
- 1程序员请收好:10个非常实用的 VS Code 插件
- 2如何使用api接入星火大模型(超详细,亲测有效!)_星火大模型v4接口
- 3NLTK库——词形还原(Lemmatization)_nltk词形还原(lemmatization)
- 4Python实战项目——用户消费行为数据分析(三)_数据挖掘消费者行为分析
- 5【深度学习】归一化(十一)_权重归一化
- 6LangChain安装和入门案例_langchain 安装
- 7MySQL面试题系列-8
- 8人工智能-----自然语言处理(NLP)基础理解_智能化需求调查与分析采用自然语言处理深度学习等技术从什么等自然语言描述文
- 9第四届全国人工智能大赛答疑分享会等你围观_杨文瀚 鹏城实验室
- 10西北乱跑娃 --- bottle web框架(七)_bottle 如何显示图片
细粒度图像分类论文研读-2018_weakly supervised fine-grained categorization with
赞
踩
文章目录
Object-Part Attention Model for Fine-grained Image Classification(by localization- classification subnetwork)
Abstract
细粒度图像分类主要有两大局限性:
- 依赖于对象或者局部注释,这需要很大的工作量;
- 忽略对象与其各部分之间的相互关系以及各部分之间的相互关系。
第二个问题是目前新出现的。
因此,本文提出了弱监督细粒度图像分类的对象注意模型(OPAM),主要的新颖性是:
- Object-part attention model集成了两级注意:对象级注意定位图像中的对象,部分级注意选择对象的判别部分。两者共同用于学习多视图和多尺度特征,以增强他们的相互促进。
- Object-part spatial constraint model结合了两个空间约束:对象空间约束确保所选部分具有高度代表性,部分空间约束消除冗余并增强对所选部分的判别。两者共同用于利用细微和局部差异来区分子类别。
重要的是,文章提出的方法中既没有使用对象也没有使用部分注释,这避免了标签的大量劳动力消耗。在4个广泛使用的数据集上与10种以上最先进的方法相比,文章的OPAM方法实现了最佳性能。
通过阅读几篇论文,所谓弱监督指的是在无部分标注且仅有类别标注的情况下对局部检测进行间接的学习。
Introduction
关于定位,目前不依赖于标注的做法有两种:
- 采用无监督方法:选择性搜索:生成数千个图像块,这是一种自底向上的过程,具有较高的整体性但确实较低的精读,因此需要去除不完整的图像块并保留包含对象或辨别部分的图像块。
- 自上而下的注意力模型,这在16、17年的论文中已经广泛出现,属于弱监督的方法。
16年的论文有:
《Xiaopeng Zhang, Hongkai Xiong, Wengang Zhou, Weiyao Lin, andQi Tian. Picking deep filter responses for fine-grained image recognition.IEEE Conference on Computer Vision and Pattern Recognition (CVPR),pages 1134–1142, 2016.》
《Yu Zhang, Xiu-Shen Wei, Jianxin Wu, Jianfei Cai, Jiangbo Lu, Viet-AnhNguyen, and Minh N Do. Weakly supervised fine-grained categorizationwith part-based image representation.IEEE Transactions on ImageProcessing (TIP), 25(4):1713–1725, 2016.》
在细粒度分类的背景下,找到对象和有区分度的部分可以视为一个两级的注意力过程:object-level and part-level。
本文依然是一款解决标注问题的工作。
目前一些弱监督的方法在选择有区分度的部分时,对象与其部分之间以及这些部分之间的关系会被忽略。这俩内容都很关键,如果缺失的话会造成:
- 包含大面积的背景噪声和小面积的对象
- 彼此之间存在较大的重叠,这造成了冗余信息。
本文提出了两个模块:
Object- Part Attention Model
这一部分解决了局部标注问题。
该模块汇聚了两级注意力:
Object-level attention model 使用全局平均池化来提取显著图以定位图像目标,这是为了学习目标特征;
Part-level attention model 首先选择有区分度的部分,然后基于神经网络的聚类模式对齐这些部分,这是为了学习微小且局部的特征。
这俩部分联合使用来提升多视角及多尺度学习并且增强他们之间相互的提升来达到更好的表现。
Object- Part Spatial Constraint Model
这一部分解决了局部关系问题。
本文提出了收到object-part 空间限制模型驱动的局部选择方法,其中包含了两层限制:
- Object spatial constraint确保选择的局部在目标区域且具有较高的代表性;
- Part spatial constraint减少了局部之间的重叠且突出了局部的特点,这减少了冗余,提升了区分度。
Our OPAM Approach
本文的方法基于一个直观的想法,细粒度图像分类通常首先定位对象(对象级注意力),然后区分部分(部分级注意力)。
Object-level Attention Model
现存的一些工作都忙着定位局部了,忽视了对象级别的定位。
为什么要考虑对象级的定位呢?这是因为这能够消除背景噪声的影响以学习到有意义有代表性的对象特征。
也有一些工作考虑了对象和局部,但是都是带注释的。
那么如何解决注释问题呢?
