
- 1YOLOv8部署,从图像到打标签,再到标签转换,最后机器学习。_yolov8打标签程序
- 2MySQL创建表和约束条件(四)_创建数据表hzb,里面包含以下字段:bh整数字符(此项数据不能为空)并设置为主键约束,
- 3腾讯云GPU云服务器CPU是什么?主频多少?_intel xeon cooper lake 处理器,基频 3.4 ghz,睿频3.8 ghz
- 4动态规划(DP)之入门学习-数字三角形_c语言动态规划数字三角形问题dp最简单的写法
- 5利用数据可视化技术来学习钻石鉴别_diamonds.csv 百度网盘
- 6Django及Flask漏洞合集_django漏洞集合
- 7深入了解Python自然语言处理库NLTK
- 8Android音乐播放器显示startForeground(ONGOING_NOTIFICATION_ID, notification);异常解决方法_android startforeground notification
- 9基于Matlab的Q-learning算法机器人路径规划仿真_matlab qlearn
- 10Win10安装RabbitMQ_rabbitmq的注册表在哪里
Shell脚本学习笔记_登录之后,普通用户的shell提示符[stu1@server1~]以结尾。
赞
踩
1. 写在前面
工作中,需要用到写一些shell脚本去完成一些简单的重复性工作, 于是就想系统的学习下shell脚本的相关知识, 本篇文章是学习shell脚本整理的学习笔记,内容参考主要来自C语言中文网, 学习过程中, 加入了一些在学习过程中的实践经验和思考, 并抽取出一些常用的知识内容整理成这篇文章,方便以后回看回练, 如果想更系统的学习, 可以去前面这个网站进行学习。
大纲如下:
- Shell基础
- Shell编程
- Shell高级
- Shell的一些快捷操作
Ok, let’s go!
2. Shell基础
2.1 what?
shell: 用户和内核之间的”代理”
- Shell 是一个应用程序,它连接了用户和 Linux 内核,让用户能够更加高效、安全、低成本地使用 Linux 内核,这就是 Shell 的本质。

shell主要用来开发一些实用的、自动化的小工具,例如检测计算机的硬件参数、搭建 Web 运行环境、日志分析等,不适合开发具有复杂逻辑的中大型软件。
shell是一种脚本语言。
- 编译性语言:程序运行之前,把所有的代码翻译成二进制形式(可执行文件), 用户拿到的是可执行文件,看不到源码。这个过程叫做编译,这样的编程语言叫编译性语言,完成编译过程的软件叫编译器。 C/C++, GO等
- 优点是执行速度快、对硬件要求低、保密性好,适合开发操作系统、大型应用程序、数据库等
- 解释性语言:一边执行,一边翻译,无须生成任何二进制文件, 用户拿到源码即可运行。程序运行后即时翻译,翻译一部分执行一部分,不会等所有代码都翻译完,这个过程叫做解释, 这样的编程语言叫解释性语言,完成解释过程的软件叫解释器。 python, javascript, php,shell等
- 脚本语言的优点是使用灵活、部署容易、跨平台性好,非常适合 Web 开发以及小工具的制作
2.2 why?
Shell是运维人员必须掌握的技能, Shell 脚本是实现 Linux 系统自动管理以及自动化运维所必备的工具
- Linux 运维工程师(OPS): 主要工作就是搭建起运行环境,让程序员写的代码能够高效、稳定、安全地在服务器上运行,他们属于后勤部门。OPS 的要求并不比程序员低,优秀的 OPS 拥有架设服务器集群的能力,还会编程开发常用的工具。工作细节如下:
2.3 常见的Shell
常见的 Shell 有 sh、bash、csh、tcsh、ash, zsh等。 我现在使用的是zsh
bash 由 GNU 组织开发,保持了对 sh shell 的兼容性,是各种 Linux 发行版默认配置的 shell
# 查看当前系统可用的shell
cat /etc/shells
# 查看当前系统的默认shell 默认是zsh,这里面插件很多,扩充了很多功能
echo $SHELL
- 1
- 2
- 3
- 4
- 5
- 6
SHELL是 Linux 系统中的环境变量,它指明了当前使用的 Shell 程序的位置,也就是使用的哪个 Shell。
这里安利一款比较好用的Shell, zsh, 这个安装一些插件之后有自动的代码补齐功能,还有一些很强大的功能,非常方便。
# 安装zsh
sudo apt-get install zsh # 切换完毕之后,需要重新登录
# 显示存在的bash
cat /etc/shells
# 取代bash 设为默认shell
sudo usermod -s /bin/zsh username or chsh -s /bin/zsh
# 切回去bash
chsh -s /bin/bash
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
安装上zsh之后,还需要安装一些插件, 才能让其变强大
# 安装oh my zsh 此时打开终端, 会发现颜色变了, 可以使用zsh --version看是否安装成功
$ sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
# 配置插件主题等
vim ~/.zshrc
# 推荐的插件 参考:https://segmentfault.com/a/1190000039860436
1. git
2. zsh-syntx-highlighting(高亮语法)
3. zsh-autosuggestions(自动补全)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.4 Shell命令
Shell 命令分为两种:
- Shell 自带的命令称为内置命令,它在 Shell 内部可以通过函数来实现,当 Shell 启动后,这些命令所对应的代码(函数体代码)也被加载到内存中,所以使用内置命令是非常快速的。
- 更多的命令是外部的应用程序,一个命令就对应一个应用程序。运行外部命令是要开启一个新的应用程序,需要创建新的进程,加载代码等,所以效率上比内置命令差很多
用户输入一个命令,Shell先检测是不是内部的,如果是去执行,如果不是,则检测有没有对应的外部程序,如果有, 则执行,否则报错。
怎么检测有没有对应的外部程序呢?
-
Shell 在启动文件中增加了一个叫做PATH 的环境变量,该变量就保存了 Shell 对外部命令的查找路径,如果在这些路径下找不到同名的文件,Shell 报错找不到命令。这就是为啥有些软件安装之后,要配置环境变量的原因,如果不配置,软件里面的有些命令无法在shell里面使用。
echo $PATH- 1
2.5 Shell命令的选项和参数
shell命令的基本格式:
command [选项] [参数]
- 1
选项用于调整命令功能,而命令的参数是这个命令的操作对象。不管是内置命令还是外部命令,它后面附带的数据最终都以参数的形式传递给了函数
2.6 Shell命令的提示符
命令提示符不是命令的一部分,起到提示作用。
[wuzhongqiang@localhost ~]$
- 1
各个部分的含义如下:
[]是提示符的分隔符号,没有特殊含义。wuzhongqiang表示当前登录的用户。@是分隔符号,没有特殊含义。localhost表示当前系统的简写主机名~代表用户当前所在的目录为主目录(home 目录)。如果用户当前位于主目录下的 bin 目录中,那么这里显示的就是bin。$是命令提示符。Linux 用这个符号标识登录的用户权限等级:如果是超级用户(root 用户),提示符就是#;如果是普通用户,提示符就是$。
Shell通过修改PS1和PS2两个环境变量可以控制上面提示符的格式。
[wuzhongqiang@localhost ~]$ echo $PS1
[\u@\h \W]\$
[wuzhongqiang@localhost ~]$ echo $PS2
>
[wuzhongqiang@localhost ~]$ PS1="[\t][\u]\$ "
[12:51:43][wuzhongqiang]$ PS1="[hello, world]\$ "
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这种修改只对当前会话有效,如果想固定格式,让它对任何 Shell 会话都有效,那么就得把 PS1 变量的修改写入到 Shell 启动文件中
2.7 Shell脚本
shell脚本, 从hello world开始:
#!/bin/bash
echo "Hello World !"
