
- 1《HarmonyOS开发 – OpenHarmony开发笔记(基于小型系统)》第1章 OpenHarmony与Pegasus物联网开发套件简介_pegasus智能家居开发套件
- 2java笔记二(IO流与json)_io与json
- 3三星平板显示无法连接网络连接服务器,三星p600平板电脑无法连接无线网络该怎么办?...
- 4华为OD机试 - 比较两个版本号的大小(Java)_版本号比对 java
- 5GPT-SoVITS 本地搭建踩坑_gpt-sovits 本地部属
- 6嵌入式算法移植优化学习笔记5——CPU,GPU,TPU,NPU都是什么_tpu gpu npu原理
- 7ServiceManager简单分析_registercontextawareservice是注册到servicemanager吗
- 8[论文翻译]基于图像自适应GAN重建_hand p, leong o, voroninski v. phase retrieval und
- 9IDEA中war包与war exploded包的区别以及热部署时没有Update classes and resources_idea war exploded包找不到
- 10“低代码时代”未来程序员将不再是职业?“全民皆码农”?_底层的编程都不需要程序员了
西交人机所提出视频全景分割新基线IMTNet,发表在图像领域顶级期刊TIP上_ieee tip图标
赞
踩

论文标题:Instance Motion Tendency Learning for Video Panoptic Segmentation