本文给出了一个模型,包含了两个组成部分:patch filtering和saliency extraction。
前者过滤掉噪声图像块然后保留那些与目标相关的来训练一个CNN,称之为ClassNet。这一做法的的目的是学习多视角、多尺度的、特定子类别的特征。
后者在CNN中通过全局平均池化提取显著图来定位图像中的目标。
Patch Filtering
首先关注如何扩展训练数据。本文采用搜索算法找了很多图像块以此填充数据,以得到一个有效的CNN。这些学习了多视角、多尺度的特征。
当然从SS算法到数据填充还要做一些加工。
本文通过CNN移除了噪声块,称之为FilterNet。目的仅仅是判断它是否应该被选择。扩充训练数据后提升了ClassNet的训练效果。这样做的好处有两点:
- ClassNet成为了一个有效的细粒度图像分类器;
- 其内部特征对于构建局部聚类以达到相同语义的局部对齐很有帮助。
补丁过滤步骤仅在训练阶段实行。
Saliency Extraction
本阶段采用CAM来得到显著图以进行目标的定位。
显著图指示了代表性区域,如图4第二行所示。

然后对显著性图进行二值化和连通性区域提取,获得图像的目标区域,如图4的第三行。
最后,定位到对象后,我们训练一个CNN,称为ObjectNet,以获取基于对象级注意力的预测。
Part-level Attention Model
Object- part Spatial Constraint Model
首先已经通过OAM模块得到对象区域,这里基于这一知识从自下而上过程产生的候选图像块中选择有区分度的局部。于是,两个空间约束被联合考虑:对象和局部,局部和局部。
这两个约束的实现可以表示为:
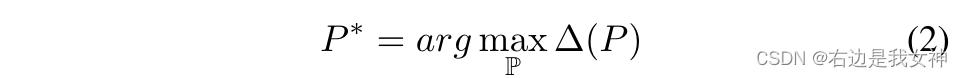
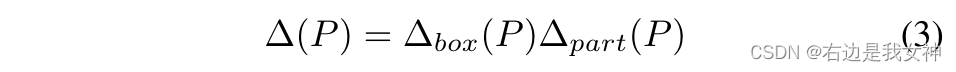
