
- 1CentOS 6系统升级到CentOS 7.2过程(亲测可行)_centos6升级到7
- 2安全可信 | 天翼云算力调度平台通过信通院首批可信算力云服务评估!_算力调度中的转发安全
- 3extjs异步刷新技术Ext.Ajax.request_await ext.ajax.request
- 4Lua for 循环_lua for 循环
- 5Android蓝牙协议栈fluoride(十) - 音乐播放(3)
- 601背包回溯法复杂度_dd大牛的《背包九讲》
- 7navicat连接异常,错误编号2059-authentication plugin…_navicat连接mysql出现2059错误
- 8低代码发展专访系列之六:低代码平台能解决业务重构的问题么?_政低代码平台技术重构
- 9linux程序安装教程,CrossOver Linux 已知程序安装教程
- 10DeepFaceLab AI换脸使用教程(1.安装及分解视频)
NLP自然语言处理-机器学习和自然语言处理介绍(一)_机器学习 自然语言
赞
踩
“NLP自然语言处理-机器学习和自然语言处理介绍”
一.机器学习
1.什么是机器学习
从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
人类在成长、生活过程中积累了很多的历史与经验。人类定期地对这些经验进行“归纳”,获得了生活的“规律”。当人类遇到未知的问题或者需要对未来进行“推测”的时候,人类使用这些“规律”,对未知问题与未来进行“推测”,从而指导自己的生活和工作。
机器学习中的“训练”与“预测”过程可以对应到人类的“归纳”和“推测”过程。通过这样的对应,我们可以发现,机器学习的思想并不复杂,仅仅是对人类在生活中学习成长的一个模拟。由于机器学习不是基于编程形成的结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关性结论。
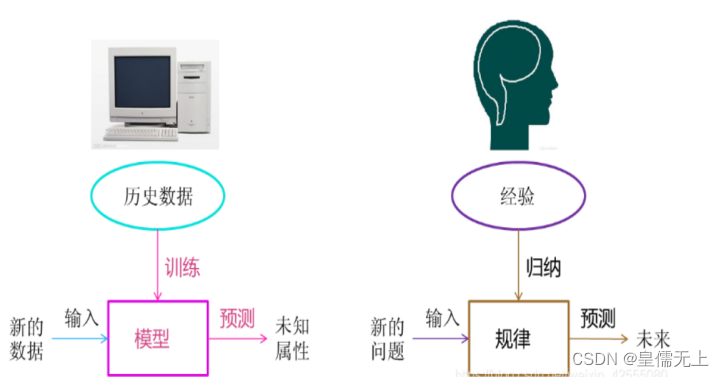
很长的一段时间人工智能也只是一个幻想,直到20世纪40年代电脑的出现,才有一批科学家开始严肃地探讨实现的可能性。经过快一个世纪的努力,逐渐取得了一些成果,比如自动驾驶。

2.机器学习与人工智能、深度学习的关系
简单来说就是:机器学习是人工智能的一个实现途径;深度学习是机器学习的一个方法发展而来。
3.机器学习能够做什么
机器学习的应用领域非常宽,涉及到各个领域以及学科当中。
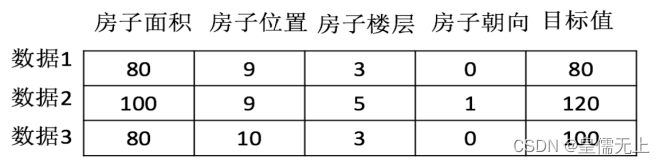
4.机器学习如何获取信息
(1)机器学习是从历史数据中自动分析获得模型,并利用模型对未知数据进行预测;
(2)这些所谓的历史数据结构包括:特征值和目标值;
(3)通俗的讲,特征值是指要探索的人、物的基本信息,例如身高、体重等;而目标值指的是人、物体所属的类别,例如A(警察)、B(医生)、C(律师)三类中的哪一类。
(4)对于每一行的数据我们可以称之为样本,而有些数据集可以没有目标值。
5.机器学习算法分类
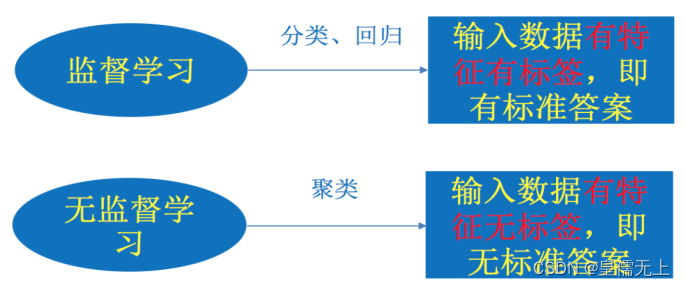
(1)监督学习(supervised learning)(预测)
定义:输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
举例:分类:k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络;(是猫还是狗?-类别)
回归:线性回归、岭回归等。(房屋价格?-连续型数据)
(2)无监督学习(unsupervised learning)
定义:输入数据是由输入特征值所组成。
举例:聚类 k-means(旅客群体的划分-商务人群还是非商务人群?)
