
- 1这6种最佳移动自动化测试工具你知道吗?
- 2我的2021年总结
- 3PostgreSQL存储过程(函数)_greenplumn 存储过程loop循环
- 4湖南文理学院c语言题库,湖南文理学院_通讯录管理系统课程设计归纳总结报告书(C语言)(21页)-原创力文档...
- 5postgres14.5+postgis3.3.2+pgRouting3.4.2源码安装_pgrouting 安装
- 6无公网IP,使用ZeroTier免费内网穿透_allow assignment of global ips
- 72024年MathorCup数学建模挑战赛A题B题C题D题思路模型代码_2024数学建模挑战杯
- 8Ardupilot 高度控制代码整理(超长篇)_无人机定高代码
- 9git 强制将本地代码提交到远端分支_git push origin --force
- 10学历低能不能大厂?
大语言模型入门
赞
踩
内容来源
视频传送门:
Andrej Karpathy大神亲授:大语言模型入门【中英】_哔哩哔哩_bilibili
https://www.youtube.com/@HungyiLeeNTU
最近AI大模型太火了,找遍了全网,发现了两个可以带你快速入门大模型的视频。以下是对这两个视频的总结,
本文预计阅读时间15分钟,主要关于大模型的基本原理,大模型是如何训练的,以及模型的未来。
一、大语言模型的基本原理
1.1 什么是大语言模型

-
一个大语言模型只是两个文件:参数和某些可以运行这些参数的代码。
-
因为这是一个 700 亿参数模型,每个参数都存储为2个字节,因此参数文件有140GB,2个字节,是因为数据类型是float16
-
运行参数的代码,可能是一个c文件/python文件或任何其他编程语言
1.2 什么是ChatGPT
ChatGPT
G:generate 生成
P:Pre-trained 预训练
T:Transformer 注意力机制
1.3 大语言模型在做什么
- 可以理解成它在预测下一个单词
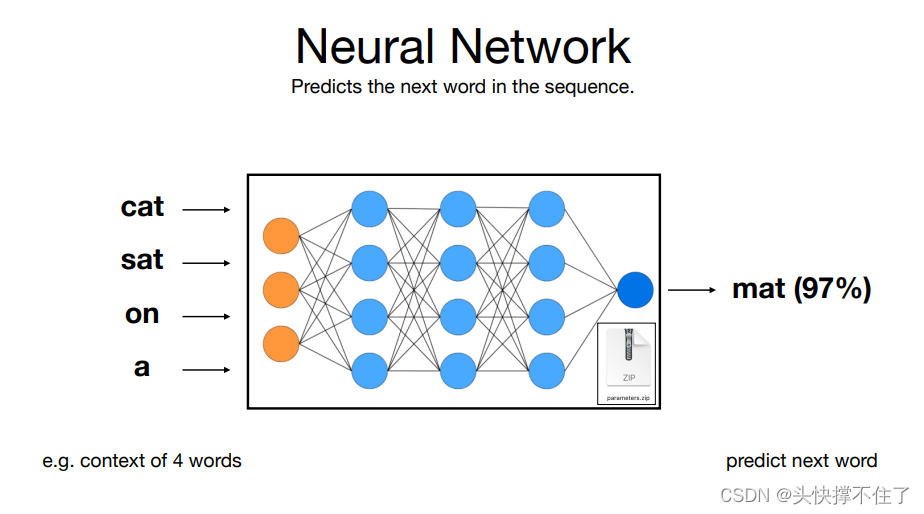
这个神经网络基本上只是试图预测一个序列中的下一个单词,你可以这样理解。你可以输入一个单词序列,例如“cat sat on a”,这个输入进入神经网络,这些参数分散在整个神经网络中,有神经元彼此相连并以某种方式激活。最后输出的是对接下来的单词的预测。例如,在这个例子中,这个神经网络可能会预测,在这个四个词的上下文中,下一个词很可能是“Matt”,可能有97%的概率。
- 大语言模型会根据概率掷骰子
比如前面的mat占97%的概率,但另外的3%的其他单词也可能会被选到,这也是每次chatgpt的回答都不一样的原因。
为什么不直接选概率最高的那一个?
