
- 1历史最全自然语言处理测评基准分享-数据集、基准(预训练)模型、语料库、排行榜_boolq(布尔问题)是一个用于自然语言处理任务的数据集和评估指标
- 2使用Diamond比对NR数据库获取物种注释_diamond nr
- 32021年网络计算机统考试题,网络教育《计算机应用基础》统考题库-2021年6月最新题库.doc...
- 4【C++ unordered_map】leetcode常用的哈希表操作_unordered_map
- 5Go语言中忘记字符串格式化可能产生的副作用
- 6Tablayout自定义+viewpage2_tablayout+viewpager2
- 7[C++] 内存布局完整解读
- 8移动应用开发之路 05 Android Studio 简单登录界面制作_android studio做一个登录页面
- 9[软考]软件设计师的认知_软考中项的软件设计师
- 10XLnet和tranformer-XL的双流注意力机制_the model xlnet is one of the few models that has
【2022秋招面经】——NLP_nlp面经
赞
踩
文章目录
- Word2Vec
- 基本原理
- 问题
- word2vec的优化,包括层级softmax的复杂度
- word2vector负采样时为什么要对频率做3/4次方?
- 对于其中的窗口选择策略?窗口选择5,10,15都有什么区别吗?是不是越大越好呢?
- word2vector 如何做负采样?是在全局采样?还是在batch采样?如何实现多batch采样?
- 怎么确保采样不会采到正样本?
- W2V经过霍夫曼或者负采样之后,模型与原模型相比,是等价的还是相似的?
- 问题1:介绍一下word2vec?
- 问题2:对比 Skip-gram 和 CBOW
- 问题3:对比 HS 和 负采样
- 问题 4:负采样为什么要用词频来做采样概率?
- 问题 5:为什么训练完有两套词向量,为什么一般只用前一套?
- 问题 6:对比字向量和词向量
- 问题 7:为什么负采样/分层softmax能加快训练
- 问题8:word2vec的缺点
- 问题9:hs为什么用霍夫曼树而不用其他二叉树?
- 问题10:为什么用的是线性激活函数?
- LSTM
- NLP 中常用的数据增强方法?
Word2Vec
基本原理
1. CBOW(Continuous Bag-of-Words) 连续词袋模型
CBOW 简单来说,就是通过上下文,来预测中间的词。
假设我们上下文大小取 4 ,特定的这个词是“learning”,如下所示:
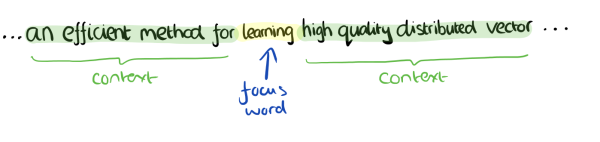
CBOW 使用的是词袋模型,因此输入的八个词都是平等的,也就是不考虑输入词和目标词之间的位置,只要在我们上下文之内即可。
如果后续不加优化的话,对目标位置的预测结果是已知所有词的概率
2. skip-gram 跳字模型
skip-gram 简单来说就是通过一个词,来预测上下文。
输入是一个词,不加优化的话,输出上下文词的概率
skip-gram 和 CBOW 是一种互补的关系,训练的时候二选一即可。
关系如下:
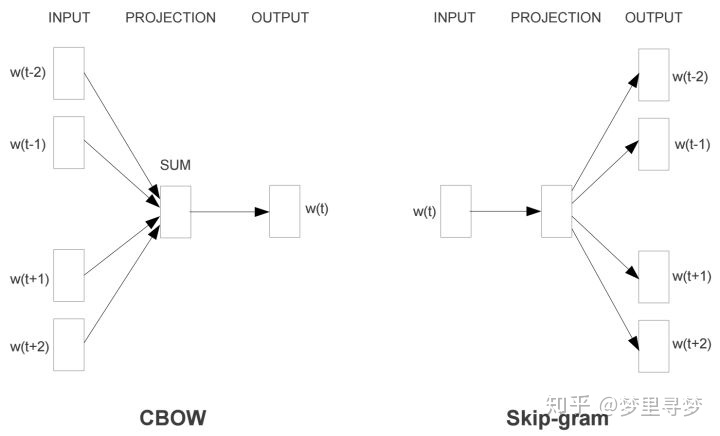
缺点:
上面两种方法在用 softmax 计算概率的时候,因为要对每一个词的概率进行预测,假如词库里面一共有几万个词,计算量很大,非常耗时,所以需要进行优化。
3. Hierachical softmax(层级 softmax)
传统的神经语言模型一般有三层,输入层(词向量),隐藏层和输出层(softmax),结构如下图所示。里面最大的问题在于隐藏层到输出层的softmax层的计算量很大。
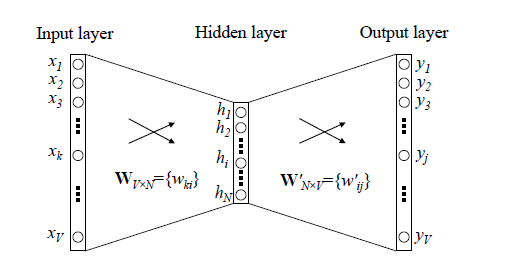
word2vec对传统的神经语言模型做了改进,首先,对于从输入层到隐藏层的映射,没有采取神经网络的线性变换加激活函数的方法,而是采用简单的对所有输入词向量求和并取平均的方法。比如输入的是三个4维词向量:(1,2,3,4),(9,6,11,8),(5,10,7,12)(1,2,3,4),(9,6,11,8),(5,10,7,12),那么我们word2vec映射后的词向量就是(5,6,7,8)(5,6,7,8)。由于这里是从多个词向量变成了一个词向量。