论文链接:https://ieeexplore.ieee.org/document/9975287
作者单位:西安交通大学人机所、伊利诺伊大学芝加哥分校、Wormpex AI Research(Gang Hua,IEEE Fellow)
欢迎关注微信公众号 CV顶刊顶会 ,严肃且认真的计算机视觉论文前沿报道~
期刊介绍:IEEE Transactions on Image Processing(IEEE TIP)是图像处理领域公认的顶级国际期刊,是中国计算机学会(CCF)推荐的A类期刊,代表了图像处理领域先进的重大进展,要求论文在理论和工程效果上对图像处理及相关领域具有重要推动作用,其最新的影响因子为15.8。
视频全景分割是计算机视觉领域中一项基础的场景感知任务,它不仅需要对输入视频的每一帧执行全景分割,而且还需要关联相邻帧中的相同实例。之前的方法大多缺乏对其中的时序相关性进行建模,因而会在帧与帧之间的实例关联部分出现错误,同时无法处理由大规模运动引起的模糊分割边界问题。为了解决这些难题,来自西安交通大学、伊利诺伊大学芝加哥分校和Wormpex AI Research等研究机构的团队提出了一种简单而有效的实例运动趋势网络 (Instance Motion Tendency Network,IMTNet) 来解决视频全景分割任务。IMTNet通过对全局运动趋势图来对不同帧中的实例进行关联,并且对运动边界进行细化。具体来说,IMTNet中的全局运动趋势模块 (Global Motion Tendency Module,GMTM) 旨在从光流数据中学习鲁棒的运动特征,它可以将前一帧中的每个实例直接关联到当前帧中的相应实例。