
- 1使用Google colab进行机器学习项目开发
- 2Langchain+ElasticSearch+文心千帆 构建检索增强LLM Agent_langchain 搜索引擎
- 3spring cloud启动报错Cannot instantiate interface org.springframework.boot.BootstrapRegistryInitializer
- 4网络通信安全
- 5ai论文开题报告(免费ai生成论文)硕士论文文献综述总结!超全!看完全会了!
- 6[深度学习] 自然语言处理 --- 基于Attention机制的Bi-LSTM文本分类_bi-lstm+attention
- 7docker Compose-网络设置_docker compose network配置
- 8Python爬虫项目(附源码)70个Python爬虫练手实例!_python爬虫 70个python练手项目列表
- 9进阶MySql查询_要求按学号courseid字段值的前2个字符降序排列
- 10在 C#和ASP.NET Core中创建 gRPC 客户端和服务器
【MYSQL】MySQL整体结构之系统服务
赞
踩
一、系统服务层
学习了MySQL网络连接层后,接下来看看系统服务层,MySQL大多数核心功能都位于这一层,包括客户端SQL请求解析、语义分析、查询优化、缓存以及所有的内置函数(例如:日期、时间、统计、加密函数...),所有跨引擎的功能都在这一层实现,譬如存储过程、触发器和视图等一系列服务。
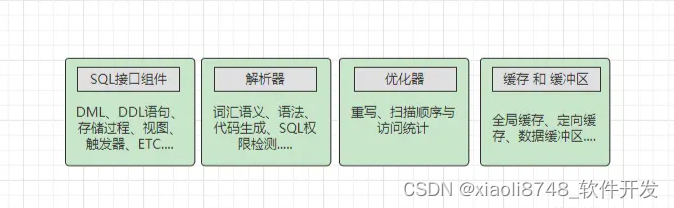
也就是上述这几部分,主要包含SQL接口、解析器、优化器以及缓存相关的这些部分。当然,也许你会问我还有一个[管理服务&工具组件]呢,这块其实属于全局的,属于MySQL的基础设施服务,接下来一个个的讲一下服务层的各个细节吧。
1.1、SQL接口
SQL接口组件,这个名词听上去似乎不太容易理解,其实主要作用就是负责处理客户端的SQL语句,当客户端连接建立成功之后,会接收客户端的SQL命令,比如DML、DDL语句以及存储过程、触发器等,当收到SQL语句时,SQL接口会将其分发给其他组件,然后等待接收执行结果的返回,最后会将其返回给客户端。
简单来说,也就是
SQL接口会作为客户端连接传递SQL语句时的入口,并且作为数据库返回数据时的出口。
对于这个组件没太多好聊的,简单展开两点叙述一下后就结束这个话题,第一点是对于SQL语句的类型划分,第二点则是触发器。在SQL中会分为五大类:
DML:数据库操作语句,比如update、delete、insert等都属于这个分类。DDL:数据库定义语句,比如create、alter、drop等都属于这个分类。DQL:数据库查询语句,比如最常见的select就属于这个分类。DCL:数据库控制语句,比如grant、revoke控制权限的语句都属于这个分类。TCL:事务控制语句,例如commit、rollback、setpoint等语句属于这个分类。
再来聊一聊MySQL的触发器,这东西估计大部分小伙伴没用过,但它在有些情景下还较为实用,不过想要了解触发器是什么,首先咱们还得先理解存储过程。
存储过程:是指提前编写好的一段较为常用或复杂
SQL语句,然后指定一个名称存储起来,然后先经过编译、优化,完成后,这个“过程”会被嵌入到MySQL中。
也就是说,[存储过程]的本质就是一段预先写好并编译完成的SQL,而我们要聊的触发器则是一种特殊的存储过程,但[触发器]与[存储过程]的不同点在于:存储过程需要手动调用后才可执行,而触发器可由某个事件主动触发执行。在MySQL中支持INSERT、UPDATE、DELETE三种事件触发,同时也可以通过AFTER、BEFORE语句声明触发的时机,是在操作执行之前还是执行之后。
说简单一点,[
MySQL触发器]就类似于Spring框架中的AOP切面。
OK~,至此就先打住,对于这些概念暂且了解到这里,后续会专门去聊MySQL的存储过程、触发器、视图等这些特殊的操作。
1.2、解析器
客户端连接发送的SQL语句,经过SQL接口后会被分发到解析器,解析器这东西其实在所有语言中都存在,Java、C、Go...等其他语言都有,解析器的作用主要是做词法分析、语义分析、语法树生成...这类工作的,如果对于这个具体过程感兴趣,可以参考之前的《JVM-执行引擎子系统-Javac编译过程》,Java源码在编写后,会经历这个过程,SQL语言同样类似。
而解析器这一步的作用主要是为了验证SQL语句是否正确,以及将SQL语句解析成MySQL能看懂的机器码指令。稍微拓展一点大家就明白了,好比如我们编写如下一条SQL:
select * form user;
然后运行会得到如下错误信息:
ERROR 1064 (42000): You have an error in your SQL syntax; check....