第二个改进就是从隐藏层到输出的softmax层这里的计算量个改进。为了避免要计算所有词的softmax概率,word2vec采样了霍夫曼树来代替从隐藏层到输出softmax层的映射。
由于我们把之前所有都要计算的从输出softmax层的概率计算变成了一颗二叉霍夫曼树,那么我们的softmax概率计算只需要沿着树形结构进行就可以了。如下图所示,我们可以沿着霍夫曼树从根节点一直走到我们的叶子节点的词 w 2 w_2 w2
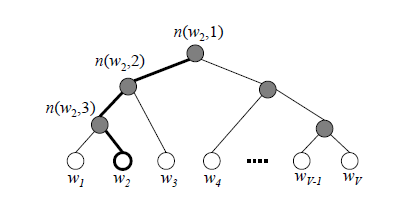
霍夫曼树的内部节点类似之前神经网络隐藏层的神经元
根节点是输入词向量取平均
叶子节点类似于softmax输出层的神经元
叶子节点的个数就是词汇表的大小
判别正类和负类的方法是使用sigmoid函数,即:
p
(
+
)
=
σ
(
x
w
T
θ
)
=
1
1
+
e
−
x
w
T
θ
p(+)=\sigma (x_{w}^{T}\theta )=\frac{1}{1+{{e}^{-x_{w}^{T}\theta }}}
p(+)=σ(xwTθ)=1+e−xwTθ1
参考链接:word2vec原理(二) 基于Hierarchical Softmax的模型
4. negative sampling(负采样)
如果我们的训练样本里的中心词 w 是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久。
训练方法
用二元逻辑回归的方法求出对应的对数似然函数 L。
用随机梯度上升法,每次只用一个样本更新梯度,来进行迭代更新我们需要的参数 x w , θ w x_w, θ^w xw,θw。(对L求导)
负采样方法
负采样训练是一种解决多类别和稀疏目标的通用方法。word2vec 训练时,更新窗口内的positive word 和 非窗口内negative words 对应的参数。如果不使用负采样, negative words 则为词典中,其他非窗口内所有的词,这个范围很大,训练非常耗时。而负采样方法 对 negative words进行随机抽样,降低 negative words 量级。
负采样中某个固定的正样本对应 k k k 个负样本,即模型总共包含了 k + 1 k + 1 k+1 个binary classification。对比之前10000个输出单元的softmax分类,negative sampling转化为个二分类问题,每次迭代并不是训练10000个,而仅训练其中 k + 1 k + 1 k+1 个,计算量要小很多,大大提高了模型运算速度。
这种方法就叫做负采样(Negative Sampling): 选择一个正样本,随机采样 k k k个负样本、
选取了context之后,如何选取负样本:
- 通过单词出现的频率进行采样:导致一些类似 a、the、of等词的频率较高
- 均匀随机地抽取负样本:没有很好的代表性
论文中采用:
p
(
w
i
)
=
f
(
w
i
)
3
4
∑
j
=
1
n
f
(
w
j
)
3
4
p({{w}_{i}})=\frac{f{{({{w}_{i}})}^{\frac{3}{4}}}}{\sum\limits_{j=1}^{n}{f{{({{w}_{j}})}^{\frac{3}{4}}}}}
p(wi)=j=1∑nf(wj)43f(wi)43
这种方法处于上面两种极端采样方法之间,即不用频率分布,也不用均匀分布,而采用的是对词频的 3 4 \frac{3}{4} 43除以整体词频的 3 4 \frac{3}{4} 43进行采样。其中 f ( w j ) f(w_j) f(wj) 是语料库中观察到的某个词的词频。
参考链接:博客园刘建平Pinard word2vec原理(三) 基于Negative Sampling的模型
问题
word2vec的优化,包括层级softmax的复杂度
Hierachical softmax 的复杂度从原来的 x 变为 logx
word2vector负采样时为什么要对频率做3/4次方?
