
- 1gitlab配置ssh自用精简步骤_gitlab查看ssh配置
- 2ssh内网穿透失败_usr/bin/ssh-copy-id: error: ssh: connect to host 1
- 3教程|幻兽帕鲁服务器数据备份与恢复_帕鲁 linux
- 410种常用的分析模型 数据分析必看
- 5ssh localhost免密登录
- 6anaconda_conda init bash
- 73 python pandas_python3 pandas
- 8美狐讲堂:视频用直播用SDK盘点_aliplayer和ijkplayer
- 9DHCP自动获取IP地址实验(思科)
- 10Pycharm踩坑路_win11无法启动pychar2023
【Logback】Logback 日志框架的架构
赞
踩
目录
目前,logback 分为三个模块,logback-core、logback-classic 和 logback-access。
logback-core (核心)模块为其他两个模块奠定了基础。
logback-classic 模块扩展了 logback-core。logback-classic 模块是 log4j 日志的改进版本。logback-classic 模块实现了 slf4j API,因此使用 slf4j API 时,可以轻松地在 logback 和其他日志框架之间来回切换(例如 JDK 1.4 中引入的 log4j 或 java.util.logging(JUL))。//核心+核心拓展
logback-access 模块用于与 Servlet 容器集成,用来提供 HTTP-access 日志功能。logback-access 不能安装在 Web 应用程序级别,而是必须安装在容器级别。在 Web 应用程序级别捆绑 logback-access.jar 没有任何意义。//logback-access 模块内容暂时不进行过多深入,后续有时间再探讨
在这篇文章中,介绍的 logback 指的都是 logback-classic 模块的内容。
logback 有三个主要的类:Logger、Appender 和 Layout。
这三中类型的组件协同工作,可以使开发人员能够根据日志级别记录日志(Logger),并在运行时控制这些日志的输出位置(Appender)和输出格式(Layout)。
Logger 类是 logback-classic 模块的一部分。Appender 和 Layout 接口是 logback-core 的一部分。logback-core 作为一个通用模块,并没有记录器(Logger)的概念。//需要明确各个组件之间的包关系,核心只有通用功能,ogback-classic 是对核心的拓展
1、Logger(记录器)
与普通 System.out.println 相比,Logger(记录器) 的优势在于它能够禁用某些日志语句,同时还不阻碍其他日志语句地打印。//简单的来说,就是Logger可以对日志消息进行分类打印,即日志分级
所有的 Logger(记录器) ,都统一放置在记录器容器(LoggerContext)中,LoggerContext 负责生成 Logger 并对这些 Logger 按一定的层次进行树状排列。
什么?记录器是有层次(顺序)的吗?
是的,你没有看错,记录器的层次与记录器的命名有关,它的层次划分的标识用的是 “.”。比如,名为 “com.foo” 的 Logger 是名为 “com.foo.Bar” 的 Logger 的父级 Logger。这就像命名为 “java” 的包既是 “java.util” 的父级包,也是 “java.util.Vector” 的父级包一样。
为什么要对记录器进行分层呢?
这个是有好处的,可以非常方便的支持 Logger 的日志级别和附加器的继承,这部分内容将在后边详细说明。
对于按层次进行树状排列,我们可以第一时间想到的就是 Linux 的目录结构,在 Linux 中所有目录都是从根目录开始的。类似的,那么在 LoggerContext 中也一定有一个根记录器。
没错,logback 中的根记录器就是位于所有记录器层次结构的顶层,它是所有记录器的父级记录器,我们可以通过名称来获取这个根记录器,代码如下所示:
Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME);(1)有效级别和级别继承
记录器可以被分配级别,比如在 ch.qos.logback.classic.Level 类中就定义了 TRACE、DEBUG、INFO、WARN 和 ERROR 这五种级别。
此外,在 logback 中,还有一种用于对日志事件进行标记或分类的机制:Marker。它允许你对特定的日志事件添加额外的信息,以便在日志输出时更好地组织和过滤日志。//简单提一下,日常开发用得不多
刚才说到,logback 中的记录器是分层的。所以,如果给定的记录器没有分配级别,那么它就会从其最接近的父级记录器那里继承它的级别。//级别继承规则
因此,为了确保所有记录器最终都能指定继承级别,根记录器始终具有指定的级别。默认情况下,该级别为 DEBUG。//现在知道了吧,logback 的默认日志级别debug就是从这里来的
指定级别以及根据级别继承规则生成的有效级别的示例如下:

在上面的示例中,记录器 root、X 和 X.Y.Z 分别被分配级别 DEBUG、INFO 和 ERROR。 Logger X.Y 从其父级记录器 X 继承其级别值。
(2)日志打印和日志筛选
打印方法决定了请求进行日志记录的级别。例如,如果 Logger 是记录器实例,则语句 Logger.info("..") 就是 INFO 级别的日志记录语句。
如果日志请求的级别高于或等于该记录器的有效级别,那么该日志请求就是有效的(已启用)。否则,该请求被认为是无效的(被禁用)。//级别启用的规则
这条规则是 logback 的核心。它假定的级别顺序如下://ERROR为最高级别
