
- 1聚焦ChatGPT4:开启中文及多语言主题新篇章!_gpt4all 如何训练中文
- 2AI绘画核心技术与实战【课程推荐】
- 3入门教程 Android实现一个简易的新闻列表APP(TabLayout+ViewPager+Fragment)_android新闻应用设计
- 4程序员如何提升自己的价值_程序员的需求的价值提升
- 5【postgresql 基础入门】数据类型介绍,整型,字符串,浮点数,日期时间类型特点,精度及表示范围,选择合适类型来提升性能_scale6 must round to an absolute value less than 1
- 6Windows下用Eclipse CDT 配置C/C++ 编译环境
- 7PyTorch笔记 - Position Embedding (Transformer/ViT/Swin/MAE)_position embding
- 8如何选择O2OA(翱途)开发平台的部署架构?
- 9谷歌gemma2b windows本地cpu gpu部署,pytorch框架,模型文件百度网盘下载_gemma部署 cpu
- 10AI人工智能进阶-BERT/Transformer/LSTM/RNN原理与代码
Vision Transformer结构原理+实战项目+代码讲解
赞
踩
简介
Transformer 模型是一种目前非常流行和成功的深度学习模型,Transformer模型最初提出用于NLP领域,取得了极大的成功,能有效地处理文本信息。它的优点在于擅长处理长文本,具有强大的记忆能力,可以并行计算。在自然界中人脑对于图像的观察也存在注意力机制,注意力会集中于图像中的关键信息。因此,注意力这个机制不仅可以用于自然语言处理(NLP)领域处理文本,还可以考虑应用于计算机视觉(CV)领域处理图像。Vision Transformer(ViT)是将传统的Transformer模型改进应用于计算机视觉领域。ViT 可以直接处理图像数据,不需要使用传统的 CNN 网络,因此可以避免 CNN 中的平移不变性假设和局部性假设。传统的CNN网络是提取图像的局部特征,若想获得全局特征,只能不断增加卷积层的堆叠层数,同时模型参数量和计算复杂度也会不断增加。而ViT可以直接提取图像的全局信息,不需要堆叠很多层,具有更好的表达能力和泛化能力。接下来将通过一个图像分类的实践项目来详细讲解ViT的模型结构以及具体应用的全过程。
1.数据集准备
该项目具有强大的泛化能力,适用于任何图像分类任务,只需要更换数据集和改变类别数目参数num_class即可 。
本项目主要利用ViT模型实现图像分类任务。这里的数据集采用开源数据集“Cat and Dog”,经典的猫狗大战,实现猫狗图像分类。数据集链接:Cat and Dog (kaggle.com)
将数据集下载解压,命名为data,按照以下格式存储并与代码文件放在同一目录下。
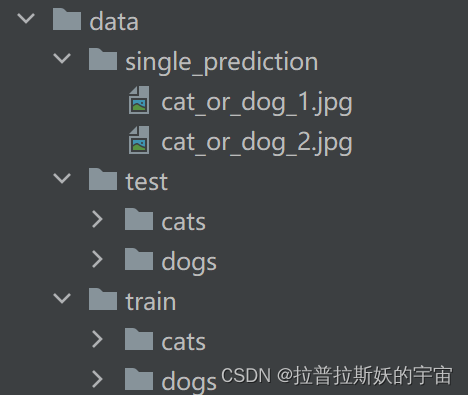
数据集中有3个文件,在此分别命名为train,test,single_prediction,train和test中包含cats和dogs两个文件夹分别存储猫和狗的图片(.jpg格式),train中有8000张图片用作训练集和验证集,test中有2000张图片用作测试集,single_prediction中有两张图片用于自行测试。
2.数据加载
深度学习任务中要把数据以data和label 的形式加载到dataloader中,一个batch一个batch的输入到神经网络模型中训练。因此数据加载是训练模型的第一步。
1.File_list
- train_dir = './data/train'
- test_dir = './data/test'
- train_list1 = glob.glob(os.path.join(train_dir+'/cats', '*.jpg'))
- train_list2 = glob.glob(os.path.join(train_dir+'/dogs', '*.jpg'))
- train_list = train_list1+train_list2
