- 1在Ubuntu上安装Hadoop_ubuntu安装hadoop_普通网友的博客-csdn博客
- 2conda环境下RuntimeError: Couldn‘t determine Stable Diffusion‘s hash问题解决_couldn't determine stable diffusion's hash: cf1d67
- 3分享谷歌浏览器历史版本下载地址和谷歌浏览器驱动历史版本下载地址
- 4LeetCode第1题-两数之和(C++实现)_class solution <%public:vector
twosum(vector< - 5SpringBoot + Redis 实现接口限流_springboot redis限流
- 6轻松玩转树莓派Pico之五、FreeRTOS体验_树莓派4b 移植freertos
- 7数学建模学习笔记(十)——时间序列模型_arima样本量指的是年份数据还是指标数据
- 8自然语言处理(NLP)技术_自然语言处理技术csdn
- 9司马阅成为「百度文心大模型灵境矩阵平台」首批合作伙伴,共建AI生态
- 10【华为OD机试真题 Java语言】159、星际篮球争霸赛 | 机试真题+思路参考+代码解析_华为od 星球争霸篮球赛
Git - 底层原理_turn off this advice by setting config variable ad
赞
踩
目录
git merge - 3 way merge with conflict
.git
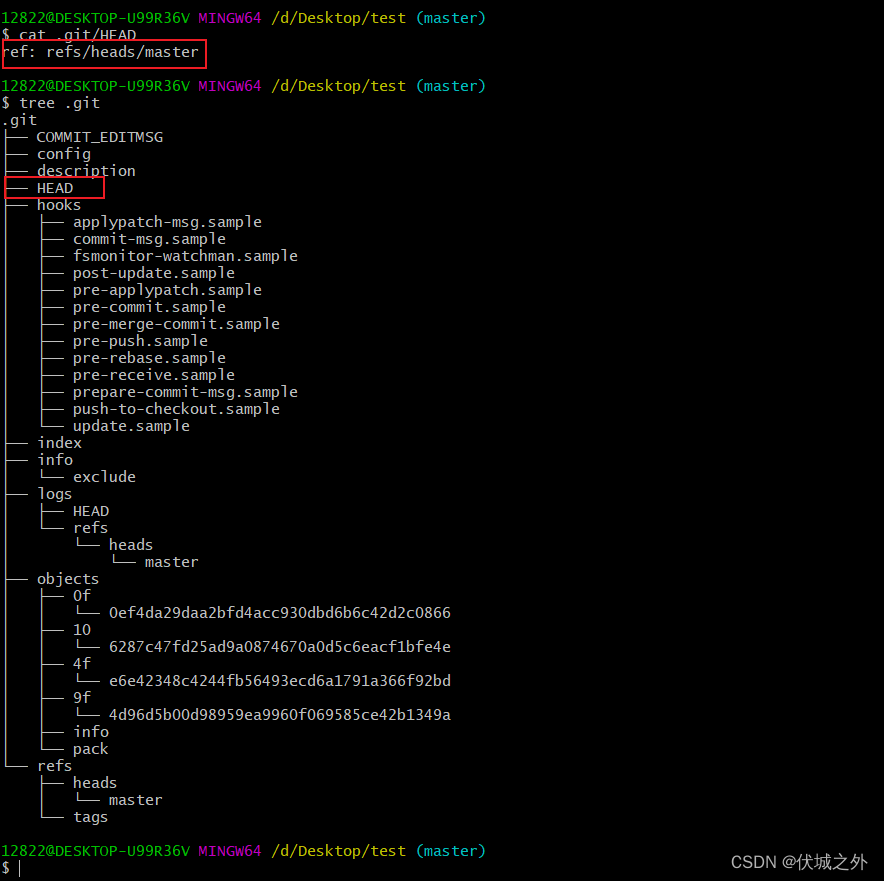
当我们使用git init命令创建一个空白的仓库后,命令执行目录下会生成一个.git文件夹,这个文件夹就是被创建的本地git仓库。
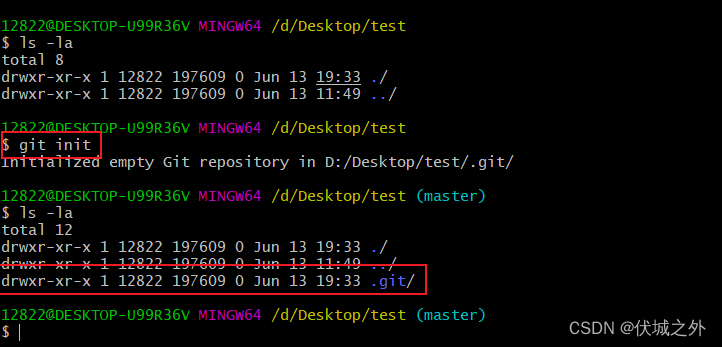
我们打印下.git的目录结构

.git/config
我们先查看下 .git/config文件

里面是当前git仓库的一些配置信息
我们可以使用git config命令向该配置文件中加入配置信息:用户名,用户邮箱
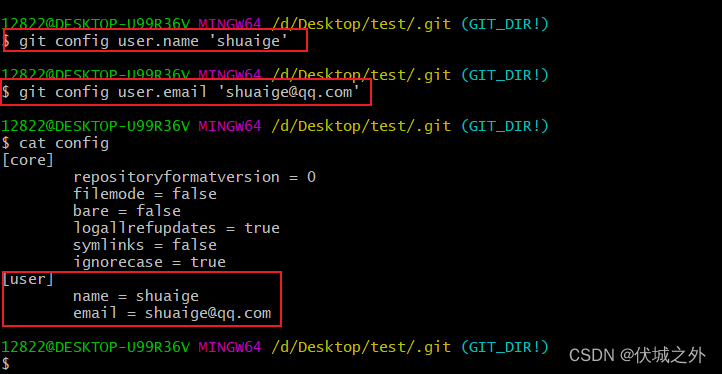
而与此同时,~/.gitconfig 全局git配置文件中也有用户名和用户邮箱信息

全局git配置文件中的配置信息是对所有本地git仓库有效的。
所以很明显,.git/config优先级更高。如下面例子中,git log打印提交记录日志中的用户信息就是.git/config中配置的
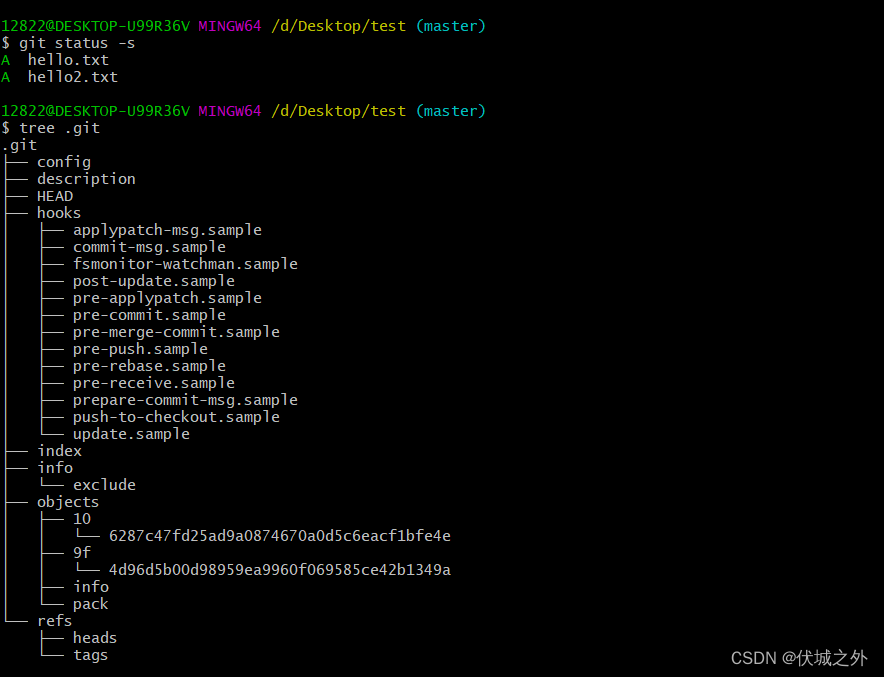
git add执行背后的操作
未执行git add前的.git工作目录
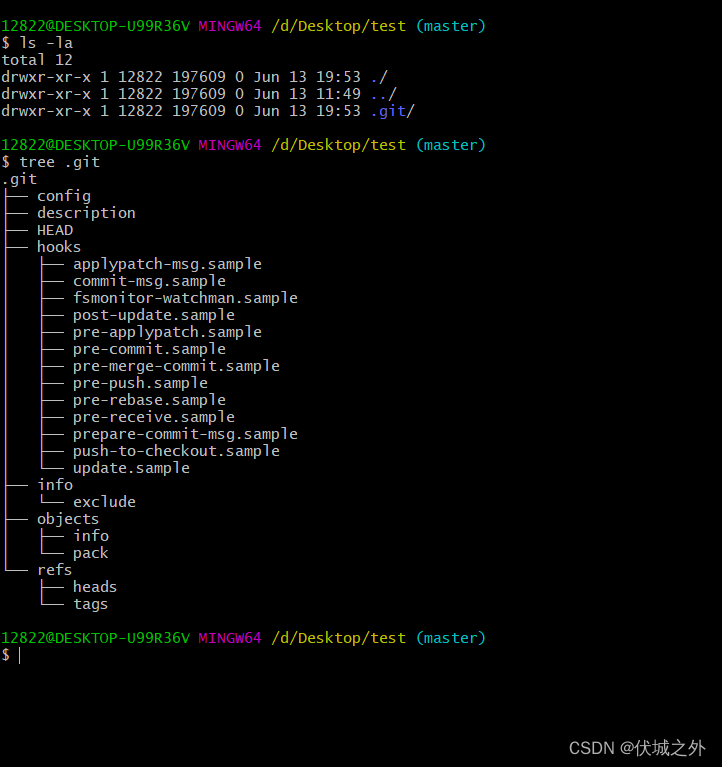
执行git add后的.git工作目录

