
- 1了解Docker,容器和更安全的软件交付
- 2二叉树的四种基本遍历方式(C语言)_二叉树中序遍历c语言代码
- 3【Unity3D】 Unity Chan项目分享
- 4【C++】ROS:navigation导航模块学习与算法示例_ros 3d导航
- 5手把手教你轻松本地部署Llama3和私有知识库_llama3 本地知识库
- 6傅里叶变换的矩阵分析_傅里叶变换矩阵
- 7我的实习经历_大学英语记叙文 我的实习经历
- 8Redisson—分布式锁框架_redisson框架
- 9使用Python在Ubuntu14.04上部署Hadoop2.7.7_hadoop2.7.7对应的python hdfs库版本
- 10用python实现KNN算法_python knn
大模型语言模型:从理论到实践_大规模语言模型:从理论到实践
赞
踩
大模型语言模型:从理论到实践
- [一、资源获取链接]
- [二、概念整理]
-
- [定义]
- [发展历程]
- [大模型的基本构成]
一、资源获取链接
 [](https://blog.csdn.net/weixin_44597347/article/details/135368383)二、概念整理 -------------------------------------------------------------------------
[](https://blog.csdn.net/weixin_44597347/article/details/135368383)二、概念整理 -------------------------------------------------------------------------
定义
