
热门标签
热门文章
- 1已解决ERROR: Could not find a version that satisfies the requirement XXX
- 2华为nova7se活力版和华为畅享20pro的区别_华为nova12活力版怎么样
- 3Ubuntu16.04 安装 indicator-sysmonitor_indicator-sysmonitor : depends: python3-psutil but
- 4unity更改模型的坐标轴位置_unity如何改变物体坐标轴
- 5labelme使用教程_labelme打开图片闪退
- 6YOLOPose实战:手把手实现端到端的人体姿态估计+原理图与代码结构_yolo-pose如何定义姿态
- 7「AI作曲家」Suno 使用 v3 在几秒钟内创作完整的两分钟歌曲_suno生成2分钟以上的
- 8NLP与AI会议期刊详细整理「CCF, SCI」_ai比较好中的trans期刊
- 9SpringCloud-实现基于RabbitMQ的消息队列_springcloud rabbitmq
- 10大模型强化学习:RLHF、PPO_大模型 rl
当前位置: article > 正文
nlp入门之jieba分词器
作者:2023面试高手 | 2024-03-31 09:04:23
赞
踩
jieba分词器
源码请到:自然语言处理练习: 学习自然语言处理时候写的一些代码 (gitee.com)
说到中文分词,就不得不提jieba分词器,虽然已经很久没有更新,但是依然很好用
5.1 jieba分词器安装
jieba分词器安装十分方便,输入命令就可安装成功
pip install jieba5.2 分词工具
jieba分词器提供了中文的分词工具,并且有精确模式和全模式两种模式,默认是精确模式
示例:
- # 分词工具
- seg_list = jieba.cut('我来到北京清华大学', cut_all=True)
- print('全模式:' + '/'.join(seg_list))
- seg_list = jieba.cut('我来到北京清华大学', cut_all=False)
- print('精确模式:' + '/'.join(seg_list))
- seg_list = jieba.cut('他来到网易杭研究大厦')
- print(','.join(seg_list))

5.3 添加自定义词典
jieba还可以添加自定义的词典,使分词更精准
示例:
- # 添加自定义词典
- text = '故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等'
- seg_list = jieba.cut(text, cut_all=True)
- print('全模式:' + '/'.join(seg_list))
- seg_list = jieba.cut(text, cut_all=False)
- print('精确模式:' + '/'.join(seg_list))

默认词典中不识别乾清宫和黄琉璃瓦,现在添加词典加入这两个词
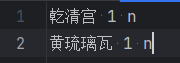
- jieba.load_userdict("./data/mydict.txt")
- # jieba.add_word("乾清宫")
- text = '故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等'
- seg_list = jieba.cut(text, cut_all=True)
- print('全模式:' + '/'.join(seg_list))
- seg_list = jieba.cut(text, cut_all=False)
- print('精确模式:' + '/'.join(seg_list))

