
- 1兰州新区学计算机的地方,兰州新区大学城都有哪些学校
- 2No field mActive of type Landroid/util/SparseArray; in class Landroidx/fragment/app/FragmentManagerI_android nosuchfielderror: no instance field mactiv
- 3ctfmon是什么启动项_win7启动项没有ctfmon.exe的解决方法
- 4淘晶驰串口屏入门(四)进度条、滑块、定时器、单选框、复选框、二维码_陶晶弛串口屏写脚本定时刷新
- 5因为粗心遇到的坑 springboot 启动项目启动不了 Disconnected from the target VM, address: '127.0.0.1:63165', transport_yml文件disconnected报错
- 6群晖安装docker+宝塔面板+80端口+自动同步_群晖docker安装宝塔
- 7ios monkey
- 8多线程进阶:volatile的作用以及实现原理_多线程共享变量volatile
- 9airtest连接小米mix3不成功_airtest连接小米手机一连接就下线
- 10全网最全的网络安全技术栈内容梳理(持续更新中)_网络安全开发技术 博客
PostgreSQL 的实体化视图介绍_pg创建实体视图
赞
踩
PostgreSQL 实体化视图提供一个强大的机制,通过预先计算并将查询结果集存储为物理表来提高查询性能。本教程将使用 DVD Rental Database 数据库作为演示例子,指导你在 PostgreSQL中创建实体化视图。
了解实体化视图
实体化视图是查询结果集的快照,以物理表的形式存储。与常规视图不同,实体化视图是虚拟的,每次被引用时都会执行底层查询,实体化视图能持久化数据,并通过定期刷新来提高查询性能。
相比于频繁的查询执行,实体化视图对于底层数据变化不频繁的场景是非常有用的。这使得它们成为报告、数据仓库和实时数据要求不严格的场景的理想选择。
设置 DVD Rental 数据库
在深入探讨实体化视图前,让我们先来设置 DVD Rental 数据库。它是 MySQL 常用的 Sakila 数据库样例的 PostgreSQL 版本。你可以从官方 PostgreSQL 教程网页(PostgreSQL Sample Database)上下载 DVD Rental 数据库。
数据库文件为 ZIP 格式(dvdrental.zip),所以在加载数据库样例到 PostgreSQL 数据库服务器前,你需要将它解压缩为 dvdrental.tar。解压为 .tar 文件后,创建名为“dvdrental”的新数据库,然后执行 pg_restore 命令以将 .tar 文件内容填充到 dvdrental 数据库中。
pg_restore -U postgres -d dvdrental D:\sampledb\postgres\dvdrental.tar将上面的路径替换为你系统上指向已解压的 dvdrental.tar 路径。
你可以点击 此处 查看详细的安装说明。
创建实体化视图
假设我们想创建一个实体化视图,显示每个电影类别产生的总收入。以下是操作步骤:
- 连接你的 PostgreSQL 数据库
- 通过下面的 DML 语句创建实体化视图:
- CREATE MATERIALIZED VIEW mv_category_revenue AS
- SELECT
- c.name AS category,
- SUM(p.amount) AS total_revenue
- FROM
- category c
- JOIN film_category fc ON c.category_id = fc.category_id
- JOIN film f ON fc.film_id = f.film_id
- JOIN inventory i ON f.film_id = i.film_id
- JOIN rental r ON i.inventory_id = r.inventory_id
- JOIN payment p ON r.rental_id = p.rental_id
- GROUP BY
- c.name;
例子中,我们将 DVD Rental 数据库中多张表进行联合,以计算每个电影类别的总收入。
在 Navicat For PostgreSQL(或 Navicat Premium)16:
-
- 点击“实体化视图”按钮,将显示实体化对象列表,在对象工具栏中点击“+ 新建实体化视图”,将打开视图设计器:

-
- 在定义编辑器中输入上述语句的 SELECT 部分:

-
- 我们可以点击“预览”按钮来检查语句是否可以如期运行:
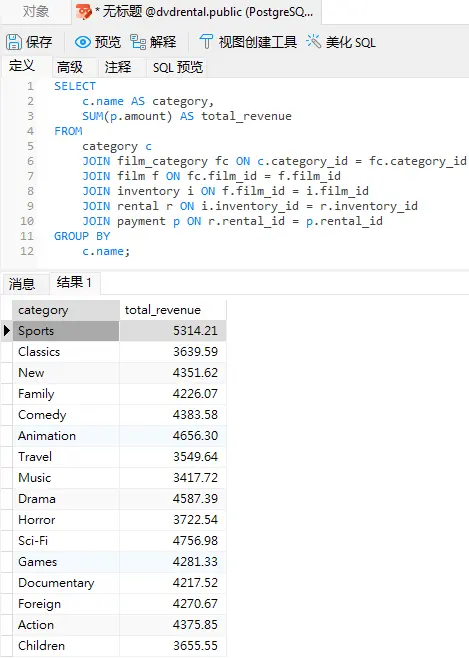
-
- 点击“保存”按钮,完成创建新的实体化视图。这将会弹出一个提示输入实体化视图名称的对话框,根据上面的 CREATE MATERIALIZED VIEW 语句中的名称,我们将它命名为“mv_category_revenue”:

-
- 点击对话框中的保存按钮,Navicat 会将实体化视图名称从“无标题”改为我们提供的名称。同时也会将新建的实体化视图添加到左侧导航窗格的实体化视图列表中:
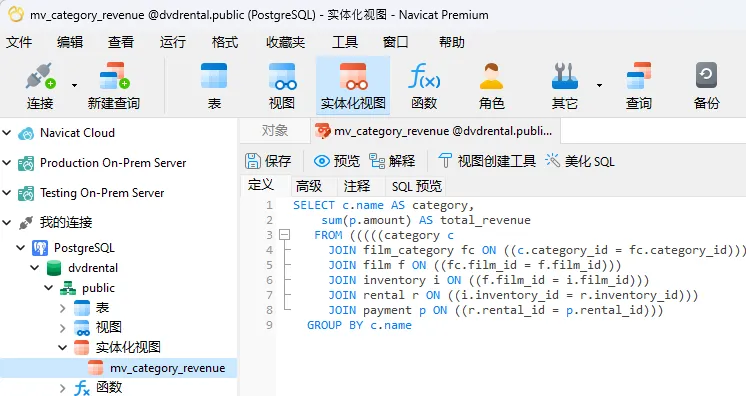
总结
在非实时数据场景下,PostgreSQL 实体化视图是一个优化查询性能的有用工具。通过预计算和存储复杂查询的结果,实体化视图可以显著提高分析和报告任务的响应时间。本教程中,我们学习了如何为 DVD Rental 数据库创建实体化视图,并展示了在真实场景中的实际应用。