TRACE < DEBUG < INFO < WARN < ERROR
在下表中,根据日志的筛选规则,产生的行(级别请求)和列(有效级别)的交集对应的布尔值如下://注意,这张表是竖着对比
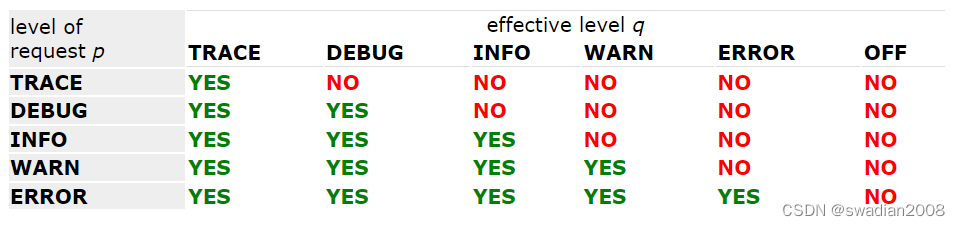
如上表,当 有效级别(q) 为 TRACE 时,所有的 请求打印级别(p) 都是支持的,当 有效级别(q) 为 INFO 时,请求打印级别(p) 为只支持 INFO、WARN 和 ERROR 三个级别,TRACE、DEBUG 级别是不支持的。
(3)记录器命名
使用相同名称调用 LoggerFactory.getLogger 方法,将始终返回完全相同的 Logger 对象的引用。//记录器实例是单例
- Logger x = LoggerFactory.getLogger("log");
- Logger y = LoggerFactory.getLogger("log");
也就是说,上述 x 和 y 引用的是完全相同的记录器对象。因此,当配置一个记录器时,可以在代码中的其他位置获取到相同的实例,而无需传递该记录器的引用。//就好比Spring中可以通过Bean名称从容器中获取Bean实例,该容器是全局可访问的
logback 中的记录器可以随意命名,一般推荐使用类的完全限定名称,因为日志输出带有生成该日志的记录器的名称,所以这种命名策略可以轻松识别到日志消息的来源。示例如下:
- //类的限定名
- private static final Logger loggerByName
- = LoggerFactory.getLogger("self4.Example");
-
- //类.class
- private static final Logger loggerByClass
- = LoggerFactory.getLogger(Example.class);
2、Appenders(追加器)
根据 Logger 的日志级别对日志的记录请求进行筛选,只是 logback 功能中的一部分,除此之外, logback 还允许将日志记录请求打印到多个目的地。
在 logback 中,输出目标称为追加器(Appenders)。目前,控制台、文件、远程套接字服务器、MySQL、PostgreSQL、Oracle 和其他数据库、JMS 和 远程 UNIX Syslog 守护进程 都存在附加器。//在logback中,有很多的附加器可以提供给我们选择,常用的有控制台和文件
一个 Logger 可以添加多个追加器(Appenders)。
使用 ch.qos.logback.classic.Logger 中的 addAppender 方法可以将 Appender 添加到指定的 Logger。所有有效的日志打印请求都会被转发到该 Logger 的 Appender 上,以及从其父级 Logger 中追加的所有的 Appender 上。换句话说,追加器也是可以从父级记录器中追加继承的。//记录器分层的好处
例如,如果将 控制台附追加器(ConsoleAppender) 添加到根记录器,那么所有的子级记录器都会拥有 控制台附追加器(ConsoleAppender) ,而无需额外添加。//默认开启追加器继承行为
如果将记录器的继承性标志设置为 false,那么可以覆盖此默认行为,使该 Appender 不再追加父类记录器的 Appender 。//禁用追加器的继承行为
对 Appender 可继承的规则总结如下:
| 记录器名称 | Attached Appenders 已经附加的追加器 | Additivity Flag 继承性标志 | Output Targets 输出目标 | Comment 备注 |
|---|---|---|---|---|
| root | A1 | 不可用 | A1 | 根记录器位于层结构的顶层,因此可继承性标志不可用 |
| x | A-x1, A-x2 | true | A1, A-x1, A-x2 | Appenders of "x" and of root. |
| x.y | none | true | A1, A-x1, A-x2 | Appenders of "x" and of root. |
| x.y.z | A-xyz1 | true | A1, A-x1, A-x2, A-xyz1 | Appenders of "x.y.z", "x" and of root. |
| security | A-sec | false | A-sec | 可继承标志为false,所以不会继承Appender root.A1,只有Appender A-sec |
| security.access | none | true | A-sec | 因为父类的继承标志为 flase,所以其子类只会继承 Appender security.A-sec, |
3、Layouts(布局)
通常,开发人员不仅希望自定义输出目的地,还希望能够自定义输出格式。在 logback 中自定义输出格式是由 Appender 和 Layouts 进行关联来实现的,这种关联关系在配置中的体现如下:
- <!--Appender-->
- <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
- <encoder>
- <!--Layouts 格式化日志请求-->
- <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
- </encoder>
- </appender>
Layouts 负责根据用户的意愿格式化日志请求,而 Appender 负责将格式化的输出发送到其目的地。 PatternLayout 是标准 logback 发行版的一部分,允许用户根据类似于 C 语言 printf 函数的转换模式指定输出格式。
4、如何避免日志参数构建成本?