5.4 关键字提取
根据词典中词语的频率,可以提取关键词
示例:
- # 关键字抽取
- seg_list = jieba.cut(text, cut_all=False)
- print(u"分词结果:")
- print('/'.join(seg_list))
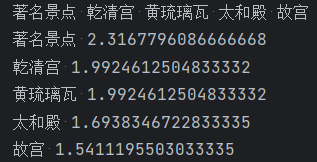
- tags = jieba.analyse.extract_tags(text, topK=5)
- print(u"关键字:")
- print(' '.join(tags))
- tags = jieba.analyse.extract_tags(text, topK=5, withWeight=True)
- for word, weight in tags:
- print(word, weight)
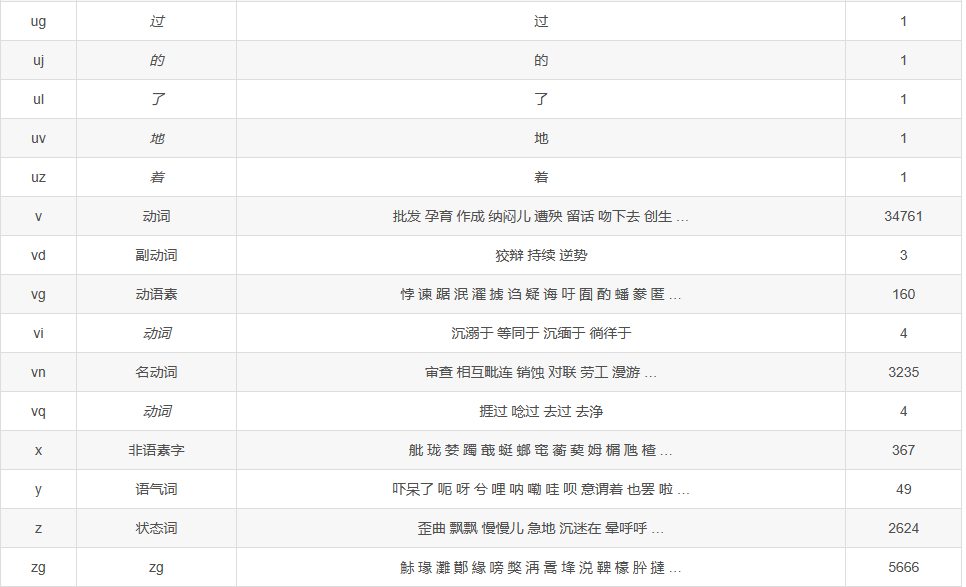
5.5 词性标注
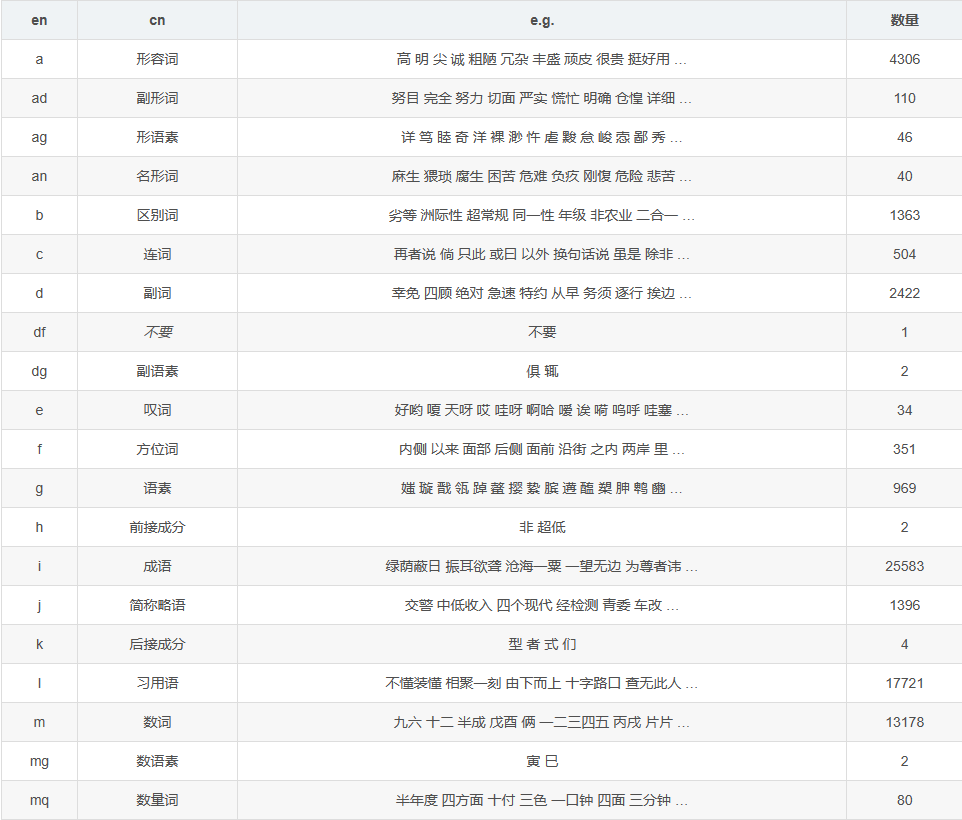
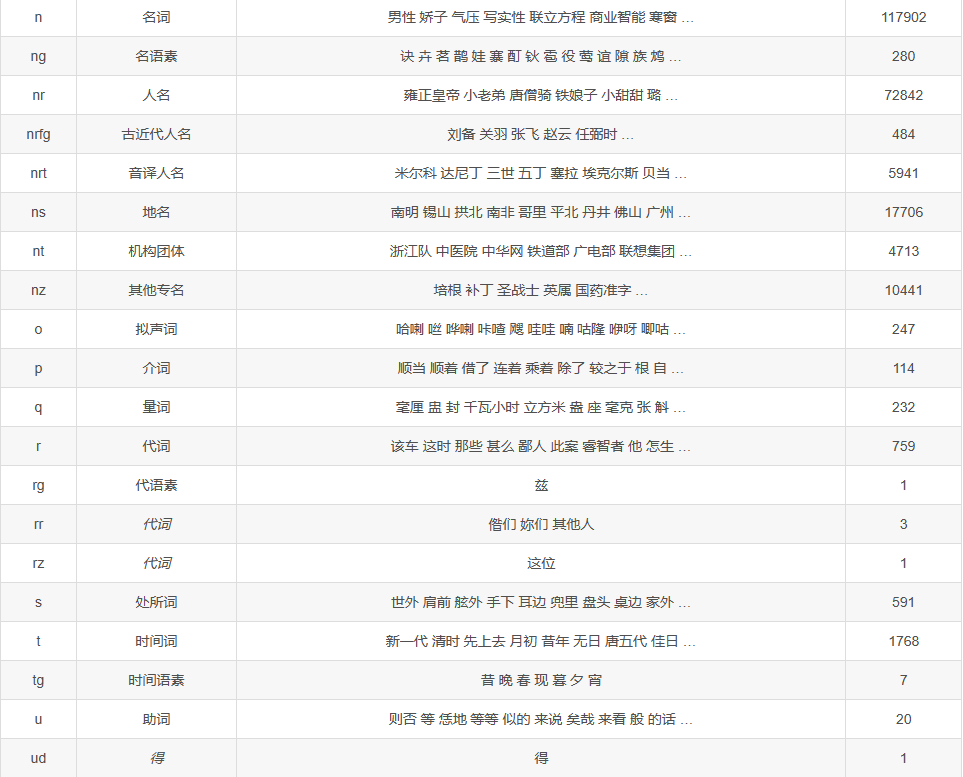
jieba也可以标注词性
示例:
- # 词性标注
- words = pseg.cut('我爱北京天安门')
- for word, flag in words:
- print('%s %s' % (word, flag))

5.6 词云展示
利用xxx的发言稿作为语料,进行分词并且统计频率最后画在一张图上体现出来关键字
示例
- # 词云展示
- data = {}
- with open('./data/19Congress.txt', 'r', encoding='utf-8') as f:
- text = f.read()
- with open('./data/stopwords.txt', encoding='utf-8') as file:
- stopwords = [line.strip() for line in file]
- seg_list = jieba.cut(text, cut_all=False)
- for word in seg_list:
- if len(word) >= 2:
- if not data.__contains__(word):
- data[word] = 0
- data[word] += 1
- print(data)
- my_wordclod = WordCloud(
- background_color='white', # 背景颜色
- max_words=400, # 设置最大实现的字数
- font_path=r'./data/SimHei.ttf', # 设置字体格式,不设置显示不了中文
- mask=imread('./data/mapofChina.jpg'), # 指定在什么图片上画
- width=1000,
- height=1000,
- stopwords=set(stopwords)
- ).generate_from_frequencies(data)
-
- plt.figure(figsize=(18,16))
- plt.imshow(my_wordclod)
- plt.axis('off')
- plt.show()
- my_wordclod.to_file('result.jpg')


其中原图是一张纯色的中国地图

运行后的结果

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/344069
推荐阅读
相关标签

