
- 1漏洞分析|jeecg-boot 未授权SQL注入漏洞(CVE-2023-1454)_jeecg漏洞
- 2ClickHouse Kafka表引擎使用详解_clickhouse kafka引擎
- 3C++入门手写直接插入排序_直接插入排序手写c++
- 4详解FPGA —— 下一代AI算力芯片(中)_intel fpga dla
- 5Android_studio和java的完整安装_android studio java
- 6python自动化测试selenium(四)切换页面、切换窗口_python selenium 同一个窗口里不同页面
- 7【VUE】7、VUE项目中集成watermark实现页面添加水印_vue-watermark
- 8Unity学习笔记——鼠标移动到物品上显示物品名字,点击后显示物品信息_unity 鼠标移动到文字上显示装备详情
- 9TextView自动调节字体大小_appcompattextview 自动文字大小
- 10三大IT运维工单系统对比
doxygen 无法生成图片_设计稿智能生成代码如何识别组件?Imgcook 3.0 解析
赞
踩
文 / 阿里淘系 F(x) Team - 苏川
背景介绍
imgcook 能够自动生成代码主要做两件事: 从视觉稿中识别信息,然后将这些信息表达成代码。
本质是通过设计工具插件从设计稿中提取 JSON 描述信息,通过规则系统、计算机视觉和机器学习等智能还原技术对 JSON 进行处理和转换,最终得到一个符合代码结构和代码语义的 JSON,再用一个 DSL 转换器,转换为前端代码。DSL 转换器就是一个 JS 函数,输入是一个JSON,输出就是我们需要的代码。
例如 React DSL 的输出就是符合 React 开发规范的 React 代码,其中核心部分在于 JSON to JSON 这部分,这个 JSON 的格式可以查看 imgcook schema 这篇文档。

设计稿中只有图像、文本这些元信息,位置信息是绝对坐标,直接生成的代码是由 div、img、span 或 View、Image、Text 这些元件粒度的标签组成,但实际开发中,我们会将 UI 界面不同粒度的物料组件化,例如 搜索框、按钮这种基础组件,或者计时器、券、视频、轮播等这种带有业务属性的组件,又或者更大颗粒度的 UI 区块。

如果希望能生成组件粒度的代码, 需要能识别视觉稿中的组件,并且转化成对应的组件化代码。例如以下视觉稿中电饭煲位置处是一个视频,但从视觉稿中只能提取到图片信息,并生成如右侧的代码。

