
- 1torchtext0.14 实践手册(0.12版本同理)
- 2Copilot插件使用介绍_copilot怎么用插件
- 3springboot项目:订单生成和沙箱支付_spring boot mysql 怎么储存多种订单号生成规则
- 4Sketchup模型与ArcGIS进行数据交互的方法_arcgis pro skp
- 5狂追ChatGPT:开源社区的“平替”热潮_chatglm 联互联网
- 6面试自我介绍范文(30篇)_面试自我介绍csdn
- 7iMX6ULL 软件定制应用笔记 -9个知识点讲解_imx6u pl2303
- 8Homebrew命令详解_brew命令详细解释
- 9批量免费AI写作工具,批量免费AI写作软件
- 10centos7 后台启动jar包
Python + 爬虫,分析一波京东评论 | 文末福利
赞
踩


作者 | 李秋键
头图 | 下载于ICphoto
出品 | AI 科技大本营(ID:rgznai100)
引言:
随着电子商务、社交媒体等信息技术的快速发展,在线评论已经成为影响消费者购买决策和产品市场销量的重要信息资源。从制造企业的视角来看,在线产品评论作为一种新的口碑形式,包含了消费者对产品的全方面评价,有助于制造企业了解消费者的需求。相比较传统的调查问卷和访谈数据,在线产品评论具有数据量大,收集成本低等优势。
此外,由于来自消费者的主动分享,而非被动问答,在线评论数据能够更真实地反映消费者的需求。在线评论数据形式主要包括文本、音频、图形等。尽管数据量大,更新速度快,数据种类繁多,但它的主要作用还是体现在其真实性和价值性上。
为保证数据的真实性,数据质量的评估是一个重要问题。另外,随着在线评论数据规模的不断扩大,价值稀疏问题也变得越来越重要。通过消除不重要和不相关的数据,提供有用的和有价值的数据,可以帮助企业更好地了解消费者和把握消费市场。
由此可见在当今大数据的环境下对于数据的掌握是极其重要的,故今天我们将实现京东评论的情感分析。
得到的模型评估效果如下可见:


数据处理
1.1 环境要求
本次环境使用的是python3.6.5+windows平台
主要用的库有:
codecs模块提供了流接口和文件接口来完成文本数据不同表示之间的转换。通常用于处理Unicode文本,不过也提供了其他编码来满足其他用途;
pickle模块实现了基本的数据序列化和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。numpy模块用来矩阵和数据的运算处理,其中也包括和深度学习框架之间的交互等。
Matplotlib是Python中专门用于数据可视化的第三方库,也是最为流行的绘图库。
pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
1.2 评论数据的获取
评论数据的获取需要使用爬虫技术,其实现过程如下:
第一,获取初始URL。初始URL地址可以由用户人为指定,也可以由用户指定的某个或某几个初始爬取网页决定。
第二,根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,需要先爬取对应URL地址中的网页,接着将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,并将已爬取的URL地址存放到一个URL列表中,用于去重及判断爬取的进程。
第三,将新的URL放到URL队列中,再于第二步内获取下一个新的URL地址之后,再将新的URL地址放到URL队列中。
第四,从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新的网页中获取新的URL并重复上述的爬取过程。
第五,满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫便会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。
通用爬虫技术应用有着不同的爬取策略,其中的广度优先策略以及深度优先策略都比较关键,深度优先策略的实施是依照深度从低到高的顺序来访问下一级网页链接。
- def jie_xi(url1, productId, url2, ran_num, url3):
- # 拼接URL并乱序循环抓取页面
- for i in ran_num:
- i = str(i)
- url = (url1+productId+url2+i+url3)
- r = requests.get(url=url, headers=headers, cookies=cookie)
- html = r.content # .content返回的是bytes型也就是二进制的数据
- print("当前抓取页面:", url, "状态:", r)
- html = str(html, encoding="GBK") # 对抓取的页面进行编码
- # file = open("page.txt", "w") # 将编码后的页面输出为txt文本存储
- # file.writelines(html)
- # 使用正则提取userClient字段信息
- user_comment = re.findall(r',.*?"content":(.*?),', html)
- # usera = re.findall(r',.*?"creationTime":(.*?),', html)
- # userd = re.findall(r',.*?"referenceName":(.*?),', html)
- write_to_csv(user_comment, productId)
- write_to_txt(user_comment, productId)
- print(user_comment)
- time.sleep(3)