发现新增了objetcs/10目录和目录下文件,新增了index文件
其中6287c47fd25ad9a0874670a0d5c6eacf1bfe4e是一串HASH值,由SHA1算法是根据 git add的文件的内容生成的。
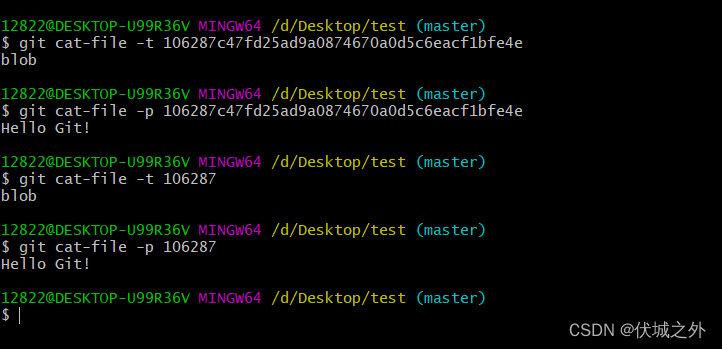
我们可以使用 git cat-file -t 查看git objects的类型,git cat-file -p查看git objects的内容
需要注意 git cat-file命令的参数为 目录 + 完整HASH值,或者目录 + HASH值前4位
git objects的HASH值中不包含文件名信息,验证如下:
生成一个内容也为“Hello Git!”的hello2.txt文件,也git add它,但是.git/objects中没有新增新对象。
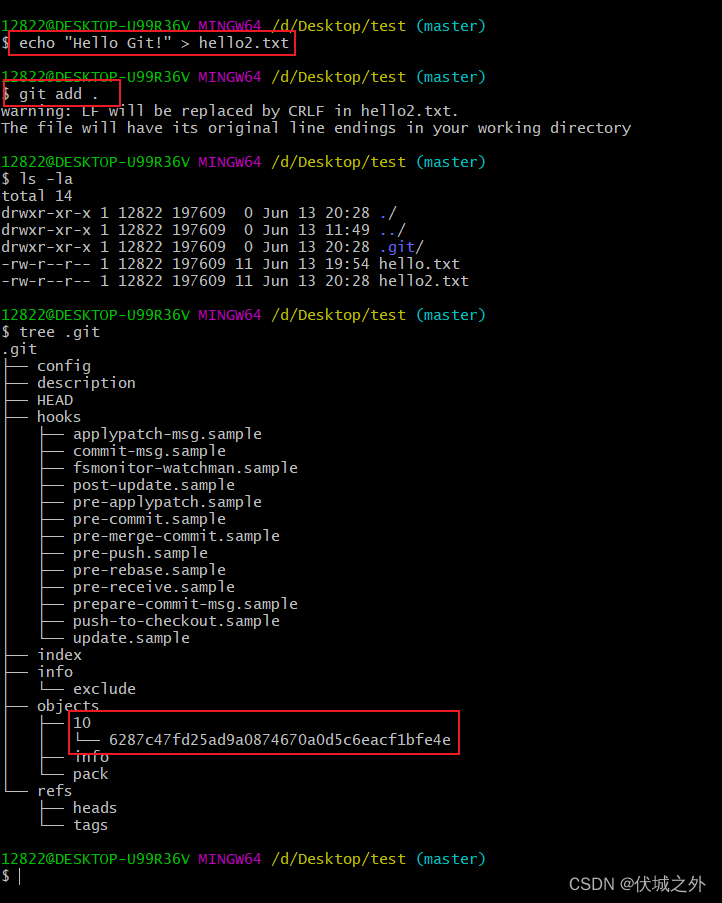 当git add的文件的内容相同时,它们将共用一个.git/objects下的对象
当git add的文件的内容相同时,它们将共用一个.git/objects下的对象
.git/objects对象名字:HASH值计算规则
基于SHA1算法,计算字符串【 "blob" + " " + 文件大小 + "\0" + 文件内容 】的HASH值
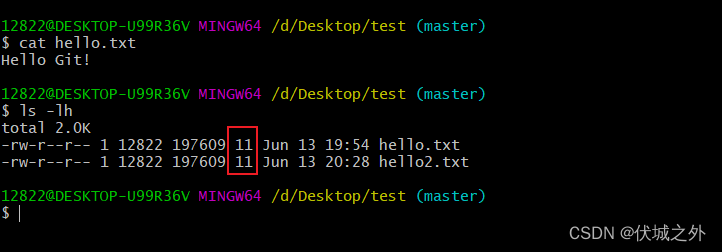
需要注意的是hello.txt文件内容是echo命令添加的,echo命令会默认在文件内容末尾加一个换行符(PS:echo有时候需要-e参数才可以识别转义字符)
所以虽然输入的内容“Hello Git!”长度是10位,但是实际上是11位。
另外windows系统自带了一个SHA1算法的函数 shasum

另外,.git/objects/10下的文件的内容是:被压缩过的内容(”blob 11\0Hello Git!“) + 压缩配置信息
所以一般而言,.git/objects/10下的文件大小 要远小于 hello.txt的文件大小
但是当hello.txt文件太小时,.git/objects/10下的文件的大小将有很大一部分是压缩配置信息,此时会表现为.git/objects/10下的文件的反而变大了的现象。
.git/index
学习Git时,Git有三块区域:工作区、暂存区、git仓库。
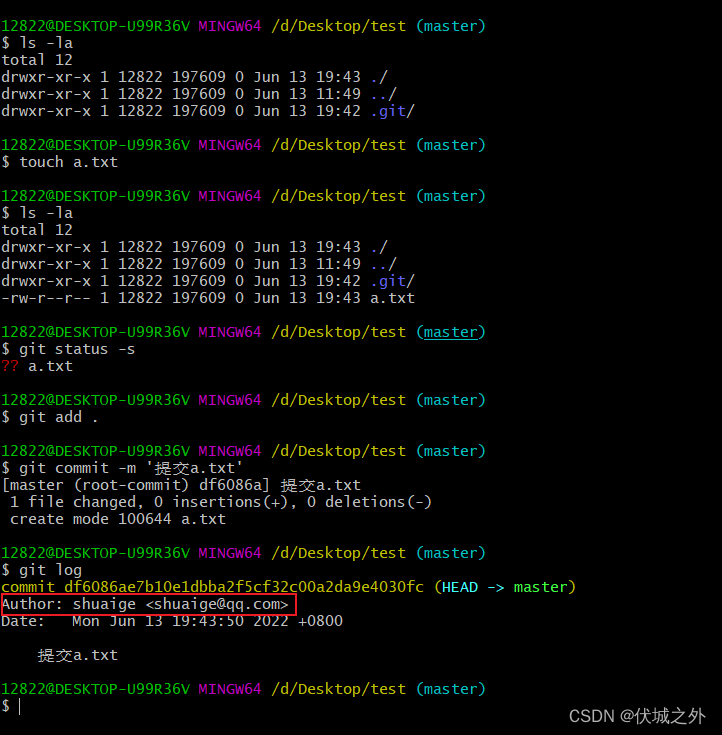
当我们新建一个文件时,该文件将默认处于工作区,并且状态是 Untracked。
当我们git add该文件后,该文件会被转成一个blob对象存放到暂存区.git/objects中,而前面学习了blob对象内容是由,"blob" + " " + 文件大小 + "\0" + 文件内容 ,经过SHA1算法加密产生的,所以blob对象中并不包含文件名信息。
而暂存区还有一个别名叫”索引区“,这里的索引其实就是git add文件的名字信息,他被存储在.git/index文件中

我们可以使用 git ls-files来打印出.git/index中信息:发现.git/objects中blob对象对应的文件名都在
我们可以使用git ls-files -s打印.git/index的详细信息:
- 100644:是hello.txt的文件权限值
- 106287c47fd25ad9a0874670a0d5c6eacf1bfe4e:是hello.txt的文件内容
- 0
- hello.txt:文件名
当我们git add某文件后,该文件状态就变为了new file,如果此时我们再次修改工作区中该文件,则会造成工作区中文件内容 和 暂存区中文件内容 不一致,Git通过计算两个文件内容HASH值,发现不同,则认定工作区中该文件为modified状态

而由于工作区中修改后文件还没有被git add,所以暂存区中hello.txt保持原样。
一旦我们git add 工作区中修改后文件到暂存区,则

暂存区中,.git/objects会多一个blob对象,即为hello.txt修改后的内容加密后的对象。
.git/index中,hello.txt对应的blob对象也会变更新的。
git commit运行原理
当我们git add文件到暂存区后,一般紧接着会git commit提交文件到git仓库。那么git commit的运行原理是啥呢?
git commit前
git commit后

发现多了不少东西,首先我们先看git commit命令执行返回信息
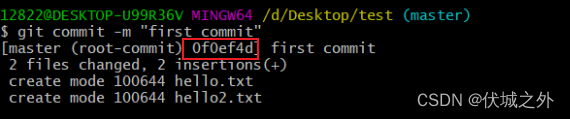
提示在 master分支上进行了一次根提交(root-commit)0f0ef4d,提交信息为first commit。
本次提交造成两个文件改变,两个文件新增,新增了hello.txt、hello2.txt。

我们发现0f0ef4d其实是.git/objects中的一个对象,对象类型为commit,对象内容为

包含了一个tree信息,author作者信息,提交时间戳信息,提交人信息,提交描述信息。

而tree信息也指向了.git/objects中的一个对象

而该对象又是一个tree类型,内容是另外两个blob对象的索引。
所以整体得到一个视图:

另外,.git/refs/heads/master内容也指向了本次commit对象,这表明当前master分支最新的commit是0f0ef4d
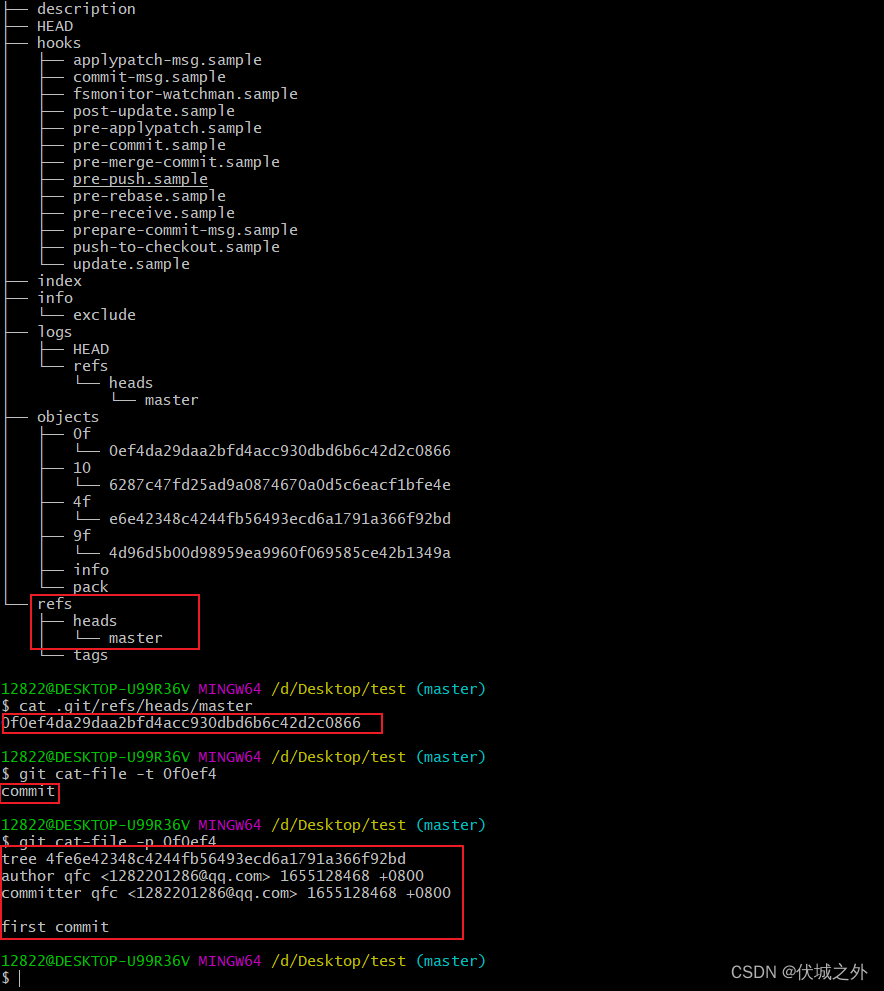
而.git/HEAD又指向了.git/ref/heads/master,我们可以将.git/HEAD理解为一个指针,它永远指向我们当前工作的分支,比如当前工作分支是master分支。
假设我们创建了一个新的分支,并切换到该分支,则.git/HEAD内容将变为该分支所在文件
好的,上面就是commit和分支的关系的简单说明。
下面我们继续讨论git commit,如果我们修改了hello.txt的内容,则必然造成工作区和暂存区的hello.txt内容不一致,导致工作区的hello.txt被Git判定为modified状态,

然后我们git add它,会产生一个新的blob对象,并且暂存区的hello.txt的索引会改变指向到新blob对象

如果我们再次git commit,则会产生一个commit对象,一个tree对象

而此次commit对象中多了一个parent对象,该parent对象是上一次commit对象。
所以视图如下:

那么我们继续测试git commit,如果我们新增了一个文件夹,那么文件夹会被Git识别到吗

可以发现folder1没有被识别到。
如果我们继续向folder1中新增一个文件hello3.txt

可以发现,当我们向folder1中添加了一个新文件后,则folder1会被Git识别为Untracked状态。

当我们git add文件夹后,发现暂存区的索引新增了一个 folder1/hello3.txt,并且其对应一个新创建的blob对象,内容就是hello3.txt的内容。
下面我们git commit
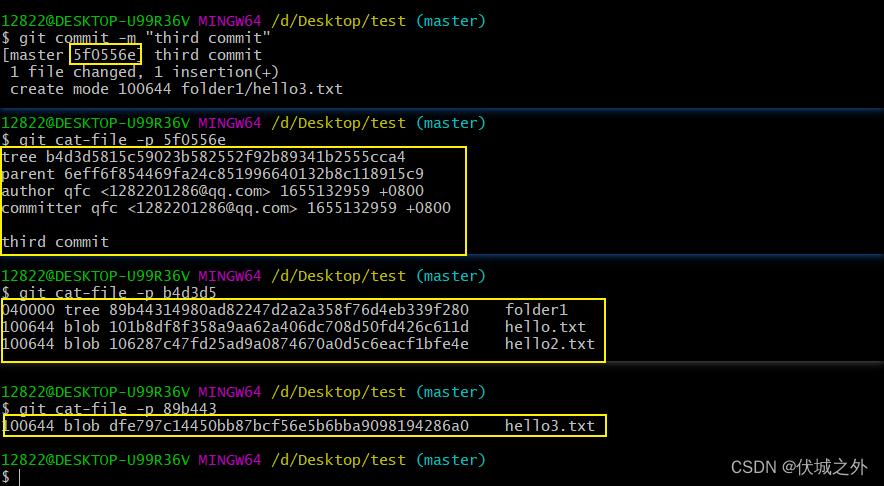
可得视图:
 现在,从图中,其实已经可以看出了Git仓库的基本工作原理了:每个commit就是一个版本,每个版本都有一个root tree,根据root tree就可以找到本版本对应的文件及其他文件夹内文件。
现在,从图中,其实已经可以看出了Git仓库的基本工作原理了:每个commit就是一个版本,每个版本都有一个root tree,根据root tree就可以找到本版本对应的文件及其他文件夹内文件。
Git的文件状态

分支Branches
在Git中,分支的概念就是一个commit对象。
.git/HEAD是一个指针,它总是指向当前工作的分支,且总是指向当前分支最新一次commit。

这里提示当前正在工作的分支是 .git/refs/heads/master

检查对应的SHA1名字的文件

发现master分支就是一个commit对象。

而分支总是指向最新一次commit对象。
所以 HEAD -> master,表示当前工作分支是master,且指向master分支的最新commit。

分支操作及背后原理
git branch命令用于展示当前git仓库中的所有分支
git branch <branch_name> 用于基于当前所在分支,创建一个新的分支
git branch -d <branch_name> 用于删除指定名字的分支,但是删除前会检查该分支是否被merge过,如果没有,则不执行删除
git branch -D <branch_name> 用于强制删除指定名字的分支,不管其有没有被merge过。
git checkout <branch_name> 用于切换到指定名字的分支

上面*号表示master分支是当前正在工作的分支
打印当前.git目录(PS:由于.git/hooks文件较多,已手动删除 rm -f .git/hooks/*.samples)
发现 .git/refs/heads只有一个分支master

当创建一个新分支后,.git/refs.heads就有两个分支了,master和dev
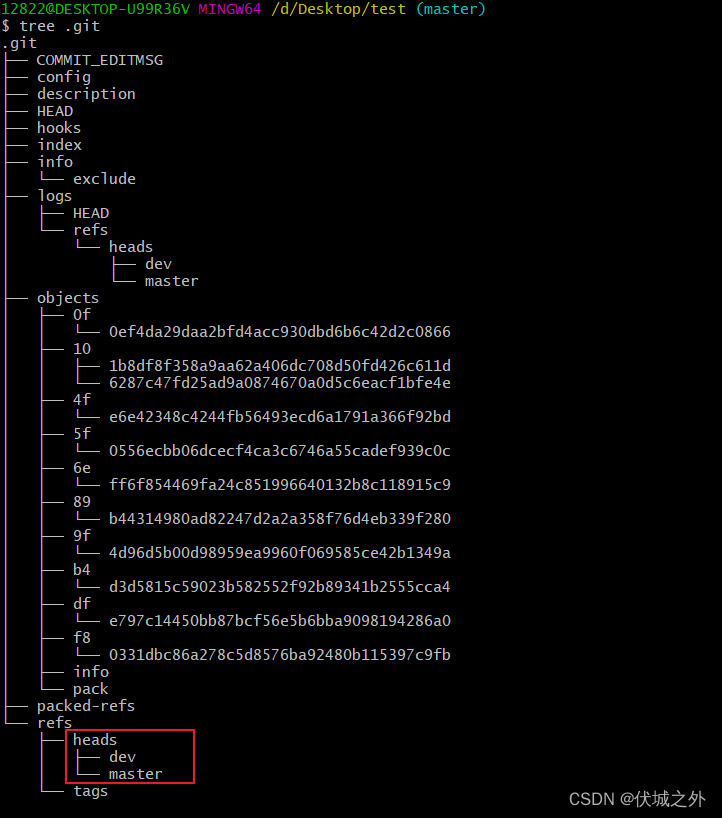
而其他地方,如.git/objects并没有新增对象。
这也证明了分支本质就是一个指针,它指向一个commit对象。
那么dev分支指向的commit对象是哪个呢?

