
- 1【华为OD机试考生抽中题 C&D卷】孙悟空吃蟠桃,用 Python 编码,速通_华为机考爱吃蟠桃的孙悟空
- 2Docker部署PostgreSQL数据库_docker下如何部署postgresql
- 3【全网首发】Linux系统最全笔记(建议收藏)_linux笔记
- 4牛客周赛 Round 39题解
- 5UE5 利用Project Launcher快速打包_ue5打包项目
- 6Linux进程控制实验_使用fork函数创建两个子进程,其中一个子进程运行“ls-l”指令,另一个子进程在暂停
- 73分钟部署完成Docker Registry及可视化管理工具Docker-UI_docker-registry-ui
- 8数据结构学习--第2章_数据结构第二章
- 9基于FPGA的FFT算法实现_用xilinx的fpga实现fft变换
- 10图文并茂解释TCP/IP原理_tcpip原理
用于文本去重(相似度计算)的Simhash算法学习及python实现(持续学习中)_simhash算法实例
赞
踩
来源于众多文章的学习,将在文章末尾,集中附录出所有学习的文章
1. Simhash算法是什么?
一段文字所包含的信息,就是它的信息熵。如果对这段信息进行无损压缩编码,理论上编码后的最短长度就是它的信息熵大小。
如果仅仅是用来做区分,则远不需要那么长的编码,任何一段信息(文字、语音、视频、图片等),都可以被映射(Hash编码)为一个不太长的随机数,作为区别这段信息和其他信息的指纹,只要Hash算法设计得好,任何两段信息的指纹都很难重复。
SimHash算法是Google在2007年发表的论文《Detecting Near-Duplicates for Web Crawling》中提到的一种指纹生成算法,被应用在Google搜索引擎网页去重的工作之中。
简单的说,SimHash算法主要的工作就是将文本进行降维,生成一个SimHash值,也就是论文中所提及的“指纹”,通过对不同文本的SimHash值进而比较海明距离,从而判断两个文本的相似度。
对于文本去重这个问题,常见的解决办法有余弦算法、欧式距离、Jaccard相似度、最长公共子串等方法。但是这些方法并不能对海量数据高效的处理。
比如说,在搜索引擎中,会有很多相似的关键词,用户所需要获取的内容是相似的,但是搜索的关键词却是不同的,如“北京好吃的火锅“和”哪家北京的火锅好吃“,是两个可以等价的关键词,然而通过普通的hash计算,会产生两个相差甚远的hash串。而通过SimHash计算得到的Hash串会非常的相近,从而可以判断两个文本的相似程度。
下面是查看simhash值的实例
from simhash import Simhash def get_Features(s): ''' 设置一个长度为3的滑动窗口,并只匹配数字英文加下划线,如输入'你好啊,今天真高兴': 返回['你好啊', '好啊今', '啊今天', '今天真', '天真高', '真高兴'] ''' width = 3 s = s.lower()#字符小写处理 s = re.sub(r'[^\w]+','',s)#删除非下划线或单词的字符 return [s[i:i + width] for i in range(max(len(s) -width + 1,1))] print(get_Features('How are you? I am fine. Thanks.')) ''' ['how', 'owa', 'war', 'are', 'rey', 'eyo', 'you', 'oui', 'uia', 'iam', 'amf', 'mfi', 'fin', 'ine', 'net', 'eth', 'tha', 'han', 'ank', 'nks'] ''' print('%x' % Simhash(get_Features('How are you? I am fine. Thanks.')).value) print('%x' % Simhash(get_Features('How are you? I am fine. Thanks.')).value) print('%x' % Simhash(get_Features('How r you? I am fine. Thanks.')).value) ''' \w :匹配包括下划线的任何单词字符,等价于 [A-Z a-z 0-9_] \W :匹配任何非单词字符,等价于 [^A-Z a-z 0-9_] %x :16进制打印 ''' ''' E:\JP\LearnCoding\simhash_learn>python search_simhash.py 4d4da690b5a57e47 4d4da690b5a57e47 由于进行了正则替换掉所有非单词下划线的字符,所以,字符串空格的存在导致的不同不会影响最终结果 文字的顺序会影响结果 4f08a4f4b5a13a4b '''

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
2.Simhash算法思想
假设我们有海量的文本数据,我们需要根据文本内容将它们进行去重。对于文本去重而言,目前有很多NLP相关的算法可以在很高精度上来解决,但是我们现在处理的是大数据维度上的文本去重,这就对算法的效率有着很高的要求。
而局部敏感hash算法可以将原始的文本内容映射为数字(hash签名),而且较为相近的文本内容对应的hash签名也比较相近。SimHash算法是Google公司进行海量网页去重的高效算法,它通过将原始的文本映射为64位的二进制数字串,然后通过比较二进制数字串的差异进而来表示原始文本内容的差异。
