
热门标签
热门文章
- 1【路径规划】基于人工势场的多无人机三维路径规划matlab源码
- 2Termux配置安卓编译环境_termux魔改版
- 3【正点原子Linux连载】第三十一章 外置RTC芯片AT8563T实验 摘自【正点原子】ATK-DLRK3568嵌入式Linux驱动开发指南_8563t芯片功能
- 4linux:管理员权限下发生“etc/profile“ E212: Can‘t open file for writing解决办法_/etc/profile" e212: can't open file for writing
- 5cocosCreator 之localStorage本地存储和封装拓展_cocos 拓展 cc
- 6GitOps 和 DevOps 有什么区别?
- 7pytorch学习一:Anaconda下载、安装、配置环境变量。anaconda创建多版本python环境。安装 pytorch。_anaconda环境变量
- 8【虚拟机】VM + CentOS7 + Python3.8安装与配置_centos安装python3.8
- 9职场不给“大龄”程序员活路?几招教你化解职场大龄危机_目前哪一类程序员岗位最不受年龄影响
- 10基于springboot的网上在线考试系统的设计与实现_基于spring boot的在线考试系统论文
当前位置: article > 正文
【Python自动化Excel】多个excel文件,按列匹配数据_用python实现将多个excel按某列匹配合并
作者:2023面试高手 | 2024-04-18 05:36:39
赞
踩
用python实现将多个excel按某列匹配合并
在办公场景中,我们常常会遇到这样的场景:多个的Excel文件需要基于某一列或多列进行数据的匹配、合并,并提取出匹配数据中的相关数据。
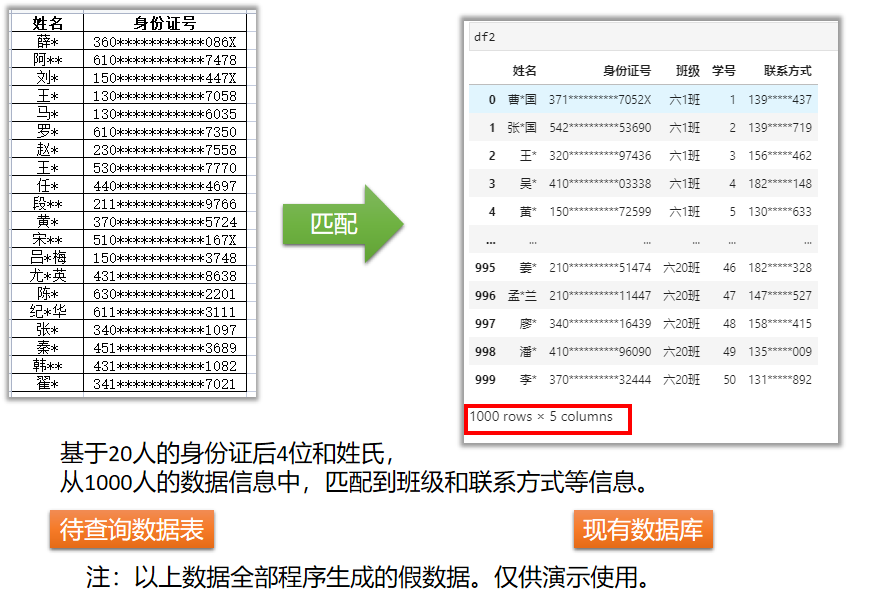
最近遇到了这样一个问题:在核酸检测过程中,某个混检的试管出了问题,而之前采样的20人已经离开了,需要在4000多人中快速找到这20人的联系方式,以便重新采集。最惨的是采集app上只能看到这20人的身份证尾号和姓氏。
要解决这个问题关键有两步:匹配数据和提取数据。
Python中的pandas库提供了这一个问题的解决方案。代码写好后,只需关注两点:按哪列数据匹配、要提取哪些列,便可以解决这类问题。
问题描述
1.辅助列生成
import pandas as pd
# 读取Excel文件
df1 = pd.read_excel('./待查询信息.xlsx')
df2 = pd.read_excel('./学生信息加密表格.xlsx')
# 待查询数据表——生成辅助列:姓氏
df1['姓氏'] = df1['姓名'].str[0]
df1['身份证后四位'] = df1['身份证号'].str[-4:]
# 数据库表——生成辅助列:编号后四位和姓氏
df2['身份证后四位'] = df2['身份证号'].str[-4:]
df2['姓氏'] = df2['姓名'].str[0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

2.合并匹配
mergeDf = pd.merge(df1,df2,how='left',on=['身份证后四位','姓氏'])
- 1
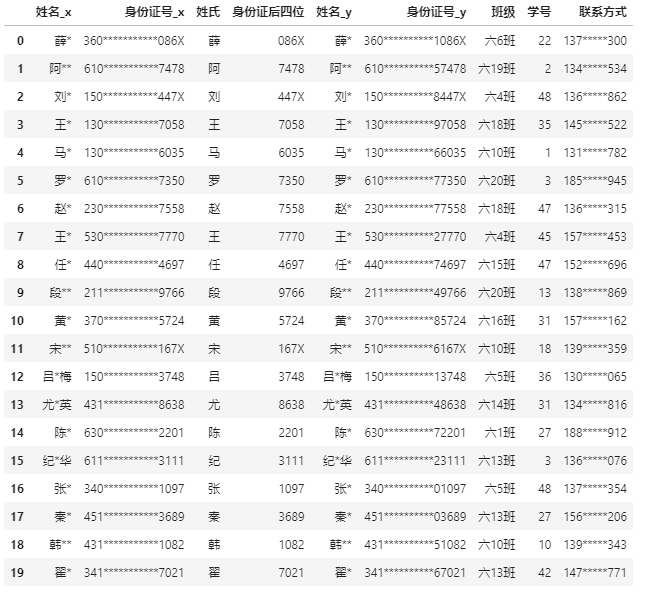
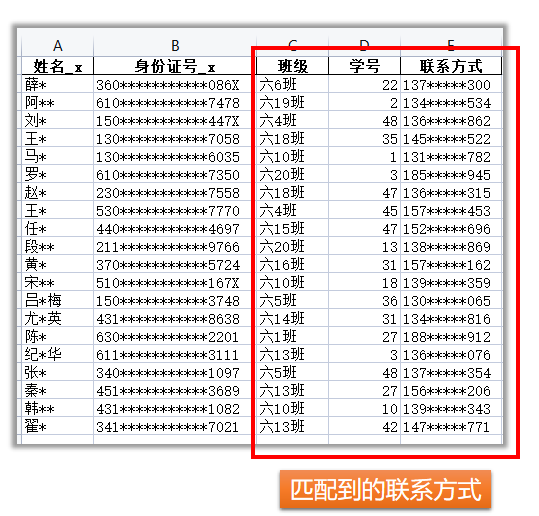
3.选取另存
# 选取需要的列名
outColNames = [
'姓名_x',
'身份证号_x',
'班级',
'学号',
'联系方式',
]
mergeDf[outColNames].to_excel("数据匹配后的结果.xlsx",index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
其实对于数据的匹配,excel中的vlookup()函数也可以做,但不同的Excel文件之间处理免不了繁琐的框选、复制、粘贴吧,而且数据量大的时候手工拖动操作不仅效率低,而且有操作失误的风险。
文件之间处理免不了繁琐的框选、复制、粘贴吧,而且数据量大的时候手工拖动操作不仅效率低,而且有操作失误的风险。
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读

相关标签

