
- 1真的太好用了,原来用 Python 自动化办公能做到这么多有趣又有用的事情_python实现办公自动化的好处
- 2Python凯撒密码_凯赛密码python
- 3python中requests设置代理服务器_python requests proxy
- 4手把手教你用IDEA上传新项目到gitlab,图文并茂!_idea推送新项目到gitlab
- 5MySQL数据库创建创建数据表_mysql数据库如何创建数据表
- 6自然语言处理中的机器翻译:技术与进展
- 75 CatBoost模型
- 8基于docker快速启动postgreSQL_docker启动postgres
- 9基于LoRA微调部署Stable Diffusion【免费试用阿里云】_stable diffusion微调lora
- 10数据挖掘十大经典算法_2006年ieee国际数据挖掘会议选出了数据挖掘领域中最重要的10个算法,其中不属
YOLOV8制作训练数据集,使用数据集进行训练模型,使用训练模型权重验证数据集(以数据集coco128为例)_yolov8使用自己权重训练,如何造作
赞
踩
Yolo系列的数据集格式一般是jpg或者是png格式,标签是txt文件
本次数据集制作以coco128为例,制作自己的小型数据集,作为训练学习使用
coco128数据集大家自行下载,或者自己手里的数据集都可以使用,仅作为示例为大家展示,对于自己的数据集修改相应示例中的名称即可
第一:初始数据集
在yolo系列的根目录下创建Dataset文件夹,在Dataset文件夹中放入coco128数据集,在coco128文件夹下创建image文件夹将数据集的图片和标签文件全部放入image中

将数据集的图片和标签文件全部放入image中
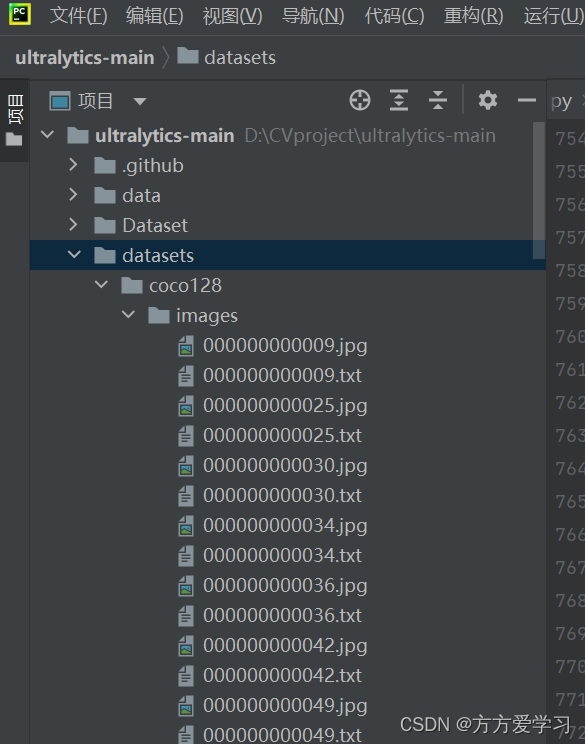
第二:数据集分割
在dataset文件夹下创建process.py文件,用来将image中的图片和标签进行分割,process.py代码如下:(ps:process.py一定放在dataset文件夹下,不要放在image里)
- import os
- import random
- import shutil
-
- def split_dataset(data_dir,train_val_test_dir, train_ratio, val_ratio, test_ratio):
- # 创建目标文件夹
- train_dir = os.path.join(train_val_test_dir, 'train')
- val_dir = os.path.join(train_val_test_dir, 'val')
- test_dir = os.path.join(train_val_test_dir, 'test')
- os.makedirs(train_dir, exist_ok=True)
- os.makedirs(val_dir, exist_ok=True)
- os.makedirs(test_dir, exist_ok=True)
-
- # 获取数据集中的所有文件
- files = os.listdir(data_dir)
-
- # 过滤掉非图片文件
- image_files = [f for f in files if f.endswith('.jpg') or f.endswith('.png')]
- # 随机打乱文件列表
- random.shuffle(image_files)
-
- # 计算切分数据集的索引
- num_files = len(image_files)
- num_train = int(num_files * train_ratio)
- num_val = int(num_files * val_ratio)
- num_test = num_files - num_train - num_val
-
- # 分离训练集
- train_files = image_files[:num_train]
- for file in train_files:
- src_image_path = os.path.join(data_dir, file)
- src_label_path = os.path.join(data_dir, file.replace('.jpg', '.txt').replace('.png', '.txt'))
- dst_image_path = os.path.join(train_dir, file)
- dst_label_path = os.path.join(train_dir, file.replace('.jpg', '.txt').replace('.png', '.txt'))