simhash属于局部敏感型(locality sensitive hash)的一种,主要思想是降维,将高维的特征向量映射成一个f-bit的指纹(fingerprint),通过比较两篇文章的f-bit指纹的Hamming Distance来确定文章是否重复或者高度近似,海明距离越小,相似度越低(根据 Detecting Near-Duplicates for Web Crawling 论文中所说),一般海明距离为3就代表两篇文章相同。。为了陈述方便,假设输入的是一个文档的特征集合,每个特征有一定的权重。比如特征可以是文档中的词,其权重可以是这个词出现的次数。
3.Simhash算法流程
分词→hash→加权→合并→降维
3.1 分词
3.1.1 短文本的处理
直接分词,对所有词语进行计算
把需要判断的文本,分词形成这个文章的特征单词。
- 分词的工具的选择可以由使用者决定,一般可以选用python结巴工具包
def get_cibiao(Inp,Outp):
'''
获得文件的所有不重复的词,存入新的文件
'''
f=open(Inp,encoding="utf-8",errors="ignore")
o=open(Outp,"w")
for line in f:
line=line.strip()
ciyu=jieba.cut(line,cut_all=False)
……省略使用部分的代码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.1.2 长文本的处理-基于TF-IDF的文本关键词抽取方法
该部分主要参考中文文本关键词抽取的三种方法-python和TF-IDF算法介绍及实现
使用每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
像这种算法的实现,如果单纯只是使用,此部分可以省略,毕竟现在这种计算过程好像都已经封装(大概是叫这个吧)在simhash库里了
3.1.2.1 TF-IDF算法思想
- 词频(Term Frequency,TF)
指某一给定词语在当前文件中出现的频率。由于同一个词语在长文件中可能比短文件有更高的词频,因此根据文件的长度,需要对给定词语进行归一化,即用给定词语的次数除以当前文件的总词数。

- 逆向文件频率(Inverse Document Frequency,IDF)
是一个词语普遍重要性的度量。即如果一个词语只在很少的文件中出现,表示更能代表文件的主旨,它的权重也就越大;如果一个词在大量文件中都出现,表示不清楚代表什么内容,它的权重就应该小。可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。

- TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)
是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
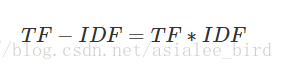
- TF-IDF的主要思想是
如果某个词语在一篇文章中出现的频率高,并且在其他文章中较少出现,则认为该词语能较好的代表当前文章的含义。即一个词语的重要性与它在文档中出现的次数成正比,与它在语料库中文档出现的频率成反比。

3.1.2.2 TF-IDF文本关键词抽取方法流程
由以上可知,TF-IDF是对文本所有候选关键词进行加权处理,根据权值对关键词进行排序。假设Dn为测试语料的大小,该算法的关键词抽取步骤如下所示:
(1) 对于给定的文本D进行分词、词性标注和去除停用词等数据预处理操作。本分采用结巴分词,保留’n’,‘nz’,‘v’,‘vd’,‘vn’,‘l’,‘a’,'d’这几个词性的词语,最终得到n个候选关键词,即D=[t1,t2,…,tn] ;
- 【这里保留词性是原文的操作,我们应该选择适合自己的,待修改】
(2) 计算词语ti 在文本D中的词频;
(3) 计算词语ti 在整个语料的IDF=log (Dn /(Dt +1)),Dt 为语料库中词语ti 出现的文档个数;
(4) 计算得到词语ti 的TF-IDF=TF*IDF,并重复(2)—(4)得到所有候选关键词的TF-IDF数值;
(5) 对候选关键词计算结果进行倒序排列,得到排名前TopN个词汇作为文本关键词。
3.1.2.3 代码实现(待修改/实现)
Python第三方工具包Scikit-learn提供了TFIDF算法的相关函数,本文主要用到了sklearn.feature_extraction.text下的TfidfTransformer和CountVectorizer函数。其中,CountVectorizer函数用来构建语料库的中的词频矩阵,TfidfTransformer函数用来计算词语的tfidf权值。
注:TfidfTransformer()函数有一个参数smooth_idf,默认值是True,若设置为False,则IDF的计算公式为idf=log(Dn /Dt ) + 1。
基于TF-IDF方法实现文本关键词抽取的代码执行步骤如下:
(1)读取样本源文件sample_data.csv;
(2)获取每行记录的标题和摘要字段,并拼接这两个字段;
(3)加载自定义停用词表stopWord.txt,并对拼接的文本进行数据预处理操作,包括分词、筛选出符合词性的词语、去停用词,用空格分隔拼接成文本;
(4)遍历文本记录,将预处理完成的文本放入文档集corpus中;
(5)使用CountVectorizer()函数得到词频矩阵,a[j][i]表示第j个词在第i篇文档中的词频;