- 1
- 2
#!是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell;后面的/bin/bash就是指明了解释器的具体位置。
脚本中,可以编写各种命令,实现一些自动话的操作等, 可以通过编写注释#开头,让脚本更加通俗易懂。
Shell脚本的执行方式:
- 作为程序执行
chmod a+x [test.sh](http://test.sh) ./test.sh - shell脚本作为参数传递给bash解释器
/bin/bash [test.sh](http://test.sh), 这种方式运行脚本,其实不需要在脚本文件的第一行指定解释器信 - source命令执行,不需要给脚本增加执行权限
source [test.sh](http://test.sh) 或 . testsh这个是在当前进程中运行脚本,上面两个是开启了新进程运行脚本
如果需要在当前进程运行shell脚本,就用3的这两种方式,如果是开一个新进程运行shell脚本,就用1或者2这种方式。
2.8 Shell配置文件
Shell在启动时要配置运行环境,如初始化环境变量、设置命令提示符、指定系统命令路径等。这个过程会加载一系列配置文件。
如果是登录式方式启动shell
/etc/profile: 全局配置文件, 最优先加载~/.bash_profile、~/.bash_login、~/.profile: 个人用户的配置文件,不同系统配置文件可能不同,优先级依次降低, bash_profile中会读取bashrc
如果是非登陆方式启动shell, 会直接读~/.bashrc
~/.bashrc、/etc/bashrc、/etc/profile.d/*.sh: bashrc中会读etc/bashrc
上面提到了登录式和非登录式, 这是啥意思呢?
Shell其实有4种运行方式, 由下面的两个维度两两组合:
- 登录和非登录: 登录是需要输入用户名和密码, 非登录就是直接登录了,判断方法:
shopt login_shell - 交互和非交互:交互是跟shell不停互动, 而非交互是把命令写到shell脚本种,一键运行。判断方法:
echo $PS1$PS1在非交互下是空值
用户编写自己的shell脚本文件:把握好~/.bashrc。
- 将自己的一些代码添加到
~/.bashrc,这样每次启动 Shell 都可以个性化地配置。 - 或将自己编写的代码放到一个新脚本myconf.sh,然后在
~/.bashrc中使用类似. ./myconf.sh的形式将新文件引入进来就行了
输入一个命令之后, Shell是去PATH变量中去找到对应的程序,所以PATH变量的设置很重要。
- 如果是登录式shell, PATH在
/etc/profile中设置,然后在~/.bash_profile也会增加几个目录 - 如果是非登录式,PATH会在
etc/bashrc中设置
如果我们想增加自己的一些命令路径,将路径放到~/.bashrc 中
PATH=$PATH:xxx/anaconda/bin
- 1
3. Shell编程
3.1 变量
3.1.1 变量初识
shell是一种脚本语言, 符合脚本语言定义变量的规则:不需要指定类型,直接赋值
Bash Shell中,每一个变量的值都是字符串,无论用没用引号, 值都会以字符串的形式存储。即使你将整数和小数赋值给变量,它们也会被视为字符串。
支持三种变量的定义:
variable=value
variable='value'
variable="value"
- 1
- 2
- 3
赋值号=的周围不能有空格。使用变量, 变量前面加$符号即可, $variable
推荐给所有变量加上花括号{ } , 有利于帮助解释器识别变量边界 ${variable}
- 单引号
' '包围变量的值时,单引号里面是什么就输出什么,即使内容中有变量和命令(命令需要反引起来)也会把它们原样输出。这种方式比较适合定义显示纯字符串的情况,即不希望解析变量、命令等的场景 - 以双引号
" "包围变量的值时,输出时会先解析里面的变量和命令,而不是把双引号中的变量名和命令原样输出。这种方式比较适合字符串中附带有变量和命令并且想将其解析后再输出的变量定义

如果变量的内容是数字,那么可以不加引号;如果真的需要原样输出就加单引号;其他没有特别要求的字符串等最好都加上双引号,定义变量时加双引号是最常见的使用场景。
如果想把命令的结果赋值给变量, 建议用这种方式:
variable=`command` # 上面这个
variable=$(command) # 这一种方式建议
# 方式一可以在多种shell中有效, 但方式二只在bash shell中有效
# 方式一不支持嵌套, 方式二可以
Fir_File_Lines=$(wc -l $(ls | sed -n '1p'))
- 1
- 2
- 3
- 4
- 5
- 6
readonly可以将变量声明为只读变量
temp="wuzhongqiang"
readonly temp
temp="zhangsan" # read-only variable: temp
- 1
- 2
- 3
unset可以删除变量
unset variable_name
注意: unset不能删除只读变量
- 1
- 2
3.1.2 变量作用域
shell中变量的作用域有三种:
-
局部变量: 只能在函数内部中使用
shell支持自定义函数,但和其他语言不同的是, shell函数里面定义的变量, 默认是全局变量, 和在函数外部定义的变量有一样的效果。
#!/bin/bash #定义函数 function func(){ a=99 } #调用函数 func #输出函数内部的变量 echo $a 99- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果仅仅想在函数内部使用, 需要加local关键字。
function func(){ local a=99 }- 1
- 2
- 3
-
全局变量: 当前shell进程中使用
首先,注意一个点,shell进程和shell脚本是两个概念。 打开一个窗口时, 就新建了一个shell进程。 在该窗口下定义的变量,默认就是全局变量, 会在该窗口下有效。如果打开一个新的窗口, 就没有效果了。
同一个窗口下,如果有多个shell脚本, 在a.sh中定义一个变量, 在b.sh中输出, 也会同样有效。
这里做一个实验:
vim a.sh 写入: #!/bin/bash a=200 echo $a vim b.sh 写入 #!/bin/bash echo $a # 然后 source a.sh 200 source b.sh 200 bash a.sh 200 bash b.sh ""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
原因是
source或者是., 表示当前进程执行脚本, 而bash表示新开进程执行脚本。 在同一个进程中,变量全局有效。不限于脚本。 -
环境变量: 子进程中有效
全局变量只在当前 Shell 进程中有效,对其它 Shell 进程和子进程都无效。如果使用
export命令将全局变量导出,那么它就在所有的子进程中也有效了,这称为“环境变量”。首先是子进程的概念:父进程中再创建进程, 该进程就是子进程, 父进程里面的变量子进程可以使用。 最简单的方式创建子进程,就是bash命令

如果是换一个窗口就无效了。
如果想一个变量在所有窗口下都有效, 那就需要写入到配置文件中了。
3.1.3 Shell的位置参数
运行 Shell 脚本文件时可以给它传递一些参数,在脚本文件内部使用$n的形式来接收,例如,$1 表示第一个参数,$2 表示第二个参数…
vim a.sh
#!/bin/bash
echo "$1"
echo "$2"
./a.sh hello world
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在调用函数时也可以传递参数。Shell 函数参数的传递和其它编程语言不同,没有所谓的形参和实参,在定义函数时也不用指明参数的名字和数目。换句话说,定义 Shell 函数时不能带参数,但是在调用函数时却可以传递参数,这些传递进来的参数,在函数内部就也使用$n的形式接收,例如,$1 表示第一个参数,$2 表示第二个参数,依次类推。
#!/bin/bash
#定义函数
function func(){
echo "$1"
echo "$2"
}
#调用函数
func hello world
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这种通过$n的形式来接收的参数,在 Shell 中称为位置参数。
3.1.4 Shell的特殊变量

demo:
vim c.sh
bash c.sh hello world
#!/bin/bash
echo "process id: $$" 589461
echo "file name: $0" c.sh
echo "first param: $1" hello
echo "secord param: $2" world
echo "all parameters 1: $@" hello world
echo "all parameters 2: $*" hello world
echo "parameters count: $#" 2
# 函数亦然
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
几个点需要看一下:
-
$@和$*: 都表示给传递给脚本或者函数的所有脚本或者参数,如果不被””包围,两者没有区别,都会将每个参数看作一份数据,中间空格隔开。如果被””包围,两者就有区别:”$@”: 仍然将每个参数都看作一份数据,彼此之间是独立的“$*“: 会将所有的参数从整体上看做一份数据,而不是把每个参数都看做一份数据
vim d.sh # 执行 bash d.sh a b c d #!/bin/bash echo "$@" # a b c d echo 输出没有区别 echo "$*" # a b c d for var in "$@" # a do # b echo $var # c done # d for var in "$*" do echo $var # a b c d done for var in $@ # a do # b echo $var # c done # d for var in $* # a do # b echo $var # c done # d- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
-
$?: 用来获取上一个命令的退出状态,或者上一个函数的返回值#!/bin/bash if [ "$1" == 100 ] then exit 0 #参数正确,退出状态为0 else exit 1 #参数错误,退出状态1 fi bash ./test.sh 100 # 开启一个新进程,如果是和上面用同一个进程,退出之后就啥也看不见了 echo $? 0 bash ./test.sh 1 echo $? 1 vim test.sh #!/bin/bash function test(){ return `expr $1` } test 2 echo $? # 2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