此外,IMTNet中还内嵌了一个运动边界细化模块(Motion Boundary Refinement Module,MBRM)来学习一个层次分类器来处理运动目标的边界像素,这可以有效地修正不准确的分割预测。 作者在现有标准的视频全景分割基准Cityscapes 和 Cityscapes-VPS上进行了广泛的实验,实验结果表明,IMTNet已达到SOTA性能。
1.引言
视频全景分割任务可以认为是继承了图像全景分割和多目标跟踪两项任务的挑战。一方面,它需要为背景中的每个像素分配一个语义类标签,如草地、道路和树木,并为前景中的每个像素分配一个实例身份标签,如人id1、人id2、汽车id1和汽车id2。另一方面,它需要为跨视频帧的同一实例保持一致的身份标签。
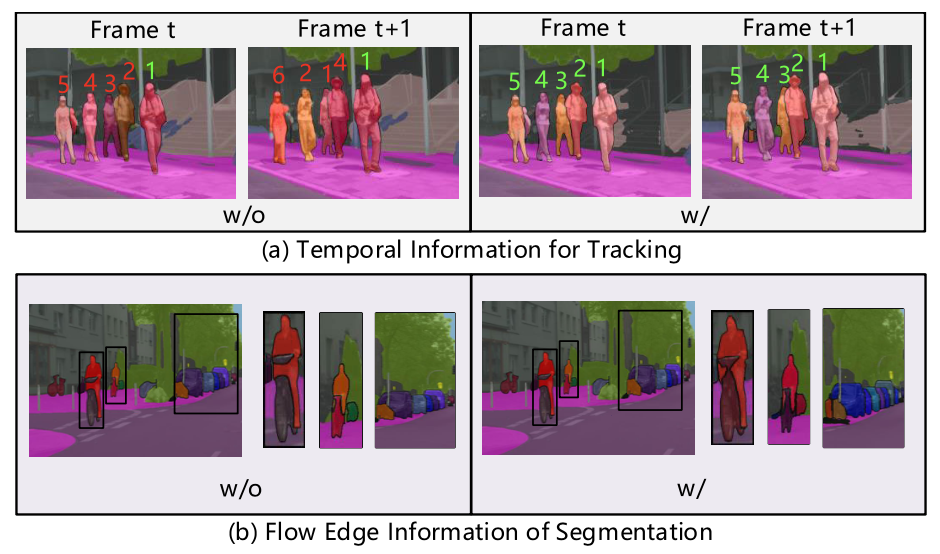
现有的视频全景分割方法大致可以分为两类,第一类方法通过分离构建图像全景分割和多对象跟踪两个核心组件来提高视频全景分割的整体性能,这种方式将视频全景分割视为两个独立子任务的集成,因而两个任务在训练过程中互相不受影响。为了解决这个限制,有研究者提出了以端到端的方式训练统一的视频全景分割网络,端到端网络目前可以获得更好的全景分割性能。但是由于现实应用场景中含有巨大差异,视频全景分割的任务仍远未解决。在模型推理时,常会出现实例间遮挡的情况,此外,许多实例在不同帧之间会出现大幅度的运动,这使得模型在跟踪过程中很难估计移动目标的准确边界。为了解决这两个问题,需要在模型的实例关联和分割阶段中充分利用时间信息。如上图 (a) 所示,身份切换问题可以通过结合时间信息得到很好的解决。而光流边缘信息可以是模型更加关注模糊物体的边界,如上图(b)所示。
