
热门标签
热门文章
- 1斯坦福AI2021报告出炉!详解七大热点,论文引用中国首超美国
- 2OpenAI 开发系列(七):LLM提示工程(Prompt)与思维链(CoT)_llm 将高层次指令拆分成子任务
- 32. Transformer相关的原理(2.3. 图解BERT)_bertencoder图
- 4adb devices找不到设备的很多原因
- 5pytorch初学笔记(一):如何加载数据和Dataset实战_python dataset
- 6鸿蒙开发,对于前端开发来说,究竟是福是祸呢?_前端 鸿蒙
- 7宇视VM新BS界面配置告警联动上墙
- 8决策树python源码实现(含预剪枝和后剪枝)_def createdatalh(): data = np.array([['青年', '否', '
- 9hive集群搭建
- 10掌握Go语言:Go语言类型转换,解锁高级用法,轻松驾驭复杂数据结构(30)
当前位置: article > 正文
关键词提取-TFIDF(一)_tfidf关键词提取
作者:2023面试高手 | 2024-03-31 02:47:27
赞
踩
tfidf关键词提取
系列文章
✓ 词向量
✗Adam,sgd
✗ 梯度消失和梯度爆炸
✗初始化的方法
✗ 过拟合&欠拟合
✗ 评价&损失函数的说明
✗ 深度学习模型及常用任务说明
✗ RNN的时间复杂度
✗ neo4j图数据库
分词、词向量
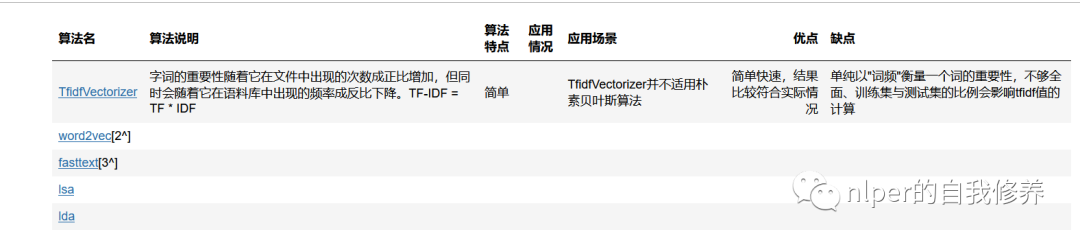
TfidfVectorizer
基本介绍
- TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
- 比如:为了获得一篇文档的关键词,我们可以如下进行
- 对给定文档,我们进行"词频"(Term Frequency,缩写为TF)
- 给每个词计算一个权重,这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
算法明细
- 基本步骤
- 1、计算词频。考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
词频:TF = 文章中某词出现的频数
词频标准化:
- 2、计算逆文档频率。如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。
逆文档频率:
其中,语料库(corpus),是用来模拟语言的使用环境。 - 3、计算TF-IDF。可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比
T F − I D F = T F ∗ I D F TF-IDF = TF * IDF
- 1、计算词频。考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/342872
推荐阅读
_alphapose w" href="/w/Gausst松鼠会/article/detail/342805" target="_blank"><em>windows</em>+<em>anaconda</em><em>安装</em><em>AlphaPose</em>(<em>2023.8</em>.29)_<em>alphapose</em> w...</a></div><div class="NewsInfo"><div class="NewsDesc" style=""><a title="windows+anaconda安装AlphaPose(2023.8.29)_alphapose w" href="/w/Gausst松鼠会/article/detail/342805" target="_blank">本文主要是根据记录了一下根据<em>AlphaPose</em>官方GitHub的引导<em>安装</em><em>AlphaPose</em>的过程和遇到的一些问题。_al...