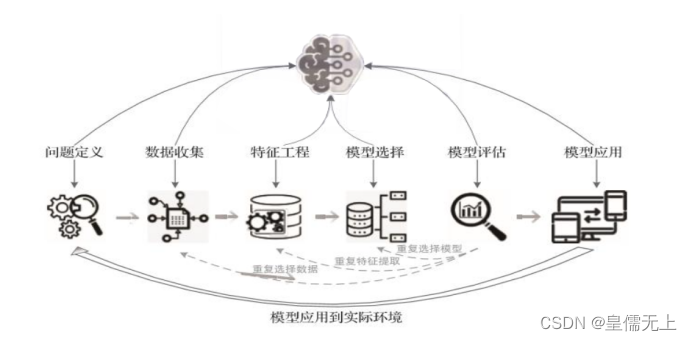
6.机器学习基本流程
为了提取知识和做出预测,机器学习使用数学模型来拟合数据。这些模型将特征作为输入,这里的特征指原始数据某个方面的数值表示。在机器学习流程中,特征是数据和模型之间的纽带。
建立机器学习流程的绝大部分时间都耗费在特征工程和数据清洗上,即特征工程。正确的特征要视数据的具体情况而定,往往结合着不同的业务场景,因此业务的指导也对特征的选择起到了至关重要的影响。
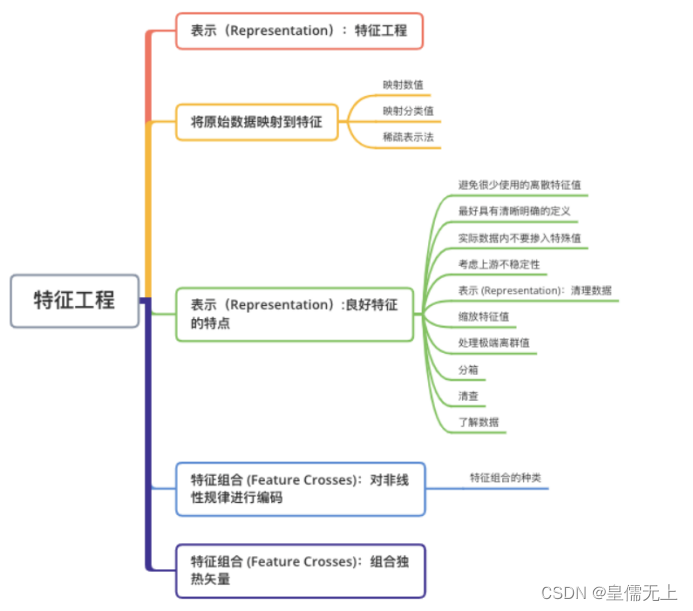
7.特征工程
(1)特征工程简单介绍
“数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这里的数据指的就是经过特征工程得到的数据。特征工程指的是把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征,使得机器学习模型逼近这个上限。特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。特征工程在机器学习中占有非常重要的作用,一般认为括特征构建、特征提取、特征选择三个部分。特征构建比较麻烦,需要一定的经验。 特征提取与特征选择都是为了从原始特征中找出最有效的特征。它们之间的区别是特征提取强调通过特征转换的方式得到一组具有明显物理或统计意义的特征;而特征选择是从特征集合中挑选一组具有明显物理或统计意义的特征子集。两者都能帮助减少特征的维度、数据冗余,特征提取有时能发现更有意义的特征属性,特征选择的过程经常能表示出每个特征的重要性对于模型构建的重要性。
(2)特征处理
特征的一般类型包括数值型、类别型和文本型特征,这里我们简单介绍下文本型特征的处理。
第一.词袋:文本数据预处理后,去掉停用词,剩下的词组成的list,在词库中的映射稀疏向量。Python中用CountVectorizer处理词袋.