大规模语言模型(Large Language Models,LLM),也称大语言模型或大型语言模型,是一种由包含数百亿以上参数的深度神经网络构建的语言模型,通常使用自监督学习方法通过大量无标注文本进行训练。
自2018年以来,Google、OpenAI、Meta、百度、华为等公司和研究机构都相继发布了包括BERT,GPT等在内多种模型,并在几乎所有自然语言处理任务中都表现出色。2019年大模型呈现爆发式的增长,特别是2022年11月ChatGPT(Chat Generative Pre-trained Transformer)发布后,更是引起了全世界的广泛关注。用户可以使用自然语言与系统交互,从而实现包括问答、分类、摘要、翻译、聊天等从理解到生成的各种任务。大规模语言模型展现出了强大的对世界知识掌握和对语言的理解能力。
深度神经网络训练需要采用有监督方法,使用标注数据进行训练,因此,语言模型的训练过程也不可避免需要构造训练语料。
但是由于训练目标可以通过无标注文本直接获得,从而使得模型的训练仅需要大规模无标注文本即可。语言模型也成为了典型的自监督学习(Self-supervised Learning)任务。
互联网的发展,使得大规模文本非常容易获取,因此训练超大规模的基于神经网络的语言模型也成为了可能。
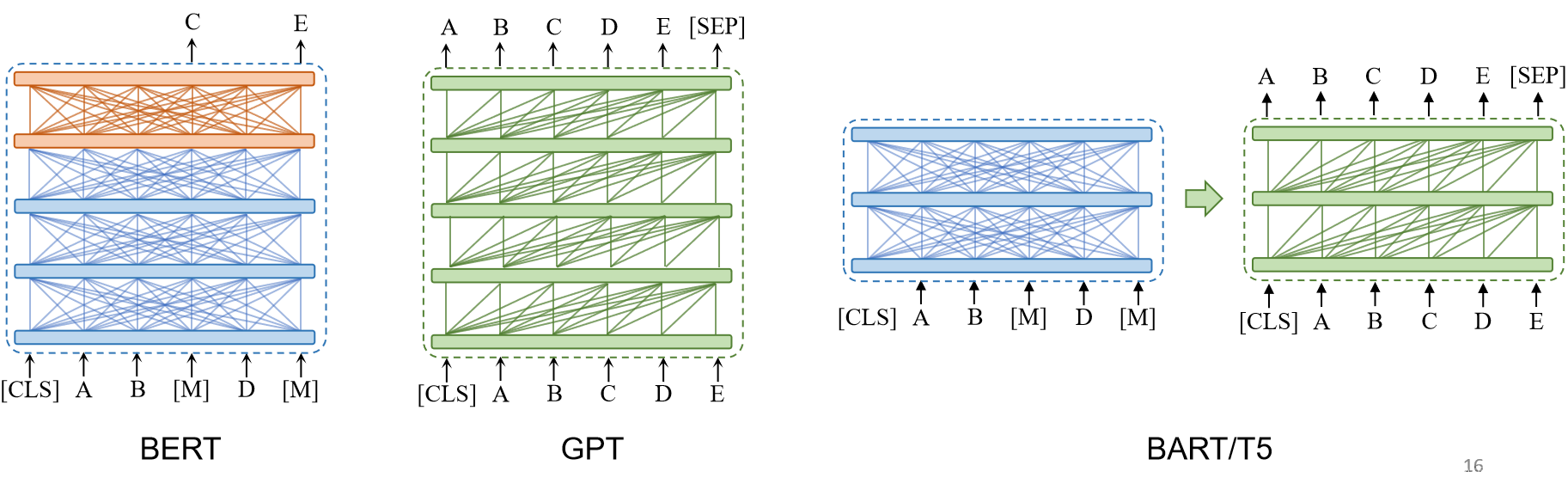
以ELMo为代表的动态词向量模型开启了语言模型预训练的大门。此后,以GPT和BERT为代表的基于Transformer 架构的大规模预训练语言模型的出现,使自然语言处理全面进入预训练微调范式新时代。这类方法通常称为预训练语言模型(Pre-trained Language Models,PLM)。