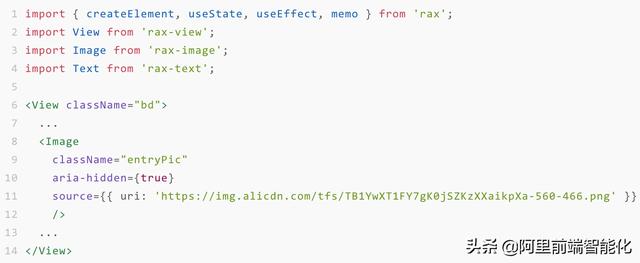
实际生成的代码需要用 Rax 组件 rax-video 来表达,如下:
import { createElement, useState, useEffect, memo } from 'rax';import View from 'rax-view';import Picture from 'rax-picture';import Text from 'rax-text';import Video from 'rax-video'; ... 那我们要做两件事:
- 识别:将设计稿中需要组件化的部分识别出来,需要精确到具体的 DOM 节点。
- 表达:用前端组件表达,包括组件包的引入、组件名称的替换、组件属性的设置。
技术方案
识别方案
按照对智能化能力分级定义,I1 级别可通过设计稿协议人工辅助生成组件代码,I2 级别可通过规则算法分析元素样式识别组件生成组件代码,I3 级别使用目标检测模型识别组件,但目标检测方案无法避免复杂设计稿背景带来的专模型准确度低的问题。在探索出图片分类方案后,在特定业务域下即使设计稿很复杂训练出来的模型准确度也较高,目前在 I4 级别优化算法工程链路降低业务接入成本。
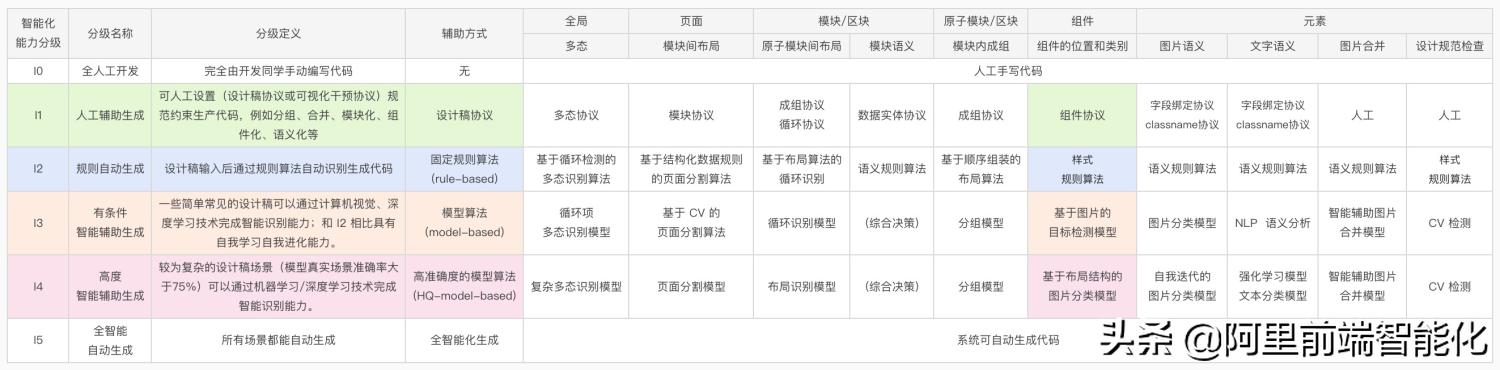
(组件识别能力模型)
L1 阶段人工辅助生成:设计稿组件协议
直接在设计稿中标记组件名称,在使用 imgcook 插件导出 JSON 描述数据时通过解析标记拿到图层中的人工设定的组件信息。