2.本文方法
下图展示了IMTNet的整体框架构成,IMTNet包含两个关键模块,分别是全局运动趋势模块GMTM用来对跨视频帧中的实例进行关联。运动边界细化模块MBRM用来修正不精确的中间分割结果。作者选用了目前较为流行的SOTA方法UPSNet[1]作为整体框架的baseline,其中的backbone为ResNet-FPN负责来提供共享特征表示。
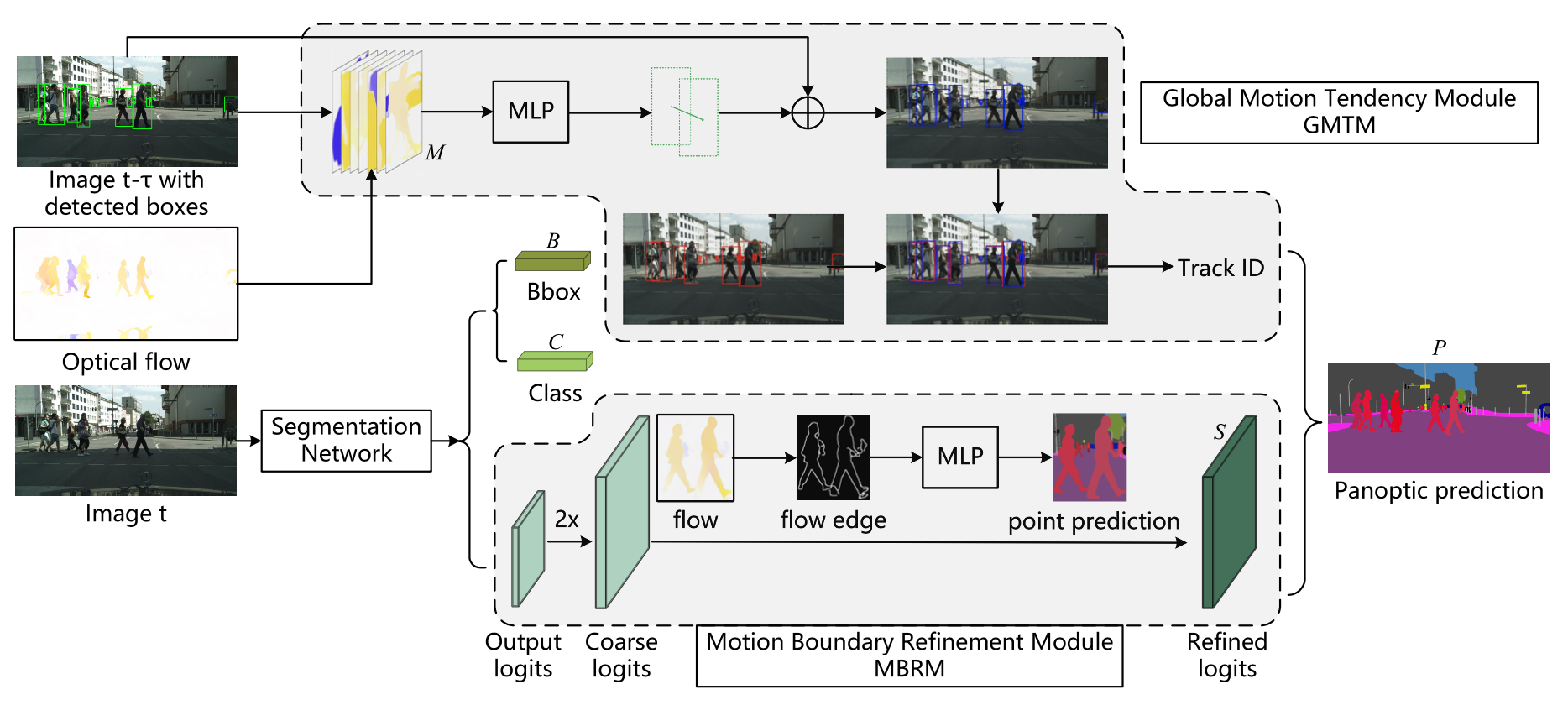
2.1 全局运动趋势模块GMTM
GMTM模块负责从视频光流中学习稳健的运动特征。具体来说,GMTM在操作过程中会联合外观和运动特征对实例在帧之间的偏移量进行估计。GMTM的网络架构非常简单,只需要几个多层感知机来估计实例从前一帧到当前帧的偏移量。首先将两个连续帧输入到FlowNet2[2]中提取像素级光流 F t F_t Ft,随后输入到GMTM中,并通过运动矢量作为ground-truth对其进行训练。
具体来说,作者将前一帧中的所有实例表示为 B t − 1 = b t − 1 1 , b t − 1 2 , . . . , b t − 1 n B_{t−1} = {b^{1}_{t-1} ,b^{2}_{t-1} ,...,b^{n}_{t-1} } Bt−1=bt−11,bt−12,...,bt−1n,其中 b t − 1 i b^{i}_{t-1} bt−1i 表示实例在前一帧中的位置信息。 当前帧中的相应实例表示为 B t = b t 1 , b t 2 , . . . , b t n B_{t} = {b^{1}_{t} ,b^{2}_{t} ,...,b^{n}_{t} } Bt=bt1,bt2,...,btn,由于许多实例在前一帧或当前帧中会被遮挡,因此预测偏移量可能存在较大误差。