- test_list1 = glob.glob(os.path.join(test_dir+'/cats', '*.jpg'))
- test_list2 = glob.glob(os.path.join(test_dir+'/dogs', '*.jpg'))
- test_list = test_list1+test_list2
-
- labels = [path.split('/')[-1].split('.')[0] for path in train_list]
- train_list, valid_list = train_test_split(train_list,
- test_size=0.2,
- stratify=labels,
- random_state=seed)
- print(f"Train Data: {len(train_list)}")
- print(f"Validation Data: {len(valid_list)}")
- print(f"Test Data: {len(test_list)}")

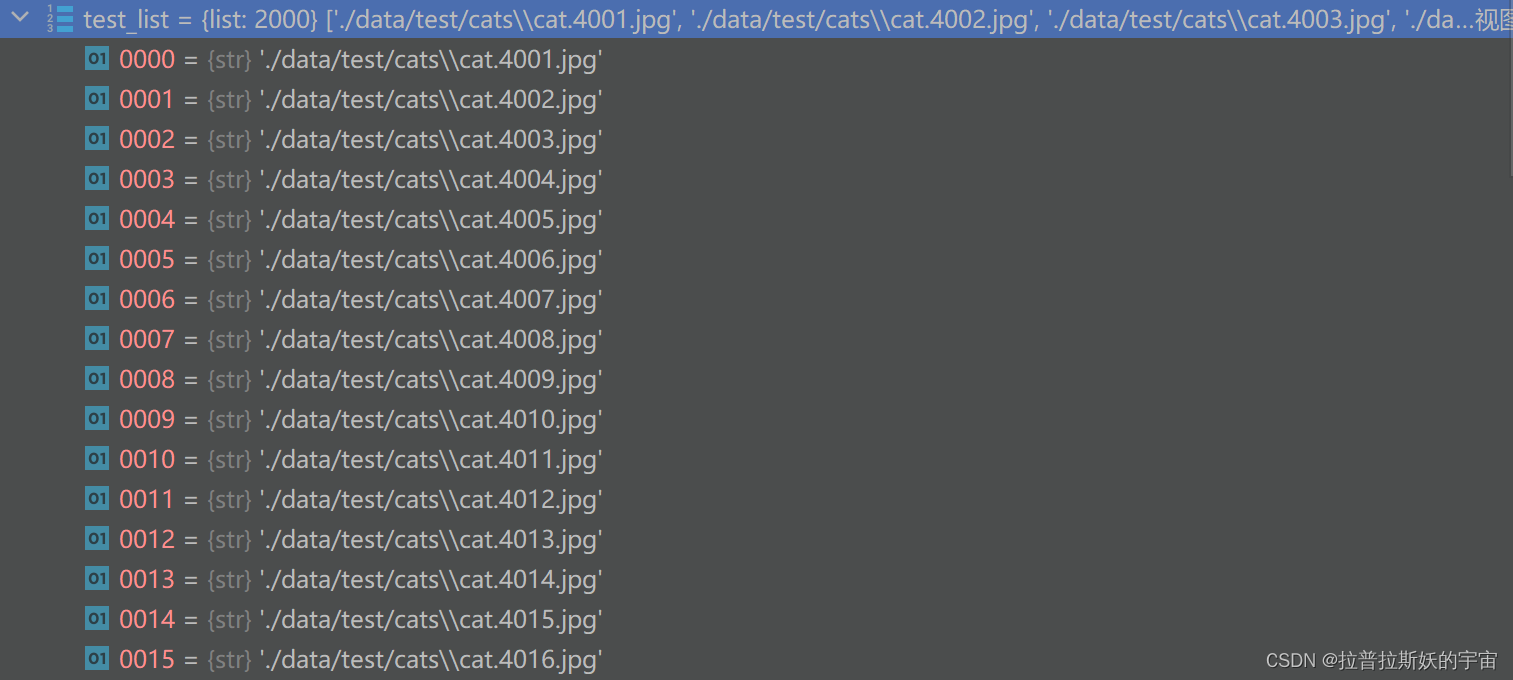
读取图片路径存储到file_list,调用train_test_split函数将train_list按80%划分为训练集,20%为验证集。从train_list中提取文件名cat/dog作为label。
2.Imge augumentation
- train_transforms = transforms.Compose(
- [
- transforms.Resize((224, 224)),
- transforms.RandomResizedCrop(224),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- ]
- )
-
- val_transforms = transforms.Compose(
- [
- transforms.Resize(256),
- transforms.CenterCrop(224),
- transforms.ToTensor(),
- ]
- )
-
- test_transforms = transforms.Compose(
- [
- transforms.Resize(256),
- transforms.CenterCrop(224),
- transforms.ToTensor(),
- ]
- )
3.Dataset
- class CatsDogsDataset(Dataset):
- def __init__(self, file_list, transform=None):
- self.file_list = file_list
- self.transform = transform
-
- def __len__(self):
- self.filelength = len(self.file_list)
- return self.filelength
-
- def __getitem__(self, idx):
- img_path = self.file_list[idx]
- img = Image.open(img_path)
- img_transformed = self.transform(img)
-
- label = img_path.split("/")[-1].split(".")[0]
- label = 1 if label == "dog" else 0
-
- return img_transformed, label
-
- train_data = CatsDogsDataset(train_list, transform=train_transforms)
- valid_data = CatsDogsDataset(valid_list, transform=test_transforms)
- test_data = CatsDogsDataset(test_list, transform=test_transforms)
Dataset:用于创建Pytorch可用的数据集