第二.把词袋中的词扩充到n-gram:n-gram代表n个词的组合。比如“我喜欢你”、“你喜欢我”这两句话如果用词袋表示的话,分词后包含相同的三个词,组成一样的向量:“我 喜欢 你”。显然两句话不是同一个意思,用n-gram可以解决这个问题。如果用2-gram,那么“我喜欢你”的向量中会加上“我喜欢”和“喜欢你”,“你喜欢我”的向量中会加上“你喜欢”和“喜欢我”。这样就区分开来了。
第三.使用TF-IDF特征:TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF(t) = (词t在当前文中出现次数) / (t在全部文档中出现次数),IDF(t) = ln(总文档数/ 含t的文档数),TF-IDF权重 = TF(t) * IDF(t)。自然语言处理中经常会用到。
第四.补齐可对应的缺省值:不可信的样本丢掉,缺省值极多的字段考虑不用。
举例:为了使要分析的地址更加精确,我们选择将地址进行补全。这些都属于自然语言处理。
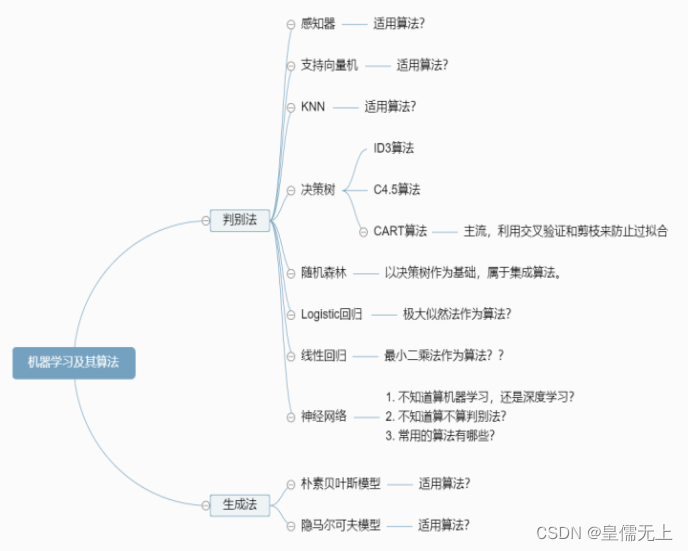
8.机器学习建模
针对于不同的问题和场景,可选择与其相匹配的算法,以下举例:
(1)逻辑回归:大多数情况下被用来解决分类问题(二元分类),但多类的分类(所谓的一对多方法)也适用。这个算法的优点是对于每一个输出的对象都有一个对应类别的概率。
(2)朴素贝叶斯:它也是最有名的机器学习的算法之一,它的主要任务是恢复训练样本的数据分布密度。这个方法通常在多类的分类问题上表现的很好。
(3)K-最近邻:kNN(k-最近邻)方法通常用于一个更复杂分类算法的一部分。例如,我们可以用它的估计值做为一个对象的特征。有时候,一个简单的kNN算法在良好选择的特征上会有很出色的表现。当参数(主要是metrics)被设置得当,这个算法在回归问题中通常表现出最好的质量。
(4)决策树:分类和回归树(CART)经常被用于这么一类问题,在这类问题中对象有可分类的特征且被用于回归和分类问题。决策树很适用于多类分类。
二.自然语言处理
1.人工智能简介
人工智能根据特定场景分为:弱人工智能,即只能解决限定领域的一些问题;强人工智能,即能解决生活中通用场景的一些问题;超人工智能,即远超人类领域的智慧。
人工智能的研究方向包括:语音合成,语音识别,字符识别,机器翻译,声纹识别,指纹识别,语义理解和图像识别等。
2.什么是自然语言处理
自然语言处理是指使计算机能够像人类一样理解、处理和生成语言。是人工智能领域的一个重要分支。
例如:我们在使用手机的时候,当你对着手机说“hi ,siri,打电话给XXXX”的时候,手机能够为你执行你要打电话给某人的指令。
3.自然语言处理的重要性
据IDC报告,当下数据以每年50%左右的速度快速增长,截至2020年全球数据规模将达44ZB,其中文本等非结构化数据占比高达75%-85%,因此对文本等非结构数据的挖掘分析显得尤为迫切和重要。各公司建立个子的NLAP平台目标在于解决计算机和人类(自然)语言的交互问题,尤其是自动处理大规模自然语言语料。从大量非结构化文本数据中抽取未知的、可理解的、最终可用的知识,并运用这些知识更好地组织信息。