(人工设置组件协议生成组件化代码)
L2 阶段规则自动生成:样式规则匹配
这种方式需要人工标记视觉稿填写组件名称和属性,一个页面上的组件可能会有很多,这种人工约定方式让开发者多了很多额外工作,我们期望能自动化、智能化的识别视觉稿中的需要组件化的 UI。
通过规则算法能够自动帮我们检测出一些有通用样式特征的组件,例如有 4 个圆角的宽度大于高度的节点可以认为是按钮这种规则判断,但是规则判断的泛化能力很差,无法应对复杂多样的视觉表现。
L3-L4 阶段智能辅助生成:学习识别 UI 组件
找到视觉稿中需要组件化的元素,它是什么组件,它在 DOM 树中的位置或者在设计稿中的位置,这是深度学习技术很适合解决的问题,可以接受大量丰富的样本数据,学习和归纳出经验,预测相似组件样本的类别,这种相似特征就不再局限于使用规则算法的宽高样式等,泛化能力较强。
在 如何使用深度学习识别 UI 界面组件?这篇文章中我把这个问题定义为一个目标检测的问题,使用深度学习对 UI 界面进行目标检测,找到可在代码中组件化的页面 UI 的类别和边界框,但是这篇文章主要是以 UI 界面组件识别为例介绍使用深度学习解决问题的方式,并没有考虑到实际应用。这里以解决 D2C 组件化出码这个实际问题为核心,分享一下如何才能在实际项目中应用组件识别的能力。
我们很难收集到所有用户的样本提供一个准确度较高的通用组件识别模型,另外不同团队使用的组件类别和样式差异较大,可能会有相同类别的样本但 UI 差异却很大,或者不同类别的样本 UI 却很相似,这样会导致识别效果会很差。因此需要能支持用户以自己的组件为训练集,训练一个专有的组件识别模型。这里以淘系营销常用的几个组件为例,介绍组件识别的应用方案。
基于图片的目标检测方案
在 如何使用深度学习识别 UI 界面组件?这篇文章中有详细介绍目标检测的知识,将视觉稿的图像作为输入,训练一个目标检测模型,用于识别图片中的组件。
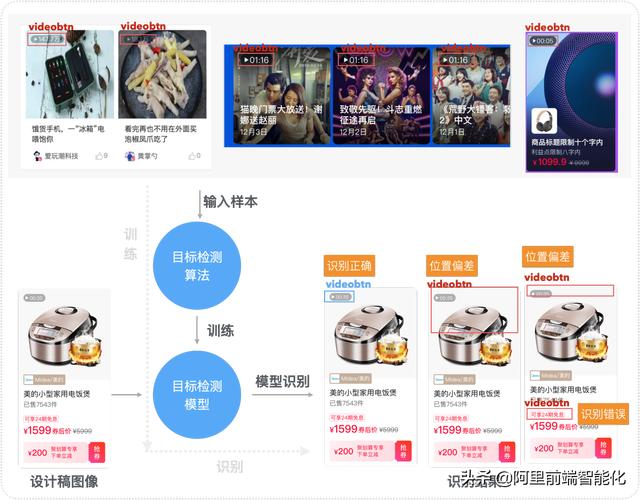
(目标检测模型训练与预测路径)
如上图所示,训练目标检测模型需要输入大量样本,样本是视觉稿的整张图片,并且需要给图片标记你想要模型识别的组件,训练出可以识别组件的目标检测模型,当有的新的需要识别的设计稿时,将设计稿图像输入给模型识别,最终得到模型识别的结果。
使用目标检测的方案会存在一些问题:
- 样本完全需要人工打标,需要收集 UI 图片,对图片中的组件进行标记。如果要新增一个分类,需要给每张图片重新打标,打标成本很大;
- 既需要识别出正确的位置,还需要识别出正确的类别。视觉稿图像中背景是很复杂的,容易被误识别;
- 就算识别出的类型是准确的,也会有位置偏差。
在 imgcook 智能生成代码的场景中,组件识别的结果是需要精确到具体的 DOM 节点的,用这种目标检测的方案既需要识别出准确的位置又需要识别出正确的类别,线下实验的模型准确度本身就不高,线上应用的准确度就会比较低,基本上无法确定最终识别的结果应该到哪个 DOM 节点上。
基于布局树的图片分类方案
由于我们可以从设计稿中获取图像的 JSON 描述信息,图像中每个文本节点和图像节点都已经具备位置信息,并且经过 imgcook 智能还原后能生成较为合理的布局树。所以我们可以基于这个布局树,以容器节点为粒度将可能的组件节点裁剪出来。

(图片分类模型训练与预测路径)
例如我们可以把这里的 div/view 节点都裁剪出来,就可以得到一个小的图片的集合,然后将这些图片送给一个图片分类模型预测,这样我们把一个目标检测问题转换成了一个图片分类问题。
模型会给每张图片在每一个分类中分配一个概率值,某个分类的概率值越大表示模型预测该图片是这个分类的概率越大。我们可以设置一个置信度为 0.7,当概率值大于置信度 0.7 时,则认为是最终分类的结果,例如上图中,最终只有两张图片是可信的识别结果。如果对分类的准确度要求很高,就可以将置信度设置高一点。
相比目标检测,使用图片分类方案,样本可以用程序自动生成,无需人工打标;只需要识别类别,类别准确则位置信息绝对准确。所以我们改用基于布局识别结果的图片分类方案,识别准确度大大提升。
表达方案
布局算法生成布局之后的 JSON Schema 进入组件分类识别层,组件识别结果会更新到 JSON Schema 中传入下一层级。