dataset类是一个抽象类,所有的数据集想要在数据与标签之间建立映射,都需要继承这个类,所有的子类都需要重写__getitem__方法,该方法根据索引值获取每一个数据并且获取其对应的label,子类也可以重写__len__方法,返回数据集的size大小。
__init__负责加载全部原始数据,初始化。
__len__负责返回数据集大小
__getitem__负责按索引取出某个数据,并对该数据做预处理。
本项目的CatsDogsDataset通过file_list根据索引idx获取图片路径img_path,再通过Image.open()读取图片img,然后经过transform得到数据img_transgormd和标签label。
4.Dataloader
- train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
- valid_loader = DataLoader(dataset=valid_data, batch_size=batch_size, shuffle=True)
- test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True)
Dataloader:数据加载器,用于向模型中输入数据
.Dataset类 当作一个参数传递给DataLoader类,得到一个数据加载器,这个数据加载器每次可以返回一个 Batch 的数据供模型训练使用。这一过程通常可以让我们把一张 生图 通过标准化、resize等操作转变成我们需要的 [B,C,H,W] 形状的 Tensor。
batch_size一般为2的整数倍,根据硬件算力调整大小,这里设为64。
shuffle为是否打乱顺序。
3.ViT
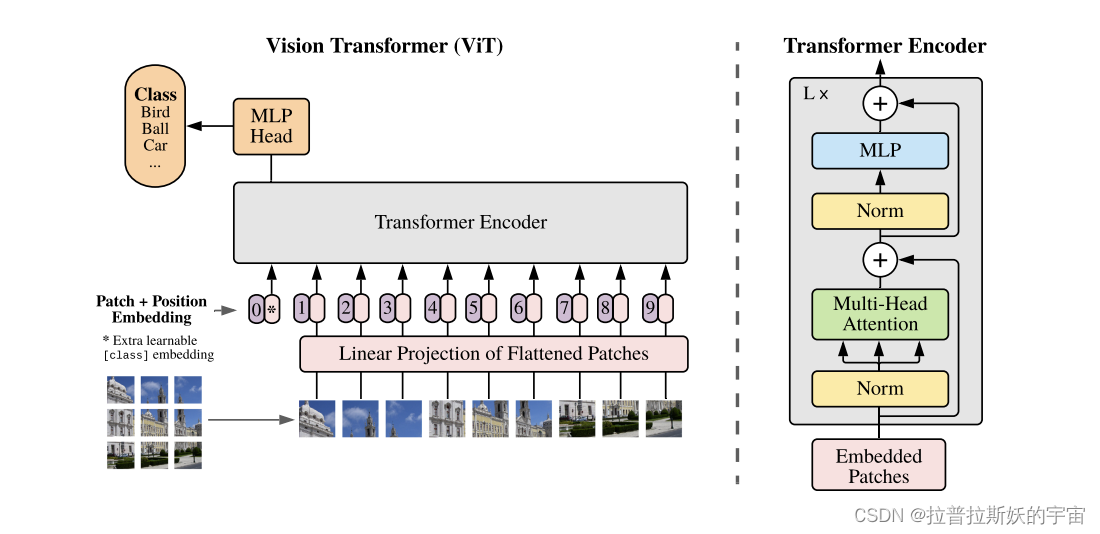
ViT模型是将注意力机制应用到计算机视觉领域中,与NLP中的传统transformer结构相似,但ViT模型中只有编码器Encoder没有解码器Decoder。
ViT模型主要由Patch Embedding、Positional Encoding、Transformer Encoder、MLP四部分组成。
1.Patch Embedding
Transformer模型最初用于自然语言处理领域(NLP),要求输入的是具有时序关系的向量序列(token)即[num_token,token_dim]的形式。因此如果要在计算机视觉领域(CV)中应用Transformer模型就要把图像转化成向量序列,Transformer模型致力于提取文本中的全局时序信息,而在CV中应用Transformer目的是为了提取图像的空间特征和全局信息。因此,ViT模型的提出了Patch Embedding,就是将一张图像切分成一个个小块(Patch),然后将Patch映射成向量,并转化成[num_token,token_dim]的形式。
- self.to_patch_embedding = nn.Sequential(
- Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
- nn.LayerNorm(patch_dim),
- nn.Linear(patch_dim, dim),
- nn.LayerNorm(dim),
- )
这段代码是 Transformer 模型中的Patch Embedding模块,用于将输入图像分成多个 patches,并将每个 patch 转换为一个嵌入向量(embedding)。另外也可以通过卷积层实现此功能。
具体来说,Rearrange 是torch的一个系统函数,它将输入的图像张量重排为一个新的形状,其中 patch_height 和 patch_width 分别表示 patch 的高度和宽度,patch_dim 表示每个 patch 被转换为嵌入向量后的维度,dim 表示整个模型的嵌入维度。
接下来,使用 nn.LayerNorm 对每个 patch 进行归一化处理,并使用 nn.Linear 将嵌入向量的维度变换为 dim。最后再次使用 nn.LayerNorm 对整个向量进行归一化处理。