为了解决这个问题,作者采用最小预测误差来计算偏移损失,因而 GMTM 的损失函数定义为:
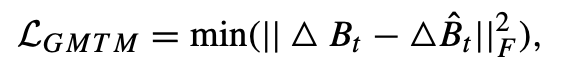
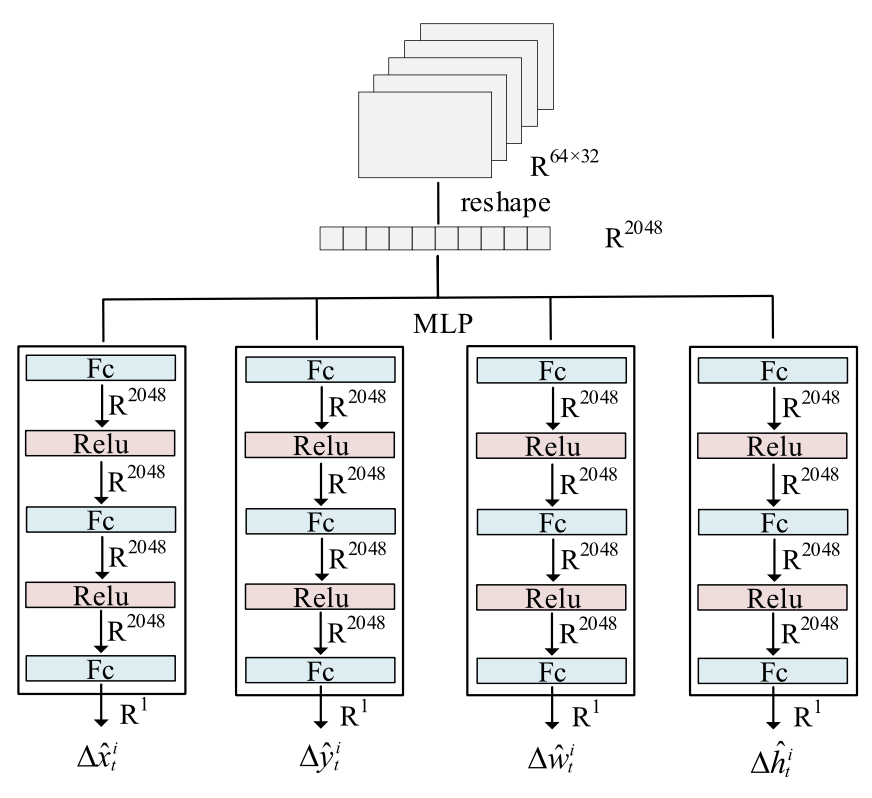
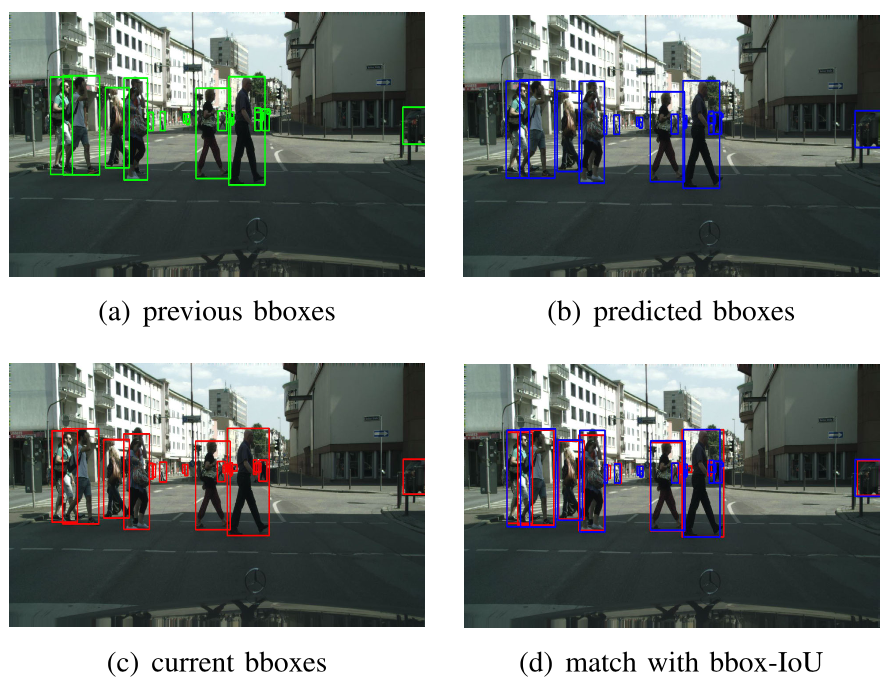
其中实例间的偏移量又四个可学习的多层感知器(MLP)进行预测,如下图所示,这样就可以通过计算预测框和当前帧中检测到的框的 IoU 重叠程度来跨帧对实例进行关联。
在下图中,作者展示了实例关联的具体过程,前一帧的目标框与当前帧的光流一起送入到GMTM 中。在得到预测框之后,可以简单地将实例与预测框和当前帧中检测到的框之间的 IoU 重叠匹配起来。
2.2 运动边界细化模块MBRM
MBRM模块的网络结构如下图所示。MBRM的目标是学习视频中的运动边界细化机制来校正移动实例的边界。在具体操作过程中,MBRM 学习了一个层次化的分类器来修正不准确的分割结果,尤其是在移动目标的边界像素处,使用细分策略来计算上采样过程中作为锚点的高分辨率分割图。
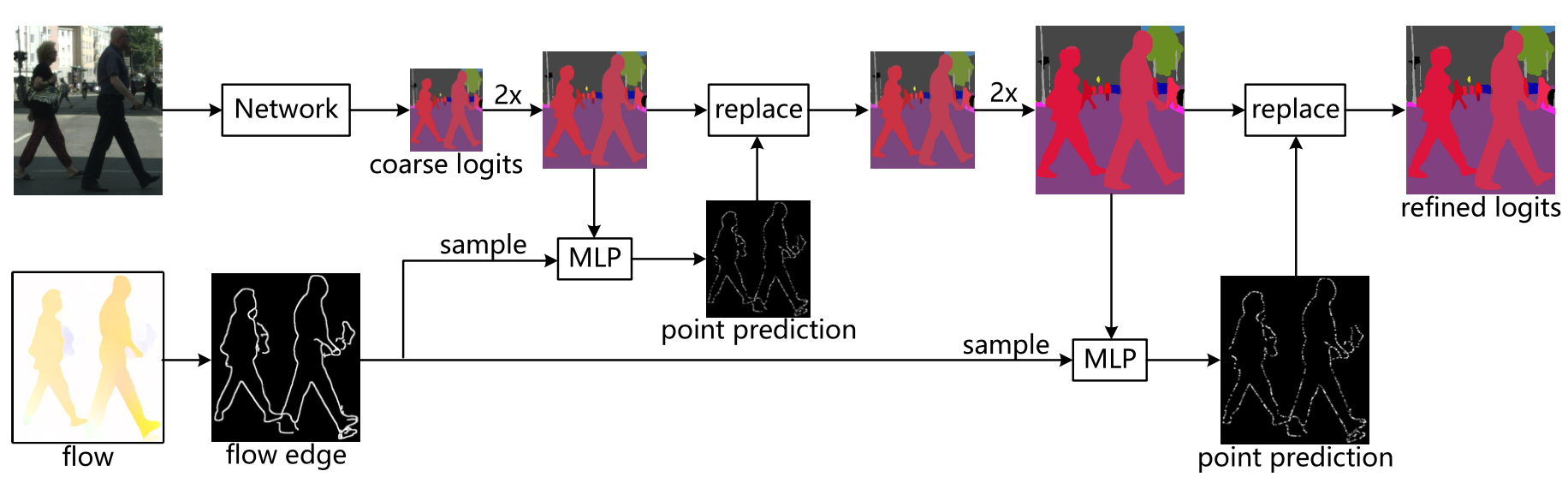
作者使用两个点分类子网络(point classification sub-networks)分别从语义 logits 和掩码 logits 预测当前点的标签。每个点分类子网络的架构是一个简单的多层感知器。