- shutil.copy(src_image_path, dst_image_path)
- shutil.copy(src_label_path, dst_label_path)
-
- # 分离验证集
- val_files = image_files[num_train:num_train+num_val]
- for file in val_files:
- src_image_path = os.path.join(data_dir, file)
- src_label_path = os.path.join(data_dir, file.replace('.jpg', '.txt').replace('.png', '.txt'))
- dst_image_path = os.path.join(val_dir, file)
- dst_label_path = os.path.join(val_dir, file.replace('.jpg', '.txt').replace('.png', '.txt'))
- shutil.copy(src_image_path, dst_image_path)
- shutil.copy(src_label_path, dst_label_path)
-
- # 分离测试集
- test_files = image_files[num_train+num_val:]
- for file in test_files:
- src_image_path = os.path.join(data_dir, file)
- src_label_path = os.path.join(data_dir, file.replace('.jpg', '.txt').replace('.png', '.txt'))
- dst_image_path = os.path.join(test_dir, file)
- dst_label_path = os.path.join(test_dir, file.replace('.jpg', '.txt').replace('.png', '.txt'))
- shutil.copy(src_image_path, dst_image_path)
- shutil.copy(src_label_path, dst_label_path)
-
- print("数据集分离完成!")
- print(f"训练集数量:{len(train_files)}")
- print(f"验证集数量:{len(val_files)}")
- print(f"测试集数量:{len(test_files)}")
-
- def move_files(data_dir):
- # 创建目标文件夹
- images_dir = os.path.join(data_dir, 'images')
- labels_dir = os.path.join(data_dir, 'labels')
- os.makedirs(images_dir, exist_ok=True)
- os.makedirs(labels_dir, exist_ok=True)
-
- # 获取数据集中的所有文件
- files = os.listdir(data_dir)
-
- # 移动PNG文件到images文件夹
- png_files = [f for f in files if f.endswith('.png')]
- for file in png_files:
- src_path = os.path.join(data_dir, file)
- dst_path = os.path.join(images_dir, file)
- shutil.move(src_path, dst_path)
-
- # 移动TXT文件到labels文件夹
- txt_files = [f for f in files if f.endswith('.txt')]
- for file in txt_files:
- src_path = os.path.join(data_dir, file)
- dst_path = os.path.join(labels_dir, file)
- shutil.move(src_path, dst_path)
-
- print(f"{data_dir}文件移动完成!")
- print(f"总共移动了 {len(png_files)} 个PNG文件到images文件夹")
- print(f"总共移动了 {len(txt_files)} 个TXT文件到labels文件夹")
-
-
- # 设置数据集路径和切分比例
- data_dir = './coco128/images' # 图片和标签路径
- train_val_test_dir= './coco128' # 目标文件夹