论文作者提到出于经验,效果好。
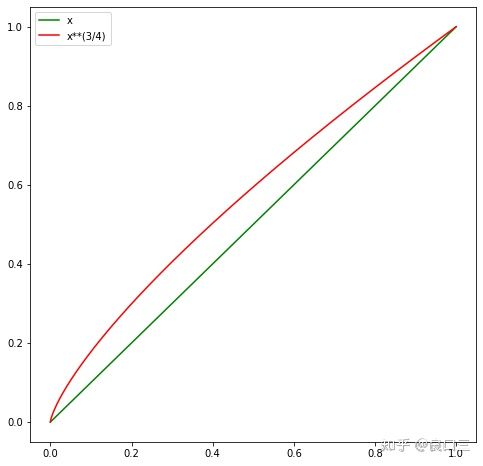
可以看到,在0~1区间, x 3 / 4 x^{3/4} x3/4 输出是大于 x。而且对于越小的值,这种增益越大。
从抽样的角度来看,通过对权重开 3/4 次幂,可以提升低频词被抽到的概率。
可以认为:在保证高频词容易被抽到的大方向下,通过权重3/4次幂的方式,适当提升低频词、罕见词被抽到的概率。如果不这么做,低频词,罕见词很难被抽到,以至于不被更新到对应的Embedding。
参考链接:为什么Word2Vec训练中, 需要对负采样权重开3/4次幂?
对于其中的窗口选择策略?窗口选择5,10,15都有什么区别吗?是不是越大越好呢?
word2vector 如何做负采样?是在全局采样?还是在batch采样?如何实现多batch采样?
怎么确保采样不会采到正样本?
W2V经过霍夫曼或者负采样之后,模型与原模型相比,是等价的还是相似的?
下面十个问题参考链接:
word2vec问题(不涉及原理细节)
问题1:介绍一下word2vec?
(1) 两个模型是 CBOW 和 Skip-gram,两个加快训练的技巧是 HS(Hierarchical Softmax )和负采样。
(2) 假设一个训练样本是由核心词 w 和其上下文 context(w) 组成,CBOW 就是用 context(w) 去预测 w;而 Skip-gram 则反过来,是用 w 去预测 context(w) 里的所有词。
(3) HS 是试图用词频建立一棵哈夫曼树,那么经常出现的词路径会比较短。树的叶子节点表示词,共词典大小多个,而非叶子结点是模型的参数,比词典个数少一个。要预测的词,转化成预测从根节点到该词所在叶子节点的路径,是多个二分类问题。// 不太明白??
(4 ) 对于负采样,则是把原来的 Softmax 多分类问题,直接转化成一个正例和多个负例的二分类问题。让正例预测 1,负例预测 0,这样子更新局部的参数。
问题2:对比 Skip-gram 和 CBOW
(1) 训练速度上 CBOW 应该会更快一点。
因为每次会更新 context(w) 的词向量,而 Skip-gram 只更新核心词的词向量。
两者的预测时间复杂度分别是 O(V),O(KV)
(2) Skip-gram 对低频词效果比 CBOW好。
因为是尝试用当前词去预测上下文,当前词是低频词还是高频词没有区别。但是 CBOW 相当于是完形填空,会选择最常见或者说概率最大的词来补全,因此不太会选择低频词。(想想老师学生的那个例子)
Skip-gram 在大一点的数据集可以提取更多的信息。总体比 CBOW 要好一些。
问题3:对比 HS 和 负采样
(1)优化目标:
①HS让每个非叶子节点去预测要选择的路径(每个节点是个二分类问题),目标函数是最大化路径上的二分类概率。
p
(
w
∣
c
o
n
t
e
x
t
(
w
)
)
=
∐
j
=
2
l
(
w
)
p
(
d
j
w
∣
x
w
,
θ
j
−
1
w
)
p(w|context(w))=\coprod\limits_{j=2}^{l(w)}{p(d_{j}^{w}|{{x}_{w}},\theta _{j-1}^{w})}
p(w∣context(w))=j=2∐l(w)p(djw∣xw,θj−1w)
p
(
d
j
w
∣
x
w
,
θ
j
−
1
w
)
=
[
σ
(
x
w
T
θ
j
−
1
w
)
]
1
−
d
j
w
⋅
[
1-
σ
(
x
w
T
θ
j
−
1
w
)
]
d
j
w
p(d_{j}^{w}|{{x}_{w}},\theta _{j-1}^{w})={{[\sigma (x_{w}^{T}\theta _{j-1}^{w})]}^{1-d_{j}^{w}}}\text{ }\!\!\cdot\!\!\text{ }\!\![\!\!\text{ 1-}\sigma (x_{w}^{T}\theta _{j-1}^{w}){{\text{ }\!\!]\!\!\text{ }}^{d_{j}^{w}}}
p(djw∣xw,θj−1w)=[σ(xwTθj−1w)]1−djw ⋅ [ 1-σ(xwTθj−1w) ] djw
②负采样是最大化正样例概率同时最小化负样例概率。
g
(
w
)
=
σ
(
x
w
T
θ
w
)
∏
u
∈
N
E
G
(
w
)
[
1
−
σ
(
x
w
T
θ
u
)
]
g(w)=\sigma (x_{w}^{T}{{\theta }^{w}})\prod\limits_{u\in NEG(w)}{[1-\sigma }(x_{w}^{T}{{\theta }^{u}})]
g(w)=σ(xwTθw)u∈NEG(w)∏[1−σ(xwTθu)]
(2)负采样更快一些,特别是词表很大的时候。与HS相比,负采样不再使用霍夫曼树,而是使用随机负采样,能大幅度提高性能。
问题 4:负采样为什么要用词频来做采样概率?