根据如下论文,如果一直选择概率最高的那一个,可能会导致不断的循环同一句话。
所以掷骰子反而是更好的做法

-
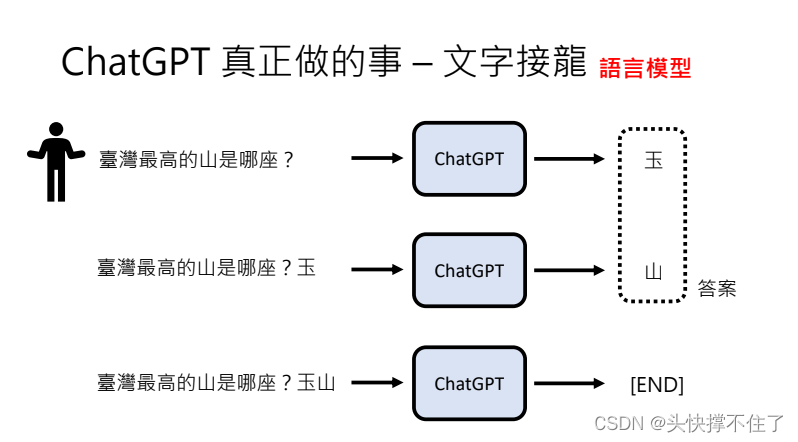
前面的输出会作为下一次的输入
-
最小的处理单位是token
https://platform.openai.com/tokenizer
二、大模型是如何被训练的
2.1 模型训练简介

-
获取大约10TB的文本,通常来自于对网络数据的爬取
-
用6000个GPU,运行12天,才能得到一个2-70b的模型,大约花费200万美元
-
这个2-70B的模型时相当初级的,ChatGPT会高出一个数量级或者更多
-
一旦你获得了这些参数,运行这个神经网络的计算量就相对较小。
2.2 模型预训练
2.2.1 大模型是如何工作的
-
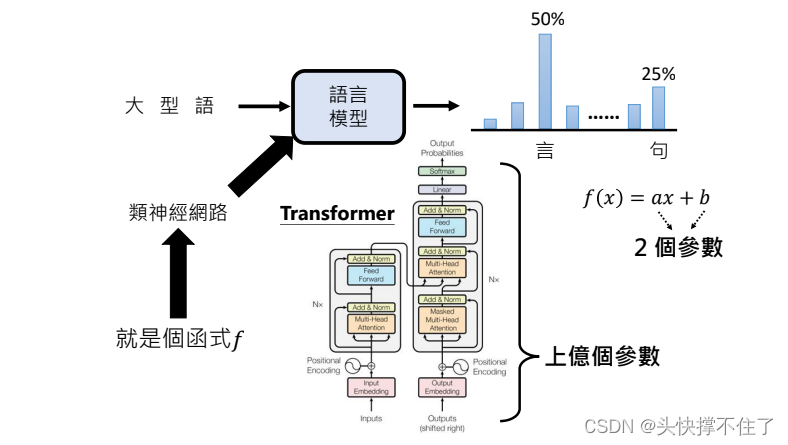
可以先理解成一个函数,这个函数中有2亿个参数。
-
这个神经网络长什么样子,可以参考如下课程
https://www.youtube.com/watch?v=Ye018rCVvOo&list=PLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J
