一个dummy node,这避免很多不必要的代码。
- 不变式简单的说就是:任意时刻,队列中的有效节点(item域非null)通过next指针是相连的。
- 可变式简单的说就是:
head和tail可能会偏离它们本该指向的位置,即first live node、last node。 - 在CAS方面,通过允许
head tail偏离,尽量减少了CAS这种开销巨大的动作。Node初始化不使用volatile写item域,也是一种优化。 - 即使是单线程环境,
head/tail也是每隔一次出队/入队操作才会更新head/tail。 ConcurrentLinkedQueue#remove和迭代器#remove都有可能造成内存泄漏。