(组件分类识别在技术分层中的位置)
我们可以这样直观的看下组件识别的结果,识别结果会挂在这个节点的 smart 属性中。

(组件分类结果)
从(图片分类模型训练与预测路径)中可以看到,根据布局结构裁剪出来的图片,经过组件分类识别后,由于模型准确度问题可能会识别出多个 videobtn 类别的节点。
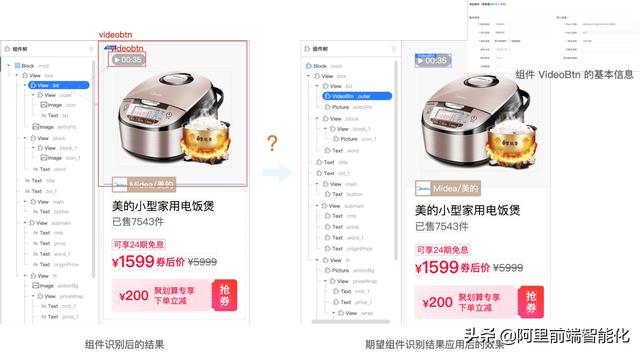
那现在我们需要根据组件识别的结果,找到需要替换成组件 Video 的节点,会遇到这些问题:
- 如何根据组件识别结果,找到应该被替换为组件的 DOM 节点?
- 找到应该被替换为组件的节点之后,如何知道要替换的组件名称是什么?
- 组件名称被替换后,如何从视觉稿中提取组件的属性值?例如这里的 VideoBtn 组件需要的时间信息、或者其他如视频组件的封面图 poster 属性、按钮组件 Button 的 text 属性?
- 识别不准确怎么办?
- 识别结果应用之后,节点被替换成组件,还能否在画布中渲染看到所见即所得的还原效果?
基于这些问题,想要将组件识别的结果最终应用到工程链路,并且能支持用户个性化的组件需求,我们需要提供一套开放的智能物料体系,支持组件可配置、可识别、可干预、可渲染、可出码。
- 可配置 - 用户可以自定义组件库,用于组件的识别、干预、渲染和出码。
- 可识别 - 通过训练自定义组件的样本,支持组件识别和表达。
- 可干预 - 编辑器干预能力,在编辑器中可以手动更改组件类型和组件属性。
- 可渲染 - 定制画布渲染能力,用户可以将自定义组件打包进画布,支持组件渲染。
- 可出码 - 支持组件粒度出码,DSL 接收 D2C Schema 和用户自定义的组件,生成组件粒度的代码。
组件识别应用的整个流程如下,用户配置了自己的组件库之后,还需要配置识别组件的模型服务,在视觉稿还原的组件识别阶段调用模型服务识别组件,在进入业务逻辑生成阶段时,调用配置好的逻辑库来将组件的识别结果(smart 字段)表达成组件(componentName),并检测视觉稿中可获取的组件属性信息用于补充组件属性。最后在画布中渲染,需要预先配置支持组件渲染的画布资源。

(组件识别应用流程)
这里详细介绍下在业务逻辑生成阶段业务逻辑库如何承接组件识别结果的应用表达,以及画布如何支持组件渲染以在视觉上表达识别结果。
逻辑应用表达 x 业务逻辑库
业务逻辑库的核心功能之一是用户可以自定义识别函数和表达函数,在业务逻辑生成阶段对每一个节点调用识别函数和表达函数。识别函数用于判断当前节点是否为想要的节点,如果是则执行对应的表达逻辑。
例如组件识别的结果会放在 D2C Schema 协议的 smart 节点上,我们可以自定义识别函数判断当前节点是否被识别为组件。这里的难点在于可能会有多个被识别为组件的节点,需要能精确的确定最终要表达为组件的节点,因为有的节点是误识别,有的节点虽然识别正确但并不是直接更改此节点的 componentName,而是需要寻找合适的节点。
对于这里的视频时间显示组件 videobtn,有多个识别结果,需要根据这个结果找到对应的需要替换为前端视频时间组件 VideoBtn 的节点,并将此节点的 componentName 替换为组件名称 VideoBtn,其中组件名称根据组件的类别 videobtn 以及录入组件时给组件输入的标签来关联,即录入组件时需要同时录入组件的类别用于组件识别。
所以在自定义识别函数中,我们需要添加一些过滤规则,例如如果有多个有嵌套包含关系的节点被识别为 videobtn,只取最里面一层的节点作为识别结果。
/** allSchema 原始数据 schema* ctx 上下文 * 执行时机:每个节点执行一次,返回为true时识别成功,可执行表达逻辑*/async function recognize(allSchema, ctx) { // ctx.curSchema - 当前选中节点Schema // ctx.activeKey - 当前选中Key // 判断是否被识别为 videobtn 的节点 const isVideoBtnComp = (node) => { return _.get(node, 'smart.layerProtocol.component.type', '') === 'videobtn'; } // 是否有子节点被识别为 videobtn const isChildVideoBtnComp = (node)=>{ if(node.children){ for(var i=0; i然后自定义表达函数,如果某一个节点执行识别函数后输出为 true, 则执行对应的表达函数。下面在自定义表达函数中更改 componentName 为 VideoBtn,并提取时间信息作为 VideoBtn 组件的属性值。
/* * json 原始数据 schema * ctx 上下文 */async function logic(json, ctx) { getTime = (node) => { for(var i=0; i经过业务逻辑层将组件识别的结果表达之后,就可以得到组件化的 Schema,最终生成组件化代码。