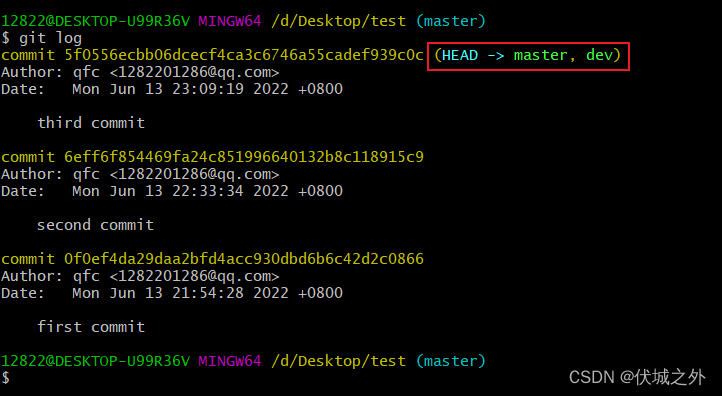
可以发现,dev分支指向的就是master分支指向的commit对象。
原因是,我们是在master分支5f0556commit上创建的dev分支,所以dev分支也指向了 5f0556commit。即如下图所示:
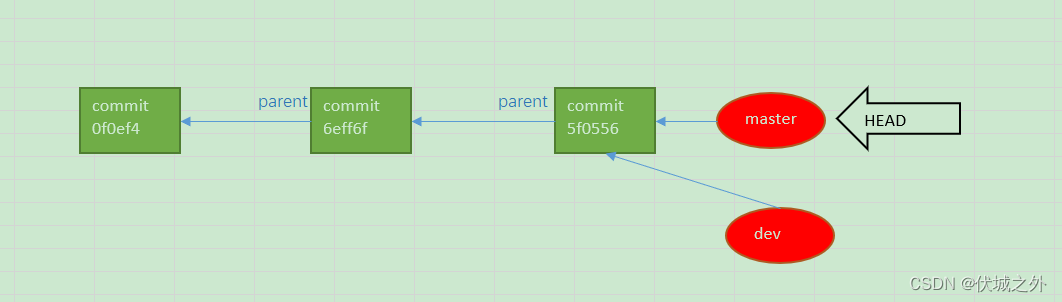
另外此时,.git/HEAD指针依旧指向master分支

还有需要注意的是,由于dev此时和master指向同一个commit,所以git log时,会出现(HEAD -> master,dev)这种HEAD指向两个分支的情况,因为HEAD虽然指向当前工作分支,但是也指向当前工作分支的最新commit。

如果我们在master分支上新增一次commit,比如修改hello.txt内容后,提交

发现,master分支指向了最新的commit,已经和dev不同了


当我们切换到dev分支后,其实就是改变.git/HEAD的指向为.git/refs/heads/dev

而此时git log显示就只有dev分支的commit对象

如果我们在dev分支上新增一个文件,并提交,则

如果我们此时删除dev分支

首先,我们不能处于dev分支上,删除dev分支,这样会报错。
原因可能是,当前HEAD指针正在指向dev,如果删除了dev,则HEAD指针就没有指向了。
所以我们要先切换到其他分支上,然后再删除dev分支
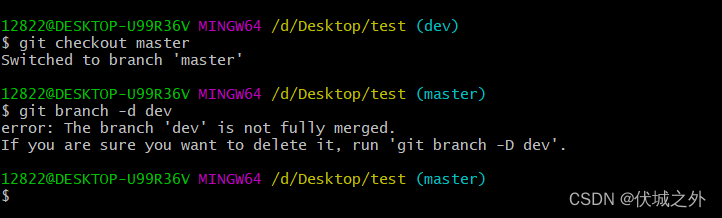
但是此时 git branch -d命令提示,dev分支上的修改还没有被merge过,这是啥意思呢?
假设我们在dev分支上开发了很多新代码,然后我们又把dev分支删掉,那么dev分支上开发的新代码就没了,这是非常危险的行为。所以当我们在删除一个分支前,需要考虑是否何如该分支新开发的代码到其他分支上去。
但是,如果我们就是想强制删除dev分支,不管代码有米有merge过呢?
可以使用git branch -D命令
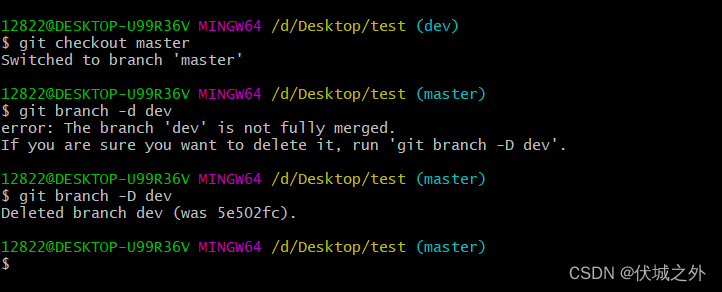
此时就能直接删除dev分支了

那么dev分支被删除后,dev分支对应的commit,tree,blob还在吗?
答案是依旧被Git保留着。

git checkout
接着上文,既然dev分支已经被强制删除了,那么Git为啥还要保留dev分支指向的commit呢?
因为Git考虑到dev有可能是被误删的,此时保留住dev分支对应的commit是可以挽回损失的。
那么如何找回dev分支对应的commit呢?
虽然,我们知道dev-commit一定是保留在了.git/objects中的,但是其中的objects非常多,一个一个找非常费时,此时如果我们能在log中找到dev的删除记录就好了,但是

git log只会显示当前所在分支的commit记录。
此时,我们需要借助git reflog命令,查看所有的分支的commit操作
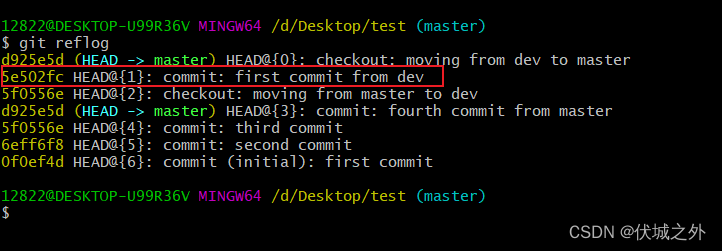 找到dev分支的最后一次commit操作,此时得到commit的SHA1值为5e502fc
找到dev分支的最后一次commit操作,此时得到commit的SHA1值为5e502fc

经过检查,发现这个commit就是我们之前删除的dev对应的commit,里面有我们在dev分支上开发的新代码dev.txt。
那么找到了被删除的dev分支对应的commit对象,我们如何恢复它呢?
其实恢复的意思就是让commit对象重新被一个分支指向。
我们知道git checkout的本质其实是,改变.git/HEAD指针的指向,而HEAD指针不仅可以指向一个分支,也可以指向一个commit对象。
即:git checkout不仅切换到一个分支,还可以切换到一个commit对象上

此时git checkout命令返回了一大堆提示信息:
Note: switching to '5e502fc'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:git switch -c <new-branch-name>
Or undo this operation with:
git switch -
Turn off this advice by setting config variable advice.detachedHead to false
HEAD is now at 5e502fc first commit from dev
大致意思是,你现在将HEAD切换到了一个commit上,但是这只是一个分离状态的切换,你需要创建一个分支,然后让HEAD指向分支,分支指向commit。你可以借助git switch -c <new_branch_name>命令完成这个动作。
(PS:git switch -c是一个新特性,我们可以使用原始方式 git checkout -b <new_branch_name>)
如果你不想进行上面操作了,可以直接git checkout切换回原来的分支。

git switch -c的意思是,新创建一个分支,让新分支指向当前HEAD指向的commit对象,最后切换到该新分支。
总结一下:
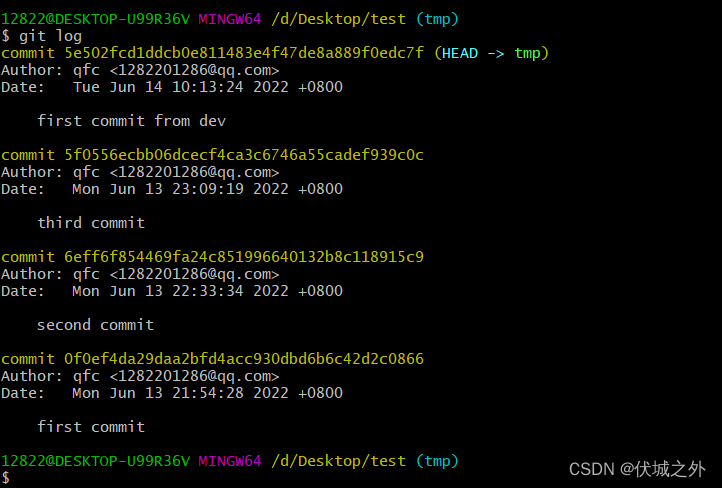
如果你误删了某个分支,如dev,并且还没合入dev的代码,此时
- git reflog 找到 dev分支的最后一次commit
- git checkout 到 dev分支的最后一次commit,即将HEAD -> commit
- git switch -c tmp,即将 tmp -> commit,将HEAD -> tmp
- 此时新分支tmp就相当于原来的误删的dev分支
git diff
当我们向被Git管理的项目中新增一个文件时,该文件将处于工作区,状态为Untracked,当我们git add该文件后,该文件将处于缓存区,状态为staged,当我们git commit该文件后,该文件将处于git仓库,状态为unmodified。
而当工作区和缓存区中该文件不同时,Git会判定该文件状态为modified,此时就会产生diff,可以使用命令 git diff查看
而当缓存区和仓库中该文件不同时,Git也会判定该文件状态为modified,此时也会产生diff,可以使用 git diff --cached查看。
但是现在大部分IDE工具已经实现了展示modified状态文件的前后差异。比如VSCode

修改hello.txt前,VSCode正常显示。
 当我们对hello.txt做了修改后,工作区中的hello.txt将和缓存区中的hello.txt不一致,hello.txt状态变为modified,此时VSCode一共做出三个反应:
当我们对hello.txt做了修改后,工作区中的hello.txt将和缓存区中的hello.txt不一致,hello.txt状态变为modified,此时VSCode一共做出三个反应:
首先是目录中,hello.txt文件备注了一个M状态,即表示工作区hello.txt已经和缓存区不一致了。
其次是,hello.txt的内容区,在存在diff的行数上,有一个绿色条,我们鼠标点击绿色条,VSCode将提示具体变更