Shell 函数中的 return 关键字用来表示函数的退出状态,而不是函数的返回值。
3.2 字符串
字符串是 Shell 编程中最常用的数据类型之一。
字符串可以不被引号包围, 可以被’’包围, 也可以被’’包围, 但是有区别:
‘’包围:任何字符都会原样输出,在其中使用变量是无效的,字符串中不能出现单引号,即使对单引号进行转义也不行。“”包围:如果其中包含了某个变量,那么该变量会被解析(得到该变量的值),而不是原样输出,如果字符串中有双引号,只要被转义就可以。- 没有引号包围:不被引号包围的字符串中出现变量时也会被解析,这一点和双引号
" "包围的字符串一样,字符串中如果出现空格,空格后边的字符串会作为其他变量或者命令解析
demo:
#!/bin/bash
n=666
str0=$n
str1=hello$n world
str2="hello \"world\" $n"
str3='hello world $n'
echo $str0 # 666
echo $str1 # world 未找到命令 如果没有空格, 只会输出hello $n也不会被解析了, 如果是hello"$n"world 此时$n会被解析
echo $str2 # hello "world" 666
echo $str3 # hello world $n
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
获取字符串的长度 ${#str_name}
echo ${#str3} 14
- 1
字符串的拼接: 将两个字符串并排放实现拼接
str1=$name$url #中间不能有空格
str2="$name $url" #如果被双引号包围,那么中间可以有空格
str3=$name": "$url #中间可以出现别的字符串
str4="$name: $url" #这样写也可以
str5="${name}Script: ${url}index.html" #这个时候需要给变量名加上大括号, 认清楚边界
- 1
- 2
- 3
- 4
- 5
字符串的截取:
-
从指定位置截取字符
# 从左边开始计数, 截取字符串 ${string: start :length} # start从0开始,length如果不写,截取到末尾 url="hello world" echo ${url: 2: 3} # llo # 从右边开始计数,截取字符串 ${string: 0-start :length} # 注意 # 从左边开始计数时,起始数字是 0(这符合程序员思维); # 从右边开始计数时,起始数字是 1(这符合常人思维)。计数方向不同,起始数字也不同。 # 不管从哪边开始计数,截取方向都是从左到右。 url="c.biancheng.net" echo ${url: 0-13: 9} # biancheng- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
从指定字符截取字符
无法指定字符串长度,只能从指定字符(子字符串)截取到字符串末尾
# ‘#’截取字符右边的所有字符 ${string#*chars} # string是要截取的字符串, chars是指定字符, 不包括chars本身 url="http://c.biancheng.net/index.html" echo ${url#*/} # /c.biancheng.net/index.html # 遇到第一个字符就开始往后截取,如果是希望遇到最后一个指定字符往后截取 echo ${url##*/} # index.html # '%'截取字符左边的所有字符 ${string%chars*} # 注意*的位置,因为要截取 chars 左边的字符,而忽略 chars 右边的字符,所以*应该位于 chars 的右侧 url="http://c.biancheng.net/index.html" echo ${url%/*} # http://c.biancheng.net echo ${url%%/*} # http:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
字符串的分割(这里是我这边的一个真实需求, 给定两个可以分割的demo)
#!/bin/bash set -eux car_fqdns=("eng.bhd.0001" "eng.bhd.0003" "eng.bhd.0004" "eng.bhd.0009" "eng.bhd.0010") echo "车辆: ${car_fqdns[*]}, 个数: ${#car_fqdns[*]}" for car in $car_fqdns do IFS='.' read -r car_model car_type car_no <<< "$car" echo $car_type/$car_no done #!/bin/bash set -eux car_fqdns=("eng.bhd.0001" "eng.bhd.0003" "eng.bhd.0004" "eng.bhd.0009" "eng.bhd.0010") echo "车辆: ${car_fqdns[*]}, 个数: ${#car_fqdns[*]}" for car in $car_fqdns do car_model=$(echo $car | cut -d'.' -f1) car_type=$(echo $car | cut -d'.' -f2) car_no=$(echo $car | cut -d'.' -f3) echo $car_type/$car_no done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3.3 数组
Shell 只支持一维数组,不支持多维数组
数组定义格式:
# 数组用()定义,元素之间用空格
array_name=(ele1 ele2 ele3 ... elen)
# shell数组是弱类型,不要求数组所有类型相同
arr=(20 56 "hello world")
# 长度也不是固定的,可以根据下表再加
arr[4]=666
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
获取数组元素:
${array_name[index]} # 获取数组中的所有元素 *或者@都可以的 ${nums[*]} ${nums[@]} #!/bin/bash arr=(1 2 3 4 5) echo ${arr[*]} # 1 2 3 4 5 echo ${#arr[*]} # 5 # 获取数组中的元素个数 加面加# ${#array_name[@]} ${#array_name[*]} # 如果一个数组元素是字符串, 再通过#获取改字符串的长度 ${#arr[2]}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
数组的拼接操作:将数组扩展成列表,然后再拼接起来
array_new=(${array1[@]} ${array2[@]})
array_new=(${array1[*]} ${array2[*]})
- 1
- 2
数组的删除:
# 删除某个单一的元素
unset arr[index]
# 删除全部的数组元素
unset arr
- 1
- 2
- 3
- 4
- 5
shell关联数组:也称为”键值对”, 和python里面的字典很像
# 创建关联数组 必须带有-A选项 declare -A stu stu["name"]="zhongqiang" stu["age"]="27" stu["sex"]="male" declare -A stu=(["name"]="zhongqiang" ["age"]="27" ["sex"]="male") # 访问关联数组元素 echo ${stu["name"]} # zhongqiang # 获取关联数组元素的所有value *可以换成@ echo ${stu[*]} # zhongqiang 27 male # 获取关联数组元素的所有key echo ${!stu[*]} # name age sex # 获取关联数组的长度 echo ${#stu[*]} # 3 #获取所有元素值 for value in ${stu[@]} do echo $value done echo "****************" #获取所有元素下标(键) for key in ${!stu[*]} do echo $key done echo "****************" #列出所有键值对 for key in ${!stu[@]} do echo "${key} -> ${stu[$key]}" done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
3.4 命令
3.4.1 内置命令
bash自身提供的命令,不是文件系统中某个可执行文件,比如cd
使用type可以确定一个命令是内部还是外部文件:
[icss@hadoop102 shell_study]$ type cd
cd 是 shell 内嵌
[icss@hadoop102 shell_study]$ type ifconfig
ifconfig 是 /usr/sbin/ifconfig
- 1
- 2
- 3
- 4
内部命令,不需要触发磁盘IO, 不需要fork出一个单独进程, 所以执行通常比外部命令快。
$PATH变量包含的目录中的大多数,都是外部命令。
# 最基础的
cd . break echo exec exit export help kill history pwd read type source nset continue wait
- 1
- 2
- 3
下面整理几个比较常用的内部命令:
-
alias: 给命令创建别名, 如果直接输入该命令,不带参数, 会列出当前shell进程中使用了哪些别名。[icss@hadoop102 shell_study]$ alias alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto' alias l.='ls -d .* --color=auto' alias ll='ls -l --color=auto' # 这个常用 alias ls='ls --color=auto' alias vi='vim' alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde' # alias定义别名 alias new_name='command' # demo alias shutown='shutdown -h now' alias timestamp='date +%s' # date可以获取当前UNIX时间戳 # 下面尝试了下在aliah.sh中测试alias #!/bin/bash alias timestamp='date +%s' echo `timestamp` # 会报错说找不到timestamp命令,这个是因为非交互模式下,alias扩展时关闭的,所以需要用shopt命令将其开启才可以 # 所以如果想运行网站上的例子,需要这么干 #!/bin/bash alias timestamp='date +%s' shopt -s expand_aliases begin=`timestamp` sleep 20s finish=$(timestamp) difference=$((finish - begin)) echo "run time: ${difference}s" # 20s # unalias 删除别名 unalias timestamp- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
