
- 1产品Axure的元组件以及案例_axure组件
- 2OpenCV图像处理技术之图像直方图_equr
- 3YOLO-World_yolo world
- 4微信支付 —— 公众号支付代码详解_nansystem:access_denied
- 5ubuntu安装完tensorrt后在conda虚拟环境调用_conda env no module named 'tensorrt
- 6NLP 自然语言处理实战_nlp项目实战
- 7重新认识快手:人工智能的从 0 到 1
- 8优化篇--vxe-table 大数据表格替代方案_vxetable性能
- 9CSS之margin塌陷问题_css margin塌陷
- 10【物联网天线选择攻略】2.4GHz 频段增益天线模块设备选择_物联网模块一定要有天线吗
微软AIGC in a Day-探索人工智能与行业应用实践沙龙-参后感
赞
踩
先来看下宣传海报

活动介绍总结
- 活动主题: 探索人工智能与行业应用实践沙龙
微软 Power Platform 携手 GPT,从应用层面深入 AI + 低代码开发,一场探索人工智能与行业应用实践的技术盛宴即将到来!
9月16日, 「探索人工智能与行业应用实践沙龙」 ,数位来自 AI、低代码领域的技术专家,将通过**
技术分享、案例实操等形式,带来 AI + 低代码开发的最新技术动态与实践技巧,学习如何利用GPT技术提升应用开发效率与用户体验**,共同探索低代码开发的无限潜力!
该活动分为2个会场:
- A会场从早上10点到下午5点半将会由众多大佬们一直以分享的形式来讲述技术等;
- B会场从下午1点30到5点30为Microsoft & NVIDIA 动手工作坊,由两位大佬带着动手操作体验AIGC;
参后感
由于是第一次到上海-Microsoft,我一不小心跟着导航走到了Microsoft的后门,当时还纳闷,该怎么进去呢.等了几分钟,一个打扫卫生的阿姨过来了,就跟着她进去了.

其实是有一个前门的,而且前门有签到的等等.

前门就很好玩了,打开拍照,签到,送东西都有.

跟随者箭头的指示,就走到了A会场

我提前半个多小时就到了,结果工作人员还在调试中.

A会场记录
因为分享的内容太多了,重点也很多,这里只写一些个人认为关键的部分
后GPT时代:Prompt即代码:
- GPT-1: GPT-1是第一次使用预训练方法来实现高效语言理解的训练;
- GPT-2: GPT-2采用迁移学习技术,在多种任务中应用预训练信息,提高语言理解能力;
- DALL.E: DALL.E是走到另一个模态;
- GPT-3: GPT-3主要注重泛化能力,few-shot (小样本)的泛化;
- GPT-3.5: GPT-3.5-instruction following (指令遵循)和tuning (微调)是最大突破;
- GPT-4: 已经开始实现工程化
- Plugin: 2023年3月的Plugin是生态化(初阶);;
- Function: 2023年6月的Function Calling是生态化(进阶) , Prompt即代码;
人机协同三范式:
- Embedding 嵌入模式:人类和AI写作工作
- Co-pilot 副驾驶模式:人类完成绝大部分工作
- AI Agents 自主代理模式:AI完成绝大部分工作
LLM的最大问题:
问题: 当前,LLM的最大问题就是缺乏最新的知识和特定领域的知识.
方案:对于这一问题,业界有两种主要解决方法:微调和检索增强生成.
大模型微调技术路线:
- 全量微调FFT(Full Fine Tuning)
- 有效参数微调PEFT(Parameter-Efficient Fine Tuning) [常用的是这种方式]
有效参数微调PEFT(Parameter-Efficient Fine Tuning):
1.Prompt Tuning
基座模型的参数不变,为每个特定任务,训练一个少量参数的小模型,在具体执行特定任务的时候按需求调用;
2.Prefix Tuning
在不改变大模型的前提下,在Prompt上下文中添加适当的条件,可以引导大模型有更加出色的表现.
3.LoRA
假设: 我们现在看到的这些大语言模型,它们都是被过度参数化的.而过度参数化的背后,都有一个低维的本质模型.适配特定的下游任务,要训练一个特定的模型.
4.QloRA
QLoRA就是量化版的LoRA,它是在LoRA的基础上,进行了进一步量化,将原本用16bit表示的参数,降低为4bit来表示,可以在保证模型效果的他偶那是个好i,极大的降低成本.