对象空间约束
保证part patch与对象重叠度很高。
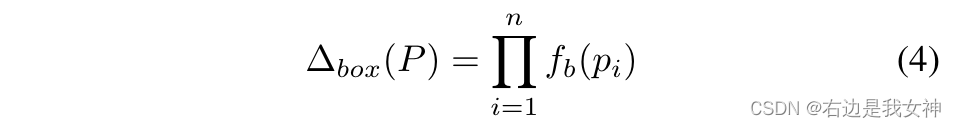
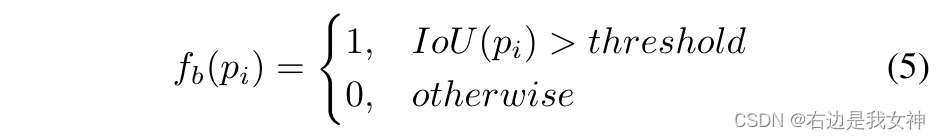
局部空间约束
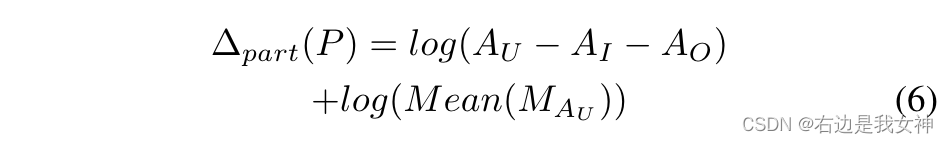
A U A_U AU是n个部分之间的并集, A I A_I AI是n个部分之间的交集, A O A_O AO是目标区域外的区域。
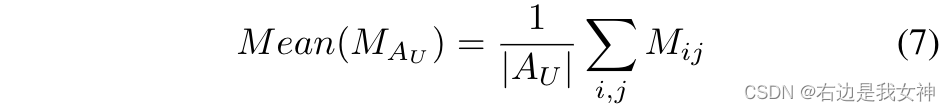
M i j M_{ij} Mij表示像素(i,j)位置的显著区域。
第一项旨在减少所选零件之间的重叠。第二项旨在最大化所选部分的显著性。
Part Alignment
通过上述方法选择的部分是没有顺序的,如图5(a)所示。
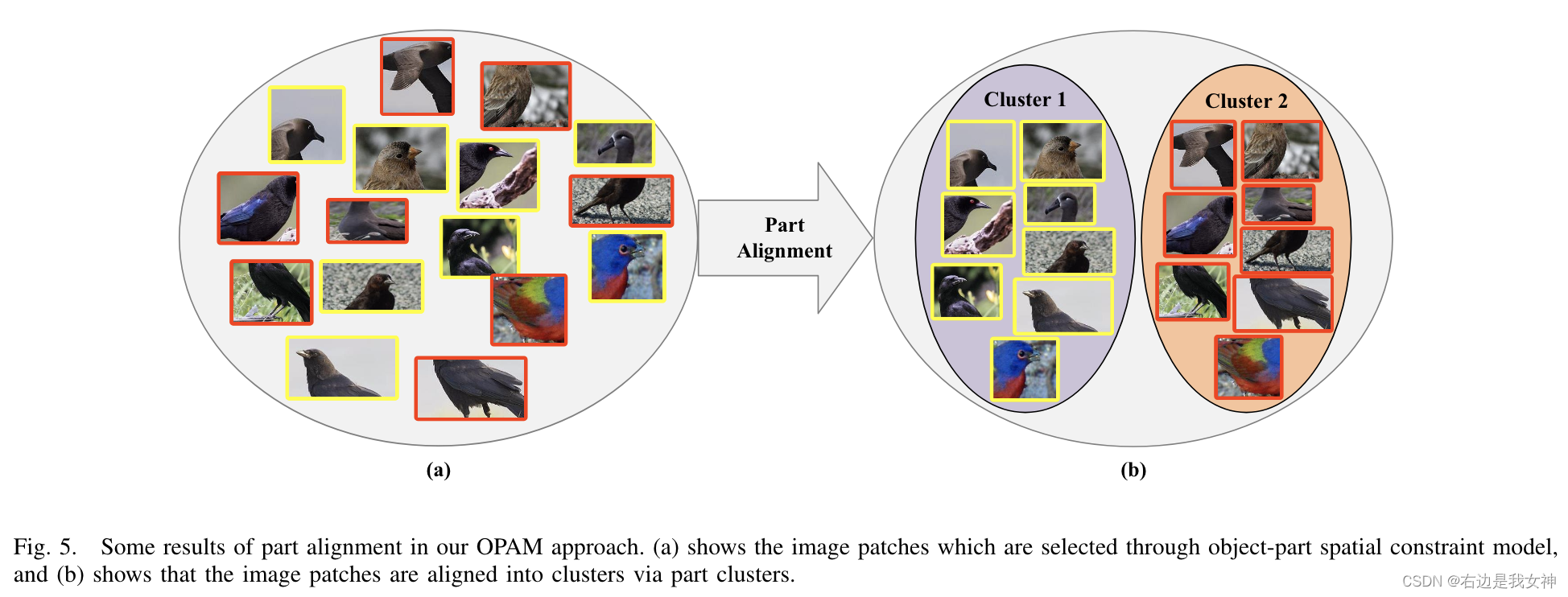
用聚类对局部特征进行语义对齐。这一思路参考的是CNN中间层的发现。
Final Prediction
本文一共有三个分类器ClassNet、ObjectNet和PartNet。
ClassNet通过与Object相关的Image patches进行训练;
ObjectNet通过定位到的Object进行训练;
PartNet则通过Part进行训练;
得到的结果通过加权结合得到最后的结果。
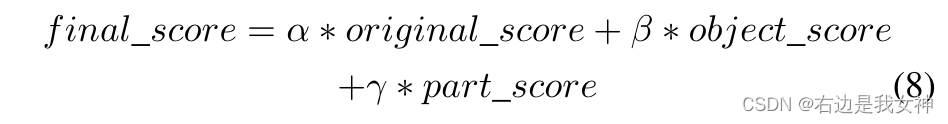
Multi-Attention Multi-Class Constraint for Fine-grained Image Recognition
Abstract
现有的大多数方法都是孤立地处理每个对象部分,而忽略了他们之间的相关性。