因为这样可以让频率高的词先学习,然后带动其他词的学习。
问题 5:为什么训练完有两套词向量,为什么一般只用前一套?
(1) 对于 Hierarchical Softmax 来说,哈夫曼树中的参数是不能拿来做词向量的,因为没办法和词典里的词对应。
(2) 负采样中的参数其实可以考虑做词向量,因为中间是和前一套词向量做内积,应该也是有意义的。但是考虑负样本采样是根据词频来的,可能有些词会采不到,也就学的不好。
问题 6:对比字向量和词向量
(1) 字向量其实可以解决一些问题,比如未登陆词,还有做一些任务的时候还可以避免分词带来的误差。
(2) 词向量它的语义空间更大,更加丰富,语料足够的情况下,词向量是能够学到更多的语义的。
问题 7:为什么负采样/分层softmax能加快训练
(1) 负采样 1在优化参数的时候,只更新涉及到的向量参数;2 放弃用softmax而是用sigmoid,原来的方法中softmax需要遍历所有单词的概率得分。
(2) 分层softmax:上面的 Softmax 每次和全部的词向量做内积,复杂度是 O(V),V 是词典大小。如果考虑把每个词都放到哈夫曼树的叶节点上,用sigmoid做二分类,那么复杂度就可以降为 O(logV),即树的高度,因为只需要预测从根节点到相应叶节点的路径即可。
问题8:word2vec的缺点
(1) 忽略了词序
问题9:hs为什么用霍夫曼树而不用其他二叉树?
这是因为Huffman树对于高频词会赋予更短的编码,使得高频词离根节点距离更近,从而使得训练速度加快。
问题10:为什么用的是线性激活函数?
word2vec不是为了做语言模型,它不需要预测得更准。
LSTM
结构
LSTM 结构如下:
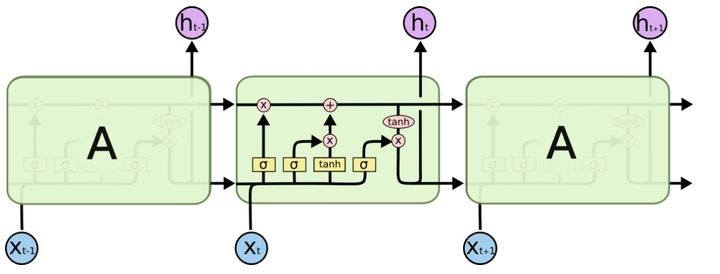
LSTM 主要包括三个门公式
1. 遗忘门(forget gate)
遗忘门决定上一时刻细胞状态中的多少信息可以传递到当前时刻中。
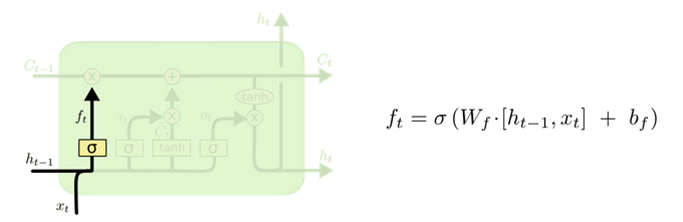
2. 输入门(input gate)
用来控制当前输入新生成的信息中有多少信息可以加入到细胞状态中。
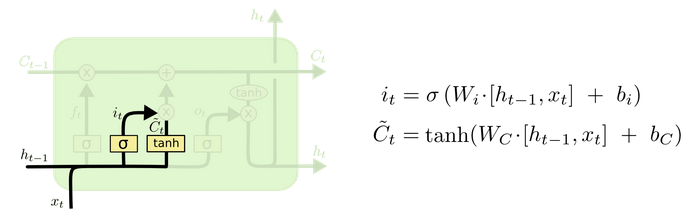
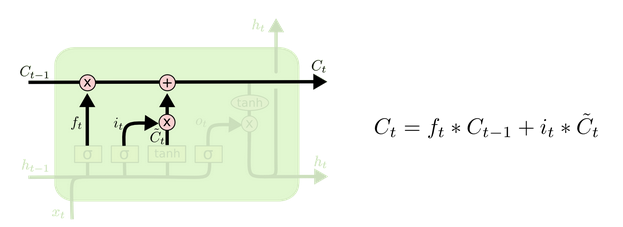
3. 更新细胞状态