- 现在这些神经网络的神奇之处在于,我们实际上完全了解这个架构,我们确切地知道在它的不同阶段发生了什么样的数学操作,问题是上这些数以亿计的参数散布在神经网络中,我们只知道如何迭代地调整这些参数,使得网络作为一个整体在下一个单词预测任务上变得更好。但我们实际上并不真正知道这2亿个参数在做什么。
这就像一些药物,人们已经再不断试验中知道某些植物具有药用价值,比如柳树皮可以用于缓解头痛和发烧。然而,直到后来,现代科学才揭示了柳树皮中含有水杨酸,这是一种有效的止痛药物。
目前我们基本上将大模型视为经验性的工艺品。
2.2.2 模型预训练(生成基础模型)
- 类似做于完型填空
遮挡住一部分文字,然后训练大模型
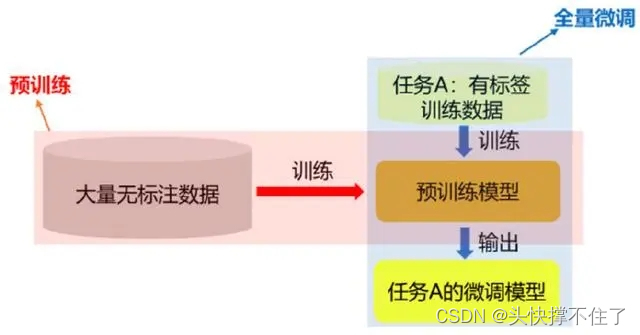
三、模型微调(生成助理模型)
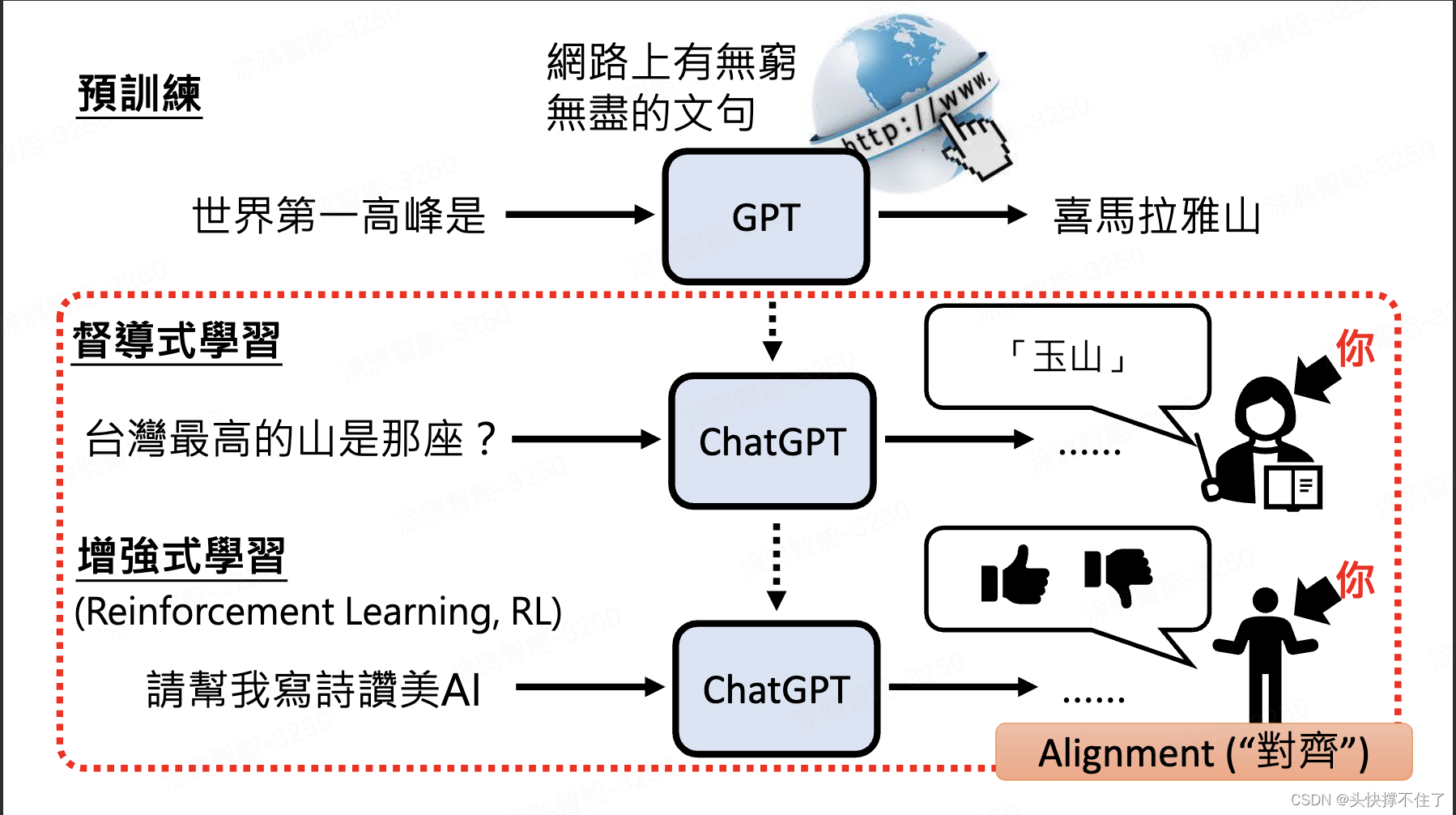
- 有监督学习
有监督学习的一个重要特点是需要大量的标注数据来进行训练。这些标注数据通常需要由人类专家进行标注,以提供正确的输出数据。然而,在某些情况下,标注数据可能很难获得或者非常昂贵,这可能会限制有监督学习的应用。
- 增强式学习
增强式学习的基本要素包括智能体、环境和奖励信号。智能体根据当前的状态选择动作,环境则根据智能体的动作给出反馈,通常以奖励的形式表示。奖励可以是正的,表示智能体的行为是有益的,也可以是负的,表示智能体的行为是不利的。智能体的目标是通过学习找到一种策略,使其在长期的交互过程中获得最大的奖励。