还有就是,VSCode的左边工具栏中有一个① ,表示产生VSCode发现了一个差异。如果有两个差异,则显示②,显示数就是差异数。
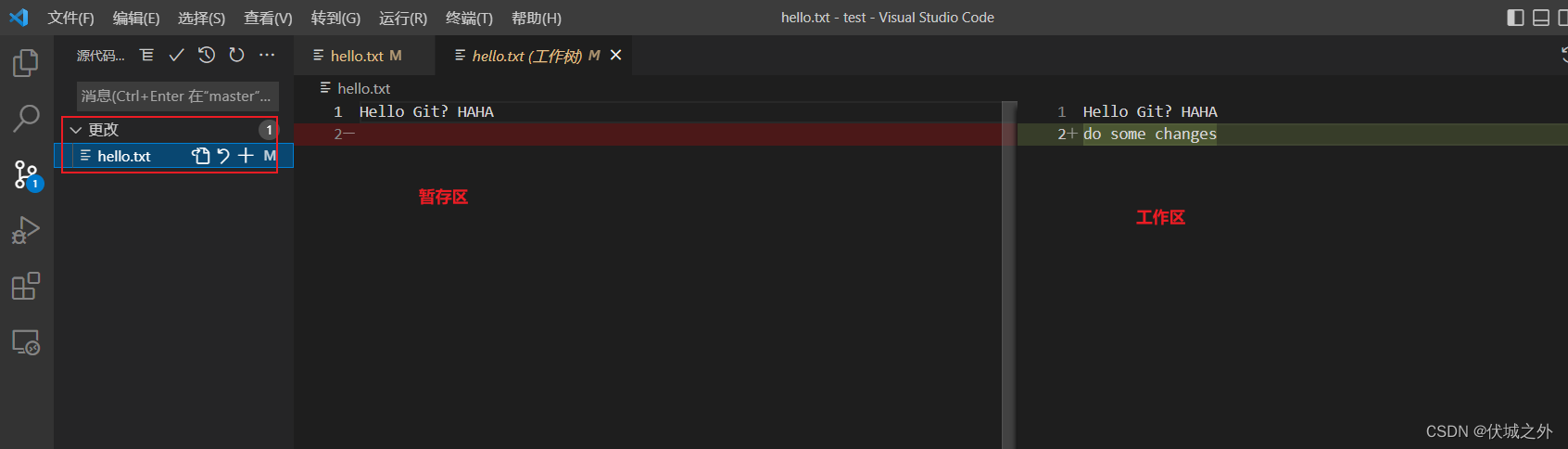
点击存在差异变更的文件hello.txt,将展示发生变更前后的两个文件的对比,左边是缓存区的hello.txt,右边是工作区的hello.txt。
当我们git add暂存工作区hello.txt后

则此时工作区与缓存区hello.txt一致,而缓存区与git仓库hello.txt不一致,hello.txt状态变为modified(暂存的更改)。
当我们git commit后,则三区hello.txt全部一致,hello.txt状态为unmodified
可以发现,使用VSCode查看文件变更的diff,非常直观以及容易。
下面演示下使用git diff命令来展示差异。
首先,变更hello.txt,造成工作区与缓存区的hello.txt不一致

我们可以借助git diff命令,查看工作区和缓存区存在不一致的文件的差异

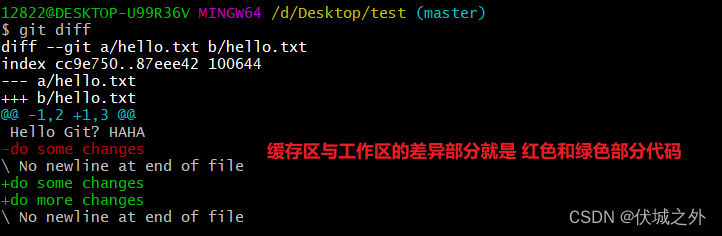
首先我们可以判断下git diff对比的是那两个区的文件差异,我们发现

cc9e750就是缓存区的hello.txt对应的blob对象,而87eee42没有对应的blob对象,应该就是工作区的临时生成的一个对象,所以git diff对比就是缓存区和工作区的hello.txt的差异。
接下来就是具体差异对比了

@@ -1,2 +1,3 @@
-1,2表示,从缓存区的第1行开始起,往后2行,如下图左边
+1,3表示,从工作区的第1行开始起,往后3行,如下图右边
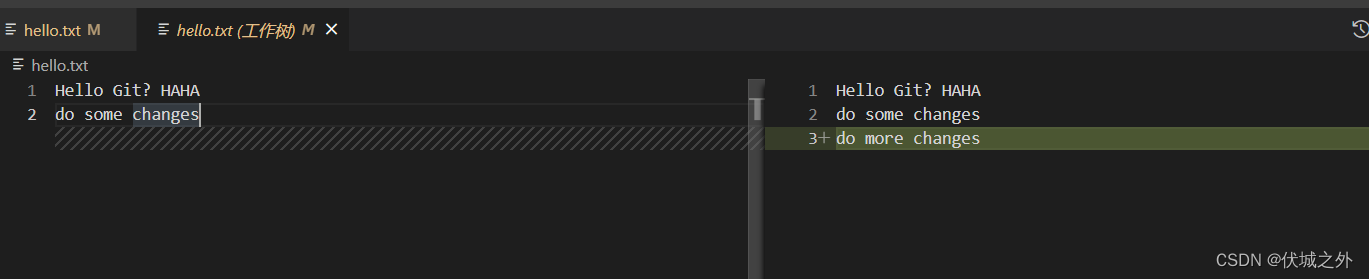
当我们git add后,工作区和缓存区hello.txt保持一致,而缓存区与git仓库将不一致

通过检查blob对象,可以发现cc9e750就是git仓库中的hello.txt,而87eee42就是缓存区中的hello.txt。所以此时-号代表git仓库,+号代表缓存区。
差异对比如前面git diff一样。
远程仓库的添加
首先我们在GitHub上新建一个远程仓库
 然后,GitHub远程仓库会提示我们在本地使用如下命令, 将本地仓库和远程仓库关联。
然后,GitHub远程仓库会提示我们在本地使用如下命令, 将本地仓库和远程仓库关联。
git remote add origin https://github.com/qwx427219/test.git初始化一个本地git仓库(删除.git/hooks/*.sample文件)
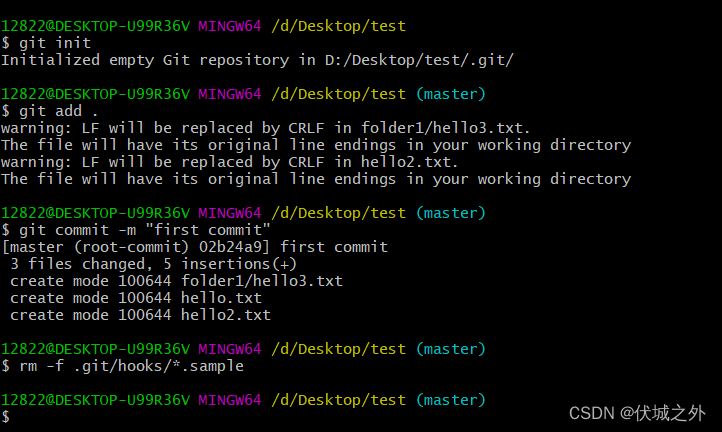
在本地仓库未关联远程仓库前,.git/config文件内容如下:

在本地仓库关联远程仓库后,.git/config文件内容如下:
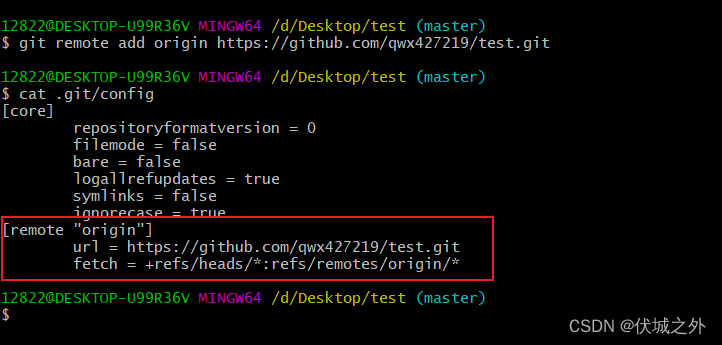
发现,多了一个配置信息[remote "origin"],即远程仓库origin的信息,其中url就是远程仓库origin的地址,这里使用的是HTTPS通道的。
当我们关联好本地仓库和远程仓库后,就需要将本地仓库的代码推送到远程仓库,按照GitHub的提示,使用如下命令:
- git branch -M main
- git push -u origin main
其中 git branch -M的作用是重命名当前工作分支,即将master重命名为main。

之后 git push -u origin main 其实是 git push -u origin main:main的简写。
-u 参数是 --set-upstream 的缩写,意思是设置上传信息
origin 是远程仓库的别名。
第一个main是远程仓库origin的分支名,第二个main是本地仓库的分支名。
整体意思是:将本地仓库的main分支推送到远程仓库origin的main分支。
git push -u origin main只需要在第一次向远程仓库提交时写全,后面再推送,直接写git push即可。
在执行git push之前,本地.git目录如下

而执行完git push之后,.git目录如下

多出了四个文件夹,两个文件。
我们主要关注.git/refs/remotes/origin/main文件
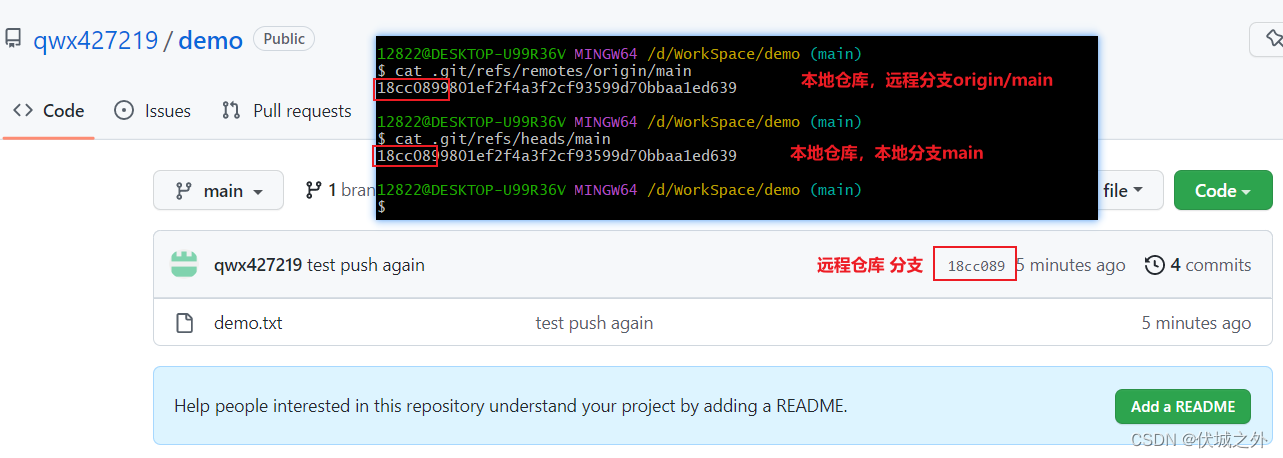
 我们发现 .git/refs/remotes/origin/main 应该就是远程仓库main分支,它指向一个commit对象,并且和本地仓库main分支指向的是统一commit对象。
我们发现 .git/refs/remotes/origin/main 应该就是远程仓库main分支,它指向一个commit对象,并且和本地仓库main分支指向的是统一commit对象。