细胞状态由两部分构成:
- 来自一时刻旧的细胞状态信息;
- 当前输入新生成的信息。
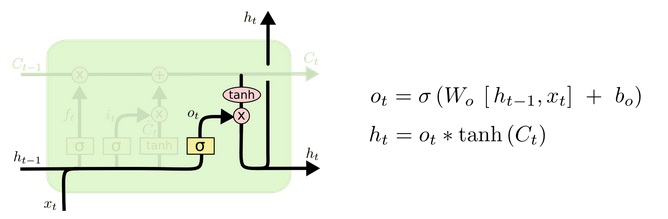
4. 输出门(output gate)
最后,基于更新的细胞状态,输出隐藏状态。
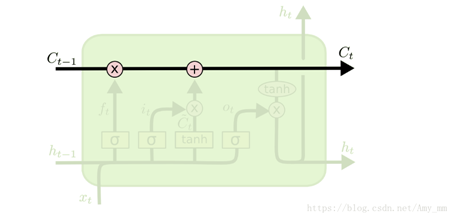
5. 记忆细胞(memory cell)
记忆细胞处于整个单元的水平线上,起到了信息传送带的作用,只几个含有简单的线性操作,能够保证数据流动时保持不变。
提问
LSTM解决了RNN的什么问题?
RNN 是在时间上的一个循环,每次循环都会用到上一次计算的结果,虽然 RNN 每个时刻 t 都会有输出,但是最后时刻的输出实际上已经包含了之前所有时刻的信息,所以一般我们只保留最后一个时刻的输出就够了。
RNN 的优缺点:
- 优点:处理a sequence或者a timeseries of data points效果比普通的DNN要好。中间状态理论上维护了从开头到现在的所有信息;
- 缺点:不难以学习到远距离的依赖关系,原因是梯度消失,网络几乎不可训练。所以也只是理论上可以记忆任意长的序列。
LSTM 就是用来缓解(实际上也没有解决) RNN 中梯度消失问题的,从而可以处理 long-term sequences。
LSTM 如何缓解梯度消失?
我们注意到, 首先三个门的激活函数是 sigmoid, 这也就意味着这三个门的输出要么接近于0 , 要么接近于1。这就使得 δ c t δ c t − 1 = f t \frac{\delta c_t}{\delta c_{t-1}} = f_t δct−1δct=ft, δ h t δ h t − 1 = o t \frac{\delta h_t}{\delta h_{t-1}} = o_t δht−1δht=ot 是非0即1的,当门为1时, 梯度能够很好的在LSTM中传递,很大程度上减轻了梯度消失发生的概率, 当门为0时,说明上一时刻的信息对当前时刻没有影响, 我们也就没有必要传递梯度回去来更新参数了。所以, 这就是为什么通过门机制就能够解决梯度的原因: 使得单元间的传递 δ S j δ S j − 1 \frac{\delta S_j}{\delta S_{j-1}} δSj−1δSj 为 0 或 1。
NLP 中常用的数据增强方法?