在上述SQL中,我们将from写成了form,结果运行时MySQL提示语法错误了,MySQL是如何发现的呢?就是在词法分析阶段,检测到了存在语法错误,因此抛出了对应的错误码及信息。当然,如果SQL正确,则会进行下一步工作,生成MySQL能看懂的执行指令。
1.3、优化器
解析器完成相应的词法分析、语法树生成....等一系列工作后,紧接着会来到优化器,优化器的主要职责在于生成执行计划,比如选择最合适的索引,选择最合适的join方式等,最终会选择出一套最优的执行计划。
当然,在这里其实有很多资料也会聊到,存在一个执行器的抽象概念,实际上执行器是不存在的,因此前面聊到过,每个客户端连接在
MySQL中都用一条线程维护,而线程是操作系统的最小执行单位,因此所谓的执行器,本质上就是线程本身。
优化器生成了执行计划后,维护当前连接的线程会负责根据计划去执行SQL,这个执行的过程实际上是在调用存储引擎所提供的API。
1.4、缓存&缓冲
这块较为有趣,主要分为了读取缓存与写入缓冲,读取缓存主要是指select语句的数据缓存,当然也会包含一些权限缓存、引擎缓存等信息,但主要还是select语句的数据缓存,MySQL会对于一些经常执行的查询SQL语句,将其结果保存在Cache中,因为这些SQL经常执行,因此如果下次再出现相同的SQL时,能从内存缓存中直接命中数据,自然会比走磁盘效率更高,对于Cache是否开启可通过命令查询。
show global variables like "%query_cache_type%";:查询缓存是否开启。show global variables like "%query_cache_size%";:查询缓存的空间大小。
同时还可以通过
show status like'%Qcache%';命令查询缓存相关的统计信息。
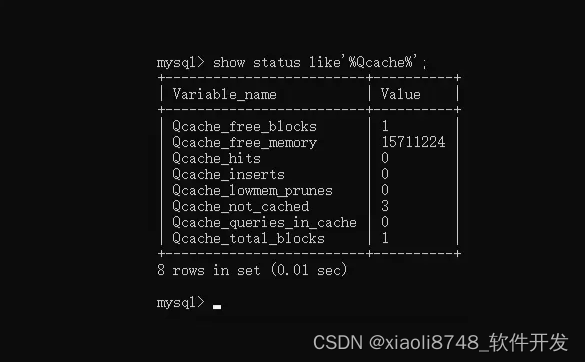
Qcache_free_blocks:查询缓存中目前还有多少剩余的blocks。Qcache_free_memory:查询缓存的内存大小。Qcache_hits:表示有多少次查询SQL命中了缓存。Qcache_inserts:表示有多少次查询SQL未命中缓存然后走了磁盘。Qcache_lowmem_prunes:这个值表示有多少条缓存数据从内存中被淘汰。Qcache_not_cached:表示由于自己设置了缓存规则后,有多少条数据不符合缓存条件。Qcache_queries_in_cache:表示当前缓存中缓存的数据数量。Qcache_total_blocks:当前缓存区中blocks的数量。
当然,由于我是MySQL5.7版本,因此对于这些依旧可以查询到,但是在高版本的MySQL中,移除了查询缓存区,毕竟命中率不高,而且查询缓存这一步还要带来额外开销,同时一般程序都会使用Redis做一次缓存,因此结合多方面的原因就移除了查询缓存的设计。
简单了解了查询缓存后,再来看看写入缓冲,这也是我说的比较有趣的点,缓冲区的设计主要是:为了通过内存的速度来弥补磁盘速度较慢对数据库造成的性能影响。在数据库中读取某页数据操作时,会先将从磁盘读到的页存放在缓冲区中,后续操作相同页的时候,可以基于内存操作。