举个例子来说明:
图像的输入数据格式为[b,c,h,w]。
假设我们有一个输入张量 x,形状为 (64, 3, 256, 256),其中:
- 64是批大小(batch size)
3是通道数(channels)- 256是图像的高度(height)
- 256是图像的宽度(width)
我们希望将每个图像分割成 16x16 的 patch,并将每个 patch 转换为一个嵌入向量。
经过重排操作后,输出张量 output 的形状为 (64, 256, 768):
- 64 是批大小,保持不变
- 256 是因为每个图像被分割成了 16
x16的网格,所以共有 16x16=256个 patch - 768 是因为每个 patch 被展平后得到的嵌入向量(token)的长度为 16
x16x3=768,其中 16x16是 patch 的像素数量,3是通道数
因此,Patch Embedding的输出张量可以看作是一个形状为 (64, 256, 768) 的三维张量,是[batch size,num_token,token_dim]的形式可以输入Transformer模型中。
2. Positional Encoding
-
- b, n, _ = x.shape
- cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
- x = torch.cat((cls_tokens, x), dim=1)
- x += self.pos_embedding[:, :(n + 1)]
- x = self.dropout(x)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))在输入Transformer Encoder之前注意需要加上[class]token以及Position Encoding。 在原论文中,作者是在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [256, 768]) -> [256, 768]。然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,位置编码就是给Patchs编号赋予位置信息。这里的Position Embedding采用的是一个可训练的参数,是直接叠加在tokens上的(add),所以shape要一样。,刚刚拼接[class]token后shape是[256, 768],那么这里的Position Embedding的shape也是[256, 768]。
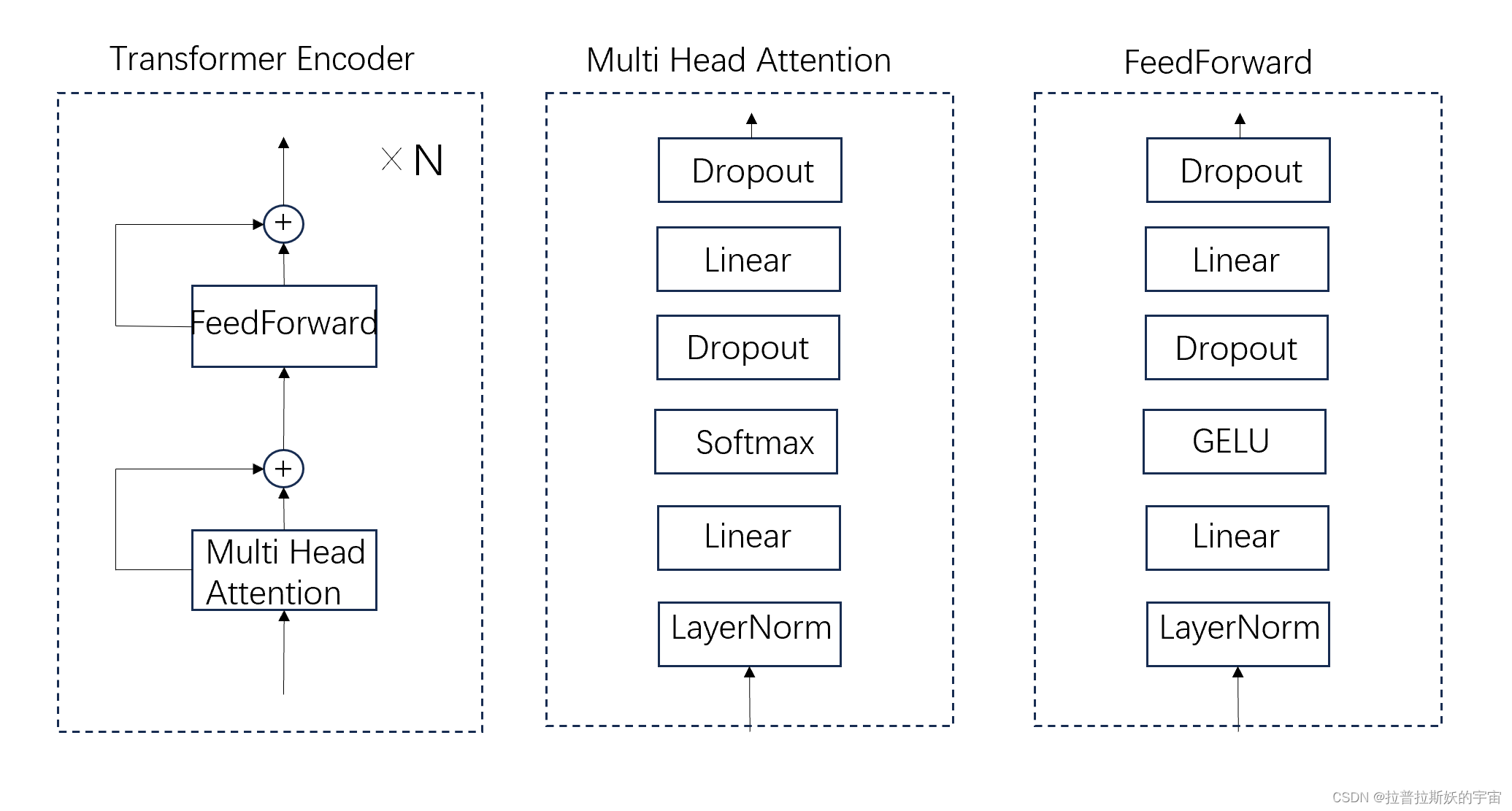
3.Transformer Encoder
- class Transformer(nn.Module):
- def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
- super().__init__()
- self.norm = nn.LayerNorm(dim)
- self.layers = nn.ModuleList([])
- for _ in range(depth):
- self.layers.append(nn.ModuleList([
- Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout),
- FeedForward(dim, mlp_dim, dropout = dropout)
- ]))
-
- def forward(self, x):
- for attn, ff in self.layers:
- x = attn(x) + x
- x = ff(x) + x
-
- return self.norm(x)
Transformer Encoder模块是由多层的Attention和FeedForward残差连接堆叠而成,attn(x)+x和ff(x)+x表示残差连接。
一个Attention主要包括Q(query),K(key),V(value)。
