
热门标签
热门文章
- 1Vue3+TypeScript+Pinia初始化项目,vscode报错解决办法!_vscode vue3+ts 老是提示代码错误
- 210大经典数据分析模型,你知道几个?(二)_scp分析模型
- 3python波形图librosa_librosa语音信号处理
- 4阿里云ECS安全组操作介绍_您所选的 1 个实例 至少要属于一个安全组,将不会执行移出安全组操作。
- 5线上问题解决:使用FFmpeg截取视频图片出现旋转问题(亲测解决,必看!!)_ffmpegframegrabber 取视频截图 旋转
- 6Unity之合并多张图片为一张大图(二)_unity 多张序列帧合并1张
- 7C# Socket发送请求及监听_c# seriport持续监听
- 8vLLM部署推理及相关重要参数_vllm prompt 参数
- 9轻松打造自己的聊天机器人:JAVA版ChatGPT_chatgpt-web-java
- 10【Linux】安装Tomcat详细教程(图文教程)_linux安装tomcat
当前位置: article > 正文
毕业设计 机器学习的情感分类与分析算法设计与实现(源码+论文)_分类算法论文csdn
作者:2023面试高手 | 2024-03-06 11:41:21
赞
踩
分类算法论文csdn
0 项目说明
基于机器学习的情感分类与分析算法设计与实现
提示:适合用于课程设计或毕业设计,工作量达标,源码开放
1 研究目的
通过对带有情感色彩的主观性文本进行分析、处理、归纳然后进行推理。通过情感分析可以获取网民的此时的心情,对某个事件或事物的看法,可以挖掘其潜在的商业价值,还能对社会的稳定做出一定的贡献。
2 研究方法
(1)使用微博官方的API对微博进行抓取,进行分类标注。
(2)对微博文本进行预处理,主要包括去掉无意义,对微博文本没有影响的词语。
(3)使用SVM算法对文本进行初步的筛选,主要是去除特别明显的广告等无关性的微博。
(4)使用朴素贝叶斯对微博进行情感分析,将微博分为积极、消极、客观三类,同时使用AdaBoost算法对朴素贝叶斯算法进行加强。
3 研究结论
主要实现:
对微博的降噪清理、对无关性的微博本文进行过滤、使用了朴素贝叶斯对微博进行情感分类、使用AdaBoost算法对朴素贝叶斯进行加强。
可改进:
(1)在情感分析的前提下,能够对某些微博中的评论来分析用户的情感倾向性,比如某些热点事件,分析大部分网民对热点事件的喜怒哀乐。同时,也可以根据该热点事件中牵涉到的时间、地点、人物等,对其深入的挖掘,甚至是做出预测性分析。
(2)可更改情感分类的策略,以更精确的分析用户的语言现象,比如分析用户的程度副词如“非常”、“超级”等,结合文本中的标点符号和重复的词语,进行综合的整体建模。
(3)除了针对某些热点事件之外,还可获取个人所有的微博进行分析。从一个人的所有微博中可以获取其情感方向的估计,比如对某件事件的喜欢或者厌恶,对某些品牌的热衷与唾弃等。
4 项目流程
4.1 获取微博文本
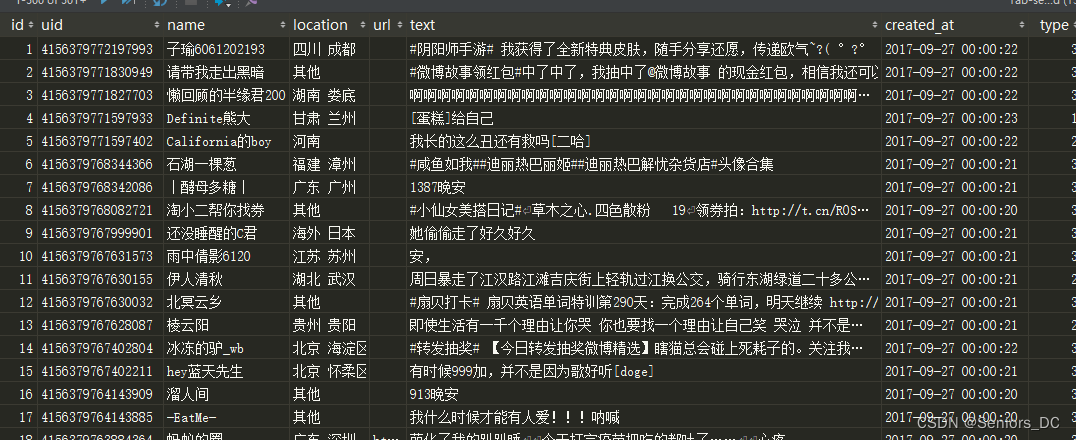
4.2 SVM初步分类
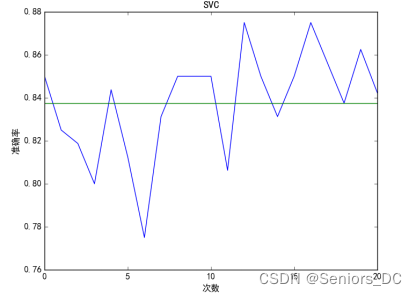
4.3 使用朴素贝叶斯分类
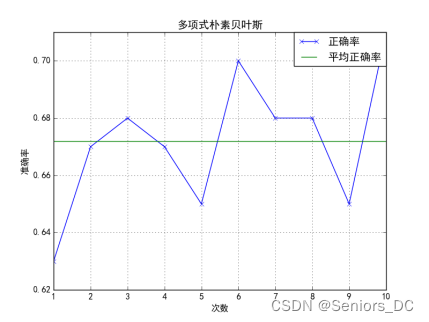
4.4 AdaBoost
4.4.1 二分类AdaBoost
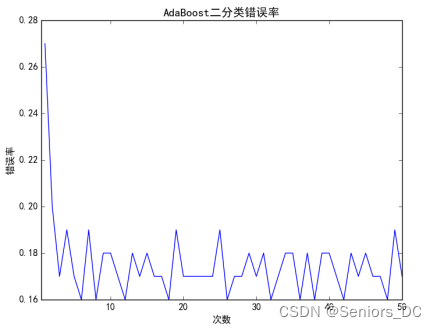
4.4.2 多分类AdaBoost
4.4.2.1 AdaBoost.SAMME
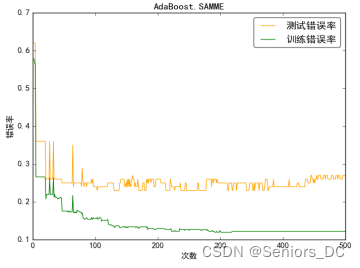
4.4.2.2 AdaBoost.SAMME.R
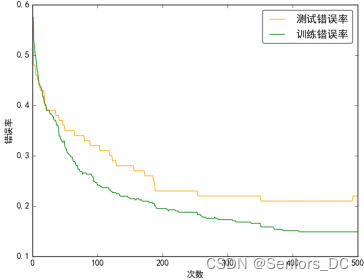
5 论文概览

6 项目源码
import random import re import traceback import jieba import numpy as np from sklearn.externals import joblib from sklearn.naive_bayes import MultinomialNB jieba.load_userdict("train/word.txt") stop = [line.strip() for line in open('ad/stop.txt', 'r', encoding='utf-8').readlines()] # 停用词 def build_key_word(path): # 通过词频产生特征 d = {} with open(path, encoding="utf-8") as fp: for line in fp: for word in jieba.cut(line.strip()): p = re.compile(r'\w', re.L) result = p.sub("", word) if not result or result == ' ': # 空字符 continue if len(word) > 1: # 避免大量无意义的词语进入统计范围 d[word] = d.get(word, 0) + 1 kw_list = sorted(d, key=lambda x: d[x], reverse=True) size = int(len(kw_list) * 0.2) # 