此外,现有的方法所涉及的多阶段或多尺度机制使得模型的效率低下,难以进行端到端的训练。
本文提出了一种新的基于注意力的卷积神经网络来调节不同输入图像中的多个目标部分。该方法首先通过one-squeeze multi-excitation(OSME)学习每个输入图像的多个注意区域特征,然后在度量学习框架中应用多注意多类约束(MAMC)。MAMC通过拉近相同注意力的同类特征,同时推开不同注意力的不同类的特征。
Introduction
大部分的工作都围绕如何有效地将局部汇集到分类网络中。
有通过局部定位+特征表示的方法,但这类强监督方法的缺点在于严重依赖手动的注释。
目前,弱监督框架收到越来越多的关注。
但是这类方法仍然受到一些限制:其一,它们的附加步骤(关注区域的局部定位和特征提取)会造成高昂的计算成本;其二,训练过程比较复杂,需要多次交替或级联;其三,也是最重要的,大多数工作倾向于孤立地检测对象的各个部分,忽略了他们之间的内在联系。因此,学习到的注意力模块很可能集中在同一个区域并且缺乏定位具有的区别特征的多个部分的能力。
从大量的实验研究中,我们观察到一个有效的、合理的细粒度分类机制应该遵循三个标准:
- 被检测的局部应该很好地分布在物体上以获取不相关的特征;
- 每个局部特征应该对不同类的目标是有区分度的;
- 局部提取器应该是轻量化的,以便能够在实际应用中按比例放大。
本文首先提出了OSME模块,灵感来源于SENet,用于提取局部特征;
其次,受到度量学习损失爹启发,本文提出了多注意力多类约束,来增强训练中不同部分的相关性。
Related work
目前的方法以弱监督机制来定位对象部分,最早的有2015年的《Fine-grained Recognition without part-annotations》以及2016年的BCNN这样的工作。
这类工作最大的特点是仅仅使用图像级别的标签进行训练。