- Q是query,是输入的信息;key和value成组出现,通常是原始文本等已有的信息;
- 通过计算Q与K之间的相关性a,得出不同的K对输出的重要程度;
- 再与对应的v进行相乘求和,就得到了Q的输出;
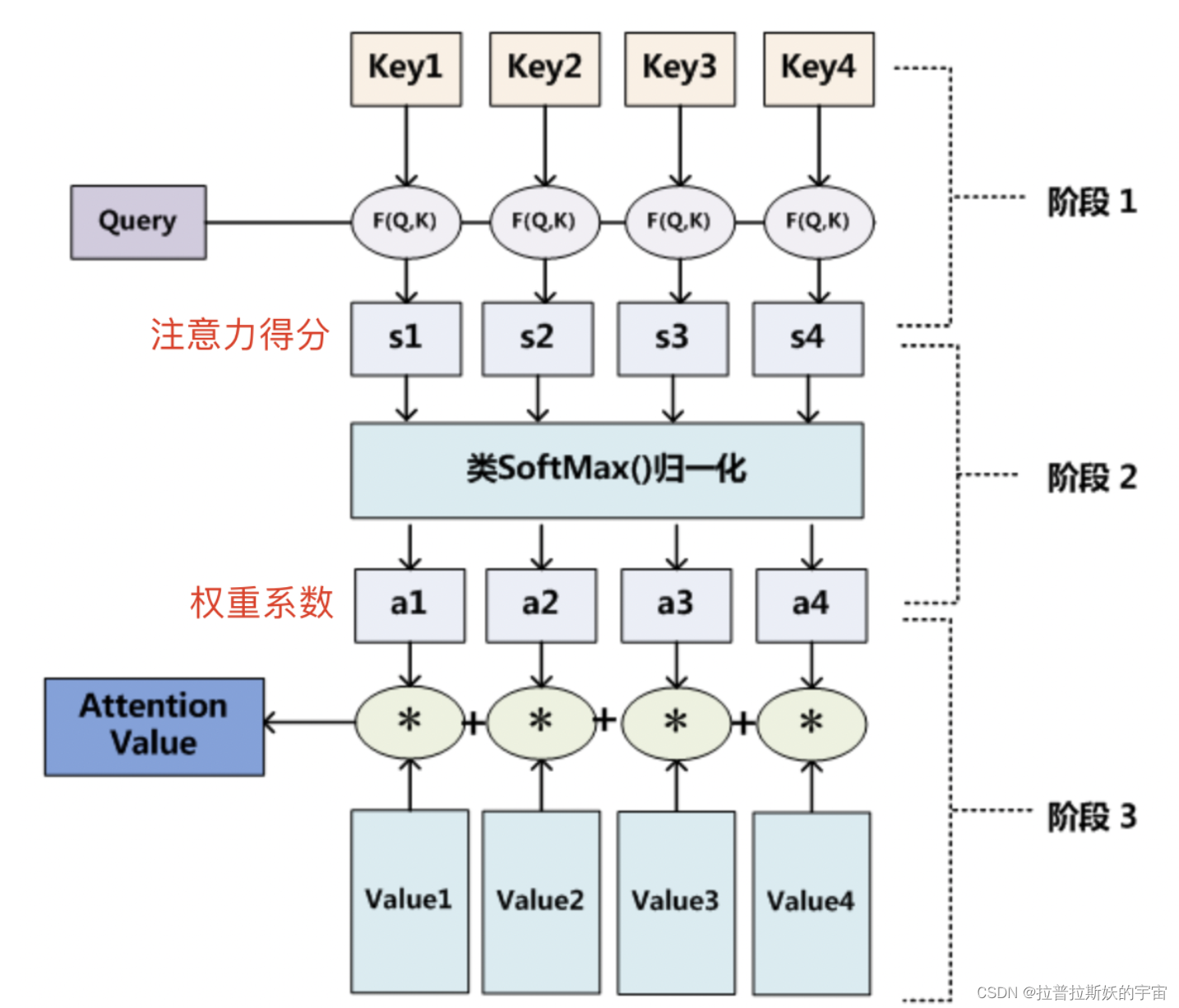
step1,计算Q对每个K的相关性。
step2,对step1的注意力的分进行归一化,转化为权重;
step3,根据权重系数对V进行加权求和,即可求出针对Query的Attention数值。
self-attention,顾名思义它只关注输入序列元素之间的关系,即每个输入元素都有它自己的Q、K、V。
Attention的计算公式为
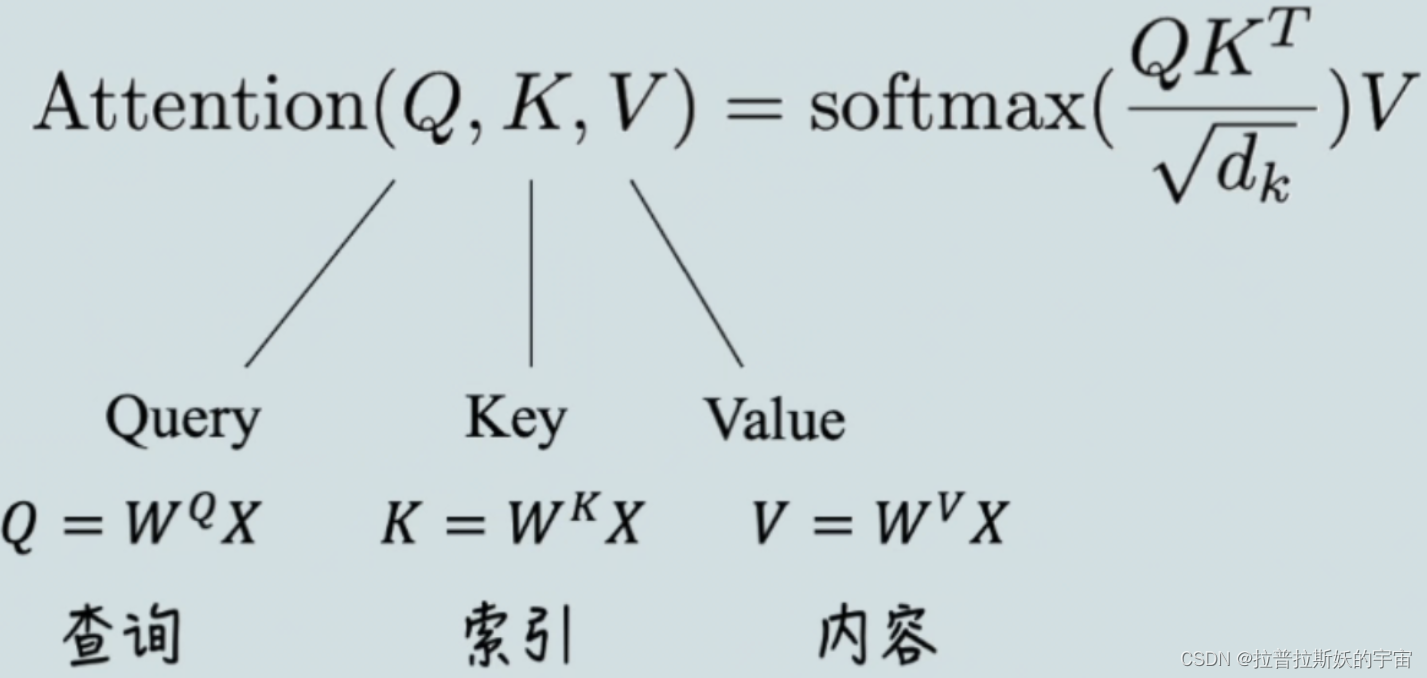
Q,K,V通过是向量X乘以权重矩阵,WQ、WK、WV 为可训练的参数,在代码中就是将向量直接输入到Linear线性层。
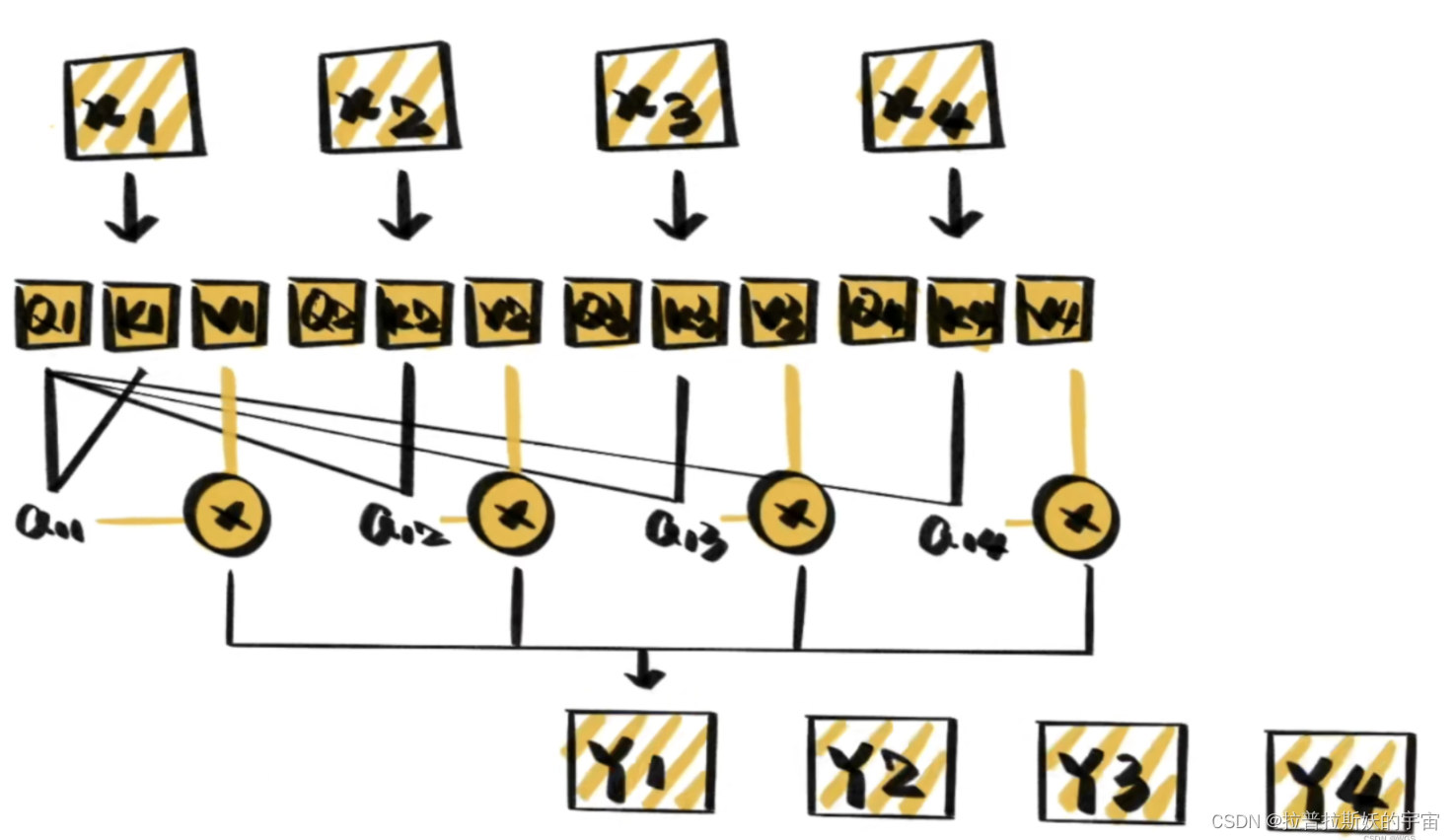
那么整个self-attention的计算过程可以如下:
1.首先就是基本的embedding将输入单词转为词向量;
2.根据嵌入向量利用矩阵乘法得到q、k、v三个向量;
3.为每一个向量计算一个相关性score:q ⋅ k T
4.为了梯度的稳定,防止梯度消失,除以根号dk;
5.进行softmax归一化得到权重系数;
6.与value点乘得到加权的每个输入向量的评分v;
7.相加之后得到最终的输出结果z
- class Attention(nn.Module):
- def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
- super().__init__()
- inner_dim = dim_head * heads
- project_out = not (heads == 1 and dim_head == dim)
- self.heads = heads
- self.scale = dim_head ** -0.5
- self.norm = nn.LayerNorm(dim)
- self.attend = nn.Softmax(dim = -1)
- self.dropout = nn.Dropout(dropout)
- self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
- self.to_out = nn.Sequential(
- nn.Linear(inner_dim, dim),
- nn.Dropout(dropout)
- ) if project_out else nn.Identity()
-
- def forward(self, x):
- x = self.norm(x)
- qkv = self.to_qkv(x).chunk(3, dim = -1)
- q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
- dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
- attn = self.attend(dots)
- attn = self.dropout(attn)
- out = torch.matmul(attn, v)
- out = rearrange(out, 'b h n d -> b n (h d)')
- return self.to_out(out)
FeedForward为前馈神经网络,也可理解为MLP多层感知机。由LayerNorm层归一化+Linear全连接层+GELU激活函数+Dropout构成。
- class FeedForward(nn.Module):
- def __init__(self, dim, hidden_dim, dropout = 0.):
- super().__init__()
- self.net = nn.Sequential(
- nn.LayerNorm(dim),
- nn.Linear(dim, hidden_dim),