4.自然语言处理的目标
(1)人机交互
包括:问答搜索,闲聊对话,指令操作和机器翻译等,目前在生活中越来越常见,其价值也随着机器能力边界的提升而不断增加。

(2)数据分析和挖掘
包括:舆情分析,文本分类,知识抽取和命名实体识别。
随着数字化浪潮席卷全球,各政府、企业也相继加入了数字化转型的大队伍当中。面对着日常生活中的海量数据,分析和挖掘数据中的重要价值、信息成为了当今人工智能领域的一大热门。同样其价值随着数据量的增加和类别的增多而不断提升。

5.在自然语言处理模块中算法的相关工作内容
(1)业务型
主要负责业务场景的算法落地,动手能力强;需要熟悉业务场景常见问题,极端情况的处理小坑不断,例如需求总改,数据常缺,效果老是降低。
(2)研究型
主要负责发表论文及算法比赛等,理论知识扎实;研究内容可以脱离实际业务,在公开数据集上工作;小坑在于想好的思路已发表,比赛的分数被人超过。同样充满了无奈。
6.NLP目前面临的挑战
随着理论和算法模型的不断迭代,总会暴露出各种的问题。
(1)语义边界
中华文化博大精深,体现在语言的丰富性和灵活性上。同样的词随着语境的不同往往会表达出不同的情感,同样的字会组合成不同含义的词。而划分语义边界也就成为了一大难点,如下:
① “校长说衣服上除了校徽别别别的”
② “过几天天天天气不好”
③ “骑车出门差点摔跤,还好我一把把把把住了”
④ ”碳碳键键能能否否定定律一“
⑤ “来到杨过曾经生活过的地方,小龙女动情地说:“我也想过过过儿过过的生活。”
⑥ “我背有点驼,麻麻说“你的背得背背背背佳”
(2)语言的递归性
(3)同文歧义
① 单身的原因有两个,一是谁都看不上,二是谁都看不上。
② 女孩给男朋友打电话:如果你到了,我还没到,你就等着吧;如果我到了,你还没到,你就等着吧。
③ 冬天:能穿多少穿多少。夏天:能穿多少穿多少
④ 关于疫情:中国:我们快完了;我们好多了
美国:我们快完了;我们好多了
(4)反话正说系列
① 屡败屡战
屡战屡败
② 情理之中意料之外
意料之外情理之中
③ 情有可原罪无可恕
罪无可恕情有可原
NLP对于机器来说很困难,本质上是因为对人来说它也很困难。换句话说,这个任务本身的复杂度就非常高,远远高于下围棋等看似复杂,但实际有明确规则的任务。语言本身具有创造力,在不同领域和时代不断发生着变化。
7.NLP的发展历程和现状
(1)发展历程
20世纪五十年代开始
与计算机的诞生几乎同时始于机器翻译任务,包括了以下两种路线:
① 基于规则的理性主义
主张建立符号处理系统,由人工整理和编写初始的语言知识表示体系,构造相应的推理程序。
② 基于统计的经验主义
主张通过建立特定的数学模型来学习复杂的、广泛的语言结构,利用统计、模式识别、机器学习等方法来训练模型。
20世纪20年代-60年代
经验主义处于主导地位,人们在研究语言的应用规律是进行统计、分析和归纳,并建立相应的分析或处理系统。
