
- 1CSS 颜色代码_css浅蓝色
- 2shardingsphere 集成springboot【水平分表】
- 3Android WebView调用系统相册和相机,注入以及与H5的交互_webview 增加打开相机相册交互
- 4有关windows10修改C盘用户中文名文件夹相关问题的具体解决方案_win10修改c盘下用户的文件夹名会出问题吗
- 5关于UE4打包问题_编译模式_实例1_ue4打包后效果不一样
- 6uniapp+vue微信小程序的 健身房预约系统_uniapp 热量数据
- 7OpenSSL/GMSSL EVP接口说明——3.5 加密解密_evp_pkey_ctx_set_ec_sign_type( pkctx, nid_sm_schem
- 82023最新玩客云刷机armbian,部署docker并配置各种常用容器镜像_玩客云 armbian
- 9Unity接入Steam平台详细流程一_steammanager获取名字
- 10十五、进程&线程&协程_pool.map 怎么等待主线程执行完
人工智能常见算法简介_ai算法需要写啥
赞
踩
人工智能的三大基石—算法、数据和计算能力,算法作为其中之一,是非常重要的,那么人工智能都会涉及哪些算法呢?不同算法适用于哪些场景呢?
一、按照模型训练方式不同可以分为:
- 监督学习(Supervised Learning)
- 无监督学习(Unsupervised Learning)
- 半监督学习(Semi-supervised Learning)
- 强化学习(Reinforcement Learning)
常见的监督学习算法包含以下几类:
1.人工神经网络(Artificial Neural Network)类:
- 反向传播(Backpropagation)
- 波尔兹曼机(Boltzmann Machine)
- 卷积神经网络(Convolutional Neural Network)
- Hopfield网络(hopfield Network)
- 多层感知器(Multilyer Perceptron)
- 径向基函数网络(Radial Basis Function Network,RBFN)
- 受限波尔兹曼机(Restricted Boltzmann Machine)
- 回归神经网络(Recurrent Neural Network,RNN)
- 自组织映射(Self-organizing Map,SOM)
- 尖峰神经网络(Spiking Neural Network)
- … …
2.贝叶斯类(Bayesin):
- 朴素贝叶斯(Naive Bayes)
- 高斯贝叶斯(Gaussian Naive Bayes)
- 多项朴素贝叶斯(Multinomial Naive Bayes)
- 平均-依赖性评估(Averaged One-Dependence Estimators,AODE)
- 贝叶斯信念网络(Bayesian Belief Network,BBN)
- 贝叶斯网络(Bayesian Network,BN)
- … …
3.决策树(Decision Tree)类:
- 分类和回归树(Classification and Regression Tree,CART)
- 迭代Dichotomiser3(Iterative Dichotomiser 3, ID3)
- C4.5算法(C4.5 Algorithm)
- C5.0算法(C5.0 Algorithm)
- 卡方自动交互检测(Chi-squared Automatic Interaction Detection,CHAID)
- 决策残端(Decision Stump)
- ID3算法(ID3 Algorithm)
- 随机森林(Random Forest)
- SLIQ(Supervised Learning in Quest)
- … …
4.线性分类器(Linear Classifier)类:
- Fisher的线性判别(Fisher’s Linear Discriminant)
- 线性回归(Linear Regression)
- 逻辑回归(Logistic Regression)
- 多项逻辑回归(Multionmial Logistic Regression)
- 朴素贝叶斯分类器(Naive Bayes Classifier)
- 感知(Perception)
- 支持向量机(Support Vector Machine)
- … …
常见的无监督学习类算法包括:
1.人工神经网络(Artificial Neural Network)类:
- 生成对抗网络(Generative Adversarial Networks,GAN)
- 前馈神经网络(Feedforward Neural Network)
- 逻辑学习机(Logic Learning Machine)
- 自组织映射(Self-organizing Map)
- … …
2.关联规则学习(Association Rule Learning)类:
- 先验算法(Apriori Algorithm)
- Eclat算法(Eclat Algorithm)
- FP-Growth算法
- … …
3.分层聚类算法(Hierarchical Clustering):
- 单连锁聚类(Single-linkage Clustering)
- 概念聚类(Conceptual Clustering)
- … …
4.聚类分析(Cluster analysis):
- BIRCH算法
- DBSCAN算法
- 期望最大化(Expectation-maximization,EM)
- 模糊聚类(Fuzzy Clustering)
- K-means算法
- K均值聚类(K-means Clustering)
- K-medians聚类
- 均值漂移算法(Mean-shift)
- OPTICS算法
- … …
5.异常检测(Anomaly detection)类:
- K最邻近(K-nearest Neighbor,KNN)算法
- 局部异常因子算法(Local Outlier Factor,LOF)
- … …
常见的半监督学习类算法包含:
- 生成模型(Generative Models)
- 低密度分离(Low-density Separation)
- 基于图形的方法(Graph-based Methods)
- 联合训练(Co-training)
- … …
常见的强化学习类算法包含:
- Q学习(Q-learning)
- 状态-行动-奖励-状态-行动(State-Action-Reward-State-Action,SARSA)