这里顺便整理下shopt命令, 这个也是shell的内置命令, 控制shell功能选项的开启和关闭,从而控制shell的行为
shopt -s opt_name Enable (set) opt_name. shopt -u opt_name Disable (unset) opt_name. shopt opt_name Show current status of opt_name # 我们可以 shopt command # 来查看功能选线的状态 [icss@hadoop102 shell_study]$ shopt expand_aliases expand_aliases on # 交互shell中这东西是开着的,但是在脚本里面, 用这个命令会发现是off,说明非交互shell中这东西关着了,打开之后,才可以用alias命令- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上面的别名设置是临时的,只在当前shell进程中有用,如果想对所有shell进程都有效, 就需要把别名写入配置文件。
-
echo: 用来在终端输出字符串,并在最后默认加换行符,类似于Python里面的print# 如果不希望最后加换行, 可以-n参数 [icss@hadoop102 shell_study]$ echo "hello world" hello world [icss@hadoop102 shell_study]$ echo -n "hello world" hello world[icss@hadoop102 shell_study]$ # 默认情况,echo不会解析以\开头的转义字符 # 如果想让echo解析转义字符, 加-e参数,此时,如果再让他不换行, 也可以加\c hello world[icss@hadoop102 shell_study]$ echo "hello\nworld" hello\nworld [icss@hadoop102 shell_study]$ echo -e "hello\nworld" hello world [icss@hadoop102 shell_study]$ echo -e "hello\nworld\c" hello world[icss@hadoop102 shell_study]$ echo -n -e "hello\nworld" hello world[icss@hadoop102 shell_study]$- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
-
read: 从标准输入中读取数据赋值给变量,如果没有重定向,默认从键盘,如果有重定向,可以从文件read [-options] [variables] # options -a array # 读取的数据赋值给数组array -d delimiter # 字符串delimiter指定读取结束的位置(不包括delimiter), 默认是换行符结束 -n num # 读取num个字符 -p prompt # 显示提示信息,提示内容prompt -r # 原样读取,\不解释为转移 -s # 静默模式,不是在屏幕上显示输入的字符, 密码的时候常用 -t seconds # 设置超时时间,单位s,用户没有指定时间输入,read退出 -u fd # 用文件描述符fd作为输入源,类似重定向 # variables # 也是可选的,如果没有提供变量名,那么读取的数据将存放到环境变量 REPLY # demo #!/bin/bash read -p "input you name and age > " name age echo ${name} echo ${age} [icss@hadoop102 shell_study]$ bash read.sh input you name and age > wuzhongqiang 28 wuzhongqiang 28 [icss@hadoop102 shell_study]$ # 看一个静默模式的 #!/bin/bash read -sp "input passwd > " passwd echo ${passwd} # 这时候输入的时候, 看不见输入了- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
-
exit: 退出当前进程, 并返回一个退出状态,使用$?可以接收这个状态,当然是在另一个shell进程中。# Shell 进程执行出错时,可以根据退出状态来判断具体出现了什么错误 # 比如打开一个文件时,我们可以指定 1 表示文件不存在,2 表示文件没有读取权限,3 表示文件类型不对 #!/bin/bash echo "befor exit" exit 1 echo "after exit" [icss@hadoop102 shell_study]$ bash exit.sh before exit [icss@hadoop102 shell_study]$ echo $? 1 [icss@hadoop102 shell_study]$ # 这里之所以可以直接echo $? 是因为bash是新开了一个进程, 也就是bash新开进程后, 执行了exit.sh脚本 # 遇到exit 1就退出新开的进程了,所以没有after exit没有显示 # echo $? 其实是另一个进程了,如果上面不是用bash 而是用. exit.sh 就直接退出当前shell窗口了- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
declare: 设置变量属性# 用法: +表示给变量加属性, -表示减属性 declare [+/-] [aAfFgilprtux] [变量名=变量值] # aFfFgilprtux 具体选项 # -f [name] 列出之前由用户在脚本中定义的函数名函数体 # -F [name] 仅自定义函数名 # -g name shell函数内部创建全局变量 # -p [name] 显示指定变量的属性和值 # -a name 声明变量是普通数组 # -A name 关联数组 # -i name 变量定义为整型 # -r name[=value] 变量定义为只读(不可修改删除) # -x name[=value] 变量设置为环境变量,等价export name=value #!/bin/bash declare -i m n ret #将多个变量声明为整数 m=10 n=30 ret=$m+$n echo $ret declare -r n=10 n=20 # 报错 只读变量- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
-
数学计算命令:shell不能直接算数运算, 必须用数学计算命令
在 Bash Shell 中,如果不特别指明,每一个变量的值都是字符串,无论你给变量赋值时有没有使用引号,值都会以字符串的形式存储,所以直接用数学运算符,其实是字符串之间的运算
echo 2+8 # 2+8 # 常用的数学计算命令 ((表达式)) # 整数运算,效率很高,推荐 注: 只能进行整数运算,不能对小数(浮点数)或者字符串进行运算 result=$((a=10+66)) # 普通运算 result=$((1+2**3-4%3)) # 复杂运算 result=$((8<3)) # 逻辑运算 result=$((a++)) # 自增运算 ((a=3+5, b=a+10)) # 多表达式计算 echo $a # 8 echo $b # 18 c=((3+5, a+b)) # 26 以最后一个表达式的结果作为整个(())命令的执行结果 # bc 可以处理小数 # shell脚本中,借助管道使用bc计算器 variable=$(echo "expression" | bc) echo "3*8"|bc # 普通 echo "scale=4;3*8/7;last*5"|bc echo "scale=5;n=$x+2;e(n)"|bc -l # shell脚本中的变量 # 如果是大量的数学运算, 用输入重定向比较方便 可以换行写 variable=$(bc << EOF expressions EOF ) m=1E n=$(bc << EOF > obase=10; # 10进制 > ibase=16; # 16进制 > print $m > EOF > )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
另外一种方式,使用declare命令,将变量声明为整数,但不灵活,开发中很少用
declare -i m n ret m=10 n=30 ret=$m+$n echo $ret echo $m+$n # 此时, m,n依然被看作字符串 # 注意 # 除了将参与运算的变量定义为整数,还得将承载结果的变量定义为整数,而且只能用整数类型的变量来承载运算结果,不能直接使用 echo 输出- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.5 结构
3.5.1 if else语句
# 最简单的if语句 if condition then statement(s) fi # 还有种写法 下面的分号是必要的 if condition; then statement(s) fi # if else if condition then statement1 else statement2 fi # if elif if condition1 then statement1 elif condition2 then statement2 elif condition3 then statement3 …… else statementn fi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
选择结构语句比较常规,比较重要的是, 怎么写判断条件, [[]]用来检测某个条件是否成立。
[[ expression ]] # 空格必须
# 支持多个表达式的判断
[[ expression1 || expression2 ]]
[[ expression1 && expression2 ]]
[[ !expression1 ]]
- 1
- 2
- 3
- 4
- 5
- 6
在shell脚本中, 经常使用判断语句来使得脚本更好的健壮性, 比如判断文件存不存在,目录是否存在, 输入是否有误等, 上面的语法可以检测某个条件是否成立,那么常用的判断条件会有哪些呢?