1.3 词云可视化
词云图是文本分析中比较常见的一种可视化手段,将出现频率相对高的词字体相对变大,让重点词、关键词一目了然。
主要用到了python的两个库:wordcloud和jieba,直接pip安装即可。
jieba主要用于中文分词,wordcloud主要用于统计词频和绘图。
- def GetWordCloud():
- path_txt = './数据/评论100004917490.txt'
- path_img = "test.jpg"
- f = open(path_txt, 'r', encoding='utf-8').read()
- background_image = np.array(Image.open(path_img))
- # join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串
- cut_text = " ".join(jieba.cut(f))
- # mask参数=图片背景,必须要写上,另外有mask参数再设定宽高是无效的
- wordcloud = WordCloud(font_path="simhei.ttf", background_color="white", mask=background_image).generate(cut_text)
- # 生成颜色值
- image_colors = ImageColorGenerator(background_image)
- # 下面代码表示显示图片
- plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation="bilinear")
- # 获得模块所在的路径的
- d = path.dirname(__file__)
- # os.path.join(): 将多个路径组合后返回
- wordcloud.to_file(path.join(d, "1.png"))
- plt.axis("off")
- plt.show()
-
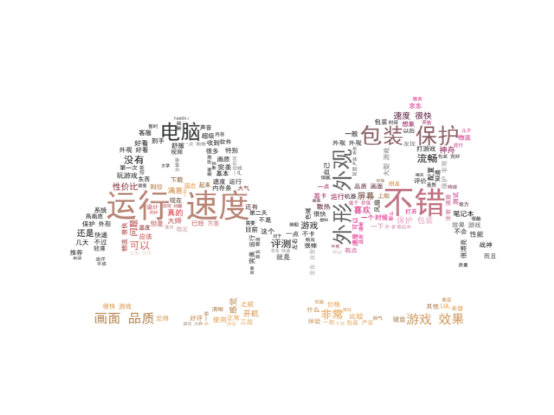

情感模型建立
文本情感分析又称意见挖掘,是指对带有情感色彩的主观性文本进行分析,挖掘其中蕴含的情感倾向,对情感态度进行划分。文本情感分析作为自然语言处理的研究热点,在舆情分析、用户画像和推荐系统中有很大的研究意义。文本情感分析的过程如图所示,包括原始数据的获取,数据的预处理、特征提取、分类器以及情感类别的输出。
原始数据的获取一般是通过网络爬虫获取相关数据,如新浪微博内容、推特语料、各大电商网站的评论等;数据预处理是指进行数据清洗去除噪声,常见的方法有去除无效字符和数据、统一数据类别(如中文或简体)、使用分词工具进行分词处理、停用词过滤等;特征提取根据使用的方法不同,会有不同的实现方法,在依赖不同的工具获得文本的数值向量表征时,常见的方法有词频计数模型N-gram和词袋模型TF-IDF,而深度学习方法的特征提取一般都是自动的;分类器输出得到文本的最终情感极性,常见的分类器方法有SVM和softmax。

首先需要进行文本特征选取,它是文本挖掘和信息检索领域的基本问题之一,旨在量化从文本中抽取出的特征词,并以此表示文本信息。
在情感词词典中,我们将情感词分成了积极情感倾向词和消极情感倾向词,所以我们只能知道这个客户所要表达的情感是积极的还是消极的,但还有些词汇虽不带有情感倾向性,但是却在评论中起到了修饰情感词的功能,显著增强评论的情感倾向性,比如评论“我觉得挺好的”和“物流非常快”中,“好”和“快”是表达客户情感倾向的词语,而修饰情感词“好”和“快”的“挺”、“非常”就是程度副词。程度副词本身不带有任何情感色彩,但是会增强或减弱情感词原本的情感程度,程度副词的修饰程度由强到弱分为很多等级,不同修饰强度的程度副词对情感词影响程度也不同。
关键代码如下:
- def __init__(self, filename=filename):
- if os.path.exists(filename):
- data = pd.read_csv(filename)
- self.data = shuffle(data)
- X_data = pd.DataFrame(data.drop('sentiment', axis=1))
- Y_data = column_or_1d(data[:]['sentiment'], warn=True)
- self.X_train, self.X_val,\
- self.y_train, self.y_val = train_test_split(X_data, Y_data, test_size=0.3, random_state=1)
- self.model = None
- self.load_model()
- self.preprocessor = Preprocessor.Preprocessor()
- else:
- print('No Source!')
- self.preprocessor.process_data()
-
- def load_model(self, filename='./model/model.pickle'):
- if os.path.exists(filename):
- with codecs.open(filename, 'rb') as f:
- f = open(filename, 'rb')
- self.model = pickle.load(f)
- else:
- self.train()
- def save_model(self, filename='./model/model.pickle'):
- with codecs.open(filename, 'wb') as f:
- pickle.dump(self.model, f)
- def train(self):
- self.model = LogisticRegression(random_state=3)
- self.model.fit(self.X_train, self.y_train)
- self.save_model()
- print('Accuracy: ' + str(round(self.model.score(self.X_val, self.y_val), 2)))
-
最终分类效果如下:
- 开源代码:https://codechina.csdn.net/qq_42279468/liqiujian_jd/-/tree/master
- 作者简介:李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。
-
- 你还知道哪些 Python 的新奇用法?
- 欢迎来评论区唠唠~
- AI科技大本营将选出三名优质留言
- 携手【中青雄狮出版社】送出
- 《Python文本数据分析与挖掘》一本
-
- 截至6月11日 14:00点
-
-
- 2001 年创刊,20 年技术见证
- 《新程序员001:开发者黄金十年》
- 重磅来袭
-
- 扫描下方二维码,添加小助手
- 即刻加入 AI 科技大本营「读者群」
- 群内将不定期放送福利
- 快快加入吧!
-