logback-classic 中的 Logger 实现了 SLF4J 的 Logger 接口,因此在一个打印方法中,也允许传入多个打印参数。需要注意的是,构造消息参数是有构造成本的,比如下边的代码:
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));这段代码会将整数 i 和 entry[i] 转换为字符串,并连接中间字符串。不管这条消息是不是会被 Logger 记录,都会执行这条消息的参数构造。//试想,如果这样的日志非常多,无疑会影响程序的性能
那么,怎样避免不必要的消息构造成本呢?
一种可取的方法是添加一个 Logger 生效级别的判断,相信你在不少代码中看到过这样的表述:
- if(logger.isDebugEnabled()) {
- logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
- }
这样,如果 Logger 禁用了 DEBUG 级别的日志,上述代码将不会产生参数构造的成本。虽然需要两次判断 Logger 是否支持 DEBUG 级别的日志:一次在 debugEnabled() 中,一次在 debug() 中,但是这种开销是微不足道的,因为判断 Logger 所花费的时间不到实际记录请求所需时间的 1%。//多次判断的性能开销非常小
此外,logback 还存在一种基于消息格式的便捷替代方案,示例代码如下://推荐使用{}
logger.debug("The new entry is {}. It replaces {}.", entry, oldEntry);只有当判断 Logger 开启了 DEBUG 级别的日志后(debug()方法中), Logger 才会格式化消息并将 “{}” 替换为指定的字符串值。换句话说,这种形式下消息不被 Logger 记录时不会产生参数构造的成本。//如果Logger不支持DEBUG级别的日志打印,程序就不会去构造参数
5、日志打印步骤的源码分析
如下代码,当我们调用 Logger 的 info() 方法时,logback 又会有哪些执行的步骤呢?
logger.info("Example log from {}", Example.class.getSimpleName());下边,让我们进入源码简单分析一下:
(1)获取过滤器链的决策结果
首先,TurboFilter 过滤器链会被调用。TurboFilter 可以设置上下文范围的阈值,还可以根据每个日志记录请求的信息(Marker, Level, Logger, message, or the Throwable)过滤掉某些事件。
如果过滤器链的回复是 FilterReply.DENY(否认),则日志记录请求将被丢弃。如果是 FilterReply.NEUTRAL(中性),则会继续进行下一步判断(步骤 2),如果回复是 FilterReply.ACCEPT,那么将会去创建 LoggingEvent 对象(步骤 3),部分源码如下所示:
- # Logger.class
- private void filterAndLog_1(String localFQCN, Marker marker, Level level, String msg, Object param, Throwable t) {
- //1、获取过滤器链的决策结果
- FilterReply decision = this.loggerContext.getTurboFilterChainDecision_1(marker, this, level, msg, param, t);
- //2、根据决策结果进行判断
- if (decision == FilterReply.NEUTRAL) {
- if (this.effectiveLevelInt > level.levelInt) {
- return;
- }
- } else if (decision == FilterReply.DENY) {
- return;
- }
- //3、创建LoggingEvent对象
- this.buildLoggingEventAndAppend(localFQCN, marker, level, msg, new Object[]{param}, t);
- }
-
- # TurboFilterList.class
- public FilterReply getTurboFilterChainDecision(Marker marker, Logger logger, Level level, String format, Object[] params, Throwable t) {
- //决策逻辑
- int size = this.size();
- if (size == 1) {
- try {
- TurboFilter tf = (TurboFilter)this.get(0);
- return tf.decide(marker, logger, level, format, params, t);
- } catch (IndexOutOfBoundsException var13) {
- return FilterReply.NEUTRAL;
- }
- } else {
- Object[] tfa = this.toArray();
- int len = tfa.length;
-
- for(int i = 0; i < len; ++i) {
- TurboFilter tf = (TurboFilter)tfa[i];
- FilterReply r = tf.decide(marker, logger, level, format, params, t);
- if (r == FilterReply.DENY || r == FilterReply.ACCEPT) {
- return r;
- }
- }
-
- return FilterReply.NEUTRAL;
- }
- }

(2)比较 Logger 有效级别与日志打印请求的级别
在这一步,logback 将 Logger 的有效级别与请求的级别进行比较。如果请求的级别低于 Logger 的有效级别,则 logback 将丢弃该请求。否则,将会去创建 LoggingEvent 对象(步骤 3)。
(3)创建 LoggingEvent 对象