四、人类对齐AI
前面都是AI尽量去向人类对齐,这里讲下人类如何对齐AI
1、把需求说清楚
不要让AI猜你的想法,直接告诉它需求即可,比如你让它写一篇论文,就告诉直接告诉它要写多少字
2、提供背景材料
如果希望它写一篇论文,最好要给他你的提纲或者背景材料,才能让它言之有物
3、提供范例
文字大模型擅长模仿,给它一个范例,它能快速的学习到。
4、鼓励AI思考

五、模型的未来
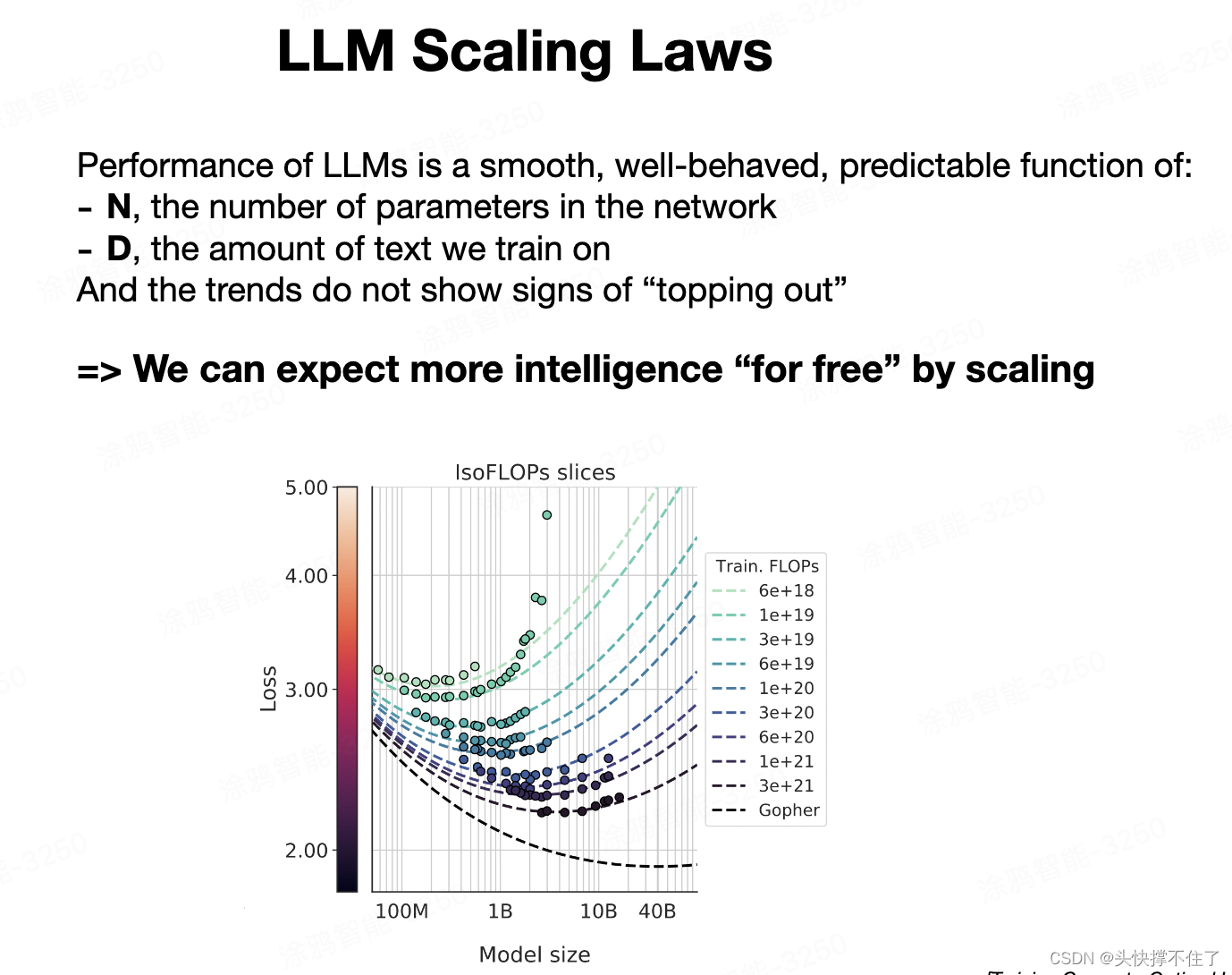
5.1 缩放定律
-
性能与参数和数据量的关系: LLM的性能,特别是在下一个词预测任务的准确度上,与两个变量紧密相关:模型中的参数数量(N)和训练所使用的文本量(D)。只要知道这两个数字,就可以相当准确地预测出模型在下一个词预测任务上的表现。
-
规律的可预测性: 这种关系呈现出显著的平滑、良好的行为,并且预测性强。目前尚未出现这种趋势的顶点或下降迹象,意味着通过扩大模型规模和增加数据量,可以预期模型性能的提升。
-
算法进展的角色: 虽然算法上的创新和进步是有益的,但即使没有算法上的重大突破,只要通过更大的计算资源训练更大的模型,也可以实现性能的提升。这种规模化(scaling)提供了提高模型性能的一条确定路径。
-