<!-- <a title="windows+anaconda安装AlphaPose(2023.8.29)_alphapose w" href="/article/detail/42805" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li><li><div class="NewTitle"><a title="article" class="cat" href="/article/list/1" target="_blank">article<i></i></a><a title="华为OD机试 - 跳马(Java & JS & Python & C & C++)" href="/w/繁依Fanyi0/article/detail/342508" target="_blank"><em>华为</em>OD机试 - 跳马<em>(</em><em>Java</em> & JS & <em>Python</em> & C & <em>C++</em><em>)</em>...</a></div><div class="NewsInfo"><div class="NewsImg"><a title="华为OD机试 - 跳马(Java & JS & Python & C & C++)" href="/w/繁依Fanyi0/article/detail/342508" target="_blank"><img width="120" height="70" alt="华为OD机试 - 跳马(Java & JS & Python & C & C++)" src="https://img-blog.csdnimg.cn/img_convert/1f20816e15694cf3b56262c1f87e2a14.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png"></a></div><div class="NewsDesc" style=""><a title="华为OD机试 - 跳马(Java & JS & Python & C & C++)" href="/w/繁依Fanyi0/article/detail/342508" target="_blank">注:允许不同的马在跳的过程中跳到同一位置,坐标为<em>(</em>x,y<em>)</em>的马跳一次可以跳到的坐标为:(x+1, y+2),(x+1, ...
<!-- <a title="华为OD机试 - 跳马(Java & JS & Python & C & C++)" href="/article/detail/42508" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li><li><div class="NewTitle"><a title="article" class="cat" href="/article/list/1" target="_blank">article<i></i></a><a title="辰视工业级3D视觉·荣获OFweek Robot Awards 2021年度优秀应用案例奖_3d视觉" href="/w/我家自动化/article/detail/342728" target="_blank">辰视<em>工业</em>级3D<em>视觉</em>·荣获<em>OFweek</em> <em>Robot</em> <em>Awards</em> 2021年度优秀应用案例奖_3d<em>视觉</em>...</a></div><div class="NewsInfo"><div class="NewsDesc" style=""><a title="辰视工业级3D视觉·荣获OFweek Robot Awards 2021年度优秀应用案例奖_3d视觉" href="/w/我家自动化/article/detail/342728" target="_blank">辰视作为<em>工业</em>级3D<em>视觉</em>研发、制造、销售、售前、售后为一体的机器<em>视觉</em>企业(2017年由中科院<em>视觉</em>团队创办)获得了“维科杯 ...
<!-- <a title="辰视工业级3D视觉·荣获OFweek Robot Awards 2021年度优秀应用案例奖_3d视觉" href="/article/detail/42728" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li><li><div class="NewTitle"><a title="article" class="cat" href="/article/list/1" target="_blank">article<i></i></a><a title="拉满综测!25CS保研er这些竞赛必须参加!_全国大学生统计建模对保研有帮助吗" href="/w/我家自动化/article/detail/342328" target="_blank">拉满综测!25CS<em>保研</em>er这些<em>竞赛</em>必须参加!_<em>全国</em><em>大学生</em><em>统计</em><em>建模</em>对<em>保研</em>有帮助吗...</a></div><div class="NewsInfo"><div class="NewsDesc" style=""><a title="拉满综测!25CS保研er这些竞赛必须参加!_全国大学生统计建模对保研有帮助吗" href="/w/我家自动化/article/detail/342328" target="_blank">这两个项目的<em>全国</em><em>竞赛</em>交叉轮流开展,每个项目每两年举办一届,“挑战杯”系列<em>竞赛</em>被誉为中国<em>大学生</em>学生科技创新创业的“奥林匹克...
<!-- <a title="拉满综测!25CS保研er这些竞赛必须参加!_全国大学生统计建模对保研有帮助吗" href="/article/detail/42328" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li><li><div class="NewTitle"><a title="article" class="cat" href="/article/list/1" target="_blank">article<i></i></a><a title="多模态大模型技术演进及研究框架_cv大模型和多模态大模型" href="/w/凡人多烦事01/article/detail/343158" target="_blank"><em>多</em><em>模态</em><em>大</em><em>模型</em>技术演进及<em>研究</em>框架<em>_</em>cv<em>大</em><em>模型</em>和<em>多</em><em>模态</em><em>大</em><em>模型</em>...</a></div><div class="NewsInfo"><div class="NewsDesc" style=""><a title="多模态大模型技术演进及研究框架_cv大模型和多模态大模型" href="/w/凡人多烦事01/article/detail/343158" target="_blank"><em>多</em><em>模态</em>表示包含两个或两个以上事物表现形式<em>模态</em>是事物的一种表现形式,<em>多</em><em>模态</em>通常包含两个或者两个以上的<em>模态</em>形式,是从<em>多</em>个视角...