一般来说,当你对数据库进行写操作时,都会先从缓冲区中查询是否有你要操作的页,如果有,则直接对内存中的数据页进行操作(例如修改、删除等),对缓冲区中的数据操作完成后,会直接给客户端返回成功的信息,然后MySQL会在后台利用一种名为Checkpoint的机制,将内存中更新的数据刷写到磁盘。
MySQL在设计时,通过缓冲区能减少大量的磁盘IO,从而进一步提高数据库整体性能。毕竟每次操作都走磁盘,性能自然上不去的。
PS:后续高版本的MySQL移除了查询缓存区,但并未移除缓冲区,这是两个概念,请切记!
同时缓冲区是与存储引擎有关的,不同的存储引擎实现也不同,比如
InnoDB的缓冲区叫做innodb_buffer_pool,而MyISAM则叫做key_buffer。
二、存储引擎层
存储引擎也可以理解成MySQL最重要的一层,在前面的服务层中,聚集了MySQL所有的核心逻辑操作,而引擎层则负责具体的数据操作以及执行工作。
如果有小伙伴研究过Oracle、SQLServer等数据库的实现,应该会发现这些数据库只有一个存储引擎,因为它们是闭源的,所以仅有官方自己提供的一种引擎。而MySQL则因为其开源特性,所以存在很多很多款不同的存储引擎实现,MySQL为了能够正常搭载不同的存储引擎运行,因此引擎层是被设计成可拔插式的,也就是可以根据业务特性,为自己的数据库选择不同的存储引擎。
MySQL的存储引擎主要分为官方版和民间版,前者是MySQL官方开发的,后者则是第三方开发的。存储引擎在MySQL中,相关的规范标准被定义成了一系列的接口,如果你也想要使用自己开发的存储引擎,那么只需要根据MySQL AB公司定义的准则,编写对应的引擎实现即可。
MySQL目前有非常多的存储引擎可选择,其中最为常用的则是InnoDB与MyISAM引擎,可以通过show variables like '%storage_engine%';命令来查看当前所使用的引擎。其他引擎如下:
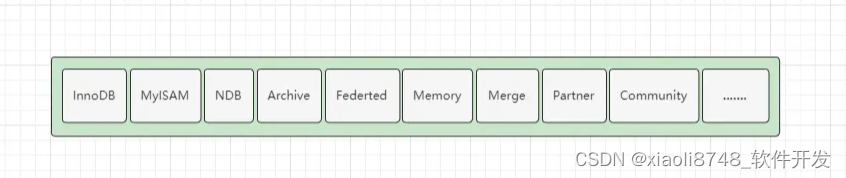
存储引擎是MySQL数据库中与磁盘文件打交道的子系统,不同的引擎底层访问文件的机制也存在些许细微差异,引擎也不仅仅只负责数据的管理,也会负责库表管理、索引管理等,MySQL中所有与磁盘打交道的工作,最终都会交给存储引擎来完成。
后续也会有专门的文章详细聊到
MySQL的存储引擎,这里先简单了解即可。
三、文件系统层
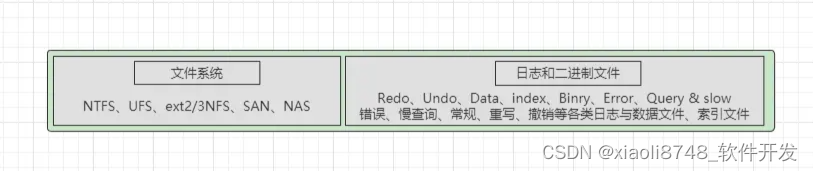
这一层则是MySQL数据库的基础,本质上就是基于机器物理磁盘的一个文件系统,其中包含了配置文件、库表结构文件、数据文件、索引文件、日志文件等各类MySQL运行时所需的文件,这一层的功能比较简单,也就是与上层的存储引擎做交互,负责数据的最终存储与持久化工作。
这一层主要可分为两个板块:①日志板块。②数据板块。
3.1、日志模块
在MySQL中主要存在七种常用的日志类型,如下:
- ①
binlog二进制日志,主要记录MySQL数据库的所有写操作(增删改)。 - ②