原文写得太好了,还有引用特别全
原文:一文了解NLP中的数据增强方法
1. 词汇替换
这一类的工作,简单来说,就是去替换原始文本中的某一部分,而不改变句子本身的意思。
1.1 基于同义词典的替换
我们从句子中随机取出一个单词,将其替换成对应的同义词。例如,我们可以使用英文的 WordNet 数据库来查找同义词,然后进行替换。
1.2 基于 Word-Embedding 的替换
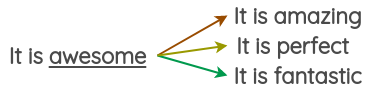
在这种方法中,我们采用预训练好的词向量,如 Word2Vec、Glove、FastText,用向量空间距离最近的单词替换原始句子中的单词。

例如,可以用三个向量空间中距离最近的单词替换原始句子中的单词,可以得到原始句子的三个变体。我们可以使用像 Gensim 包来完成这样的操作。在下面这个例子中,我们通过在 Tweet 语料上训练的词向量找到了单词 “awesome” 的同义词。
1.3 基于 Masked Language Model的替换
像 BERT、ROBERTA 和 ALBERT 这样基于 Transformer 的模型已经使用 “Masked Language Modeling” 的方式,即模型要根据上下文来预测被 Mask 的词语,通过这种方式在大规模的文本上进行预训练。
1.4 基于 TF-IDF 的替换
这种数据增强方法是 Xie 等人在 “Unsupervised Data Augmentation” 论文中提出来的。其基本思想是,TF-IDF 分数较低的单词不能提供信息,因此可以在不影响句子的基本真值标签的情况下替换它们。

2. 回译(Back Translation)
在这种方法中,我们使用机器翻译的方法来复述生成一段新的文本。Xie 等人使用这种方法来扩充未标注的样本,在 IMDB 数据集上他们只使用了 20 条标注数据,就可以训练得到一个半监督模型,并且他们的模型优于之前在 25000 条标注数据上训练得到的 SOTA 模型。
使用机器翻译来回译的具体流程如下:
其实就是把句子翻成其他语言,然后再翻回来,抄作业常干的事情(逃
- 找一些句子(如英语),翻译成另一种语言,如法语。
- 把法语句子翻译成英语句子。
- 检查新句子是否与原来的句子不同。如果是,那么我们使用这个新句子作为原始文本的补充版本。
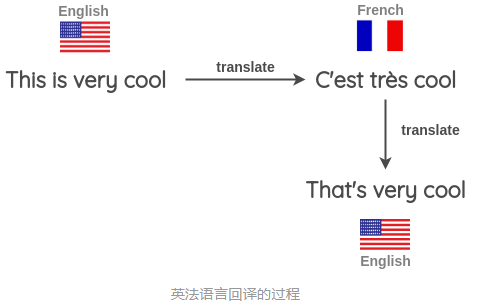
我们还可以同时使用多种不同的语言来进行回译以生成更多的文本变体。如下图所示,我们将一个英语句子翻译成目标语言,然后再将其翻译成三种目标语言:法语、汉语和意大利语。
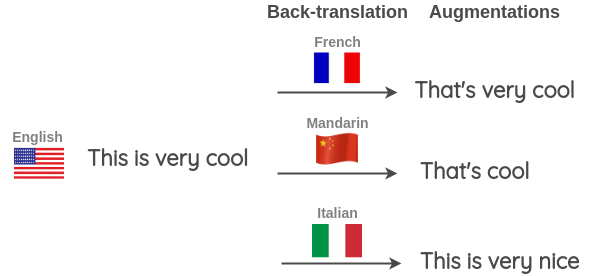
这种方法也在 Kaggle 上的 “Toxic Comment Classification Challenge” 的第一名解决方案中使用。获胜者将其用于训练数据扩充和测试,在应用于测试的时候,对英语句子的预测概率以及使用三种语言(法语、德语、西班牙语)的反向翻译进行平均,以得到最终的预测。
对于如何实现回译,可以使用 TextBlob 或者谷歌翻译。
3. 文本表面转换(Text Surface Transformation)
这些是使用正则表达式应用的简单模式匹配变换,Claude Coulombe 在他的论文中介绍了这些变换的方法。
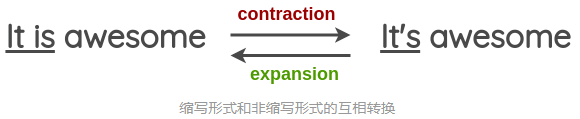