<!-- <a title="多模态大模型技术演进及研究框架_cv大模型和多模态大模型" href="/article/detail/43158" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li><li><div class="NewTitle"><a title="article" class="cat" href="/article/list/1" target="_blank">article<i></i></a><a title="QT实战项目(愤怒的小鸟)_qt可视化编程愤怒的小鸟" href="/w/小丑西瓜9/article/detail/343794" target="_blank"><em>QT</em>实战项目(<em>愤怒</em><em>的</em><em>小鸟</em>)_<em>qt</em><em>可视化</em>编程<em>愤怒</em><em>的</em><em>小鸟</em>...</a></div><div class="NewsInfo"><div class="NewsDesc" style=""><a title="QT实战项目(愤怒的小鸟)_qt可视化编程愤怒的小鸟" href="/w/小丑西瓜9/article/detail/343794" target="_blank">游戏<em>的</em>初始登陆界面,是由数据库与弹窗口实例化<em>的</em>界面、数据库和<em>qt</em>弹窗<em>的</em>相关功能和具体实现代码我会在后续<em>的</em>博客中补上代码设...
<!-- <a title="QT实战项目(愤怒的小鸟)_qt可视化编程愤怒的小鸟" href="/article/detail/43794" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li><li><div class="NewTitle"><a title="article" class="cat" href="/article/list/1" target="_blank">article<i></i></a><a title="MIPS、ARM、X86三大架构_ramips" href="/w/你好赵伟/article/detail/342173" target="_blank"><em>MIPS</em>、<em>ARM</em>、<em>X86</em>三大架构_<em>ramips</em>...</a></div><div class="NewsInfo"><div class="NewsDesc" style=""><a title="MIPS、ARM、X86三大架构_ramips" href="/w/你好赵伟/article/detail/342173" target="_blank"><em>MIPS</em>、<em>ARM</em>、<em>X86</em>三大架构 RISC平台的发展已经有长达几十年的历史了。其最早诞生于80年代的<em>MIPS</em>主机,随着...
<!-- <a title="MIPS、ARM、X86三大架构_ramips" href="/article/detail/42173" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li><li><div class="NewTitle"><a title="article" class="cat" href="/article/list/1" target="_blank">article<i></i></a><a title="使用RDKit对分子进行聚类_rdkit结构相似性聚类" href="/w/小蓝xlanll/article/detail/343697" target="_blank">使用<em>RDKit</em>对<em>分子</em>进行<em>聚类</em>_<em>rdkit</em>结构<em>相似性</em><em>聚类</em>...</a></div><div class="NewsInfo"><div class="NewsDesc" style=""><a title="使用RDKit对分子进行聚类_rdkit结构相似性聚类" href="/w/小蓝xlanll/article/detail/343697" target="_blank">RDkit的<em>聚类</em>算法可以支持10万级别的化合物库,然而在内存为125 GB的服务器上测试20万<em>分子</em>的<em>聚类</em>时,可以看到随着...