# 文件类型检测相关 [[ -b filename ]] # 文件是否存在,并且是否为块设备文件 [[ -c filename ]] # 文件是否存在,并且是否为字符设备文件 [[ -d filename ]] # 文件是否存在,并且是否为目录文件(常用) [[ -e filename ]] # 文件是否存在 [[ -f filename ]] # 文件是否存在,并且是否为普通文件 [[ -L filename ]] # 文件是否存在,并且是否为符号链接文件 [[ -p filename ]] # 文件是否存在,并且是否为管道文件 [[ -s filename ]] # 文件是否存在,并且是否为非空 [[ -S filename ]] # 文件是否存在,并且是否为套接字文件 # 文件权限检测相关 [[ -r filename ]] # 文件是否存在,并且是否有读权限 [[ -w filename ]] # 文件是否存在,并且是否有写权限 [[ -x filename ]] # 文件是否存在,并且是否有执行权限 # 数值比较相关 [[ num1 -eq num2 ]] # num1是否和num2相等 [[ num1 -ne num2 ]] # num1是否和num2不相等 [[ num1 -gt num2 ]] # num1是否大于num2 [[ num1 -lt num2 ]] # num1是否小于num2 [[ num1 -ge num2 ]] # num1是否大于等于num2 [[ num1 -le num2 ]] # num1是否小于等于num2 # 字符串判断相关 [[ -z str ]] # 判断字符串str是否为空 [[ -n str ]] # 判断字符串str是否非空 [[ str1==str2 ]] # 判断两字符串是否相等 [[ str1\>str2 ]] # 判断是否大于, 注意这里是转义,防止>误认为重定向 \<
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
注意两点:
- Shell 中,
==、>、<只能用来比较字符串,不能比较数字 - 不管是比较数字还是字符串,Shell 都不支持
>=和<=运算符
一个建议:[[ ]] 对数字的比较仍然不友好,使用 if 判断条件时,用 (()) 来处理整型数字,用 [[ ]] 来处理字符串或者文件,如果用到小数, 用bc
3.5.2 case in语句
当分支较多,并且判断条件比较简单时,使用 case in 语句可能会方便。
case expression in pattern1) statement1 ;; pattern2) statement2 ;; pattern3) statement3 ;; …… *) statementn esac # expression 可以是一个变量,一个数字,字符串活表达式,命令的执行结果等 # pattern 可以是数字,字符串, 简单正则 # ;;类似于 c里面的break, *类似于c里面的default, *之前的判断里面必须带着;;,否则会有语法错误 # *作为最后的兜底 # demo #!/bin/bash read -n 1 char case $char in [a-zA-Z]) printf "\nletter\n" ;; [0-9]) printf "\nDigit\n" ;; [0-9]) printf "\nDigit\n" ;; [,.?!]) printf "\nPunctuation\n" ;; *) printf "\nerror\n" esac
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
3.5.3 while循环
while condition do statements done # demo #!/bin/bash read m read n sum=0 while ((m <= n)) do ((sum += m)) ((m++)) done echo "The sum is: $sum"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.5.4 for循环
shell支持两种风格的for循环, c风格和python风格, 这里只整理Python风格,平时用python较多。
for variable in value_list do statements done # 取值列表 value_list 的形式有多种 # 直接给出具体的值 "abc" "390" "tom" # 可以给出一个范围 {start..end}, 比如{1..100} {A..z} 仅支持数字和字母 # 可以使用命令产生的结果 $(seq 2, 2, 100) 表示从2开始,每次增加2到100,类似于python里面的range(2, 101, 2) $(ls *.sh) # 甚至使用通配符 *.sh # 使用特殊变量 $@ $*等 # demo #!/bin/bash for filename in *.sh do echo $filename done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.5.5 select in 循环详解
用来增强交互, 可以显示出带编号的菜单,用户输入不同编号, 可以选择不同菜单,执行不同功能。
通常和case in一起使用,根据用户输入编号的不同作出反应
# 注意,select 是无限循环(死循环),输入空值,或者输入的值无效,都不会结束循环 # 只有遇到 break 语句,或者按下 Ctrl+D 组合键才能结束循环 select variable in value_list do statements done # 这里写一个demo vim select_in.sh #!/bin/bash select name in "wuzhongqiang" "zhangsan" "lisi" do case $name in "wuzhongqiang") echo "${name} age 28" ;; "zhangsan") echo "${name} age 30" ;; "lisi") echo "${name} age 10" ;; *) echo "输入有错误" esac done # 执行 [icss@hadoop102 ~]$ bash select_in.sh 1) wuzhongqiang 2) zhangsan 3) lisi #? 1 wuzhongqiang age 28 #? 2 zhangsan age 30 #? 3 lisi age 10 #? 4 输入有错误 #? 5 输入有错误 #? 3 lisi age 10 #?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
3.6 函数
语法格式:
function name() { statements [return value] } # 和其它编程语言不同的是,Shell 函数在定义时不能指明参数,但是在调用时却可以传递参数,并且给它传递什么参数它就接收什么参数 # Shell 也不限制定义和调用的顺序,你可以将定义放在调用的前面,也可以反过来,将定义放在调用的后面 # demo #!/bin/bash function getsum(){ local sum=0 for n in $@ do ((sum+=n)) done return $sum } getsum 10 20 55 15 #调用函数并传递参数 echo $? # 100 # 这种方法虽然可用,但在shell中,这种方式非常错误 原因下面解释
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
-
shell的函数参数:
函数参数是 shell位置参数的一种,在函数内部可以使用
$n来接收,例如,$1表示第一个参数,$2表示第二个参数$#: 获取传递参数的个数$*或者$@一次性获取所有参数。#!/bin/bash #定义函数 function show(){ echo "Name: $1" echo "Age: $2" } #调用函数 function getsum(){ local sum=0 for n in $@ do ((sum+=n)) done echo $sum return 0 } #调用函数并传递参数,最后将结果赋值给一个变量 total=$(getsum 10 20 55 15) echo $total # 100 等价于echo $(getsum 10 20 55 15)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
-
shell的函数返回值:
在 大部分编程语言中,返回值是指函数被调用之后,执行函数体中的代码所得到的结果,这个结果就通过 return 语句返回。
But在shell中, 返回值表示的是函数的退出状态:
- 返回值为 0 表示函数执行成功了,返回值为非 0 表示函数执行失败
- 函数执行失败时,可以根据返回值(退出状态)来判断具体出现了什么错误
- 如果函数体中没有return语句, 就会使用最后一条命令的退出状态
所以,在shell中,用
return返回函数的处理结果是不对的。那么怎么得到函数的处理结果呢?两种方案- 借助全局变量, 将得到的结果赋值给全局变量
- 另外一种是在函数内部用
echo, printf命令将结果输出,在函数外部用$()或者````捕获结果
#!/bin/bash sum=0 #全局变量 function getsum(){ for((i=$1; i<=$2; i++)); do ((sum+=i)) #改变全局变量 done return $? #返回上一条命令的退出状态 } read m read n if getsum $m $n; then echo "The sum is $sum" #输出全局变量 else echo "Error!" fi # 这种方法的弊端: 定义函数的同时还得额外弄一个全局变量,而全局变量是个不太好的编程思路,无意中可能增加函数之间的耦合性 # 下面的方式较为优雅 #!/bin/bash function getsum(){ local sum=0 #局部变量 for((i=$1; i<=$2; i++)); do ((sum+=i)) done echo $sum return $? } read m read n total=$(getsum $m $n) # 捕获住了函数里面的输出给到total echo "The sum is $total" # 如果函数里面, 想获取到多个输出怎么办呢? 从一个echo中打印,然后函数外部获取 #!/bin/bash function getsum(){ local sum=0 local product=1 for((i=$1; i<=$2; i++)); do ((sum+=i)) ((product*=i)) done echo "${sum} ${product}" # echo ${sum} ${product}也可以 return $? } read m read n total=$(getsum $m $n) echo "${total[*]}" # 可以算累加和累乘- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
下面看一个高级的, 就是想统计下某个目录下的文件个数
#!/bin/sh func() { echo `ls -1 $ROOT_PATH` # 没有""括起来, 第一个变量就返回了 } for i in `func` do echo $i done # 但注意,echo的返回值, 被认为是一个一个的变量,所以必须写个for循环才能循环把文件都打印出来 # 如果想统计某个目录下的文件个数呢, 用下面方式才可以 #!/bin/sh func() { echo "`ls -1 $ROOT_PATH`" # 这样用""括起来, 这个命令的执行结果就变成了一个变量 } echo `func | wc -l` # 这样才能统计到正确的数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4. Shell高级
4.1 Shell重定向
标准的输入和输出: 用户从键盘输入,把输入给的到程序, 程序计算,产生结果,输出到屏幕