2020 年,OpenAI 发布了由包含1750 亿参数的神经网络构成的生成式大规模预训练语言模型GPT-3(Generative Pre-trained Transformer 3)。开启了大语言模型的新时代。在不同任务上都进行微调需要消耗大量的计算资源,因此预训练微调范式不再适用于大语言模型。
通过语境学习(In-Context Learning,ICL)等方法,直接使用大语言模型就可以在很多任务的少样本场景下取得很好的效果。此后,研究人员提出了面向大语言模型的提示词(Prompt)学习方法、模型即服务范式(Model as a Service,MaaS)、指令微调(Instruction Tuning)等方法。
发展历程
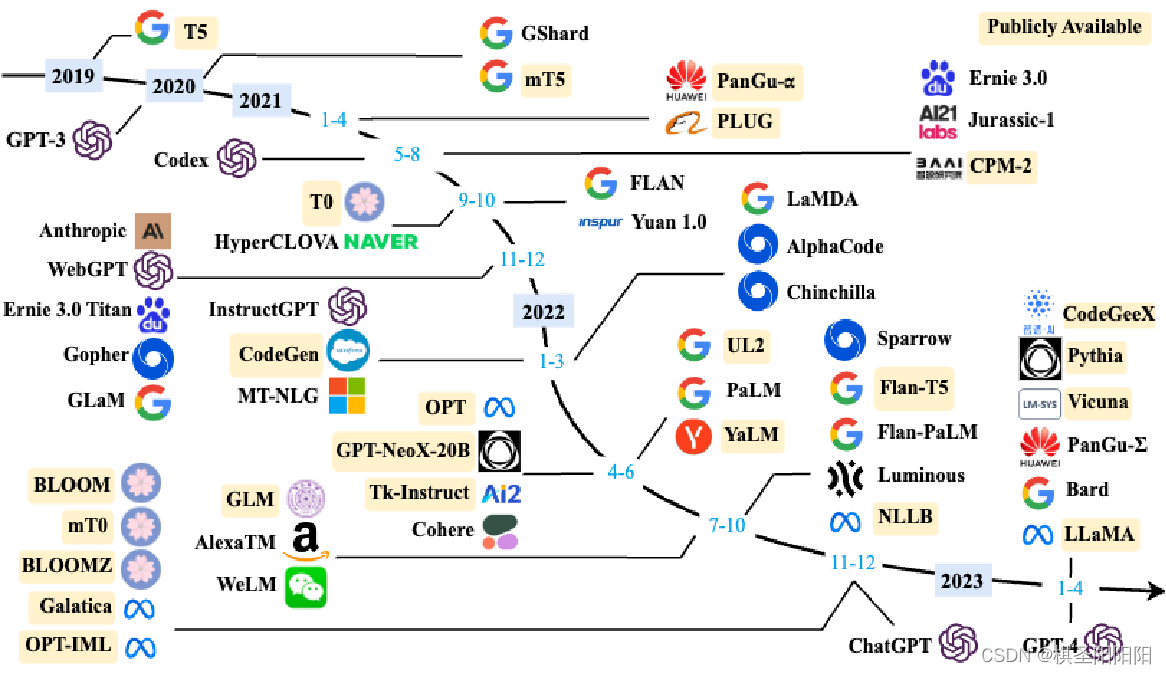
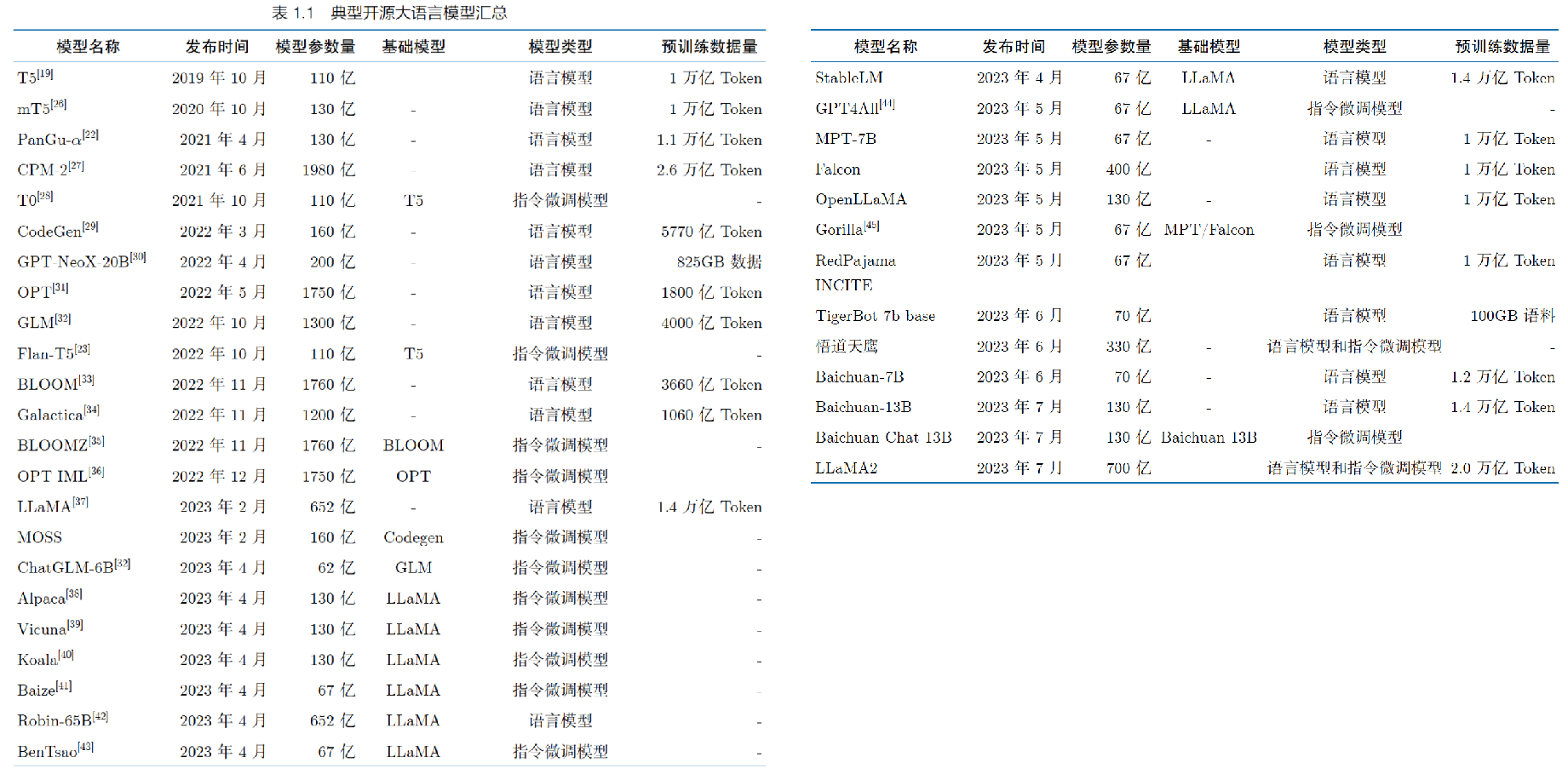
大语言模型的发展历程虽然只有短短不到五年,但是发展速度相当惊人,截止2023 年6 月,国内外有超过百种大模型相继发布。

大模型的基本构成
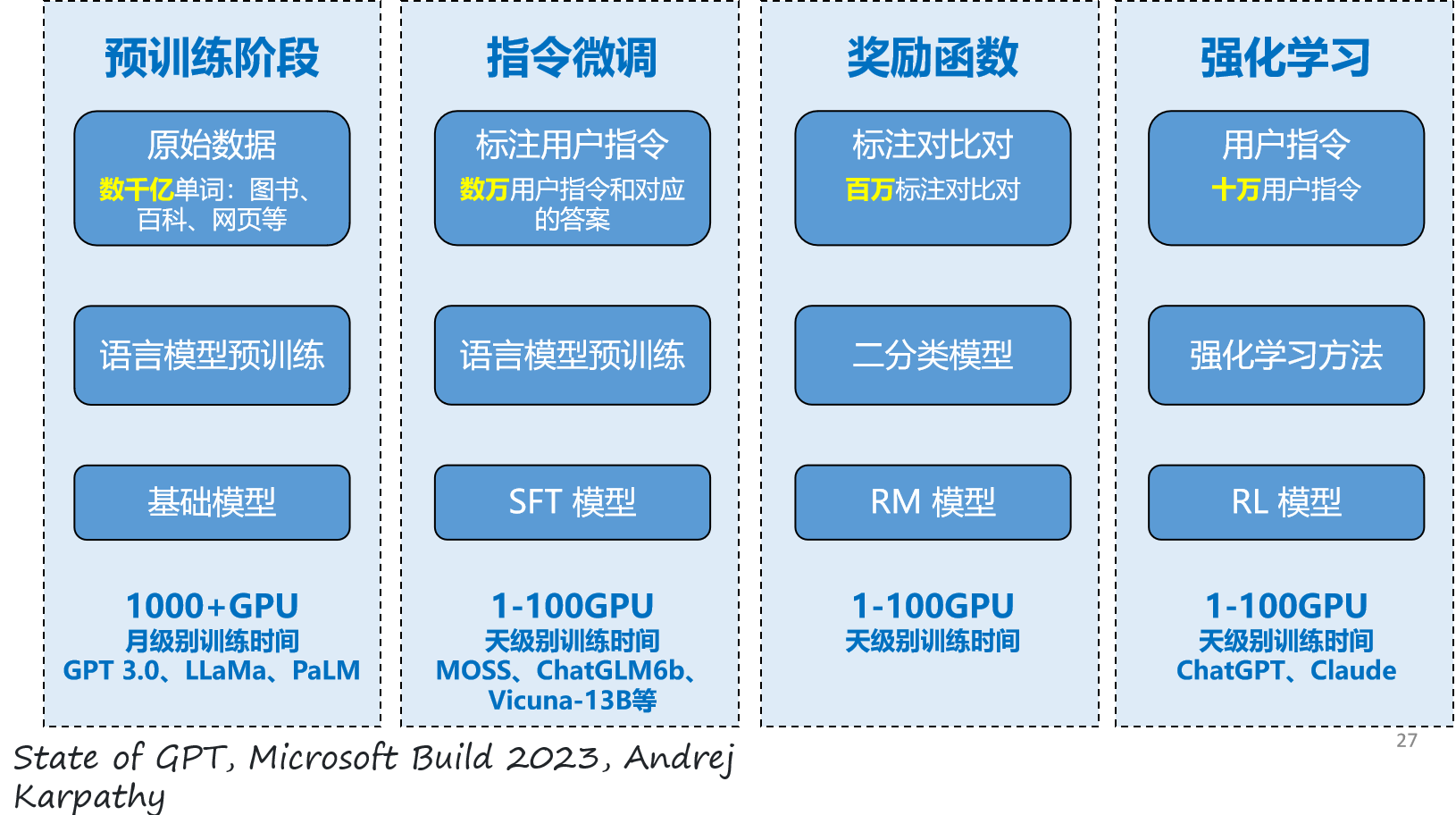
预训练(Pretraining)阶段需要利用海量的训练数据,数据来自互联网网页、维基百科、书籍、GitHub、论文、问答网站等,构建包含数千亿甚至数万亿单词的具有多样性的内容。
利用由数千块高性能GPU 和高速网络组成超级计算机,花费数十天完成深度神经网络参数训练,构建基础语言模型(Base Model)
有监督微调(Supervised Finetuning),也称为指令微调,利用少量高质量数据集合,包含用户输入的提示词和对应的理想输出结果。用户输入包括问题、闲聊对话、任务指令等多种形式和任务。
利用这些有监督数据,使用与预训练阶段相同的语言模型训练算法,在基础语言模型的基础上进行训练,得到有监督微调模型(SFT 模型)。
