
热门标签
热门文章
- 1MQ2烟雾传感器_mq2烟雾传感器浓度算法
- 2数仓建模分层概述_dws 轻度汇总
- 3【股价预测】基于matlab遗传算法优化BP神经网络预测股价【含Matlab源码 1250期】_bp神经网络预测股票模型代码
- 4Python调用deepl api脚本
- 5Docker配置mysql以及宿主机容器目录挂载_docker绑定宿主机目录和容器目录 容器目录需要创建嘛
- 6Jupyter Notebook的安装及在网页端和VScode中使用教程(详细图文教程)_jupyter notebook网页版
- 7经典算法之——解决全排列问题以及详解_排列问题的过程
- 82020江苏计算机事业单位,2020江苏事业单位计算机类岗位考情
- 9HuggingFace开源的自然语言处理AI工具平台_huggingface平台
- 10xcode15 ios17安装问题 an Library ‘iconv.2.4‘ not found Unable to execute command: Segmentation fault: 11_library 'iconv.2.4.0' not found
当前位置: article > 正文
119基于lstm对中文文本数据分类_lstm模型中文文本预测分类
作者:2023面试高手 | 2024-04-22 00:05:04
赞
踩
lstm模型中文文本预测分类
本期给大家介绍的是119基于lstm对中文文本数据分类,效果图如下:

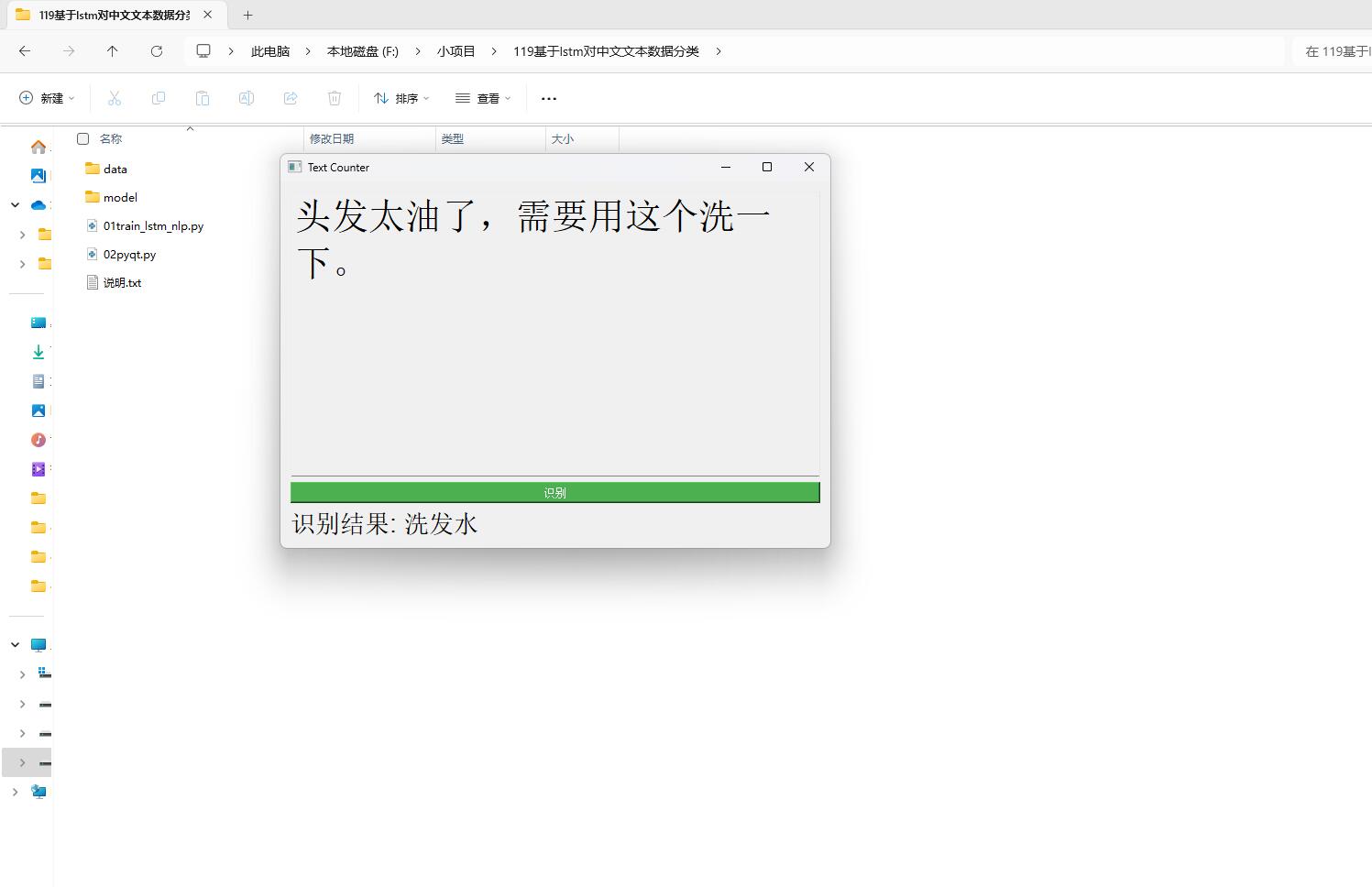
这是调用训练好的模型来识别的,运行python 02pyqt.py的可视化界面,通过输入文本来识别讲述的是什么物件。
代码下载和视频演示地址:
119基于lstm对中文文本数据分类_哔哩哔哩_bilibili
代码整体是非常简便的,总共两个py部分和一个数据集在data文件夹下。

Data文件夹存的了txt是中文停止符,用来处理中文数据用的,csv文件中记录的是数据集,第一列是对应的要最后识别出的物件,第二列表示文本是积极的还是消极的,这里做文本内容的分类暂时不需要这个。然后第三列是对应的文本内容。

运行01train_lstm_nlp.py会将csv文件里面的数据集进行训练,然后保存模型在model文件下。
运行python 02pyqt.py会有可视化的界面,输入需要测试的文本内容,就会调用已经训练好保存在本地的模型进行识别结果。
注:
下载本代码环境自行安装
如需远程安装环境运行,
或逐行代码注释(小白也能快速掌握理解代码),
或其他需求定制都是另外算的。
+我扣扣的,在非工作日和工作日晚上8-12点之间,看到消息秒回。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/465805
推荐阅读
相关标签