此时我们刷新GitHub上的远程仓库网页
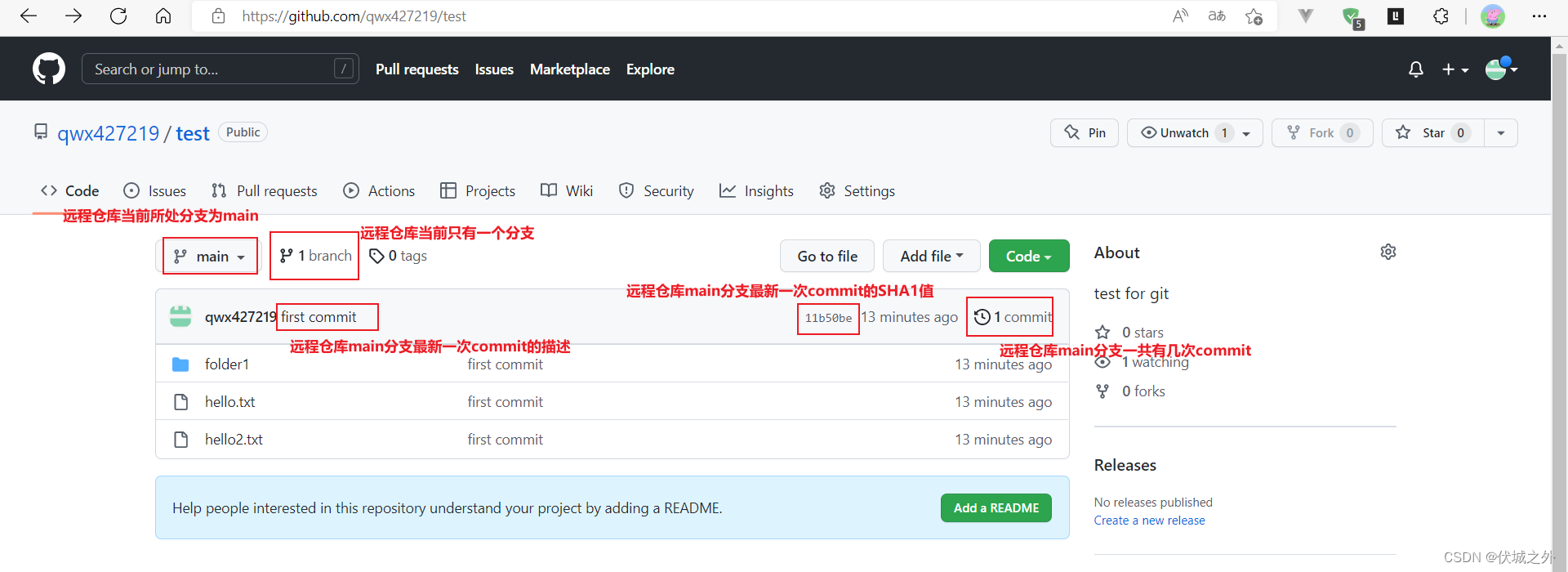

可以发现本地仓库main分支的代码已经被push到了远程仓库
小插曲-关于SHA1算法不安全的问题
我们知道,当前Git中,无论是blob对象,还是tree、commit对象,它们的名字都是一个SHA1算法计算得到的HASH值。
而SHA1算法已经被谷歌测试出来不安全了。谷歌设计出了两个不同的PDF文件,然后基于它们的内容通过SHA1算法计算得出HASH值,发现HASH值一致。
谷歌公告:SHA-1 哈希算法被攻破 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/25411255 这当然给使用SHA1算法计算git objects对象名的Git带来一定冲击。
https://zhuanlan.zhihu.com/p/25411255 这当然给使用SHA1算法计算git objects对象名的Git带来一定冲击。
我们可以分析一下,当我们git add某个文件时,会通过SHA1算法计算出该文件的HASH值,然后作为blob对象的名字。
如果存在另一个不同的文件,但是通过SHA1算法可以得到一个相同的HASH值,那么会发生什么情况呢?
则我们添加另一个特殊文件时,会通过SHA1算法计算出其HASH值,对比.git/index发现,已经存在了该HASH值对应的blob对象,则Git会错误地判断这个特殊文件不是一个Untracked状态,而是一个new file状态。
奇客Solidot | Linus Torvalds 回应 SHA-1 碰撞攻击![]() https://www.solidot.org/story?sid=51483
https://www.solidot.org/story?sid=51483
但是实际上,谷歌是通过大量算力才得出了两个巧合的PDF文件,且它们的HASH值是基于它们的内容生成的。而Git计算HASH值时,基于的是 :"blob" + " " + 文件大小 + "\0" + 文件内容
这种形式的内容的碰撞出两个巧合文件的难度将更大。
git对象的压缩
我们知道git的blob对象不是直接将 文件内容 作为自身的数据,而是将文件内容压缩后 作为自身的数据。

对于大体积的文本数据,压缩是一种有效减小其内存占用的手段。
如下例所示,原始大小4M的文件,被转为blob对象后,压缩为了2.7M

我们需要思考这样一种场景:
我们在base64.txt中新增了一点点内容,然后git add,再git commit,此时.git/objects中会新增一个commit对象,一个tree对象,一个blob对象,然后重复这个动作多次
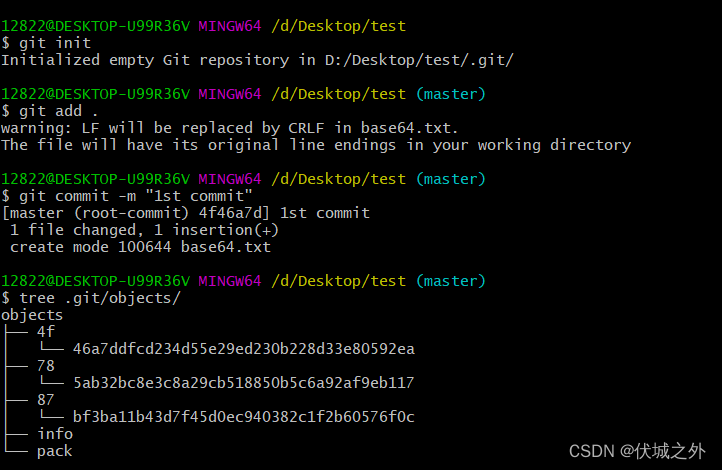
如上,是初始化仓库,并提交一个base.txt文件

修改base64.txt,之提交修改2nd,发现新增了commit对象1个,tree对象1个,blob对象1个
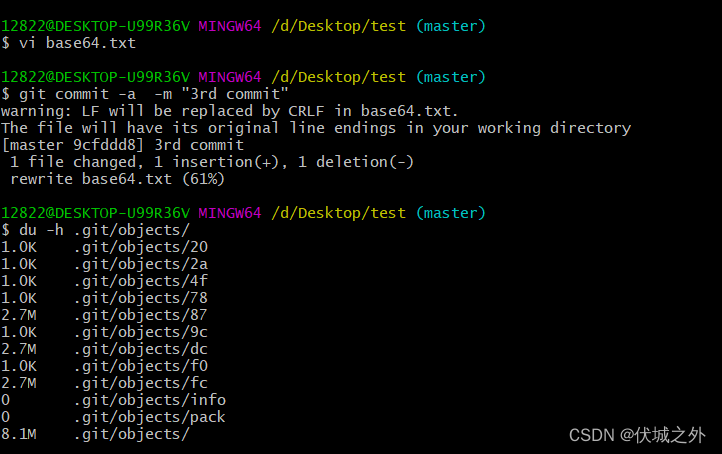
继续修改base64.txt,之提交修改3rd,发现又新增了commit对象1个,tree对象1个,blob对象1个
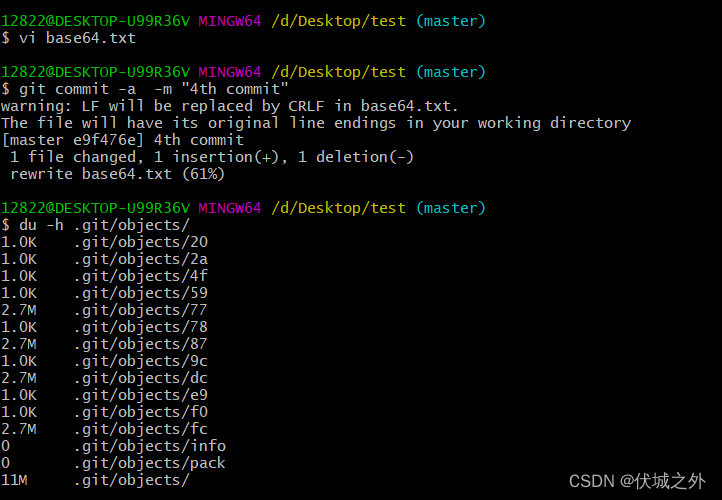
继续修改base64.txt,之提交修改4th,发现又新增了commit对象1个,tree对象1个,blob对象1个
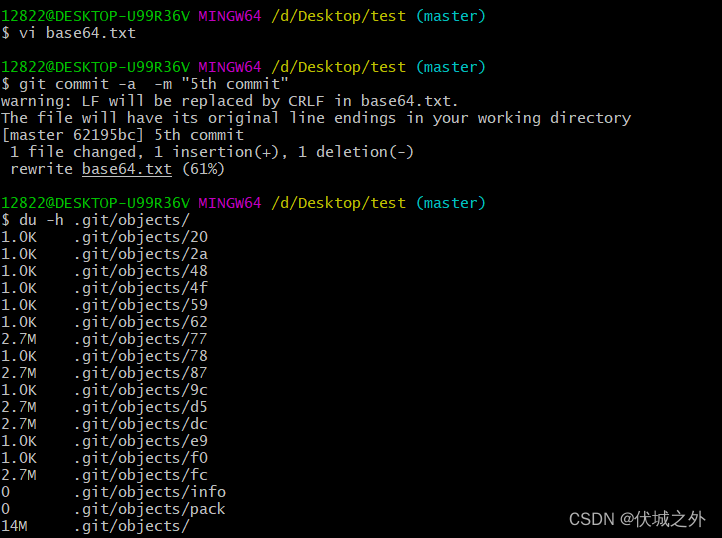
继续修改base64.txt,之提交修改5th,发现又新增了commit对象1个,tree对象1个,blob对象1个此时.git/objects的大小已经达到14M,而这14M其实都是存储的一个文件信息base64.txt。
每次修改后,git add生成的blob对象其实差异不大,大部分内容都是相同的。所以存在一定的内存浪费,此时我们如果将第一次blob对象记录下,后面git add的blob对象只保留相较于上一次的差异,这样将大大节省内存,而这种方式其实就是SVN的策略。
Git针对这种情况也引入了差异比较的策略,即放弃存储快照,而是记录差异,此时使用命令git gc,可以实现差异记录