经过训练的SFT 模型具备初步的指令理解能力和上下文理解能力,能够完成开放领域问答、阅读理解、翻译、生成代码等任务,也具备了一定的对未知任务的泛化能力。
很多类ChatGPT的模型都属于该类型,包括Alpaca、Vicuna、MOSS、ChatGLM-6B 等。很多这类模型的效果非常好,甚至在一些评测中达到了ChatGPT 的90% 的效果。
奖励建模(Reward Modeling)阶段的目标是构建一个文本质量对比模型,对于同一个提示词,SFT 模型给出的多个不同输出结果的质量进行排序。奖励模型(RM 模型)可以通过二分类模型,对输入的两个结果之间的优劣进行判断。RM 模型与基础语言模型和SFT 模型不同,RM 模型本身并不能单独提供给用户使用。
奖励模型的训练通常和SFT 模型一样,使用数十块GPU,通过几天时间完成训练。由于RM 模型的准确率对强化学习阶段的效果有至关重要的影响,因此通常需要大规模的训练数据对该模型进行训练。
强化学习(Reinforcement Learning)阶段根据数十万用户给出的提示词,利用前一阶段训练的RM模型,给出SFT模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。
使用强化学习,在SFT 模型基础上调整参数,使得最终生成的文本可以获得更高的奖励(Reward)。该阶段需要的计算量相较预训练阶段也少很多,通常仅需要数十块GPU,数天即可完成训练。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/725510

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