在训练过程中,首先从运动目标的边界采样大量的点,这些点可以通过计算光流的边缘得到。然后,再根据它们的特征和预测分数保留那些具有高不确定性的点。特别是,作者选择那些置信度较高的点用于语义逻辑,而那些预测分数接近掩码阈值的点用于掩码逻辑。随后将它们放入上述两个点分类子网络中,随后以相应的分割标签作为监督来训练这两个子网络。MBRM通过一个交叉熵损失进行优化,其公式如下:
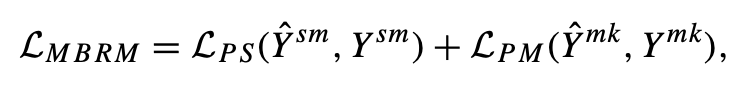
其中 L P S \mathcal{L_{PS}} LPS 和 L P M \mathcal{L_{PM}} LPM 分别代表语义点子网络和mask点子网络的损失函数,它们的具体形式如下:
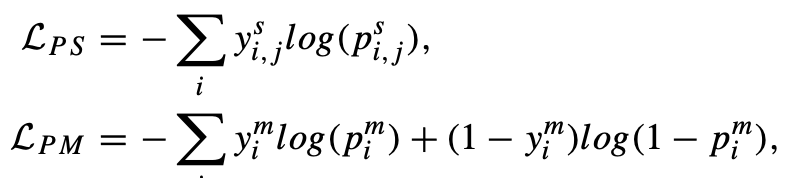
3.实验效果
作者在五个基准数据集上进行广泛的实验,包括 Cityscapes、Cityscapes-VPS、VIPSeg、MOTChallenge 和 KITTI-STEP。下表显示了这些数据集的统计数据。
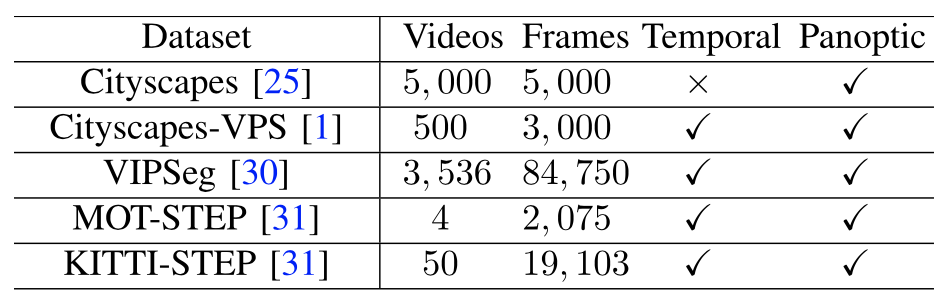
评价指标使用全景质量 (PQ) 来评估图像全景分割效果,使用平均精度 (AP) 和平均 IoU来评估实例分割和语义分割性能。为了评估 Cityscapes-VPS 数据集的视频全景质量,使用滑动窗口大小为 k 的视频全景质量。
作者选用了11种图像全景分割方法以及5种视频全景分割方法进行了性能对比实验,实验对比效果如下表所示。

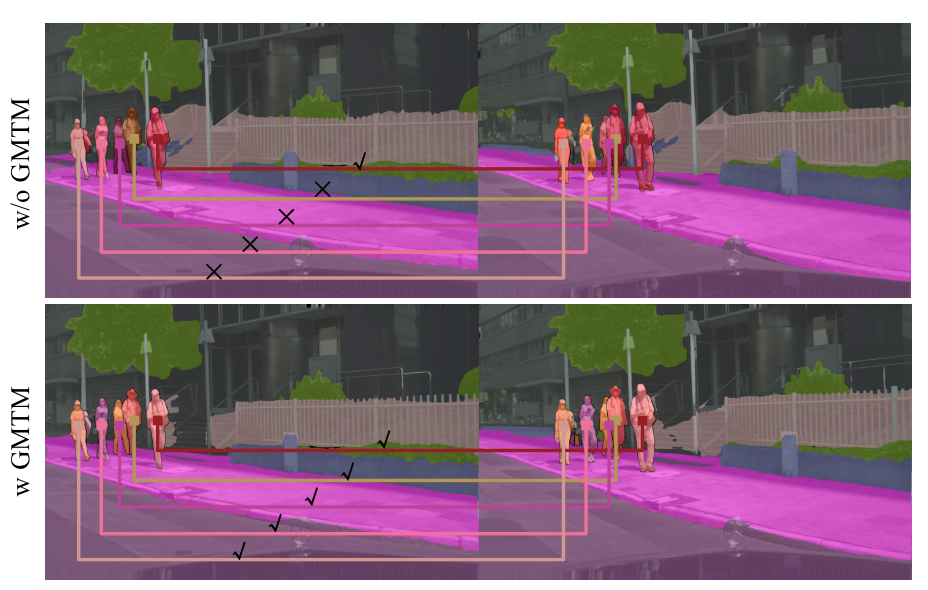