- DQN(Deep Q Network)
- 策略梯度算法(Policy Gradients)
- 基于模型强化学习(Model Based RL)
- 时序差分学习(Temporal Different Learning)
- … …
常见的深度学习类算法包含:
- 深度信念网络(Deep Belief Machines)
- 深度卷积神经网络(Deep Convolutional Neural Networks)
- 深度递归神经网络(Deep Recurrent Neural Network)
- 分层时间记忆(Hierarchical Temporal Memory,HTM)
- 深度波尔兹曼机(Deep Boltzmann Machine,DBM)
- 栈式自动编码器(Stacked Autoencoder)
- 生成对抗网络(Generative Adversarial Networks)
- … …
二、按照解决任务的不同来分类
粗略可以分5种为:
- 二分类算法(Two-class Classification)
- 多分类算法(Multi-class Classification)
- 回归算法(Regression)
- 聚类算法(Clustering)
- 异常检测(Anomaly Detection)
1.二分类(Two-class Classification)
(1)二分类支持向量机(Two-class SVM):适用于数据特征较多、线性模型的场景。
(2)二分类平均感知器(Two-class Average Perceptron):适用于训练时间短、线性模型的场景。
(3)二分类逻辑回归(Two-class Logistic Regression):适用于训练时间短、线性模型的场景。
(4)二分类贝叶斯点机(Two-class Bayes Point Machine):适用于训练时间短、线性模型的场景。(5)二分类决策森林(Two-class Decision Forest):适用于训练时间短、精准的场景。
(6)二分类提升决策树(Two-class Boosted Decision Tree):适用于训练时间短、精准度高、内存占用量大的场景
(7)二分类决策丛林(Two-class Decision Jungle):适用于训练时间短、精确度高、内存占用量小的场景。
(8)二分类局部深度支持向量机(Two-class Locally Deep SVM):适用于数据特征较多的场景。
(9)二分类神经网络(Two-class Neural Network):适用于精准度高、训练时间较长的场景。
2.多分类(Multi-class Classification)
解决多分类问题通常适用三种解决方案:
第一种,从数据集和适用方法入手,利用二分类器解决多分类问题;
第二种,直接使用具备多分类能力的多分类器;
第三种,将二分类器改进成为多分类器今儿解决多分类问题。
常用的算法:
(1)多分类逻辑回归(Multiclass Logistic Regression):适用训练时间短、线性模型的场景。
(2)多分类神经网络(Multiclass Neural Network):适用于精准度高、训练时间较长的场景。
(3)多分类决策森林(Multiclass Decision Forest):适用于精准度高,训练时间短的场景。
(4)多分类决策丛林(Multiclass Decision Jungle):适用于精准度高,内存占用较小的场景。
(5)“一对多”多分类(One-vs-all Multiclass):取决于二分类器效果。
3.回归(Regression)
回归问题通常被用来预测具体的数值而非分类。除了返回的结果不同,其他方法与分类问题类似。我们将定量输出,或者连续变量预测称为回归;将定性输出,或者离散变量预测称为分类。常见的算法有:
(1)排序回归(Ordinal Regression):适用于对数据进行分类排序的场景。
(2)泊松回归(Poission Regression):适用于预测事件次数的场景。
(3)快速森林分位数回归(Fast Forest Quantile Regression):适用于预测分布的场景。
(4)线性回归(Linear Regression):适用于训练时间短、线性模型的场景。
(5)贝叶斯线性回归(Bayesian Linear Regression):适用于线性模型,训练数据量较少的场景。
(6)神经网络回归(Neural Network Regression):适用于精准度高、训练时间较长的场景。
(7)决策森林回归(Decision Forest Regression):适用于精准度高、训练时间短的场景。
(8)提升决策树回归(Boosted Decision Tree Regression):适用于精确度高、训练时间短、内存占用较大的场景。
4.聚类算法(Clustering)
聚类的目标是发现数据的潜在规律和结构。聚类通常被用做描述和衡量不同数据源间的相似性,并把数据源分类到不同的簇中。
(1)层次聚类(Hierarchical Clustering):适用于训练时间短、大数据量的场景。
(2)K-means算法:适用于精准度高、训练时间短的场景。
(3)模糊聚类FCM算法(Fuzzy C-means,FCM):适用于精确度高、训练时间短的场景。
(4)SOM神经网络(Self-organizing Feature Map,SOM):适用于运行时间较长的场景。
5.异常检测(Anomaly Detection)
异常检测是指对数据中存在的不正常或非典型的分体进行检测和标志,有时也称为偏差检测。
异常检测看起来和监督学习问题非常相似,都是分类问题。都是对样本的标签进行预测和判断,但是实际上两者的区别非常大,因为异常检测中的正样本(异常点)非常小。常用的算法有:
(1)一分类支持向量机(One-class SVM):适用于数据特征较多的场景。
(2)基于PCA的异常检测(PCA-based Anomaly Detection):适用于训练时间短的场景。
常见的迁移学习类算法包含:
- 归纳式迁移学习(Inductive Transfer Learning)
- 直推式迁移学习(Transductive Transfer Learning)
- 无监督式迁移学习(Unsupervised Transfer Learning)
- 传递式迁移学习(Transitive Transfer Learning)
- … …
三、算法的适用场景:
需要考虑的因素有:
(1)数据量的大小、数据质量和数据本身的特点
(2)机器学习要解决的具体业务场景中问题的本质是什么?