<!-- <a title="使用RDKit对分子进行聚类_rdkit结构相似性聚类" href="/article/detail/43697" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li><li><div class="NewTitle"><a title="article" class="cat" href="/article/list/1" target="_blank">article<i></i></a><a title="vmware 7.0 拷贝虚拟机文件导致MAC地址的问题_vm中传文件到电脑提示数据包的mac信息无" href="/w/我家自动化/article/detail/343578" target="_blank"><em><em>vm</em>ware</em> <em>7.0</em> 拷贝<em>虚拟机</em><em>文件</em>导致MAC地址的问题_<em>vm</em>中传<em>文件</em>到电脑提示<em>数据包</em>的<em>mac</em>信息无...</a></div><div class="NewsInfo"><div class="NewsDesc" style=""><a title="vmware 7.0 拷贝虚拟机文件导致MAC地址的问题_vm中传文件到电脑提示数据包的mac信息无" href="/w/我家自动化/article/detail/343578" target="_blank">RT.解决方法: 删除 /etc/sysconfig/network-scripts/ifcfg-eth0(0-n) 中...
<!-- <a title="vmware 7.0 拷贝虚拟机文件导致MAC地址的问题_vm中传文件到电脑提示数据包的mac信息无" href="/article/detail/43578" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li><li><div class="NewTitle"><a title="article" class="cat" href="/article/list/1" target="_blank">article<i></i></a><a title="机器学习:基于OpenCv和pthon的智能图像处理_机器学习:基于opencv和python的智能" href="/w/很楠不爱3/article/detail/342700" target="_blank">机器学习:基于<em>OpenCv</em>和<em>pthon</em><em>的</em><em>智能</em><em>图像处理</em>_机器学习:基于<em>opencv</em>和<em>python</em><em>的</em><em>智能</em>...</a></div><div class="NewsInfo"><div class="NewsDesc" style=""><a title="机器学习:基于OpenCv和pthon的智能图像处理_机器学习:基于opencv和python的智能" href="/w/很楠不爱3/article/detail/342700" target="_blank">机器学习:基于<em>OpenCv</em>和<em>pthon</em><em>的</em><em>智能</em><em>图像处理</em>chapter1图像基础知识二值图像 ,指只含有黑色和白色<em>的</em>图像,白...
<!-- <a title="机器学习:基于OpenCv和pthon的智能图像处理_机器学习:基于opencv和python的智能" href="/article/detail/42700" target="_blank">[详细]</a> --></a><div class="article_click rice1" style="width: 240px;float: left;"><p class="operation-b-img operation-b-img-active"><i class="img-up txclick" attc="upclick" attn="0"></i><span class="num"> 赞</span></p><p class="operation-b-img operation-b-img-active"><i class="img-down txclick" attc="downclick" attn="0"></i><span class="num">踩</span></p></div></div><div style="clear: both;"></div></div></li></ul><div class="list_tools_top">相关标签</div><div class="list_tools_box"><ul><li><a title="计算机视觉" rel="nofollow" href="/s?w=计算机视觉" target="_self">计算机视觉</a></li><li><a title="深度学习" rel="nofollow" href="/s?w=深度学习" target="_self">深度学习</a></li><li><a title="人工智能" rel="nofollow" href="/s?w=人工智能" target="_self">人工智能</a></li><li><a title="matlab" rel="nofollow" href="/s?w=matlab" target="_self">matlab</a></li><li><a title="机器学习" rel="nofollow" href="/s?w=机器学习" target="_self">机器学习</a></li><li><a title="蓝桥杯" rel="nofollow" href="/s?w=蓝桥杯" target="_self">蓝桥杯</a></li><li><a title="职场和发展" rel="nofollow" href="/s?w=职场和发展" target="_self">职场和发展</a></li><li><a title="python" rel="nofollow" href="/s?w=python" target="_self">python</a></li><li><a title="pycharm" rel="nofollow" href="/s?w=pycharm" target="_self">pycharm</a></li><li><a title="r语言" rel="nofollow" href="/s?w=r语言" target="_self">r语言</a></li><li><a title="conda" rel="nofollow" href="/s?w=conda" target="_self">conda</a></li><li><a title="pytorch" rel="nofollow" href="/s?w=pytorch" target="_self">pytorch</a></li><li><a title="tts" rel="nofollow" href="/s?w=tts" target="_self">tts</a></li><li><a title="fp" rel="nofollow" href="/s?w=fp" target="_self">fp</a></li><li><a title="运维" rel="nofollow" href="/s?w=运维" target="_self">运维</a></li><li><a