(6)使用TfidfTransformer()函数计算每个词的tf-idf权值;
(7)得到词袋模型中的关键词以及对应的tf-idf矩阵;
(8)遍历tf-idf矩阵,打印每篇文档的词汇以及对应的权重;
(9)对每篇文档,按照词语权重值降序排列,选取排名前topN个词最为文本关键词,并写入数据框中;
(10)将最终结果写入文件keys_TFIDF.csv中。
- 结巴简易版代码
看了好多大佬的代码,还是这种简单的适合我,不求甚解,拿来就用
Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license()" for more information. >>> import jieba.analyse >>> corpus ='逆向文件频率(Inverse Document Frequency,IDF)是一个词语普遍重要性的度量。即如果一个词语只在很少的文件中出现,表示更能代表文件的主旨,它的权重也就越大;如果一个词在大量文件中都出现,表示不清楚代表什么内容,它的权重就应该小。' >>> keywords_textrank = jieba.analyse.textrank(corpus) Building prefix dict from the default dictionary ... Dumping model to file cache C:…………………………………………………………(此处是文件地址) Loading model cost 0.704 seconds. Prefix dict has been built successfully. >>> print(keywords_textrank) ['文件', '表示', '代表', '出现', '权重', '重要性', '词语', '度量', '主旨', '内容', '频率', '逆向', '应该', '大量文件'] >>> keywords_tfidf = jieba.analyse.extract_tags(corpus) >>> print(keywords_tfidf) ['文件', '词语', '权重', '大量文件', 'Inverse', 'Document', 'Frequency', 'IDF', '代表', '逆向', '主旨', '度量', '更能', '一个', '如果', '表示', '出现', '重要性', '频率', '很少'] >>> jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=()) >>>sentence 为待提取的文本 >>>topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20 >>>withWeight 为是否一并返回关键词权重值,默认值为 False >>>allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.2 hash
通过hash算法(可以参考Hash算法总结)把每个词变成hash值.
比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。
这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
- 为什么文章变为数字计算才能提高相似度计算性能?
学姐说:任何数据在计算机里存储的都是数字,更准确的说是二进制数值,计算机界有一句话叫“万物源于比特”
3.3 加权
通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,
W=hash*weight
具体的计算过程如下:hash二进制串中为1的乘以该特征词的分词权重,二进制串中为0的乘以该特征词的分词权重后取负,继而得到权重向量。
比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
- (权重的依据是什么?频次?)
文本内容中每个term对应的权重如何确定要根据实际的项目需求,一般是可以使用IDF权重来进行计算。
我们假设权重分为5个级别(1~5)。比如:
“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ”
==> 分词后为
“ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,
括号里是代表单词在整个句子里重要程度,数字越大越重要。
3.4 合并
把上面各个单词算出来的序列值累加,变成只有一个序列串。
比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4±5 -4+5 4±5 -4+5 4+5”
==》 “9 -9 1 -1 1 9”。
这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
3.5降维
把4步算出来的 “9 -9 1 -1 1 9” ,大于0的位置1,小于等于0的位置0,就可以得到该文本的SimHash值,变成 0 1 串,形成我们最终的simhash签名。
如果每一位大于0 记为 1,小于0 记为 0。
最后算出结果为:“1 0 1 0 1 1”。
整个过程的流程图原作者给出以下图示:

4. SimHash签名距离计算
我们把库里的文本都转换为simhash签名,并转换为long类型存储,空间大大减少。
现在我们虽然解决了空间,但是如何计算两个simhash的相似度呢?难道是比较两个simhash的01有多少个不同吗?