与其他评估指标的关联: 尽管LLM的主要目标是提高下一个词预测的准确性,但这种准确性与其他我们关心的评估指标有较强的相关性。例如,在一系列不同的测试中,当模型规模增大时,这些测试的准确率也普遍提高。
这些缩放规律反映了大型语言模型开发领域的一种基本动态,即通过增加模型规模和训练数据量,可以预期实现性能的显著提升。这种趋势目前是推动计算领域中的“淘金热”的主要因素之一,因为人们相信通过更大的计算力和更多的数据可以获得更好的模型。
5.2 Agent 智能体
- 操作系统
操作系统概念的扩展: LLM OS被视为一种新兴的计算模式,类似于传统操作系统,但以大型语言模型作为其核心处理单元。这意味着LLM不仅仅是聊天机器人或文字生成器,而是一个协调各种计算资源(如内存、计算工具)以解决问题的系统。

5.3 LLM OS: 基于LLM作为核心的操作系统将成为一个重要方向:
-
多模态交互: LLM OS不仅能够处理和生成文本,还能处理图像、视频和音频等多种媒介。这包括图像的生成和识别,甚至是音频的处理和生成,为用户提供更全面的交互体验。
-
工具的使用和集成: LLM OS能够使用和整合现有的软件基础设施,如计算器、Python编程语言等,以执行更复杂的任务。
-
知识的广泛获取和应用: 由于在庞大的数据集上进行训练,LLM OS拥有比任何单个人更广泛的知识,能够在多个主题和领域内提供信息和解决方案。