比较有意思的是 RAG和FT的对比:
-
RAG:这种方法将检索(或搜索)的能力集成到LLM文本生成中。它结合了检索系统(从大型语料库中获取相关文档片段)和LLM(使用这些片段中的信息生成答案)。 本质上, RAG帮助模型"查找”外部信息以改进其响应。
-
微调:这是采用预训练的LLM并在较小的特定数据集上进一步训练它以使其适应特定任务或提高其性能的过程。通过调优,我们根据数据调整模型的权重,使其更适合应用程序的独特需求。
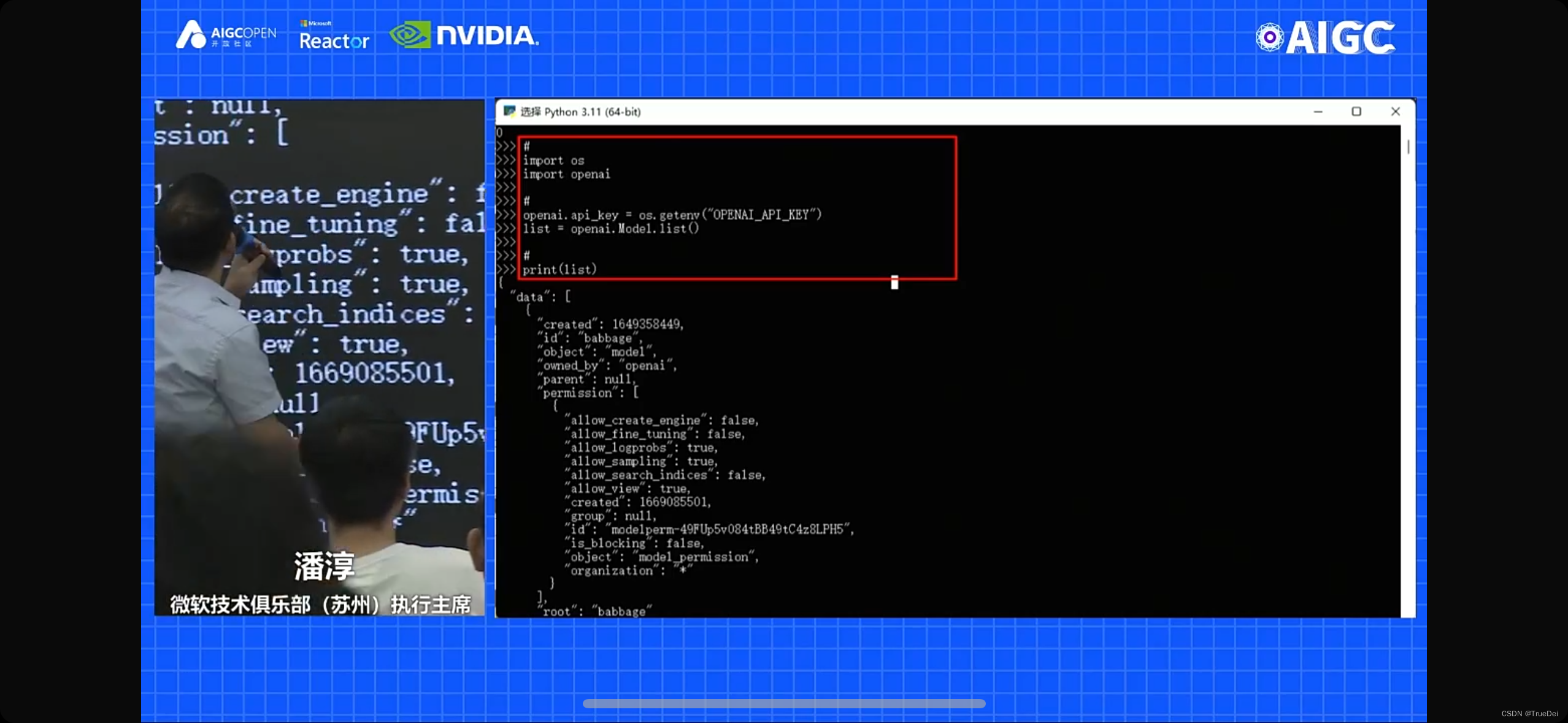
还分享了一个开发技巧,可以把OPENAI的key设置为一个环境变量,然后在代码中调用:
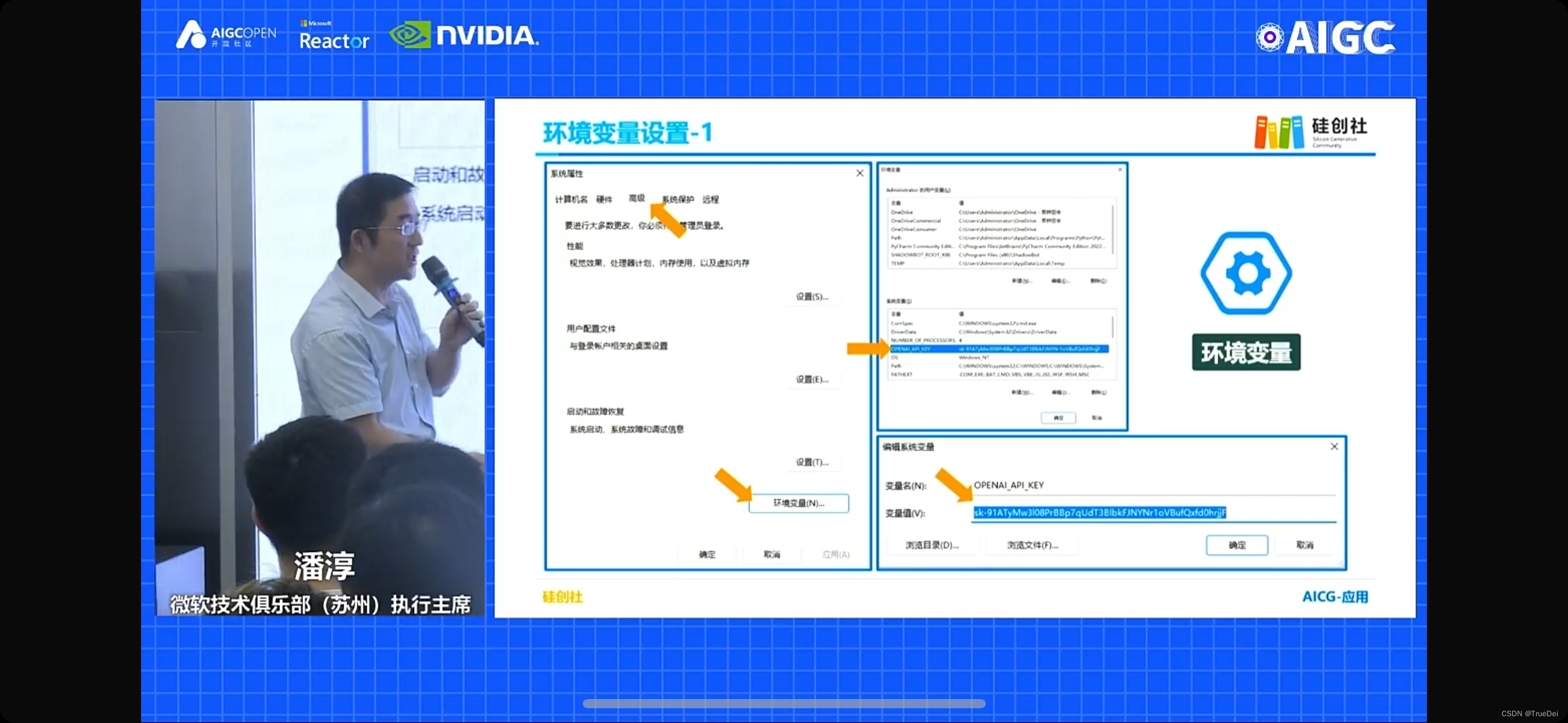
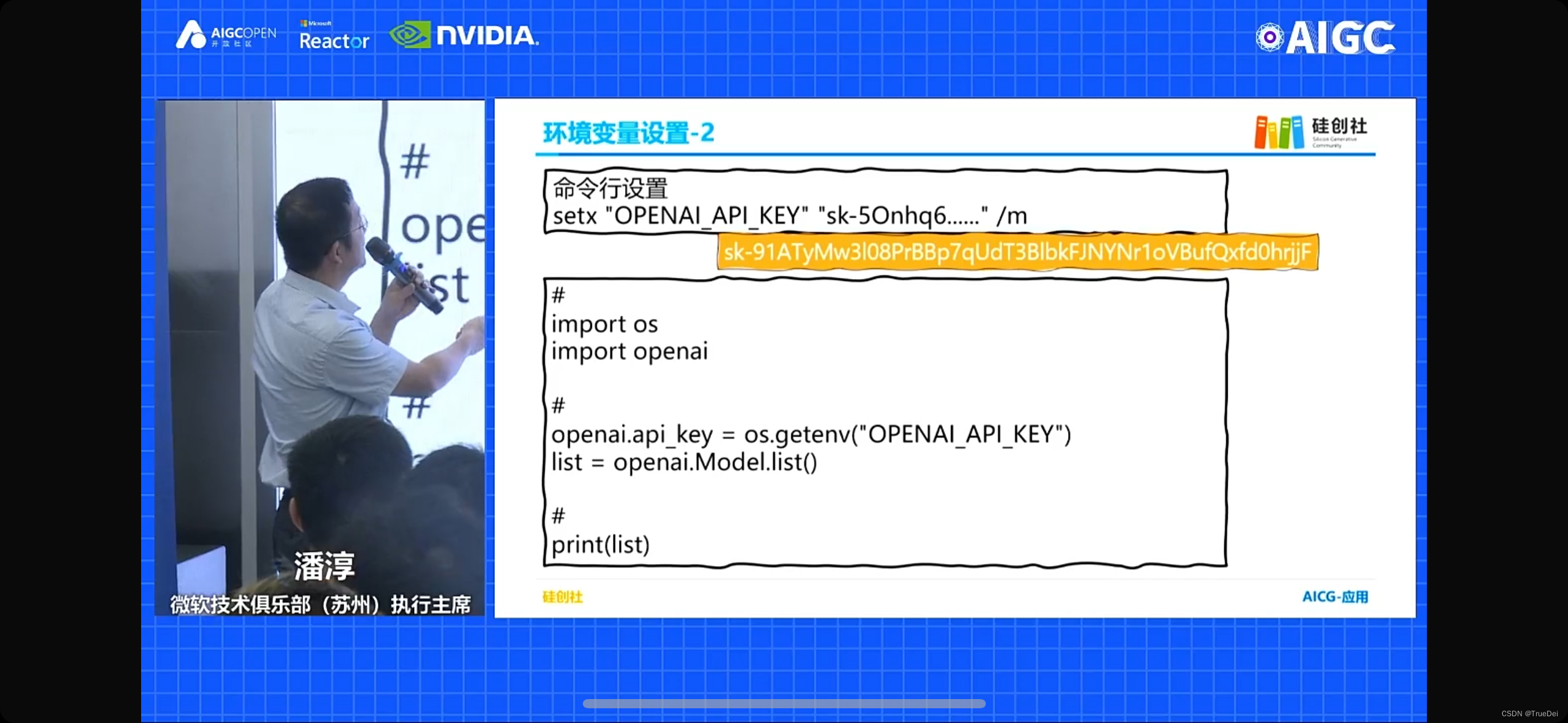
这样开发效率也会提高
AIGC技术分类
AIGC技术分类:
- 文本:总结、问答、内容补齐;
- 图像:图像编辑、生成图像,尤其是Al绘图;
- 音频:语音文本的互转,以及模仿和自动生成;
- 视频:生成、模仿、剪辑、后处理;
- 编程:生成代码、调测Bug、提示解答;
- 聊天机器人:自动化智能客服;
- 学习平台:提供算力、环境、模型框架的平台或生态;
- 搜索:进一步的提炼,和更广的自动撒网;
- 游戏:插画设计、人物原型生成,让进入门槛更低;
- 数据:结构设计、原始收集、总结提炼和发现规律;
- 垂直行业:医疗、工程、法律、教育、个体创业等;
AIGC成为金融文案工作的特级助手:
- 新书序言
- 合作方案
- 业务通知
- 调研提纲
- 活动宣传
- 考试题目
哪类人可以使用的比较好
内容生成
- 银行文案工作
- 呼叫&客服等中心 客户的问题,自动生成回复
- 为网站生成个性化的UI
总结能力
- 客服:客户对话日志的总结
- 财务报告,分析师文章等
- 舆情监控类,社交媒体,趋势总结
代码生成
- 自然语言和SQL互换
- 代码注释
- 文档
- 简单逻辑性问题
- 语法BUG
语义检索
- 搜索特定产品服务的评论
- 信息发展&知识挖掘