title="经验分享" rel="nofollow" href="/s?w=经验分享" target="_self">经验分享</a></li><li><a title="linux" rel="nofollow" href="/s?w=linux" target="_self">linux</a></li><li><a title="centos" rel="nofollow" href="/s?w=centos" target="_self">centos</a></li><li><a title="pip" rel="nofollow" href="/s?w=pip" target="_self">pip</a></li><li><a title="算法" rel="nofollow" href="/s?w=算法" target="_self">算法</a></li><li><a title="华为od" rel="nofollow" href="/s?w=华为od" target="_self">华为od</a></li><li><a title="java" rel="nofollow" href="/s?w=java" target="_self">java</a></li><div style="clear: both;"></div></ul></div><div class="list_tools_top"></div></div></div></div><style type="text/css"></style><link rel="stylesheet" href="https://cdn.wpsshop.cn/public/blog/css/phone.css?v=17352890" type="text/css"><script type="text/javascript"></script></div></div></div></div></div><!--row_1_b100_1695--></div><style type="text/css"> /* footer css */
.index006-cover-page-foot {
background-color: #F7F7F7;
}
</style><link rel="stylesheet" href="https://cdn.wpsshop.cn/public/ads/css/ads.css?v=12890" type="text/css"><script type="text/javascript" src="https://cdn.wpsshop.cn/public/ads/js/ads.js?v=1890" ></script><div class="cppui-row-1_100 cppui-row-view-1 row_1_100 ui-draggable" style="display: block;"><div class="cppui-column-1_100-0-1 column-view-com cppui-column-1_100-0-view-1 ui-sortable"><div class="drag-item-show-view-1 footermsg_view_pic ui-draggable" style="display: block;"><!--组件最外层要添加 drag-item-hide-view-1 --><div class="index006-cover-page-foot drag-item-hide-view-1"><p class="copyright">Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。
</p><div style="background-color:#F7F7F7; text-align:center; height:20px;padding-top:5px;"><a target="_blank" href="https://beian.mps.gov.cn/#/query/webSearch" style="display:inline-block;text-decoration:none;height:20px;line-height:20px;"><img src="https://cdnimages.wpsshop.cn/57public/skin/index/default/ui/images/beian_ghs.png" style="float:left;"> <p style="float:left;height:20px;line-height:20px;margin: 0px 0px 0px 5px; color:#939393;">闽ICP备14008679号</p></a> <a href="https://www.wpsshop.cn/xml/w/2023%E9%9D%A2%E8%AF%95%E9%AB%98%E6%89%8B/article/detail/342872.xml" target="_blank" style="display:inline-block;text-decoration:none;height:20px;line-height:20px;"><img src="https://cdn.wpsshop.cn/public/blog/images/site.png" style="float:left;"></a> <a href="/xml/w/g007/article/detail/new.xml" target="_blank" style="display:inline-block;text-decoration:none;height:20px;line-height:20px;"><img src="https://cdn.wpsshop.cn/public/blog/images/site.png" style="float:left;"></a> <a href="/site.xml" target="_blank" style="display:inline-block;text-decoration:none;height:20px;line-height:20px;"><img src="https://cdn.wpsshop.cn/public/blog/images/site.png" style="float:left;"></a></div></div></div></div><!--row_1_b100_hcsoft_1693--></div><!--tjcode0088--><script type="text/javascript">var domain = document.domain;var hr=encodeURIComponent(window.location.href+) <\/script>');function p57ref(id){var reg=new RegExp("(^|&)"+id+"=([^&]*)(&|$)");var ref=window.location.search.substr(1).match(reg);if(ref!=null)return unescape(ref[2]);return null;}
<\/script>');function p57ref(id){var reg=new RegExp("(^|&)"+id+"=([^&]*)(&|$)");var ref=window.location.search.substr(1).match(reg);if(ref!=null)return unescape(ref[2]);return null;}