20世纪60年代-80年代
语言学、心理学、人工智能和NLP等领域的研究几乎都是遵循理性主义研究方法。人们通过建立很多小系统来模拟智能。
20世纪80年代后期
人们更多的关注工程化、实用化的解决问题,经验主义被人们重新认识并且引入到NLP研究中,并快速发展。
20世纪80年代末-90年代
围绕经验主义和理性主义发生了很多激烈争论,但人们逐渐达成共识,无论哪一种方法都不可能完全解决自然语言处理这一复杂问题。两种方法开始从对立走向融合
21世纪以来
机器学习快速崛起。在图像、语言、文本领域都有大量的数据集被建立起来,这种资源大幅度推动了基于统计的机器学习相关算法的发展。随着AlphaGo的出现,人工智能领域获得前所未有的关注度。NLP也飞快的追赶着其他领域发展。
(2)现状
深度学习大幅改变了NLP研究,使离散的符号转化为连续的数值,因此大量的数学工具得以应用,极大的推进了NLP技术的发展。
NLP技术已经深入生活的各个角落,输入法、语音助手、搜索引擎、智能客服等大量依赖NLP技术的应用已经被推广和使用。
综合来看,目前计算机对语义的理解能力尚不如小学生,但在特定任务上可以达到人类以上的水平。
8.NLP常用工具
(1)NLP常用编程语言
① 引擎开发:C++和 Java居多
② 算法实验:python,R
C++,Java的特点:
执行效率高,开发累(代码量大),不好上手,有助于深入理解编程,有成熟的框架和各种检查工具。
Python的特点:
执行效率低,开发轻松,开源库多,简单易学,做线上业务需要开发者有较好的编程习惯。
(2)NLP常用编辑器
① Pycharm:个人推荐,我在日常开发中使用;
② Spyder:不是不行;
③ Eclipse: 支持多种语言;
④ Python 自带 ide:别难为自己;
⑤ Vim:linux中使用,需要掌握。
(3)NLP常用算法框架
① Tensorflow : 这个不用多说了,时间久、配套完善;
② Pytorch : 学术界宠儿,调试方便,个人推荐;
③ Keras : 高级封装,简单好用,现已和Tensorflow合体;
④ Gensim : 训练词向量,bm25等算法支持;
⑤ Sklearn : 大量机器学习算法,如逻辑回归,决策树,支持向量机,随机森林,KMeans等等,同时具有数据集划分和各种评价指标的实现;
⑥ Numpy : 各种向量矩阵操作。
(4)NLP常用数据处理库
① Jieba : 分词,词性标注等;
② Pandas : 数据处理,可以读取excel,csv等格式文件,按列去重、排序,去除无效值等等,但是经常搞事情;
③ Matplotlib : 用于画图,可视化是了解数据集的有效手段,也是做汇报等工作中常用的;
④ Nltk : 英文的预处理工具中的佼佼者,词性还原,去停用词等功能完善,对中文也有一定支持;
⑤ Re : 正则表达式,也许这会是你最常用的库;
⑥ Json : 读取json格式数据,非常常见;
⑦ Pickle : 文件读写自己建立的任意变量或数据结构,比如说自己建的索引等。