(3)可以接受的计算时间是什么?
(4)算法精度要求有多高?
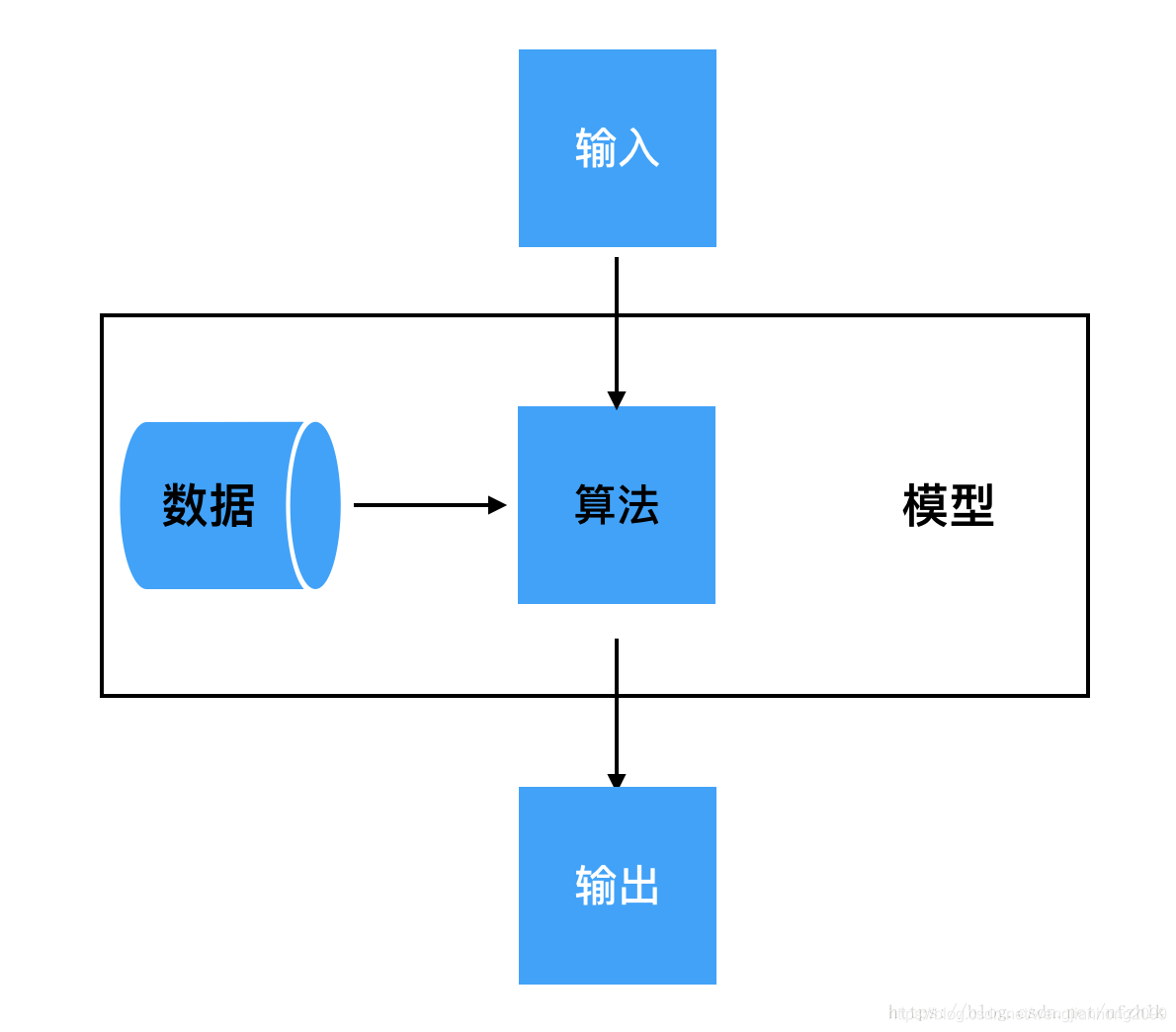
有了算法,有了被训练的数据(经过预处理过的数据),那么多次训练(考验计算能力的时候到了)后,经过模型评估和算法人员调参后,会获得训练模型。当新的数据输入后,那么我们的训练模型就会给出结果。业务要求的最基础的功能就算实现了。
互联网产品自动化运维是趋势,因为互联网需要快速响应的特性,决定了我们对问题要快速响应、快速修复。人工智能产品也不例外。AI + 自动化运维是如何工作的呢?