这就是一个通过组件分类模型识别视觉稿中 videobtn 的位置,最终用前端组件 @ali/pcom-imgcook-video-58096 应用出码的例子。
如果希望识别到视觉稿中 videobtn 类别之后,可以将视觉稿中的商品图片替换成视频,例如用 rax-video 组件出码,我们可以增加一个自定义表达函数,找到与 videobtn 节点同级的图片节点,并将此节点替换为 rax-video 组件。
/* * json 原始数据 schema * ctx 上下文 */async function logic(json, ctx) { const getBrotherImageNode = (node) => { const pKey = node.__ctx.parentKey; const parentNode = ctx.schemaMap[pKey]; for(var i=0; i使用业务逻辑库来应用组件识别结果的好处是:组件识别可以与业务逻辑解耦,用户的组件是不确定的,每个组件的名称和属性都不一样,识别之后应用的逻辑也不一样,业务逻辑库可以支持用户自定义组件应用的需求,否则组件识别的结果无法落地使用。
视觉渲染表达 x 画布构建
如果编辑器画布不支持渲染组件,组件节点会被渲染为空节点,无法在画布中展示,也就看不到视觉稿还原后所见即所得的效果,画布支持组件渲染非必须但是有必要。
目前组件支持以 NPM 包的形式打包到画布资源中,借助 iceluna 开放的渲染引擎 SDK 为 imgcook 用户提供可自定义编辑器画布的能力。用户可以选择需要的组件打包构建,构建之后获取的画布资源通过配置生效。

(编辑器画布构建架构)
落地结果
目前针对淘系常见的轮播组件、视频组件等训练了一个特定的组件识别模型,线上全链路支持组件可配置、可识别、可渲染、可干预、可出码,并在双 11 会场、聚划算等业务中应用。这种针对特定域的组件样本训练的模型识别准确率较高,可达 82%,线上应用可行性较强。

(组件识别应用全链路演示)
未来展望
组件识别能力的应用需要用户配置组件、训练模型用于识别、构建画布资源用于渲染,组件配置和画布构建比较简单,但对于用户自有的组件库,需要针对这个组件库生成对应的组件样本图片用于训练模型,目前用于淘系专用的组件识别模型训练的样本需要人工收集或编写程序自动生成,如果让用户自己去收集或编写样本生成程序,成本较大。
也有一些用户希望能接入组件识别的能力,但识别能力依赖于模型泛化能力,模型泛化能力依赖训练模型使用的样本,我们无法统一提供一个能识别所有组件的通用模型,所以需要给用户提供自定义模型和自动生成样本的能力,最大程度降低接入成本。

(样本管理、模型训练、模型服务应用一站式管理原型图)
目前样本制造机已具备通过上传设计稿自动帮用户生成训练样本的能力,并且算法模型服务也具备在线训练的能力,但还没有在线串通整个个流程,下一步需要将流程全链路在线化,支持模型根据线上用户数据反馈自我迭代。
淘系前端-F-x-Team 开通微博 啦!
除文章外还有更多的团队内容等你解锁
淘系前端-F-x-Team 微博