之后,我们再探讨一下基于注意力的方法,传统的基于部分的方法有一个重大的缺陷,那就是需要对象的局部是有意义的。这对于非结构化的对象来说是比较困难的。因此,使CNN关注一般对象的相对宽松的区域的方法是比较可行的。
Proposed Method
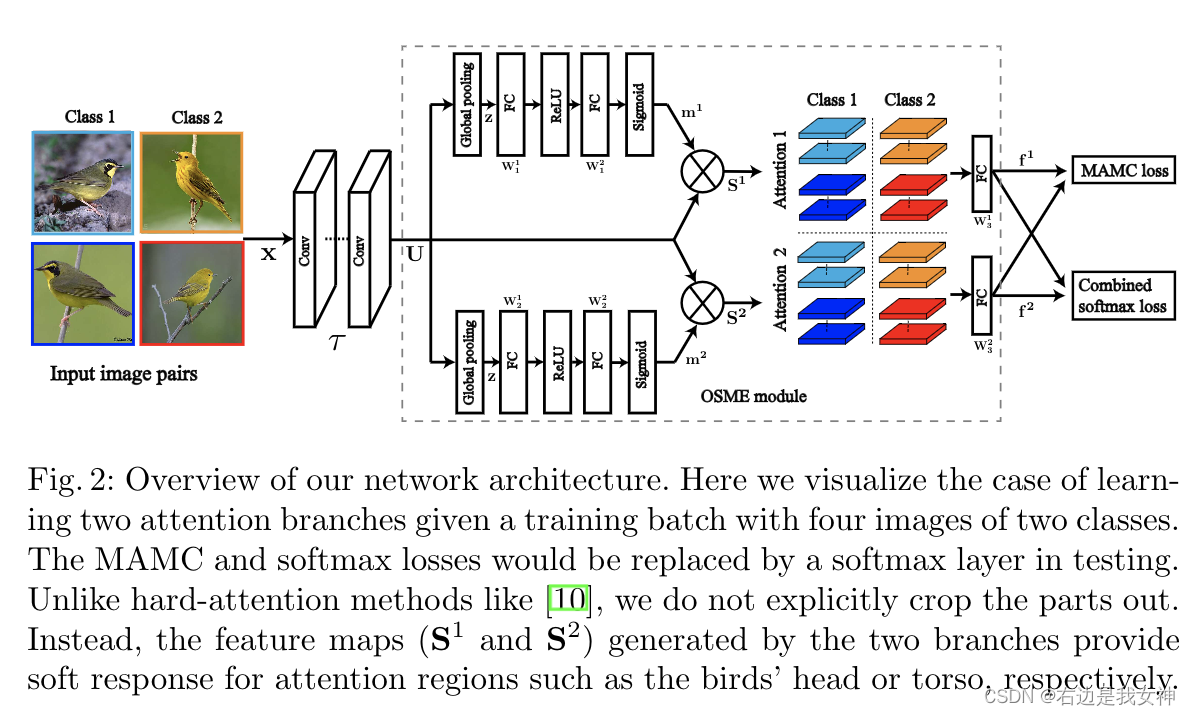
OSME Attention Module
目前有很多基于注意力的工作在探索弱监督框架,目前大致分为两类。第一类称为part detection,也就是每个注意力相当于一个bounding box。由于局部检测和特征提取被分离在不同的模块中,所以该类结构的设计比较复杂。
第二类可以被认为在feature map中加了一个soft mask。该类方法往往是基于对卷积本质的研究。本文就是属于该类方法的范畴。
本文采用SENet的思想来捕获和描述输入图像中多个有区分度的区域,与其他基于soft attention的作品相比,本文基于SENet构建,在性能和可扩展性上有很大的优势。
本文的框架是一个前馈神经网络,输入模型的图像首先由一个基础网络(ResNet-50)进行处理。我们记 x ∈ R W ′ × H ′ × C ′ x\in R^{W'\times H'\times C'} x∈RW′×H′×C′为被送入最后一个残差块 τ \tau τ的输入:
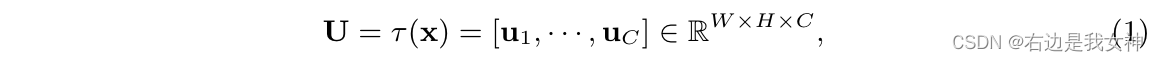
SENet的目标是重新校准输出特征图。为了生成P个特定注意力的特征图,我们通过执行one-squeeze-multi-excitation 操作来扩展SENet的思想。