- nn.GELU(),
- nn.Dropout(dropout),
- nn.Linear(hidden_dim, dim),
- nn.Dropout(dropout)
- )
-
- def forward(self, x):
- return self.net(x)
4.MLP Head
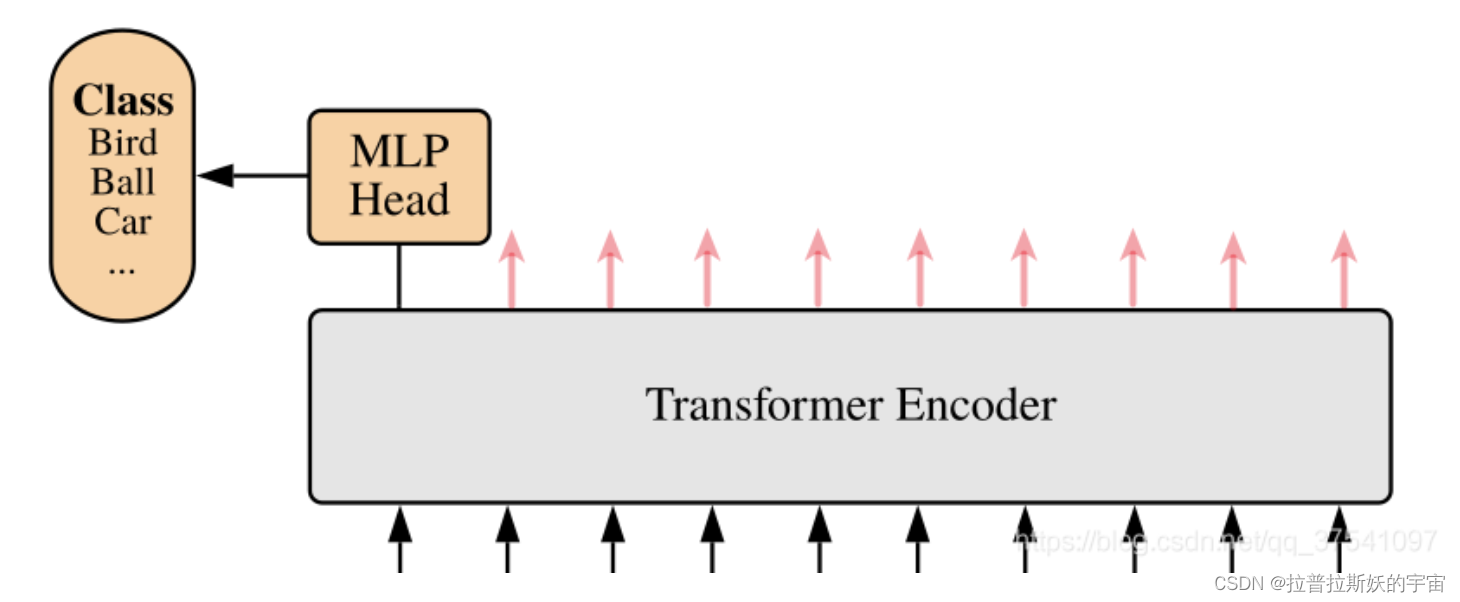
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。注意,在Transformer Encoder之后需要加一个MLP Head来输出分类结果。这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
self.mlp_head = nn.Linear(dim, num_classes),num_classes为分类的类别数。
5.ViT
- import torch
- from torch import nn
- from einops import rearrange, repeat
- from einops.layers.torch import Rearrange
-
- class ViT(nn.Module):
- def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
- super().__init__()
- image_height, image_width = pair(image_size)
- patch_height, patch_width = pair(patch_size)
- assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
- num_patches = (image_height // patch_height) * (image_width // patch_width)
- patch_dim = channels * patch_height * patch_width
- assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
- self.to_patch_embedding = nn.Sequential(
- Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
- nn.LayerNorm(patch_dim),
- nn.Linear(patch_dim, dim),
- nn.LayerNorm(dim),
- )
- self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
- self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
- self.dropout = nn.Dropout(emb_dropout)
- self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
- self.pool = pool
- self.to_latent = nn.Identity()
- self.mlp_head = nn.Linear(dim, num_classes)
-
- def forward(self, img):
- x = self.to_patch_embedding(img)
- print(x.shape)
- b, n, _ = x.shape
- cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
- x = torch.cat((cls_tokens, x), dim=1)
- x += self.pos_embedding[:, :(n + 1)]
- x = self.dropout(x)
- x = self.transformer(x)