redo-log重做/重写日志,MySQL崩溃时,对于未落盘的操作会记录在这里面,用于重启时重新落盘(InnoDB专有的)。 - ③
undo-logs撤销/回滚日志:记录事务开始前[修改数据]的备份,用于回滚事务。 - ④
error-log:错误日志:记录MySQL启动、运行、停止时的错误信息。 - ⑤
general-log常规日志,主要记录MySQL收到的每一个查询或SQL命令。 - ⑥
slow-log:慢查询日志,主要记录执行时间较长的SQL。 - ⑦
relay-log:中继日志,主要用于主从复制做数据拷贝。
上述列出了MySQL中较为常见的七种日志,但实际上还存在很多其他类型的日志,不过一般对调优、排查问题、数据恢复/迁移没太大帮助,用的较少,因此不再列出。
同样,这里先简单认识一下,后续会专门开一篇《MySQL日志篇》全面剖析。
3.2、数据模块
前面聊到过,MySQL的所有数据最终都会落盘(写入到磁盘),而不同的数据在磁盘空间中,存储的格式也并不相同,因此再列举出一些MySQL中常见的数据文件类型:
db.opt文件:主要记录当前数据库使用的字符集和验证规则等信息。.frm文件:存储表结构的元数据信息文件,每张表都会有一个这样的文件。.MYD文件:用于存储表中所有数据的文件(MyISAM引擎独有的)。.MYI文件:用于存储表中索引信息的文件(MyISAM引擎独有的)。.ibd文件:用于存储表数据和索引信息的文件(InnoDB引擎独有的)。.ibdata文件:用于存储共享表空间的数据和索引的文件(InnoDB引擎独有)。.ibdata1文件:这个主要是用于存储MySQL系统(自带)表数据及结构的文件。.ib_logfile0/.ib_logfile1文件:用于故障数据恢复时的日志文件。.cnf/.ini:MySQL的配置文件,Windows下是.ini,其他系统大多为.cnf。......
上述列举了一些MySQL中较为常见的数据文件类型,无论是前面的日志文件,亦或是现在的数据文件,这些都是后续深入剖析MySQL时会遇到的,因此在这里先有个简单认知,方便后续更好的理解MySQL。
当然,上述并没有完全列出
MySQL所有的日志类型和文件类型,大家有兴趣的可以去自行翻看一下安装MySQL的目录,你会找其中找到很多其他类型的日志或数据文件~
四、MySQL架构篇小结
看到这里,《MySQL架构篇》就已经接近尾声啦,本文的主要目的是在于先对MySQL的整体架构有一个基本认知,这也为咱们后续的文章打下了坚实的基础,因为毕竟想要深入研究一个技术,那定然不能如同管中窥豹一般,仅看一个细节点,而是更应该是先窥其全貌,再深入细节。
这里也是学习底层、源码、原理、调优等知识的一个小技巧,如果只关注于某一个点,很容易出现“不识庐山真面目,只缘身在此山中”的情况,好比你想要研究“庐山”,但是一上来就抓着里面的某颗松树往死里钻,这定然是不妥的,更应该的是先从整体出发,先将整个庐山的面貌看清楚,最后再依次根据所观察到的全貌,逐步研究每个节点上的细节。
学习底层原理、源码实现,亦或是做性能调优、线上排查,一定要遵循“先理主干,再扣细节”的方式。