- 输入重定向: 数据不是从键盘输入给到程序,而是改变了输入源,比如从文件
- 输出重定向: 程序计算完结果不是输出到屏幕,而是改变了输出点,比如文件
4.1.1 输出重定向
指命令的结果不输出到屏幕上,而是输出到其他地方保存,需要的时候可以随时查。
# 标准输出重定向 command >file # command的正确结果输出,覆盖的方式输出到文件 command >>file # command的正确结果输出,追加的方式输出到文件 command 2>file # command的错误结果输出,覆盖的方式输出到文件 command 2>>file # command的错误结果输出, 追加的方式输出到文件 # 正确输出和错误输出同时保存 command >file 2>&1 # 覆盖的方式, 把command正确错误信息都保存到file command >>file 2>&1 # 追加的方式, 把command... command >file1 2>file2 # 覆盖的方式, command的正确结果保存到file1, 错误结果保存到file2 command >>file1 2>>file2 # 追加的方式, .... # 输出重定向的完整写法其实是fd>file或者fd>>file,其中 fd 表示文件描述符,如果不写,默认为 1,也就是标准输出文件 # 默认为1时,可以省略, 如果不省略, command 1>file, 1和>不能有空格 # demo #!/bin/bash for str in "wuzhongqiang" "zhangsan" "lisi" do echo $str>>"name.txt" done ➜ shell_study cat name.txt wuzhongqiang zhangsan lisi # 错误的输出重定向 ➜ shell_study ls java ls: 无法访问 'java': 没有那个文件或目录 ➜ shell_study ls java 2>error.log ➜ shell_study cat error.log ls: 无法访问 'java': 没有那个文件或目录
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
4.1.2 输入重定向
输入重定向就是改变输入的方向,不再使用键盘作为命令输入的来源,而是使用文件作为命令的输入。
command <file # file的内容作为command的输入
command <<END # 标准输入作为command输入,直到遇到END为止
command <file >>file2 # file作为command的输入,并把输出结果给到file2
# demo 统计文档中的单词个数
wc [选项] [文件名]
# -c 统计字节数
# -w 统计单词数
# -l 统计行数
# demo
wc -l <name.txt # 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Linux中一切皆文件,为了表示和区分文件,linux会给每个文件分配一个编号, 这个编号就是文件描述符。
一个 Linux 进程启动后,会在内核空间中创建一个 PCB 控制块,PCB 内部有一个文件描述符表(File descriptor table),记录着当前进程所有可用的文件描述符,也即当前进程所有打开的文件。
除了文件描述符表,系统还维护另外两个表:
- 打开文件表
- i-node表
文件描述符表,每个进程都有一个, 而后面两个表,是系统维护的。

文件描述符是一个数组下标,通过文件描述符,可以找到文件指针,从而进入打开文件表。该表存储了以下信息:
- 文件偏移量,也就是文件内部指针偏移量。调用
read()或者write()函数时,文件偏移量会自动更新,当然也可以使用lseek()直接修改。 - 状态标志,比如只读模式、读写模式、追加模式、覆盖模式等。
- i-node 表指针。
然而,要想真正读写文件,还得通过打开文件表的 i-node 指针进入 i-node 表,该表包含了诸如以下的信息:
- 文件类型,例如常规文件、套接字或 FIFO。
- 文件大小。
- 时间戳,比如创建时间、更新时间。
- 文件锁。
所以Linux每次读写文件的时候,都从文件描述符下手,通过文件描述符找到文件指针,然后进入打开文件表和 i-node 表。
那么重定向是怎么做到的呢? 输入输出重定向就是通过修改文件指针实现的
-
发生重定向的时候,文件描述符并没有改变,改变的是文件描述符对应的文件指针。对于标准输出,Linux 系统始终向文件描述符 1 中输出内容,而不管它的文件指针指向哪里;只要我们修改了文件指针,就能向任意文件中输出内容
command 1>log.txt # 把文件描述符1的文件指针指向了log.txt, 那么就会往log.txt中输出内容- 1
> 和 <通过修改文件描述符改变了文件指针的指向,所以能够实现重定向的功能。
那么shell对文件描述符有哪些操作呢? 弄明白这个,才能看懂上面重定向的一些写法
# 输出, 输入的时候同理, 无非是把>换成<
n>filename # 输出的方式打开filename, 并绑定到文件描述符n,默认是1,即标准输出 1>log.txt 把指向log.txt的文件指针绑定到了1
n>&m # 文件描述符m的内容覆盖文件描述符n, 比如上面command >file 2>&1, 首先是file的文件指针绑定到了1, 然后又把文件描述符1的内容覆盖了2,2也指向了file
n>&- # 关闭文件描述符n及代表的文件
&>filename # 正确和错误的输出结果全部重定向到filename
- 1
- 2
- 3
- 4
- 5
4.1.3 exec命令操作文件描述符
上面使用的重定向是临时的,只对当前命令有效
echo "hello world" > log.txt echo "hello shell" # hello shell cat log.txt # hello world # 只把hello world写入到了log.txt中,也就是重定向方法,只对当前命令有效 # 如果想所有的echo命令,都写入到文件怎么办? 第一种方式就是每次echo都对他重定向, 显然太麻烦,于是乎,可以用exec,对当前shell中所有echo都重定向 exec 1>log.txt echo "hello world" # 此时,都会直接往log.txt里面写了 echo "hello shell" exec 1>&2 # 用2的文件指针内容覆盖1, 2这个是错误信息的输出指向,默认是显示屏,覆盖之后, 1就恢复成原样子,或者1>/dev/tty 这个是显示器 echo "hello C++" # 此时就输出到屏幕了 # 那么如果2里面的内容也被永久重定向怎么办? 那这种方式就无效了, 所以最好是exec重定向之前,也备份一下 exec 6>&1 # 这样可以用1>&6把1给恢复了 # 输入重定向 #!/bin/bash exec 6<&0 #先将0号文件描述符保存 exec <nums.txt #输入重定向 sum=0 while read n; do ((sum += n)) done echo "sum=$sum" exec 0<&6 6<&- #恢复输入重定向,并关闭文件描述符6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.2 代码块重定向
代码块,就是由多条语句组成的一个整体;for、while、until 循环,或者 if…else、case…in 选择结构,或者由{ }包围的命令都可以称为代码块
重定向命令放在代码块的结尾处,就可以对代码块中的所有命令实施重定向。
#!/bin/bash
sum=0
while read n; do
((sum += n))
echo "this number: $n"
done <nums.txt >log.txt # 从nums.txt里面读入n, 然后把最后的计算结果输出到log.txt
echo "sum=$sum"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.3 Here Document与字符串重定向
Shell 还有一种特殊形式的重定向叫做“Here Document”, 可以理解成文档重定向,适合想在脚本中嵌入小块数据的情况
command <<END
document # 告诉 Shell 把 document 部分作为命令需要处理的数据,直到遇见终止符END为止
END
# 这个感觉不常用, 衍生的字符串重定向有用
command <<< string
# 对于发送较短的数据到进程很方便,比如
tr a-z A-Z <<< one # ONE # 小写转成大写
# 下面这个实用的多一些, 把字符串发送到grep 或者 sed 这样的过滤程序还是很方便的
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.4 shell组命令
组命令可以将多条命令的输出结果合并在一起,在使用重定向和管道时会特别方便
{ command1; command2; command3; . . . }
# demo
{ ls -l; echo "hello world"; cat readme.txt; } > out.txt
- 1
- 2
- 3
- 4
4.5 Shell管道与过滤器
将两个或者多个命令(程序或者进程)连接到一起,把一个命令的输出作为下一个命令的输入,以这种方式连接的两个或者多个命令就形成了管道(pipe)
# | 称为管道符
command1 | command2
command1 | command2 [ | commandN... ]
command1 < input.txt | command2
command1 < input.txt | command2 -option | command3 > output.txt
# demo
tr a-z A-Z <os.txt | sort | uniq >os.txt.new
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
将几个命令通过管道符组合在一起就形成一个管道。通常,通过这种方式使用的命令就被称为过滤器。过滤器会获取输入,通过某种方式修改其内容,然后将其输出。过滤器通常与管道连用。
# 常见的过滤器
# awk 文本处理的解释性程序设计语言,通常用于数据提取,报告生成 awk -F: '{print $1}' /etc/passwd | sort
# cut 将每个输入文件(如果没有指定文件则为标准输入)的每行的指定部分输出到标准输出 grep "bin/bash" /etc/passwd | cut -d: -f1,6
# grep 用于搜索一个或多个文件中匹配指定模式的行
# tar 压缩
# head 读取文件的开头部分
# sed 过滤和转换文本的流编辑器
# sort 对文本文件排序
# split 将文件分块
# tail 显示末尾
# tee 用于从标准输入读取内容并写入到标准输出和文
# uniq 去掉重复的行
# wc 用于打印文件中的总行数、单词数或字节数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.6 Shell模块化
所谓模块化,就是把代码分散到多个文件或者文件夹, 达到代码复用的效果。 shell中,可以用source来引入其他脚本,类似于c中的include
vim func.sh function sum(){ local total=0 for n in $@ do ((total+=n)) done echo $total return 0 } vim main.sh #!/bin/bash source func.sh # 这里引入func.sh, 这里使用的相对路径, 也可以使用绝对路径 echo $(sum 10 20 55 15)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
避免重复引入的问题, C或者C++的头文件做了避免重复引入的处理,即使多次用include引入同一个文件, 最终也引入一次, 但是shell里面没有做,如果多次用source引入同一个脚本,就会执行多次, 那么,我们如何自己做重复引入避免操作处理呢?