- x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
- x = self.to_latent(x)
- return self.mlp_head(x)
4.模型训练
1. 超参数设置
- import glob
- from itertools import chain
- import os
- import random
- import zipfile
- import matplotlib.pyplot as plt
- import numpy as np
- import pandas as pd
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
- from linformer import Linformer
- from PIL import Image
- from sklearn.model_selection import train_test_split
- from torch.optim.lr_scheduler import StepLR
- from torch.utils.data import DataLoader, Dataset
- from torchvision import datasets, transforms
- from tqdm.notebook import tqdm
-
- batch_size = 64
- epochs = 10
- lr = 3e-5
- gamma = 0.7
- seed = 42
-
- def seed_everything(seed):
- random.seed(seed)
- os.environ['PYTHONHASHSEED'] = str(seed)
- np.random.seed(seed)
- torch.manual_seed(seed)
- torch.cuda.manual_seed(seed)
- torch.cuda.manual_seed_all(seed)
- torch.backends.cudnn.deterministic = True
- seed_everything(seed)
-
- device = 'cuda'
2.训练与验证
- model = ViT(
- image_size = 256,
- patch_size = 16,
- num_classes =2,
- dim = 1024,
- depth = 6,
- heads = 16,
- mlp_dim = 2048,
- dropout = 0.1,
- emb_dropout = 0.1
- ).to(device)
-
- print(model)
-
- # from torchsummary import summary
- # from ptflops import get_model_complexity_info
- #
- # summary(model,(3,256,256))
- # get_model_complexity_info(model,(3,256,256))
-
- # loss function
- criterion = nn.CrossEntropyLoss()
- # optimizer
- optimizer = optim.Adam(model.parameters(), lr=lr)
- # scheduler
- scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
- best_accuracy = 0
- if os.path.exists('best.mdl'):
- model.load_state_dict(torch.load('best.mdl'))
- for epoch in range(epochs):
- #train
- epoch_loss = 0
- epoch_accuracy = 0
- for data, label in tqdm(train_loader):
- data = data.to(device)