对的,其实也就是这样,我们通过海明距离就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。举例如下:
10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。
对于二进制字符串的a和b,海明距离为等于在a XOR b异或运算结果中1的个数(普遍算法)。
计算两个simhash值距离
from simhash import Simhash
hash1 = Simhash(u'i am very happy'.split())
hash2 = Simhash(u'i am very sad'.split())
print('hash1',hash1)
print('hash2',hash2)
print('hash1.distance(hash2):',hash1.distance(hash2))
--结果
hash1 <simhash.Simhash object at 0x0000012E64607710>
hash2 <simhash.Simhash object at 0x0000012E646077F0>
hash1.distance(hash2): 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.1 什么是海明距离呢?
简单的说,海明距离(Hamming distance)可以理解为,两个二进制串之间相同位置不同的个数。
举个例子,[1,1,1,0,0,0]和[1,1,1,1,1,1]的海明距离就是3。
在处理大规模数据的时候,我们一般使用64位的SimHash,正好可以被一个long型存储。这种时候,海明距离在3以内就可以认为两个文本是相似的。
4.2 大规模数据下的海明距离计算
在大规模数据量的情况下,如果对两个文本64位的SimHash的海明距离采用每一位比较的方法进行计算,找出海明距离小于等于3的文本,这样会耗费大量时间和资源。
这时候有一种较好的办法来均衡计算海明距离的时间复杂度和空间复杂度,具体的计算思想是这样的:
把64位的SimHash分成四个part,如果两个SimHash相似(海明距离小于等于3),根据鸽巢原理(一般指抽屉原理(数学原理)),必然有一个part是完全相同的。
这样,我们通过比较part,快速的得出两个文本是否相似。【可以这样简化来理解,四个部分,不同的部分数量小于三,也就是肯定有一个是和另外的一个是完全相同的】
此部分参考[Algorithm] 使用SimHash进行海量文本去重
存储:
1、将一个64位的simhash签名拆分成4个16位的二进制码。(图上红色的16位)
2、分别拿着4个16位二进制码查找当前对应位置上是否有元素。(放大后的16位)
3、对应位置没有元素,直接追加到链表上;对应位置有则直接追加到链表尾端。(图上的 S1 — SN)
查找:
1、将需要比较的simhash签名拆分成4个16位的二进制码。
2、分别拿着4个16位二进制码每一个去查找simhash集合对应位置上是否有元素。
3、如果有元素,则把链表拿出来顺序查找比较,直到simhash小于一定大小的值,整个过程完成。
原理:
借鉴hashmap算法找出可以hash的key值,因为我们使用的simhash是局部敏感哈希,这个算法的特点是只要相似的字符串只有个别的位数是有差别变化。那这样我们可以推断两个相似的文本,至少有16位的simhash是一样的。具体选择16位、8位、4位,大家根据自己的数据测试选择,虽然比较的位数越小越精准,但是空间会变大。分为4个16位段的存储空间是单独simhash存储空间的4倍。之前算出5000w数据是 382 Mb,扩大4倍1.5G左右,还可以接受
5.大规模文本的去重
这部分的内容,主要参考文章《海量短文本场景下的去重算法》。
这里的大规模文本,表现在需要去重的场景中,可能是两种情况:
- 第一,就是大量的文档之间的相似度比对;
- 第二,就是单个的大文档的去重。
文本的去重,作为小白的我,第一的想法就是两两比对,看似是非常简单直接,但是面临了一个非常重要的问题:时间。我们在去重的时候究竟可以承担多少时间成本。
通过对python simhash库的调用,我们可以轻易的实现文本simhash值的计算,进行不同文本间的两两比对,如下:
import jieba.analyse
from simhash import Simhash
#通过对上述两个库的引用,我们就已经可以完成文本的两两比对了。
……(过程省略)
with open(Outp,'a', encoding='gbk') as o:
hash1 = Simhash(line1.split())
hash2 = Simhash(line2.split())