vim module.sh
#!/bin/bash
if [ -n "$__MODULE_SH__" ]; then
return # shell中的return可以退出source命令引入的脚本, 只能退出由 source 命令引入的脚本文件,对其它引入脚本的方式无效
fi
__MODULE_SH__='module.sh'
echo "hello world"
vim main bash
#!/bin/bash
source module.sh # 下面多次引入,最终也只会引入一次
source module.sh
echo "here executed"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.7 Shell进程、信号与捕获
4.7.1 Linux中的进程小识
进程是运行在 Linux 中的程序的一个实例。执行一个程序时, 系统会为这个程序创建特定的环境,环境里面包括程序所需的所有东西。
操作系统通过被称为 PID 或进程 ID 的数字编码来追踪进程。系统中的每一个进程都有一个唯一的 PID。
sleep 10 &
ps -ef | grep sleep # 产看进程
- 1
- 2
当启动一个进程时, 有两种方式运行:
- 前台进程:默认程序运行前台, 此时不能再输入命令启动其他进程
- 后台进程: 后面加个
&就将命令启动到后台,此时会显示一个进程ID出来, 可以再继续运行其他命令
每个进程,有自己的生命周期,比如创建,执行,结束,清除等,查看指定进程的状态
ps -C processName -o pid=,cmd,stat
➜ ~ sleep 20 &
[1] 228282
➜ ~ ps -C sleep -o pid=,cmd,stat
CMD STAT
228282 sleep 20 SN
- 1
- 2
- 3
- 4
- 5
- 6
- 7
ps命令可以查看当前的进程。
ps ➜ ~ ps PID TTY TIME CMD 41574 pts/1 00:00:02 zsh 228360 pts/1 00:00:00 ps # ps 命令会显示进程 ID(PID)、与进程关联的终端(TTY)、格式为“[dd-]hh:mm:ss”的进程累积 CPU 时间(TIME),以及可执行文件的名称(CMD) # 使用标准语法显示系统中的每个进程 ps -ef # 使用 BSD 语法显示系统中的每个进程 ps -aux ➜ ~ ps -ef | head -5 UID PID PPID C STIME TTY TIME CMD root 1 0 0 12月11 ? 00:00:11 /sbin/init splash root 2 0 0 12月11 ? 00:00:00 [kthreadd] root 3 2 0 12月11 ? 00:00:00 [rcu_gp] root 4 2 0 12月11 ? 00:00:00 [rcu_par_gp] ➜ ~ ps -aux | head -5 USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 168268 9040 ? Ss 12月11 0:11 /sbin/init splash root 2 0.0 0.0 0 0 ? S 12月11 0:00 [kthreadd] root 3 0.0 0.0 0 0 ? I< 12月11 0:00 [rcu_gp] root 4 0.0 0.0 0 0 ? I< 12月11 0:00 [rcu_par_gp] # 查看某个命令下的进程信息 ps aux | grep xxx命令
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
另外还有两个命令:pstree和pgrep, 可以查看当前运行的进程, 这个这里不多整理了,没用到过。
4.7.2 子shell和子进程
shell中,有很多方式可以产生子进程,比如用新进程的方式运行shell脚本(bash, ./xxx.sh), 使用组命令,管道,命令替换等, 但有些区别。
shell脚本的执行过程:上到下,左到右, 如果shell脚本中遇到子脚本或者外部命令,就会申请一个新的进程执行,这个就是子进程,子进程执行完之后, 回到父进程。

子进程创建方式两种:
fork()函数创建一个子进程,除了PID这种参数, 子进程的一切都来自父进程,包括代码,数据,堆栈,打开的文件等。 虽然后面可能随着环境的不同,子进程和父进程会不一样,但fork()出来的那一刻,两者几乎一样。 比如组替换,命令替换,管道等,子进程可以使用父进程的一切,包括全局变量、局部变量、别名, 把这种进程称为子shell。- 子进程被
fork()出来之后,立即调用了exec()函数加载新的可执行文件,不用父进程继承来的东西。 比如bash ./test.sh、chmod +x ./test.sh; ./test.sh
举个例子吧:~/bin目录下面有两个执行文件a.out, b.out, 运行a.out产生进程A, 在A里面用fork()函数创建了一个进程B,B就是A的子进程。此时他们一样。这就是1。 但如果调用fork()后, 立即调用exec()加载b.out, 这时候, B进程中的代码,数据等会被销毁,根据b.out重新建立,此时B除了ID没变,其他都变了, 这就是2.
为了好理解, 看一段代码吧:
import os def child_process(): print("This is the child process, PID:", os.getpid()) def parent_process(): print("This is the parent process, PID:", os.getpid()) child_pid = os.fork() print("child_pid", child_pid) if child_pid == 0: # 子进程执行的代码 child_process() else: # 父进程执行的代码 print("Parent process continued...") if __name__ == "__main__": parent_process() # 输出 This is the parent process, PID: 224917 child_pid: 224956 Parent process continued... child_pid: 0 This is the child process, PID: 224956
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
这就是从父进程里面,新建立了一个子进程的过程,父进程根据返回的pid来判断当前是处在父进程还是子进程,这里感觉和shell不同的是, python里面建立出子进程之后, 父进程会接着运行, 运行完之后,子进程开始运行。
4.7.3 Linux中的信号
信号这个概念在linux中很重要,因为信号通常通过Linux命令用在一些常见活动中,比如ctrl+c,kill -9 [pid]等。
Linux中,信号被用于进程通信,是一个发送到某个进程或同一进程特定线程之间的异步通知,告知发生的一个事件。
Bash shell中, 可以用键盘发送信号:
- ctrl+c: 中断信号,发送 SIGINT 信号到运行在前台的进程
- ctrl+y: 延时挂起信号,使运行的进程在尝试从终端读取输入时停止。控制权返回给 Shell
- ctrl+z: 挂起信号,发送 SIGTSTP 信号到运行的进程,由此将其停止,并将控制权返回给 Shell
kill命令也可以发送信号, 比较有用的:
- SIGHUP (1): 终止,当进程的控制终端关闭时,HUP 信号会被发送到进程
- SIGINT (2): 当用户想要中断进程时,INT 信号被进程的控制终端发送到进程
- SIGKILL (9): 发送到进程的 KILL 信号会使进程立即终止。KILL 信号不能被捕获或忽略
- SIGCONT (18): CONT 信号指不操作系统重新开始先前被 STOP 或 TSTP 暂停的进程
- SIGSTOP (19): STOP 信号指示操作系统停止进程的执行
- 1
- 2
- 3
- 4
- 5
这里面最常用的就是杀死进程:
kill -9 xxx
# kill终结命令
kill %1
- 1
- 2
- 3
- 4
- 5
设计一个大且复杂的脚本时,考虑到当脚本运行时出现用户退出或系统关机会发生什么是很重要的。当这样的事件发生时,一个信号将会发送到所有受影响的进程。相应地,这些进程的程序可以采取一些措施以确保程序正常有序地终结。比如说,我们编写了一个会在执行时生成临时文件的脚本。在好的设计过程中,我们会让脚本在执行完成时删除这些临时文件。同样聪明的做法是,如果脚本接收到了指示程序将提前结束的信号,也应删除这些临时文件。
trap命令可以捕获特定的信号,并进行处理:
trap command signal [ signal ... ] # demo #!/bin/bash #捕获退出状态0 trap 'echo "Exit 0 signal detected..."' 0 #打印信息 echo "This script is used for testing trap command." #以状态(信号)0 退出此 Shell 脚本 exit 0 #!/bin/bash #捕获信号 SIGINT,然后打印相应信息 trap "echo 'You hit control+C! I am ignoring you.'" SIGINT # ctrl+c发的就是这个信号,这里捕获住之后,输入这样的一条提示,然后忽略 #捕获信号 SIGTERM,然后打印相应信息 trap "echo 'You tried to kill me! I am ignoring you.'" SIGTERM #循环5次 for i in {1..5}; do echo "Iteration $i of 5" #暂停5秒 sleep 5 done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
下面整理一个在实际中会使用的demo: 写一个脚本, 接收到ctrl-c行为,执行某个函数, 删除临时文件
#!/bin/bash #捕获INT和QUIT信号,如果收到这两个信号,则执行函数 my_exit 后退出 trap 'my_exit; exit' SIGINT SIGQUIT #捕获HUP信号 trap 'echo Going down on a SIGHUP - signal 1, no exiting...; exit' SIGHUP #定义count变量 count=0 #创建临时文件 tmp_file=`mktemp /tmp/file.$$.XXXXXX` #定义函数my_exit my_exit() { echo "You hit Ctrl-C/CtrI-\, now exiting..." #清除临时文件 rm -f $tmp_file >& /dev/null } #向临时文件写入信息 echo "Do someting..." > $tmp_file #执行无限while循环 while : do #休眠1秒 sleep 1 #将count变量的值加1 count=$(expr $count + 1) #打印count变量的值 echo $count done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
下面的一个效果:
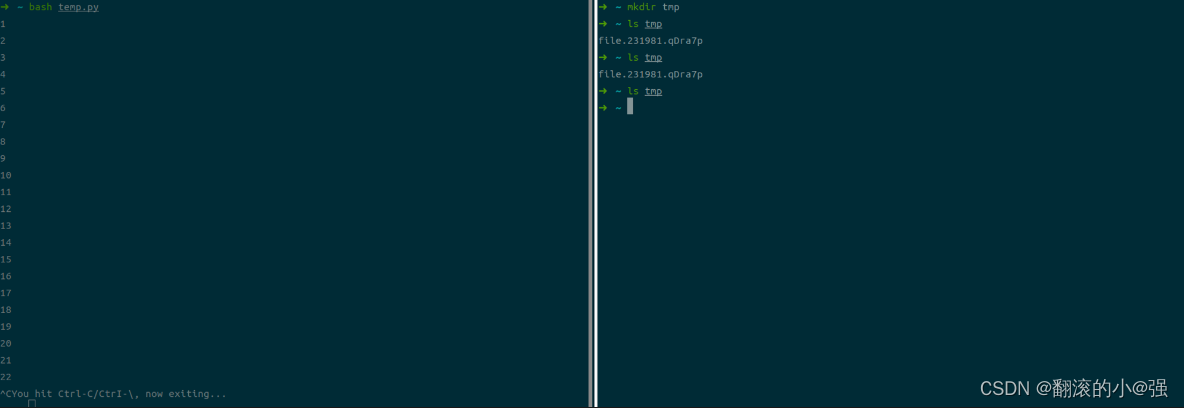
程序里面是一个无限循环,开始执行时, 在tmp目录下面会创建一个文件,里面写入了Do something, 当执行ctrl+c终止时, 退出程序,同时删掉临时文件。
Bash shell中,有两个内部变量$LINENO, $BASH_COMMAND, 可以在方便处理信号时,提供更多与脚本终结的信息。这两个命令用于报告脚本当前执行的行号以及当前运行的命令。
#!/bin/bash #捕获SIGHUP、SIGINT和SIGQUIT信号。如果收到这些信号,将执行函数my_exit后退出 trap 'my_exit $LINENO $BASH_COMMAND; exit' SIGHUP SIGINT SIGQUIT #函数my_exit my_exit() { #打印脚本名称,及信号被捕获时所运行的命令和行号 echo "$(basename $0) caught error on line : $1 command was: $2" #将信息记录到系统日志中 logger -p notice "script: $(basename $0) was terminated: line: $1, command was $2" #其他一些清埋命令 } #执行无限while循环 while : do #休眠1秒 sleep 1 #将变量count的值加1 count=$(expr $count + 1) #打印count变量的值 echo $count done # temp.py caught error on line : 1 command was: sleep
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
还可以用trap语句,忽略某些信号:
#!/bin/bash #忽略SIGINT和SIGQUIT信号 trap ' ' SIGINT SIGQUIT #打印提示信息 echo "You cannot terminate using ctrl+c or ctrl+\!" #休眠10秒 sleep 10 #重新捕获SIGINT和SIGQUIT信号。如果捕获到这两个信号,则打印信息后退出 #现在可以中断脚本了 trap 'echo Terminated!; exit' SIGINT SIGQUIT #打印提示信息 echo "OK! You can now terminate me using those keystrokes" #休眠10秒 sleep 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这个trap感觉在处理一些异常情况时会很有用。 移除信号的捕获:
$ trap - signal [ signal ... ] # 将接收到信号时的行为处理重置为默认模式 #定义函数cleanup function cleanup { #如果变量 msgfile 所指定的文件存在 if [[ -e $msgfile ]]; then #将文件重命名(或移除) mv $msgfile $msgfile.dead fi exit } #捕获INT和TERM信号 trap cleanup INT TERM #创建一个临时文件 msgfile=`mktemp /tmp/testtrap.$$.XXXXXX` #通过命令行向此临时文件中写入内容 cat > $msgfile #接下来,发送临时文件的内容到指定的邮件地址,你自己完善此部分代码 #send the contents of $msgfile to the specified mail address... #删除临时文件 rm $msgfile #移除信号INT和TERM的捕获 trap - INT TERM
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
5. Shell的一些快捷操作
shell的一些常用快捷键:
# 光标移动系列
ctrl+a: 行首
ctrl+e: 行尾
ctrl+f: 往前移动光标, 类似->, ctrl+b: 后移动光标, 类似<-
alt+f: 后移动一个单词, alt+b: 前移动一个单词
ctrl+l: 清空屏幕
# 剪切和粘贴文本
ctrl+k: 剪切光标位置到行尾, 删除到行尾
ctrl+u: 剪切光标位置到行首, 删除到行首
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
自动补全:
tab键
一次tab键: 自动补全
两次tag键: 看看有哪些可以补全的列表
- 1
- 2
- 3
- 4
- 5
搜索历史命令:
history | less
history | grep xxx命令
ctrl+r 可以对历史命令搜索, 接连ctrl+r往上找
找到之后, ctrl+j可以复制到当前,或者直接enter
- 1
- 2
- 3
- 4
- 5
脚本的鲁棒和调试命令:
#!/bin/bash
set -eux
# shell脚本的开头可以加这样一行命令, 设置脚本行为
-e 脚本中如何任何命令返回非零的退出状态(失败), 脚本立即停止运行
-u 脚本中使用了未定义的变量,将会产生错误,脚本停止执行
-x 执行脚本时,会输出执行的每一行命令及其参数,有助于调试和追踪脚本的执行流程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6. 小总
本篇文章有点长, 主要是以整理常用的shell脚本命令为主, 命令有点多, 整理了两遍算是有些初步印象, 对shell脚本的知识通过一个架子可以拎起来了, 后面需要不断的在实践中多写多练才能融会贯通。 在工作中, 我发现Shell还真实蛮常用的, 特别适合一些重复性的,逻辑简单的一些工作辅助,比如同步迁移数据,重复性文件读写,同步修改一些文件,写一些定时任务等, 在shell里面还可以执行py文件, 把python和shell结合起来, 我发现可以大幅提高工作效率,所以掌握一些基本的shell脚本的语法还是蛮必要的,加油
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