发现,.git/objects只剩2.7M了,几乎就是原文件大小。而.git/objects下的commit对象,tree对象,blob对象都不见了,全部被压缩进了.git/objects/pack中
我们可以进入pack目录检查

只有两个文件,分别idx类型文件,和pack类型文件。
其中idx类型文件是索引文件,我们可以通过命令来查看.idx文件内容
git verify-pack -v
发现它记录了之前存储在 .git/object中的 commit对象、tree对象、以及blob对象的文件名和大小。
我们发现其中记录的blob对象存在一些猫腻

d5fe214c9ed88c12949a74f58cd96de4b3bf1114这个blob非常大,而其余的blob非常小,并且其余的blob都指向了d5fe214c9ed88c12949a74f58cd96de4b3bf1114这个blob。
我们检查下这个d5fe214c9ed88c12949a74f58cd96de4b3bf1114对象,发现

这个文件记录的是最后一次commit对应的blob对象,所以理论上,其余blob应该只记录的是和最新blob的差异
当我们需要访问某个blob内容时,比如就将当前blob记录的差异和d5fe214c9ed88c12949a74f58cd96de4b3bf1114的内容进行合并,然后就得到了我们需要的blob。

通过这种记录差异的方式可以高效的存储一个文件多次修改提交后产生多个blob文件,减少其内存占用,这样有利于 在git push本地代码到远程仓库,或者从远程仓库 git clone时的速度提升。
但是也带来了另一个问题,就是每次访问blob对象时,其实都是实时通过差异合入,形成一个具体的内容,这带来了运算压力,也给用户使用blob对象带来一定延迟,所以如果我们追求快速访问的话,可以将pack解压缩,重新变为多个blob对象。
此时可以使用git unpack-objects命令来解压pack文件,我们可以使用git help unpack-objects来学习unpack命令用法git-unpack-objects(1)
git unpack-objects接收一个标准输入,所以我们需要 git unpack-objects < xxx.pack
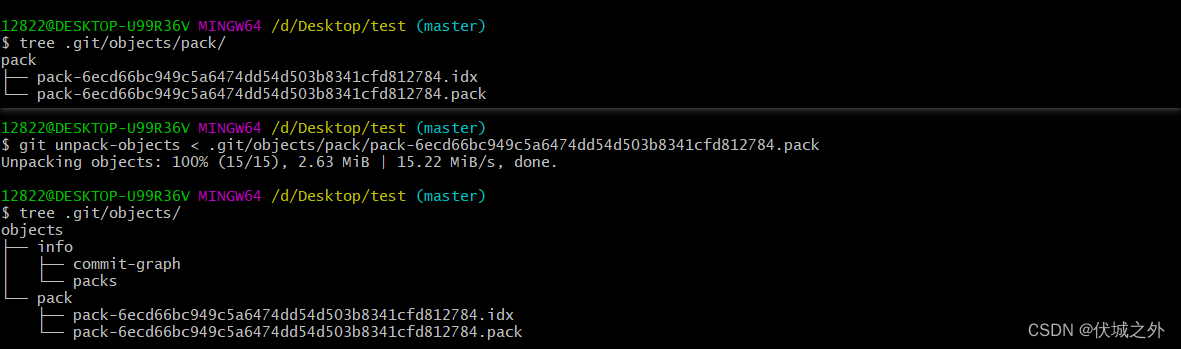
但是执行完
git unpack-objects < .git/objects/pack/pack-6ecd66bc949c5a6474dd54d503b8341cfd812784.pack发现,并.git/objects目录下并没有产生对象。
那是因为,如果.git/objects/pack下已经有pack文件了,则Git认为不需要将其解压为git对象。
所以,我们需要将位于.git/objects/pack下的pack文件移动到其他地方
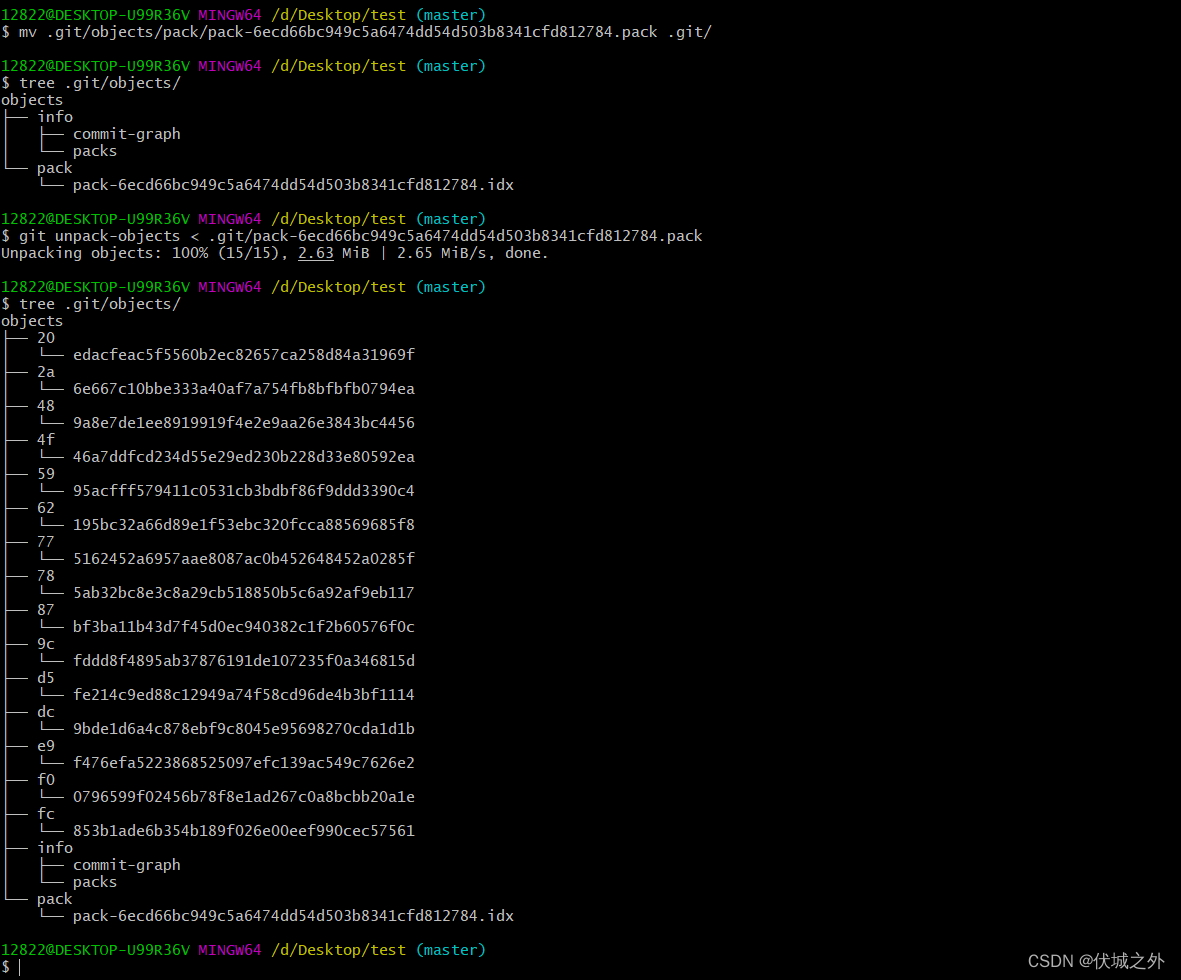
此时在解压pack文件,就可以解压成功了

git垃圾对象的清理
在.git/objects中有两种类型的垃圾对象:
- 没有被tree引用的blob对象
- 没有被brach引用的commit、tree、blob对象
对于第一种情况,我们修改一个文件后git add,得到一个blob对象,此时我们不git commit,而是继续修改文件,然后继续git add,此时又得到一个blob对象,然后进行git commit,则一开始的blob对象变成了垃圾。

此时使用git gc是无法删除这个没有tree指向的blob垃圾对象的

git gc只是将其余非垃圾的commit,tree,blob压缩到了pack文件中。
那么我们如何删除垃圾blob对象呢?
此时我们需要使用 git purne命令 git-prune(1)
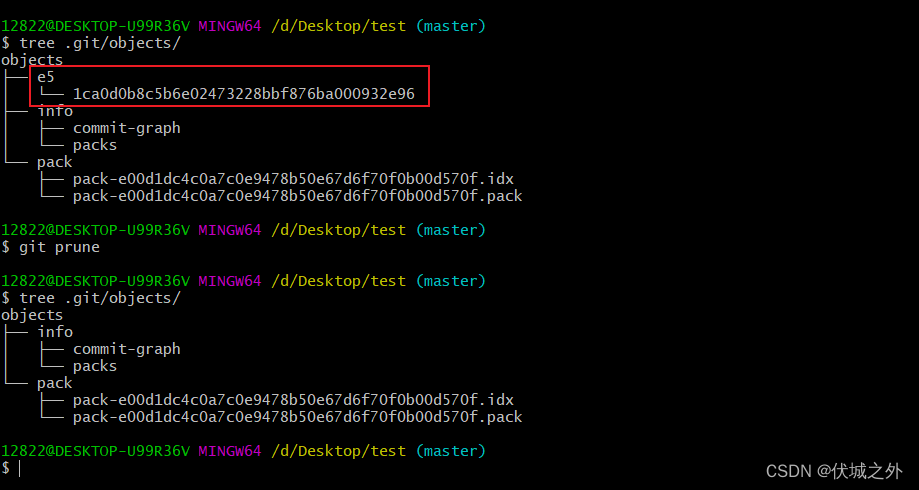
对于第二种情况,场景是这样的,我们创建了一个新分支,并在新分支上开发了一些代码,然后提交了修改到该分支上。但是后面,又发现这个新分支用不到,所以就把新分支删除了,此时虽然分支被删除,但是分支对应commit对象将被保留,同时commit对象引用的tree、blob对象也将被保留。但是此时它们应该被视为垃圾对象。
此时使用git prune是无法删除这种垃圾对象的。