print('f1:{} 与 f2:{}的海明距离是:{}'.format(fr1[66:],fr2[66:],str(hash1.distance(hash2))),file=o)
if hash1.distance(hash2) <= 3:
print('文本相似')
else:
print('文本不相似')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
如果仅仅是少数文档,通过这样的一个过程来处理,非常快速,至少在我的需要里,这种处理后时间的长短,并没有什么影响。但是,当我们将文档的数量放大,比如2698个文件的两两比对,那意味着计算机要比对3638253次,也就是300多万次。小小的笔记本承担了他这体积本不该有的重担。呼哧呼哧的运转了将近5个小时。
所以摆在我们面前的就是:如何去重==》如何高效的去重==》如何高效的对比文件
文章的作者提到,高效的去重,降低时间复杂度的关键: 就在于尽力将潜在的相似文本聚合到一块,从而大大缩小需要比较的范围。
也就是减少计算机的工作量,让它少干点活。
5.1 抽风的第一次测试
在看完大佬的文章的第一段以后,我突发奇想:
- 对于一个大文本的文件,如果,其本身是具有某种篇章格式的。也许,可以按行读取,然后每一个标记的篇章成为一个小的块,将其放入字典,以其出现的顺序作为ID,构成K:V,然后使用simhash的SimhashIndex(),对每一个新的篇章,计算hash后检索一次,从而根据检索结果的有无生成新的文件,即:
设置一个篇章可能具有的行数
按行读取文件
将每行的内容添加到列表
如果目前列表的元素数大于行数,并且新的一行的具有篇章的初始标记:
获得一个完整的篇章内容
取得其Simhsah值
将列表存入字典
建立索引
如果列表的simhash值未找到相似,说明是不重复文本
如果有相似,说明是重复文本。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
直到我开始写这一段的时候,程序不出意料的还是没有运行完。因为我根本就没有在减小运行时间上下功夫,倒是终于学会了朴素的单文本的去重方法,虽然仍是是基于两两对比的思路进行比较,但是,我感觉这个可能就是当我们试图合法的爬取网页内容时,如果不会别的方法的话,这个可能帮我进行爬取网页的去重。
可能沙雕了,我应该用一个不算辣么大的且肯定有重复的文件测试的,运行到一半又不想关了,得等明天的结果了
虽然尚未运行结束,但是我判定这个思路是有效的但是我的代码有问题。因为simhash是局部敏感的,从前文的测试我们可以发现,很小的 改变,都会带来海明距离的变化。我试图比较的文本,其重复的篇章,也是有标题上的不一致,所以可能需要改变哪些东西。
- 是不再比较标题,还是放宽海明距离的限制,亦或是不再全文进行比较而是使用关键词?
参考文章
1.作者:Poll的笔记,https://www.cnblogs.com/maybe2030/p/5203186.html#_label4
2.Hash算法总结https://blog.csdn.net/asdzheng/article/details/70226007
3.SimHash算法原理https://blog.csdn.net/Daverain/article/details/80919418
4.simhash的背景、原理、计算、使用、存储
https://blog.csdn.net/m0_37442062/article/details/98849293
5.中文文本关键词抽取的三种方法-python
https://blog.csdn.net/weixin_36226326/article/details/107525464
6.python 实现关键词提取https://blog.csdn.net/hangzuxi8764/article/details/86901822
7.TF-IDF算法介绍及实现https://blog.csdn.net/asialee_bird/article/details/81486700
8.利用simhash来进行文本去重复https://blog.csdn.net/fuyangchang/article/details/5639595
9.使用SimHash算法实现千万级文本数据去重插入(python版代码)https://blog.csdn.net/sinat_33455447/article/details/88956583
10.海量短文本场景下的去重算法https://mp.weixin.qq.com/s?__biz=MzUzNTc0NTcyMw==&mid=2247484140&idx=1&sn=20eabd51d5634e58e3b0fab1768c29ba&scene=19#wechat_redirect