在论文中,他给出了一个将动词由缩写形式转换为非缩写形式的例子,我们可以通过这个简单的方法来做文本的数据增强。
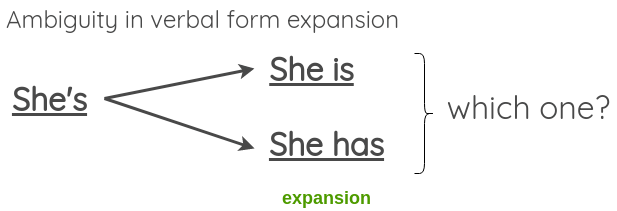
需要注意的是,虽然这样的转换在大部分情况下不会改变句子原本的含义,但有时在扩展模棱两可的动词形式时可能会失败,比如下面这个例子:
为了解决这一问题,论文中也提出允许模糊收缩 (非缩写形式转缩写形式),但跳过模糊展开的方法 (缩写形式转非缩写形式)。
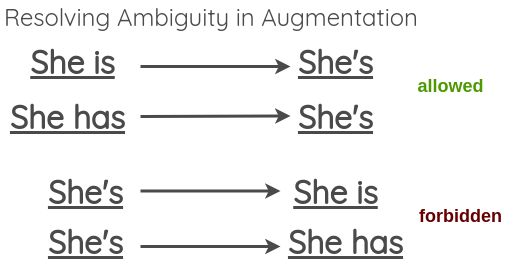
我们可以在这里找到英语缩写的列表。对于展开,可以使用 Python 中的 contractions 库。
4. 随机噪音注入(Random Noise Injection)
这些方法的思想是在文本中注入噪声,来生成新的文本,最后使得训练的模型对扰动具有鲁棒性。
4.1 拼写错误注入(Spelling error injection)
在这种方法中,我们在句子中添加一些随机单词的拼写错误。可以通过编程方式或使用常见拼写错误的映射来添加这些拼写错误,具体可以参考这个链接。

4.2 键盘错误注入(QWERTY Keyboard Error Injection)
这种方法试图模拟在 QWERTY 键盘布局上打字时由于键之间非常接近而发生的常见错误。这种错误通常是在通过键盘输入文本时发生的。

4.3 单字噪音(Unigram Noising)
Unigram 是指单个字母,或者单个音节,或者一个词表示的单词
这种方法已经被 Xie 等人和 UDA 的论文所使用,其思想是使用从 unigram 频率分布中采样的单词进行替换。这个频率基本上就是每个单词在训练语料库中出现的次数。
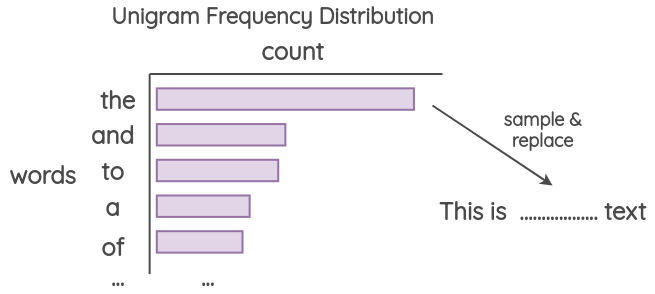
4.4 空白噪音(Blank Noising)
该方法由 Xie 等人在他们的论文中提出,其思想是用占位符标记替换一些随机单词。本文使用 “_” 作为占位符标记。在论文中,他们使用它作为一种避免在特定上下文上过度拟合的方法以及语言模型平滑的机制,这项方法可以有效提高生成文本的 Perplexity 和 BLEU 值。
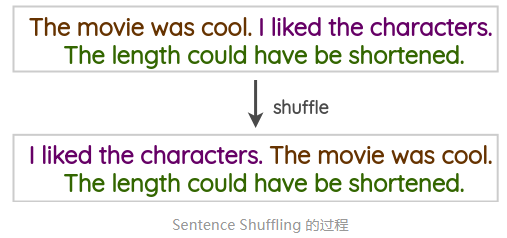
4.5 句子打乱(Sentence Shuffling)
这是一种很初级的方法,我们将训练样本中的句子打乱,来创建一个对应的数据增强样本。
4.6 随机注入(Random Insertion)
这个方法是由 Wei 等人在其论文 “Easy Data Augmentation” 中提出的。在该方法中,我们首先从句子中随机选择一个不是停止词的词。然后,我们找到它对应的同义词,并将其插入到句子中的一个随机位置。

4.7 随机交换(Random Swap)
这个方法也由 Wei 等人在其论文 “Easy Data Augmentation” 中提出的。该方法是在句子中随机交换任意两个单词。

4.8 随机删除(Random Deletion)
该方法也由 Wei 等人在其论文 “Easy Data Augmentation” 中提出。在这个方法中,我们以概率 p 随机删除句子中的每个单词。

5. 实例交叉增强(Instance Crossover Augmentation)