在第一个挤压步骤中,我们在空间维度WxH上聚集了特征图U来产生逐通道的描述子 z = [ z 1 , . . . , z C ] ∈ R C z=[z_1,...,z_C]\in R^C z=[z1,...,zC]∈RC。这其中,采用全局平均池化是一个简单却有效的方法来描述每一个通道的统计数据。
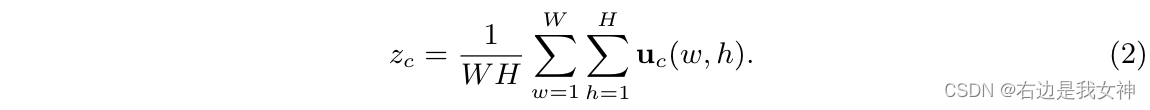
在第二个多激励步骤中,在z上,一个门控机制被单独地使用:
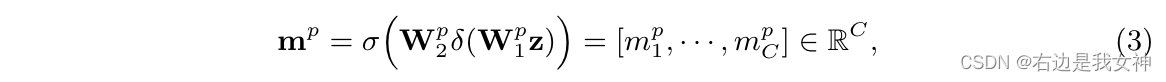
其中sigma表示Sigmoid,delta表示ReLU。
我们采用了和SENet相同的设计,通过形成一对维度的减少和增加层:
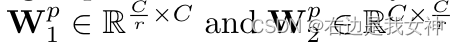
由于Sigmoid的性质,每个 m p m^p mp在通道上都是非互斥关系的,因此我们用它来重新加权原始特征映射图的通道。
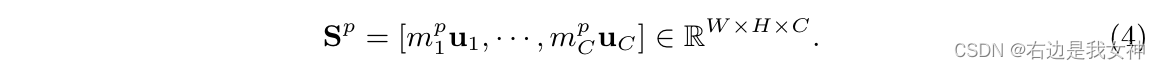
为了提取特定注意力的特征,我们将每个注意力图
S
p
S^p
Sp送入一个全连接层
W
3
p
W_3^p
W3p:
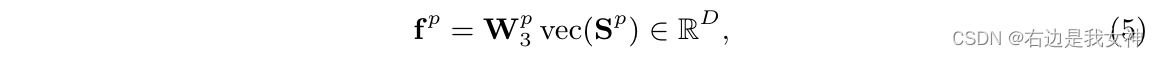
其中的vector操作属于一种flatten。
值得说明的是,SENet最初不是为了学习visual attentions。但是通过采用SENet的关键思想,OSME模块能够执行一个注意力机制。
MAMC Constraint
注意力机制有了,但是如何将提取到的注意力特征引导到正确的类被标签呢。一种直接的方法是softmax loss(带softmax的交叉熵),但是不能调节attention feature之间的相关性(意思应该是不同attention feature是独立的,无法控制他们之间的关系,这里的attention feature的意思应该是通过attention得到的新的feature)。