- train_ratio = 0.7 # 训练集比例
- val_ratio = 0.2 # 验证集比例
- test_ratio = 0.1 # 测试集比例
-
- # 调用函数分离数据集
- split_dataset(data_dir, train_val_test_dir,train_ratio, val_ratio, test_ratio)
- # 调用函数移动文件
- move_files(os.path.join(train_val_test_dir, 'train'))
- move_files(os.path.join(train_val_test_dir, 'val'))
- move_files(os.path.join(train_val_test_dir, 'test'))
-

在代码中需要将几个部分按照自己数据路径进行相应的修改:
- # 设置数据集路径和切分比例
- data_dir = './coco128/images' # 图片和标签路径
- train_val_test_dir= './coco128' # 目标文件夹
- train_ratio = 0.7 # 训练集比例
- val_ratio = 0.2 # 验证集比例
- test_ratio = 0.1 # 测试集比例
图片和标签路径要是第一步数据集的初始化时的image路径,此时的coco128与process.py是同一相对路径下,这样直接用相对路径就可以
下面的分割比例大家可以自行设置
随机打乱文件看需求是否需要 # 随机打乱文件列表 random.shuffle(image_files)
第三:数据集分离完成
运行process.py之前可以先检查一下image文件中的图片和标签是否是一一对应,后即可运行process.py文件,运行成功后会生形成相应的train、test、val文件夹,并按张相应的比例分离好

第四:制作数据集的yaml文件
数据集的yaml文件最好一起放在你所有的数据集yaml文件,我的示例是放在dataset里边了
其中train、test、val是图片的位置
nc是数据集中分类的总数
names 中要写入数据集的各个标签对应的名字
-
-
-
- train: ./coco128/train/images
- val: ./coco128/val/images
- test: ./coco128/test/images
-
- # 类别数
- nc: 80
-
- # 类别名称
- names:
-
- 0: person
- 1: bicycle
- 2: car
- 3: motorcycle
- 4: airplane
- 5: bus
- 6: train
- 7: truck
- 8: boat
- 9: traffic light
- 10: fire hydrant
- 11: stop sign
- 12: parking meter
- 13: bench
- 14: bird
- 15: cat
- 16: dog
- 17: horse
- 18: sheep
- 19: cow
- 20: elephant
- 21: bear
- 22: zebra
- 23: giraffe
- 24: backpack
- 25: umbrella
- 26: handbag
- 27: tie
- 28: suitcase
- 29: frisbee
- 30: skis
- 31: snowboard
- 32: sports ball
- 33: kite
- 34: baseball bat
- 35: baseball glove
- 36: skateboard
- 37: surfboard
- 38: tennis racket
- 39: bottle
- 40: wine glass
- 41: cup
- 42: fork
- 43: knife
- 44: spoon
- 45: bowl
- 46: banana
- 47: apple
- 48: sandwich
- 49: orange
- 50: broccoli
- 51: carrot
- 52: hot dog
- 53: pizza
- 54: donut
- 55: cake
- 56: chair
- 57: couch
- 58: potted plant
- 59: bed
- 60: dining table
- 61: toilet
- 62: tv
- 63: laptop
- 64: mouse
- 65: remote
- 66: keyboard
- 67: cell phone
- 68: microwave
- 69: oven
- 70: toaster
- 71: sink
- 72: refrigerator
- 73: book