为了证明GMTM模块的性能,作者对其进行了消融研究,作者猜测,随着时间跨度的增加,GMTM 将极大地改善 VPQ性能,原因是GMTM 更好地利用了视频的时序信息。从下图中可以看出, GMTM可以成功的关联帧间的实例,而删除GMTM后,实例匹配失败。
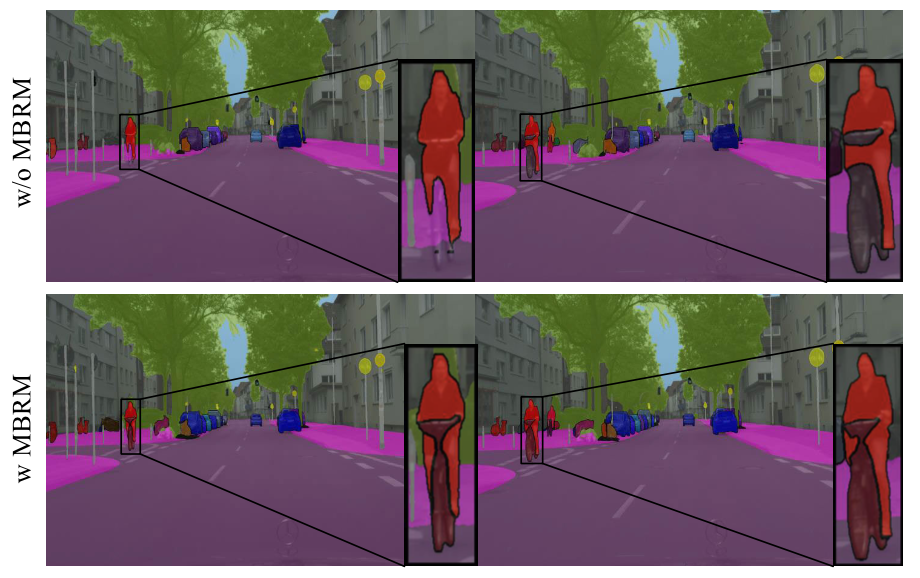
与GMTM相似,作者对 MBRM 也进行了类似的实验,实验效果如下图,MBRM可以获得更精细的分割结果,尤其是在移动目标的边界上。
4.总结
在本文中,作者提出了一个实例运动趋势网络IMTNet,用于视频全景分割任务。其中的全局运动趋势模块 (GMTM) 旨在学习稳健的运动属性,以关联不同视频帧中的实例。运动边界细化模块(MBRM)用来修正在上采样过程中从实例分割分支和语义分割分支产生的不准确的边界分割结果。作者希望提出的 IMTNet 可以成为视频全景分割的新基线。
参考
[1] Y. Xiong et al., “UPSNet: A unified panoptic segmentation network,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2019, pp. 8818–8826.
[2] E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox,“FlowNet 2.0: Evolution of optical flow estimation with deep networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 2462–2470.