如果日志打印请求经过过滤器链的筛选,执行到此步骤,logback 将创建一个 LoggingEvent 对象,其中包含请求的所有相关参数,例如请求的 Logger、请求的级别、消息本身、可能与请求一起传递的异常、当前时间、当前线程、有关发出日志记录请求的类和 MDC 的各种数据(MDC 即 Mapped Diagnostic Context:映射诊断上下文)。
- # Logger.class
- private void buildLoggingEventAndAppend(String localFQCN, Marker marker, Level level, String msg, Object[] params, Throwable t) {
- //创建LoggingEvent对象
- LoggingEvent le = new LoggingEvent(localFQCN, this, level, msg, t, params);
- le.addMarker(marker);
- //调用Appender
- this.callAppenders(le);
- }
(4)调用 Appender
创建 LoggingEvent 对象后,logback 将调用所有生效的 Appender 的 doAppend() 方法。部分源码如下所示:
- # AppenderAttachableImpl.class
- public int appendLoopOnAppenders(E e) {
- int size = 0;
- Appender<E>[] appenderArray = (Appender[])this.appenderList.asTypedArray();
- int len = appenderArray.length;
-
- for(int i = 0; i < len; ++i) {
- // 调用每一个Appender的doAppend()方法
- appenderArray[i].doAppend(e);
- ++size;
- }
-
- return size;
- }
logback 中所有 Appender 都扩展了 AppenderBase 抽象类,该类在同步块中实现 doAppend() 方法,确保了线程安全。AppenderBase 的 doAppend() 方法还会调用添加到 Appender 的自定义过滤器(如果存在任何此类过滤器)。//有关自定义过滤器将在后续再讨论
- # AppenderBase.class
- public synchronized void doAppend(E eventObject) {
- if (!this.guard) {
- try {
- this.guard = true;
- if (!this.started) {
- if (this.statusRepeatCount++ < 5) {
- this.addStatus(new WarnStatus("Attempted to append to non started appender [" + this.name + "].", this));
- }
-
- return;
- }
- // 调用添加的自定义过滤器
- if (this.getFilterChainDecision(eventObject) == FilterReply.DENY) {
- return;
- }
- // 调用具体的Appender进行日志输出
- this.append(eventObject);
- } catch (Exception var6) {
- if (this.exceptionCount++ < 5) {
- this.addError("Appender [" + this.name + "] failed to append.", var6);
- }
- } finally {
- this.guard = false;
- }
-
- }
- }
(5)格式化 LoggingEvent
被调用的具体的 Appender 负责格式化 LoggingEvent 。不同的 Appender 具有不同的实现,有一些 Appender 将格式化 LoggingEvent 的任务委托给 layout。layout 格式化 LoggingEvent 实例并将结果作为字符串返回。比如 SyslogAppenderBase(SyslogAppender),它的实现源码如下:
- # SyslogAppenderBase.class
- protected void append(E eventObject) {
- if (this.isStarted()) {
- try {
- // 1、将格式化LoggingEvent的任务委托给layout,将返回字符串
- String msg = this.layout.doLayout(eventObject);
- if (msg == null) {
- return;
- }
-
- if (msg.length() > this.maxMessageSize) {
- msg = msg.substring(0, this.maxMessageSize);
- }
- // 2、输出到目的地
- this.sos.write(msg.getBytes(this.charset));
- this.sos.flush();
- this.postProcess(eventObject, this.sos);
- } catch (IOException var3) {
- this.addError("Failed to send diagram to " + this.syslogHost, var3);
- }
-
- }
- }
不过,还有一些 Appender (例如 SocketAppender) 不会将 LoggingEvent 转换为字符串,而是将其序列化。所以,这些 Appender 没有 layout,也不需要 layout。
(6)发送 LoggingEvent
LoggingEvent 被完全格式化后,每个 Appender 会将其发送到其目的地。换句话说,就是通过 I/O 流把日志消息输出到特定的目的地。
至此,logback 日志打印步骤的源码分析结束。
最后,logback 日志框架的架构探讨也至此结束。