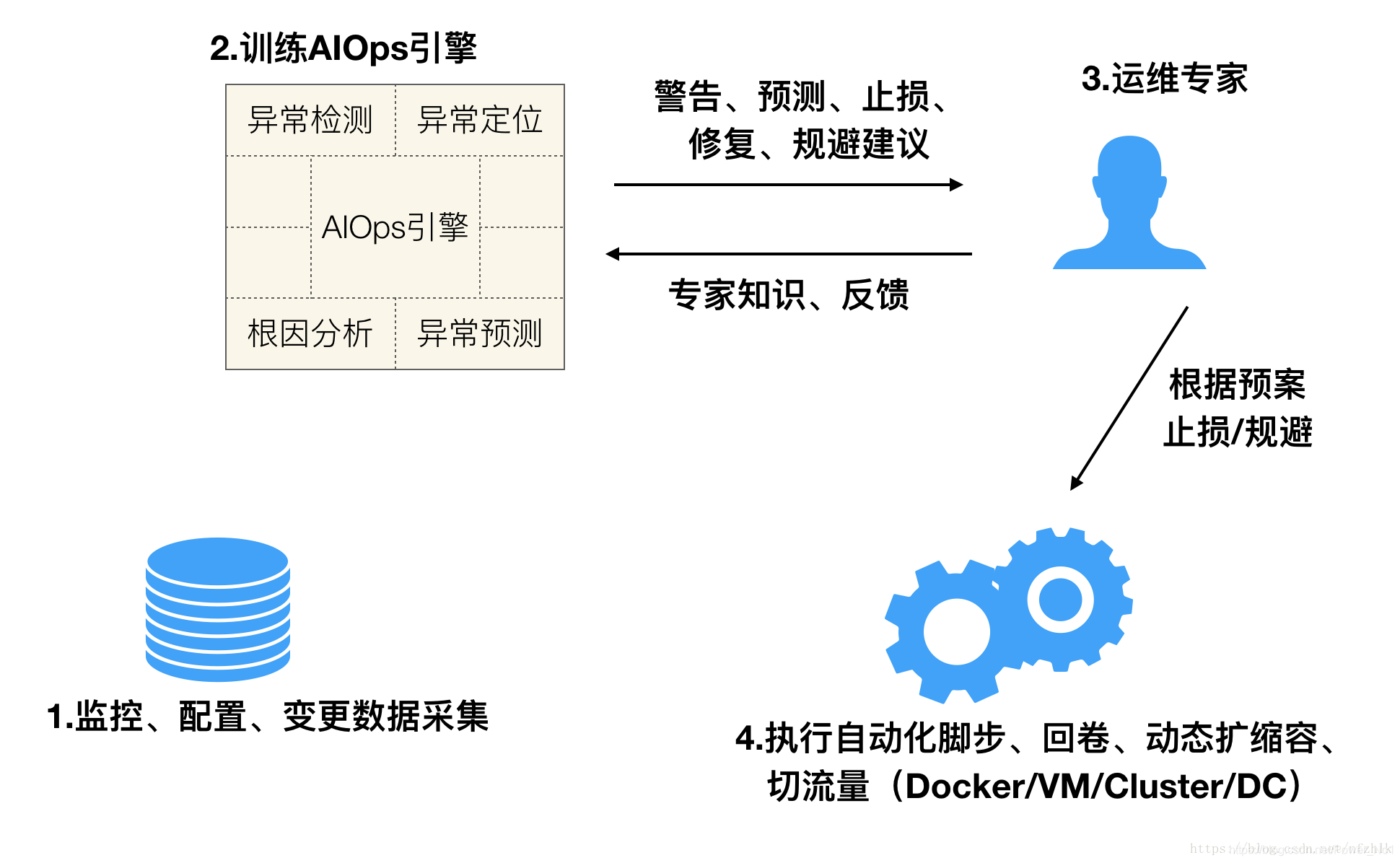
参考:《人工智能产品经理–AI时代PM修炼手册》
作者:张竞宇
————————————————
版权声明:本文为CSDN博主「nfzhlk」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/nfzhlk/article/details/82725769