- label = label.to(device)
- output = model(data)
- loss = criterion(output, label)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- acc = (output.argmax(dim=1) == label).float().mean()
- epoch_accuracy += acc / len(train_loader)
- epoch_loss += loss / len(train_loader)
- #validataion
- with torch.no_grad():
- epoch_val_accuracy = 0
- epoch_val_loss = 0
- for data, label in valid_loader:
- data = data.to(device)
- label = label.to(device)
-
- val_output = model(data)
- val_loss = criterion(val_output, label)
-
- acc = (val_output.argmax(dim=1) == label).float().mean()
- epoch_val_accuracy += acc / len(valid_loader)
- epoch_val_loss += val_loss / len(valid_loader)
- if epoch_val_accuracy>best_accuracy:
- best_accuracy = epoch_val_accuracy
- torch.save(model.state_dict(), 'best.mdl')
- print(
- f"Epoch : {epoch + 1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
- )
将最佳模型的参数保存到‘best.mdl’中,当再次运行程序时会导入最佳模型参数,在此基础上进一步训练。
3.测试
- #test
- model.load_state_dict(torch.load('best.mdl'))
- print('best_acc:',best_accuracy)
- with torch.no_grad():
- test_accuracy = 0
- test_loss = 0
- for data, label in test_loader:
- data = data.to(device)
- label = label.to(device)
- test_output = model(data)
- test_loss = criterion(test_output, label)
- acc = (test_output.argmax(dim=1) == label).float().mean()
- test_accuracy += acc / len(test_loader)
- test_loss += test_loss / len(test_loader)
- print('test_acc:',test_accuracy)
model.load_state_dict(torch.load('best.mdl')) 载入最佳模型参数用于测试。
4.训练结果
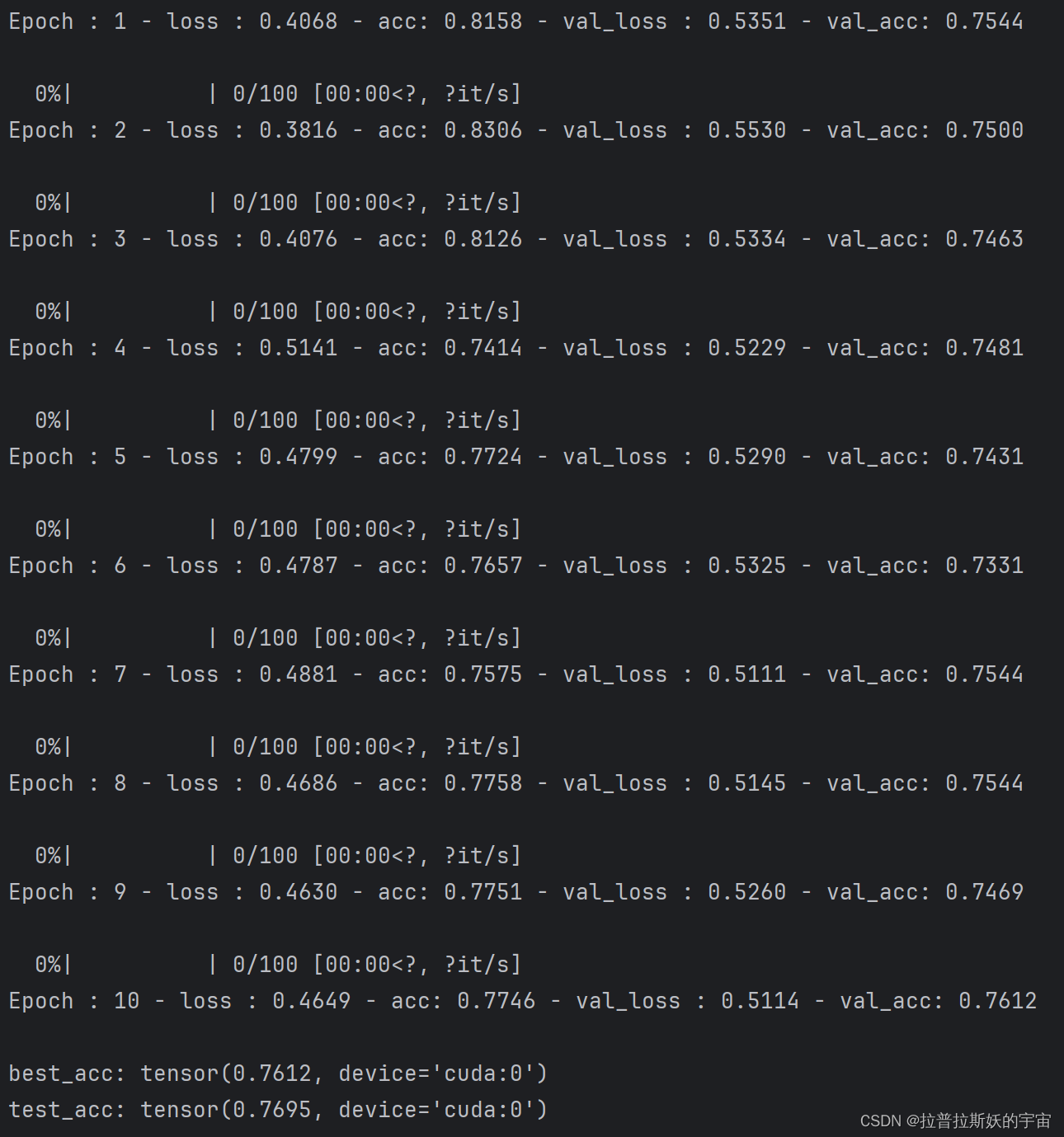
在经过30个Epoch(3次启动运行程序)会达到以上效果,说明ViT模型对于图像分类任务确实有效。但ViT对训练数据依赖性强,ViT 在训练时需要大量的高质量图像数据来训练模型,如果训练数据数据量不够大会影响模型效果,可能不如同条件下的ResNet效果好,因此,ViT用于往往需要在大规模数据集上预训练才能达到最佳效果。另外,ViT模型的计算复杂度高,对内存和硬件资源要求高,训练较费劲。本项目模型就是在24核的3090显卡上训练的。
以上就是Vision Transformer的详细讲解和实践应用,希望对大家有帮助!