另一条路子就是RA-CNN这样,采用循环搜索机制,模仿人类感知。将先前的预测作为参考,从粗到细迭代地产生注意区域。
但是这一方法的局限性在于当前预测高度依赖于先前的预测。初始误差会被迭代地放大。
本文采取了一种更加切实际的方法来在训练中直接加强各部分之间的相关性。这里的意思应该指的是加强不同branch之间的attention feature 之间的关系。
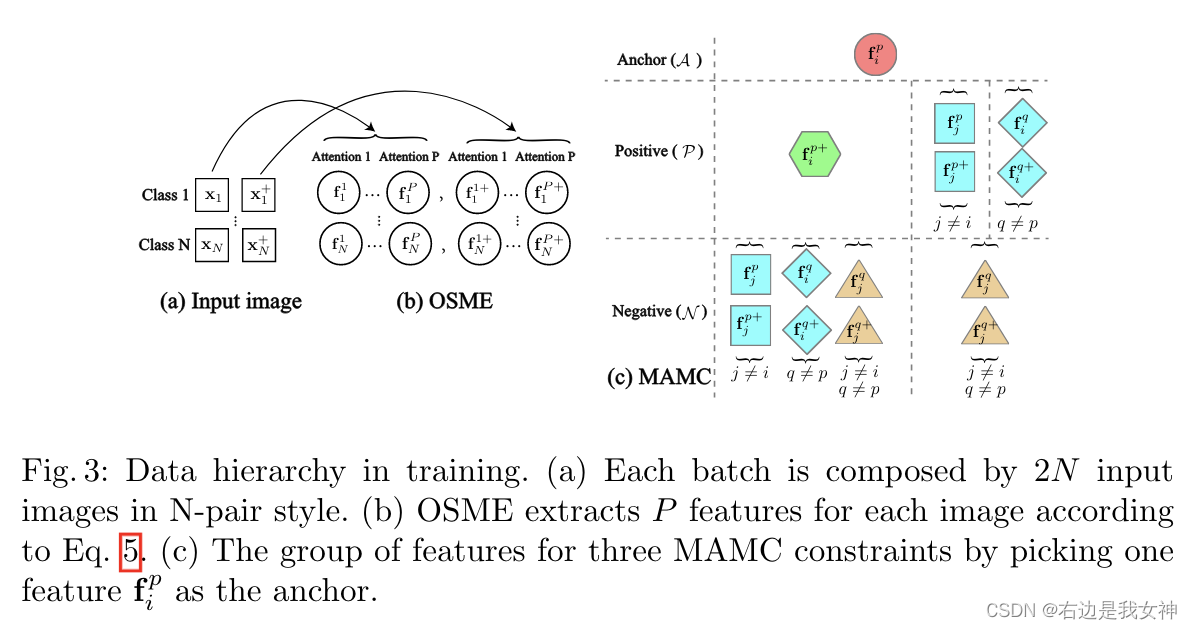
首先构建training batch, B = { ( x i , x i + , y i ) } i = 1 N B=\{(x_i,x_i^+,y_i)\}_{i=1}^N B={(xi,xi+,yi)}i=1N。这通过采样N对图片得到。
对类别 y i y_i yi的每一对图像 ( x i , x i + ) (x_i,x_i^+) (xi,xi+)来说,OSME先提取attention feature { f i p , f i p + } \{f_i^p,f_i^{p+}\} {fip,fip+}。
每个branch给2N个样本,然后本文的灵感来源于2NP个特征之间的自然聚类。通过选择
f
i
p
f_i^p
fip(第i类、第p个特征区域)作为锚点,对余下的特征分为四组:

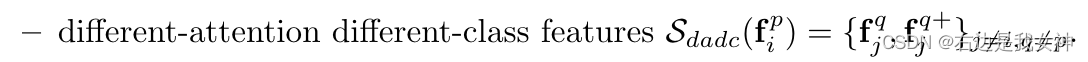
本文的目标是在度量学习的框架下,挖掘这四组的丰富的相关性。
于是,我们产生了以下三组约束:

总结
OSME模块在于融入attention得到更具有区分度的特征,其中应用了SENet的一些内容,构建起了模型的框架。
MAMC属于是对模型学习的一个探讨,为了让不同的attention分支关注不同的内容,也为了让其了解不同class之间的关系,而提出的约束方案。