取最前的30% mood = set(kw_list[:size]) return list(mood - set(stop)) def loadDataSet(path): # 返回每条微博的分词与标签 line_cut = [] label = [] with open(path, encoding="utf-8") as fp: for line in fp: temp = line.strip() try: sentence = temp[2:].lstrip() # 每条微博 label.append(int(temp[:2])) # 获取标注 word_list = [] sentence = str(sentence).replace('\u200b', '') for word in jieba.cut(sentence.strip()): p = re.compile(r'\w', re.L) result = p.sub("", word) if not result or result == ' ': # 空字符 continue word_list.append(word) word_list = list(set(word_list) - set(stop) - set('\u200b') - set(' ') - set('\u3000') - set('️')) line_cut.append(word_list) except Exception: continue return line_cut, label # 返回每条微博的分词和标注 def setOfWordsToVecTor(vocabularyList, moodWords): # 每条微博向量化 vocabMarked = [0] * len(vocabularyList) for smsWord in moodWords: if smsWord in vocabularyList: vocabMarked[vocabularyList.index(smsWord)] += 1 return np.array(vocabMarked) def setOfWordsListToVecTor(vocabularyList, train_mood_array): # 将所有微博准备向量化 vocabMarkedList = [] for i in range(len(train_mood_array)): vocabMarked = setOfWordsToVecTor(vocabularyList, train_mood_array[i]) vocabMarkedList.append(vocabMarked) return vocabMarkedList def trainingNaiveBayes(train_mood_array, label): # 计算先验概率 numTrainDoc = len(train_mood_array) numWords = len(train_mood_array[0]) prior_Pos, prior_Neg, prior_Neutral = 0.0, 0.0, 0.0 for i in label: if i == 1: prior_Pos = prior_Pos + 1 elif i == 2: prior_Neg = prior_Neg + 1 else: prior_Neutral = prior_Neutral + 1 prior_Pos = prior_Pos / float(numTrainDoc) prior_Neg = prior_Neg / float(numTrainDoc) prior_Neutral = prior_Neutral / float(numTrainDoc) wordsInPosNum = np.ones(numWords) wordsInNegNum = np.ones(numWords) wordsInNeutralNum = np.ones(numWords) PosWordsNum = 2.0 # 如果一个概率为0,乘积为0,故初始化1,分母2 NegWordsNum = 2.0 NeutralWordsNum = 2.0 for i in range(0, numTrainDoc): try: if label[i] == 1: wordsInPosNum += train_mood_array[i] PosWordsNum += sum(train_mood_array[i]) # 统计Pos中语料库中词汇出现的总次数 elif label[i] == 2: wordsInNegNum += train_mood_array[i] NegWordsNum += sum(train_mood_array[i]) else: wordsInNeutralNum += train_mood_array[i] NeutralWordsNum += sum(train_mood_array[i]) except Exception as e: traceback.print_exc(e) pWordsPosicity = np.log(wordsInPosNum / PosWordsNum) pWordsNegy = np.log(wordsInNegNum / NegWordsNum) pWordsNeutral = np.log(wordsInNeutralNum / NeutralWordsNum) return pWordsPosicity, pWordsNegy, pWordsNeutral, prior_Pos, prior_Neg, prior_Neutral def classify(pWordsPosicity, pWordsNegy, pWordsNeutral, prior_Pos, prior_Neg, prior_Neutral, test_word_arrayMarkedArray): pP = sum(test_word_arrayMarkedArray * pWordsPosicity) + np.log(prior_Pos) pN = sum(test_word_arrayMarkedArray * pWordsNegy) + np.log(prior_Neg) pNeu = sum(test_word_arrayMarkedArray * pWordsNeutral) + np.log(prior_Neutral) if pP > pN > pNeu or pP > pNeu > pN: return pP, pN, pNeu, 1 elif pN > pP > pNeu or pN > pNeu > pP: return pP, pN, pNeu, 2 else: return pP, pN, pNeu, 3 def predict(test_word_array, test_word_arrayLabel, testCount, PosWords, NegWords, NeutralWords, prior_Pos, prior_Neg, prior_Neutral): errorCount = 0 for j in range(testCount): try: pP, pN, pNeu, smsType = classify(PosWords, NegWords, NeutralWords, prior_Pos, prior_Neg, prior_Neutral, test_word_array[j]) if smsType != test_word_arrayLabel[j]: errorCount += 1 except Exception as e: traceback.print_exc(e) print(errorCount / testCount) if __name__ == '__main__': for m in range(1,11): vocabList = build_key_word("train/train.txt") line_cut, label = loadDataSet("train/train.txt") train_mood_array = setOfWordsListToVecTor(vocabList, line_cut) test_word_array = [] test_word_arrayLabel = [] testCount = 100 # 从中随机选取100条用来测试,并删除原来的位置 for i in range(testCount): try: randomIndex = int(random.uniform(0, len(train_mood_array))) test_word_arrayLabel.append(label[randomIndex]) test_word_array.append(train_mood_array[randomIndex]) del (train_mood_array[randomIndex]) del (label[randomIndex]) except Exception as e: print(e) multi=MultinomialNB() multi=multi.fit(train_mood_array,label) joblib.dump(multi, 'model/gnb.model') muljob=joblib.load('model/gnb.model') result=muljob.predict(test_word_array) count=0 for i in range(len(test_word_array)): type=result[i] if type!=test_word_arrayLabel[i]: count=count+1 # print(test_word_array[i], "----", result[i]) print("mul",count/float(testCount)) PosWords, NegWords, NeutralWords, prior_Pos, prior_Neg, prior_Neutral = \ trainingNaiveBayes(train_mood_array, label) predict(test_word_array, test_word_arrayLabel, testCount, PosWords, NegWords, NeutralWords, prior_Pos, prior_Neg, prior_Neutral)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
7 最后
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

