
- 1nodejs 实现加载 huggingface local embedding model 方法_@xenova/transformers
- 2代码随想录刷题笔记-Day22
- 3解决Microsoft 365和Visio冲突问题_microsoft 365 visio
- 4中国电信笔试题目_中电信数 笔试
- 5Linux内核调试方法_config_kexec
- 6线稿图视频制作--从此短视频平台不缺上传视频了_线稿怎么制作成画出来的视频效果
- 7计算机网络-基础编程实验(JAVA\Python3)_计算机网络socket编程实验
- 8DataX使用之MongoDB2HDFS
- 9MongoDB聚合运算符:$add
- 10【回顾2023,展望2024】砥砺前行_回想2023年,对于我来说是
YOLOv8最新改进系列:主干网络改进-YOLOv8+EfficientNetV2,引入渐进式学习策略、自适应正则强度调整机制,提升模型检测效果!_yolov8修改网络
赞
踩
YOLOv8最新改进系列
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
截止到发稿时,B站YOLOv8最新改进系列的源码包,已更新了25种+损失函数的改进!自己排列组合2-4种后,不考虑位置已达3万种改进方法!考虑位置不同后可排列上百万种!!专注AI学术,关注B站博主:AI学术叫叫兽!
另外,实验涨点还有一个技巧,已经更新的源码文件中了,供获取源码的小伙伴先尝试一下。(目前还在实验阶段,过一段时间考虑开放)
YOLOv8最新改进系列:主干网络改进-YOLOv8+EfficientNetV2,引入渐进式学习策略、自适应正则强度调整机制,提升模型检测效果!!
一、EfficientNetV2概述
文章摘要:
本文介绍了一种新的卷积网络EfficientNetV2,它具有比之前的模型更快的训练速度和更好的参数效率。为了开发这些模型,我们使用了一种训练感知的神经架构搜索和缩放的组合,以共同优化训练速度和参数效率。这些模型是从具有新操作(如Fused-MBConv)的搜索空间中搜索出来的。我们的实验表明,EfficientNetV2模型的训练速度比最先进的模型快得多,同时体积最大可减小6.8倍。我们可以通过逐步增加训练中的图像尺寸来进一步加速训练,但这往往会导致准确度降低。为了补偿这种准确度降低,我们提出了一种改进的逐步学习方法,它根据图像尺寸自适应地调整正则化(例如数据增强)。通过逐步学习,我们的EfficientNetV2在ImageNet和CIFAR/Cars/Flowers数据集上明显优于以前的模型。通过在相同的ImageNet21k上进行预训练,我们的EfficientNetV2在ImageNet ILSVRC2012上实现了87.3%的top-1准确率,比最近的ViT高出2.0%的准确率,同时使用相同的计算资源训练速度提高了5倍至11倍。
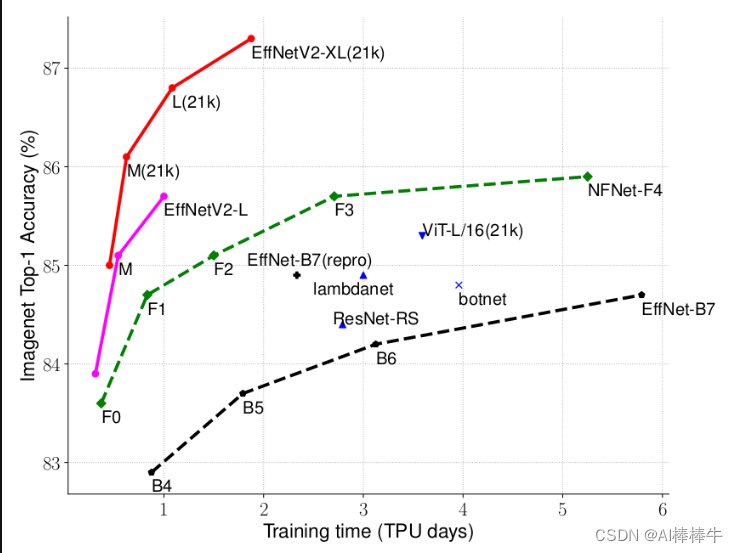
通过上图很明显能够看出EfficientNetV2网络不仅Accuracy达到了当前的SOTA(State-Of-The-Art)水平,而且训练速度更快参数数量更少(比当前火热的Vision Transformer还要强)。EfficientNetV2-XL (21k)在ImageNet ILSVRC2012的Top-1上达到87.3%。在EfficientNetV1中作者关注的是准确率,参数数量以及FLOPs(理论计算量小不代表推理速度快),在EfficientNetV2中作者进一步关注模型的训练速度。
1.1 EfficientNetV1中存在的问题
1.1.1训练图像的尺寸很大时,训练速度非常慢。
这确实是个槽点,在之前使用EfficientNet时发现当使用到B3(img_size=300)- B7(img_size=600)时基本训练不动,而且非常吃显存。通过下表可以看到,在Tesla V100上当训练的图像尺寸为380x380时,batch_size=24还能跑起来,当训练的图像尺寸为512x512时,batch_size=24时就报OOM(显存不够)了。针对这个问题一个比较好想到的办法就是降低训练图像的尺寸,之前也有一些文章这么干过。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size.
1.1.2 在网络浅层中使用Depthwise convolutions速度会很慢。
虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快)。在近些年的研究中,有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。Fused-MBConv结构也非常简单,即将原来的MBConv结构(之前在将EfficientNetv1时有详细讲过)主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3,如图2所示。作者也在EfficientNet-B4上做了一些测试,发现将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度,如表3所示,将stage2,3,4都替换成Fused-MBConv结构后,在Tesla V100上从每秒训练155张图片提升到216张。但如果将所有stage都替换成Fused-MBConv结构会明显增加参数数量以及FLOPs,训练速度也会降低。所以作者使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。
1.1.3 同等的放大每个stage是次优的。
在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中,作者采用了非均匀的缩放策略来缩放模型。
1.2 EfficientNetV2中做出的改进点
在之前的一些研究中,大家主要关注的是准确率以及参数数量(注意,参数数量少并不代表推理速度更快)。但在近些年的研究中,大家开始关注网络的训练速度以及推理速度(可能是准确率刷不动了)。但他们提升训练速度通常是以增加参数数量作为代价的。而这篇文章是同时关注训练速度以及参数数量的。
- 引入新的网络(EfficientNetV2),该网络在训练速度以及参数数量上都优于先前的一些网络。
- 提出了改进的渐进学习方法,该方法会根据训练图像的尺寸动态调节正则方法(例如dropout、data augmentation和mixup)。
- 通过实验展示了该方法不仅能够提升训练速度,同时还能提升准确率。
通过实验与先前的一些网络相比,训练速度提升11倍,参数数量减少为1/6.8
1.3 实验
为了进一步验证渐进式学习策略的有效性,作者还在Resnet以及EfficientNetV1上进行了测试,如下表所示,使用了渐进式学习策略后确实能够有效提升训练速度并且能够小幅提升Accuracy
二、YOLOv8+EfficientNetV2
2.1 修改YAML文件
2.2新建model.py
2.3 修改tasks.py
三、验证是否成功即可
执行命令
python train.py
- 1
改完收工!
关注B站:AI学术叫叫兽
从此走上科研快速路
遥遥领先同行!!!!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!