这种方法由 Luque 在他 TASS 2019 的论文中介绍,灵感来自于遗传学中的染色体交叉操作。
在该方法中,一条 tweet 被分成两半,然后两个相同情绪类别(正/负)的 tweets 各自交换一半的内容。这么做的假设是,即使结果在语法和语义上不健全,新的文本仍将保留原来的情绪类别。
这中方法对准确性没有影响,并且在 F1-score 上还有所提升,这表明它帮助了模型提升了在罕见类别上的判断能力,比如 tweet 中较少的中立类别。

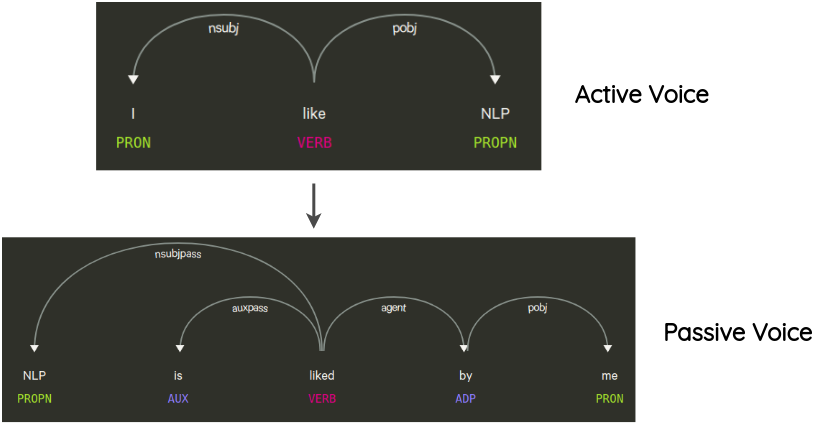
6. 语法树操作(Syntax-tree Manipulation)
这种方法最先是由 Coulombe 提出的,其思想是解析并生成原始句子的依赖树,使用规则对其进行转换来对原句子做复述生成。
例如,一个不会改变句子意思的转换是句子的主动语态和被动语态的转换。
7. 文本合成(MixUp for Text)
Mixup 是 Zhang 等人在 2017 年提出的一种简单有效的图像增强方法。其思想是将两个随机图像按一定比例组合成,以生成用于训练的合成数据。对于图像,这意味着合并两个不同类的图像像素。它在模型训练的时候可以作为的一种正则化的方式。

为了把这个想法带到 NLP 中,Guo 等人修改了 Mixup 来处理文本。他们提出了两种将 Mixup 应用于文本的方法:
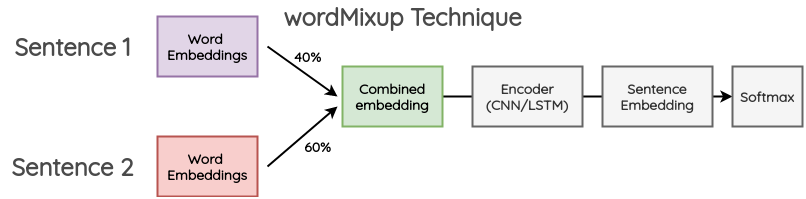
7.1 单词级别的合成(wordMixup)
在这种方法中,在一个小批中取两个随机的句子,它们被填充成相同的长度;然后,他们的 word embeddings 按一定比例组合,产生新的 word embeddings 然后传递下游的文本分类流程,交叉熵损失是根据原始文本的两个标签按一定比例计算得到的。
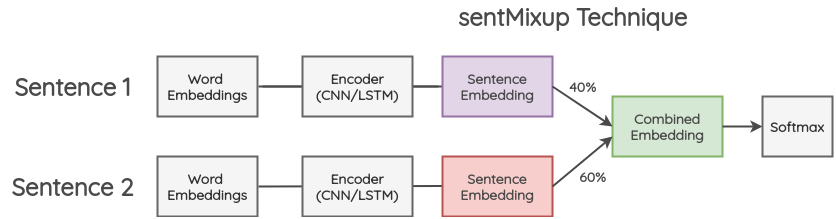
7.2 句子级别的合成(sentMixup)
在这种方法中,两个句子首先也是被填充到相同的长度;然后,通过 LSTM/CNN 编码器传递他们的 word embeddings,我们把最后的隐藏状态作为 sentence embedding。这些 embeddings 按一定的比例组合,然后传递到最终的分类层。交叉熵损失是根据原始文本的两个标签按一定比例计算得到的。
8. 生成式的方法
这一类的工作尝试在生成额外的训练数据的同时保留原始类别的标签。
Conditional Pre-trained Language Models
这种方法最早是由 Anaby-Tavor 等人在他们的论文 “Not Enough Data? Deep Learning to the Rescue!” Kumar 等人最近的一篇论文在多个基于 Transformer 的预训练模型中验证了这一想法。
问题的表述如下:
-
在训练数据中预先加入类别标签,如下图所示。
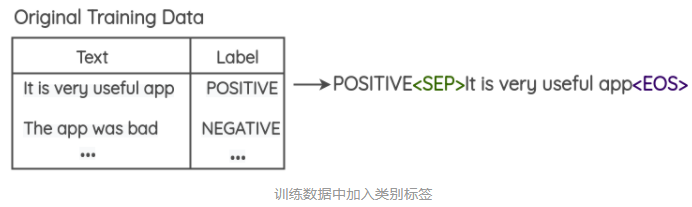
-
在这个修改过的训练数据上 finetune 一个大型的预训练语言模型 (BERT/GPT2/BART) 。对于 GPT2,目标是去做生成任务;而对于 BERT,目标是要去预测被 Mask 的词语。

-
使用经过 finetune 的语言模型,可以使用类标签和几个初始单词作为模型的提示词来生成新的数据。本文使用每条训练数据的前 3 个初始词来为训练数据做数据增强。