- 74: clock
- 75: vase
- 76: scissors
- 77: teddy bear
- 78: hair drier
- 79: toothbrush
第五:训练数据集
以yolov8为例,在train.py中,使用自己的数据集进行训练
需要修改相应位置的data
我将train.py文件做了小的调整,如下:
- def train(model,data,cfg=DEFAULT_CFG, use_python=False):
- """Train and optimize YOLO model given training data and device."""
- # model = cfg.model or 'yolov8n.pt'
- # data = cfg.data or 'coco128.yaml' # or yolo.ClassificationDataset("mnist")
- device = cfg.device if cfg.device is not None else ''
-
- args = dict(model=model, data=data, device=device)
- if use_python:
- from ultralytics import YOLO
- YOLO(model).train(**args)
- else:
- trainer = DetectionTrainer(overrides=args)
- trainer.train()
-
-
- if __name__ == '__main__':
- model='yolov8n.pt'
- # SAR数据集
- # data='D://CVproject/ultralytics-main/Dataset/SARdata.yaml'
- # coco128数据集
- data='D:/CVproject/ultralytics-main/datasets/new_COCO128.yaml'
- train(model,data)
加入了model和data传参的过程,便于后期的使用其余数据集
使用的权重参数是yolov8.pt,data是数据集的yaml文件,最好是使用绝对路径不容易出错
记得将train中的model和data注释掉
可以开始训练
训练后的结果会保存在run中的train文件夹中
第六:使用所训练模型,验证数据集
在run中训练的最后一次train文件夹下会保存weight,最好的权重和最后的权重
我们示例是使用last.pt
在val.py文件中:
要进行相应的修改,因为yolov8由bug,目前train文件和val文件不能同时运行,会出现报错。
- Traceback (most recent call last):
- File "C:/Users/aoqia/Desktop/ultralytics-main/ultralytics/yolo/v8/detect/val.py", line 292, in <module>
- val()
- File "C:/Users/aoqia/Desktop/ultralytics-main/ultralytics/yolo/v8/detect/val.py", line 287, in val
- validator = DetectionValidator(args=args)
- File "C:/Users/aoqia/Desktop/ultralytics-main/ultralytics/yolo/v8/detect/val.py", line 23, in __init__
- super().__init__(dataloader, save_dir, pbar, args, _callbacks)
- File "C:\Users\aoqia\Desktop\ultralytics-main\ultralytics\yolo\engine\validator.py", line 78, in __init__
- project = self.args.project or Path(SETTINGS['runs_dir']) / self.args.task
- AttributeError: 'dict' object has no attribute 'project'
需要对相应的文件做修改后,val可以运行,但是train就会出错,后期再训练train时需把相应的位置再改回来
修改之处如下三处(参考博主:http://t.csdnimg.cn/UUujx):
这里不再陈列
修改好相应位置后,运行val.py验证之后如下:
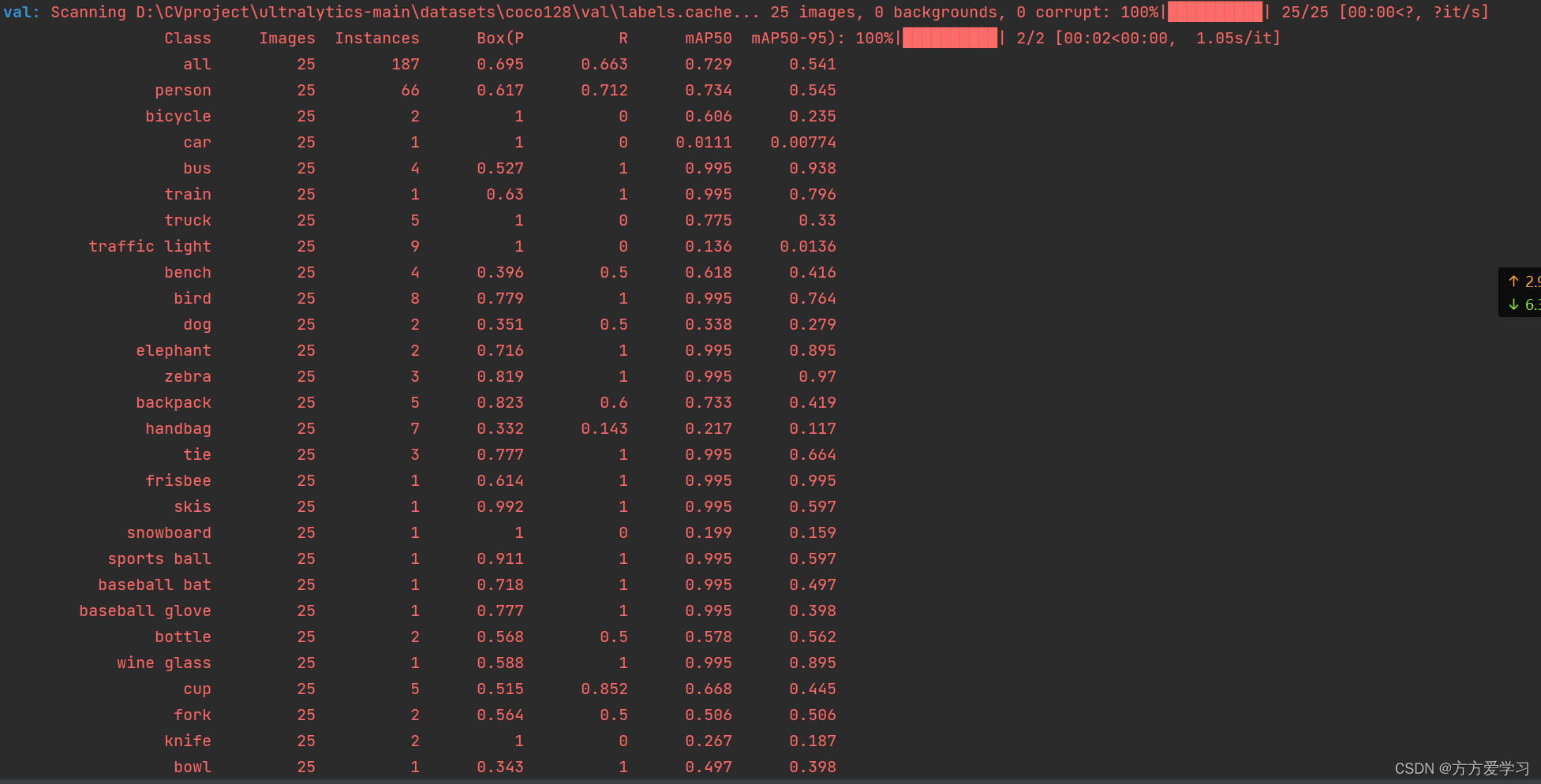
大功告成!!!!!
仅作为进门小白学习参考,如有不对的地方,感谢指正!!!