初始化git仓库,并在master分支上新建一个commit。
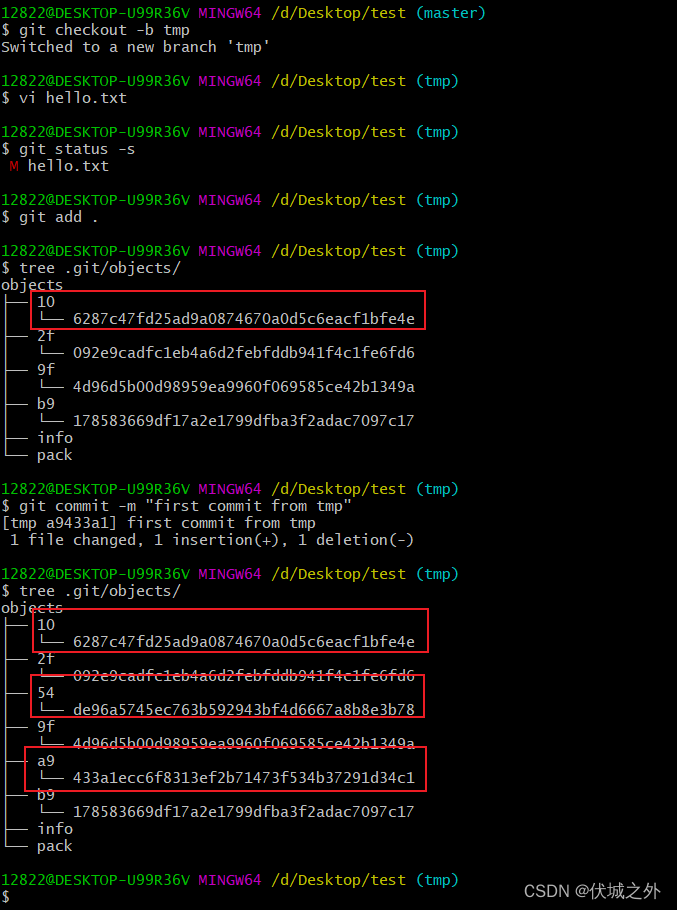
新建分支tmp,并切换到tmp上修改hello.txt,并提交修改。此时.git/objects中将新增三个对象。
 在tmp分支未合入master前,强制删除tmp分支,但是tmp分支对应的三个对象却被保留下来,它们应该被视为垃圾对象。
在tmp分支未合入master前,强制删除tmp分支,但是tmp分支对应的三个对象却被保留下来,它们应该被视为垃圾对象。
此时无论使用,git gc还是git prune都无法删除它们。

对于这种对象的删除,我们可以参考
- git -c gc.reflogExpire=0 -c gc.reflogExpireUnreachable=0 \
- -c gc.rerereresolved=0 -c gc.rerereunresolved=0 \
- -c gc.pruneExpire=now gc "$@"

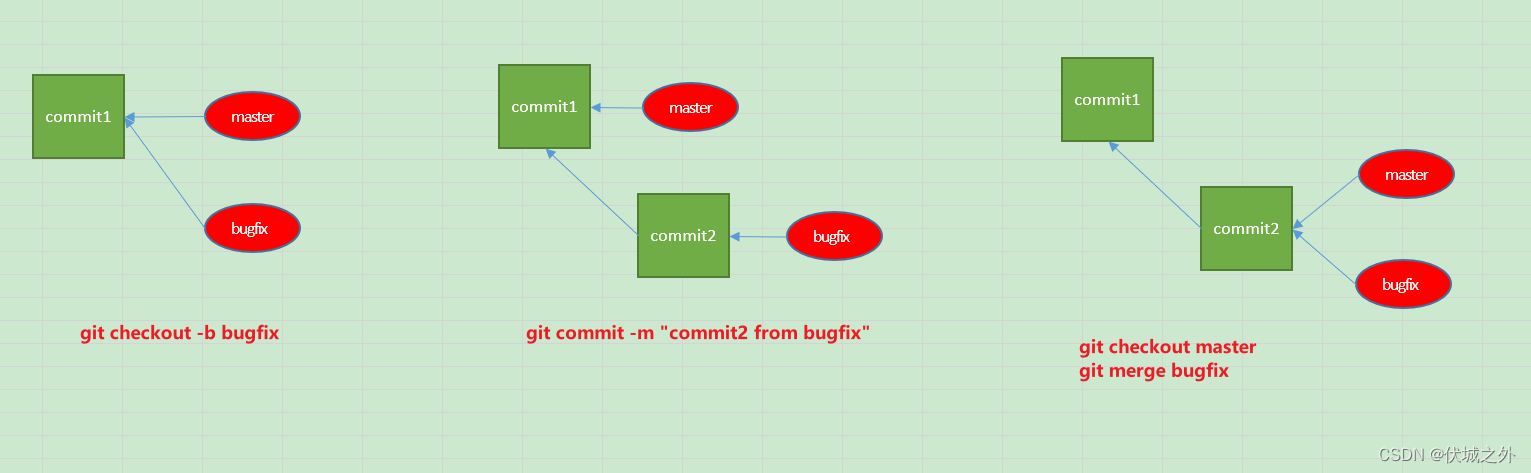
git merge - fast forwar

初始化一个git仓库,并且在master分支上提交hello.txt到仓库。最终得到如下视图:
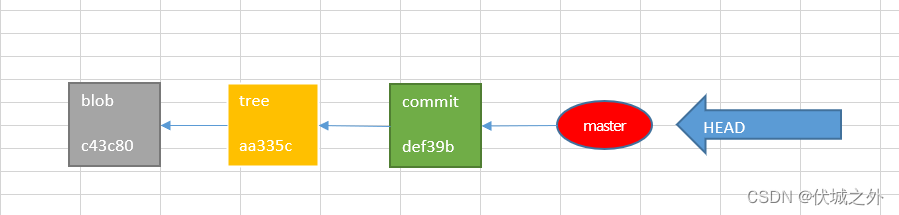
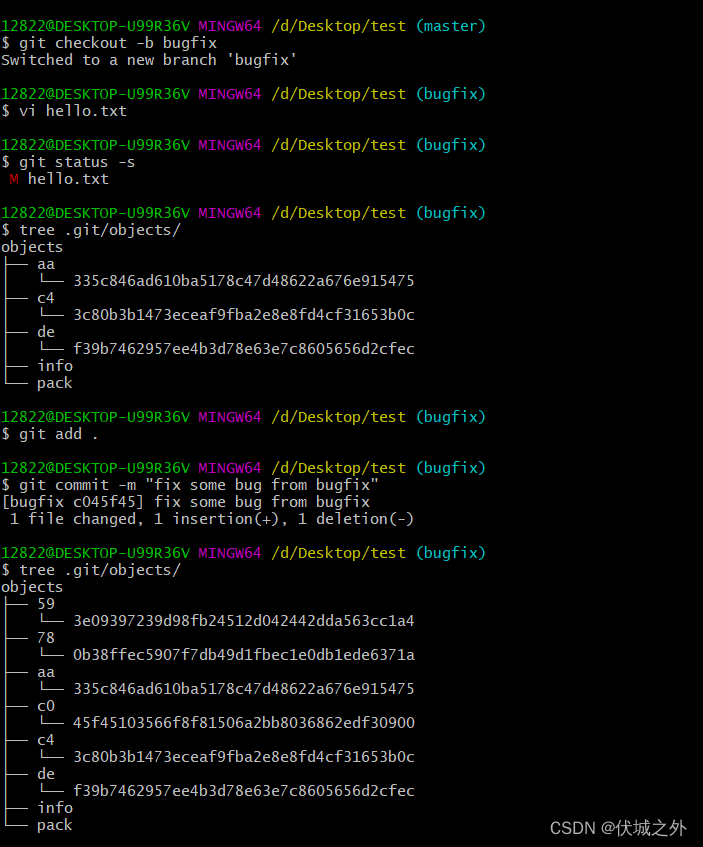
创建并切换到新分支bugfix,然后修改hello.txt,并提交

则得到如下视图

此时.git目录结构如下

当我们切换回master分支,并执行git merge bugfix后
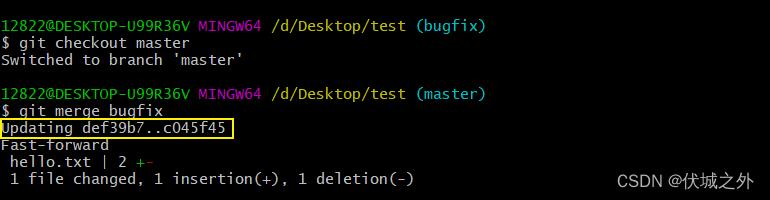
这里Updating def39b7..c045f45的意思是,将master分支的指针从def39b7转移到c045f45

而这种直接了当地通过转移master指针指向,来实现将bugfix分支代码合入master分支的方式,称为fast-forward。
这种合入方式速度很快,但是非常容易出现问题,所以Git提供了一个回退master合入操作的方式。
当我们git merge后,Git会在.git目录结构中新产生一个ORIG_HEAD文件


它指向了合入操作前的master分支指向的commit对象
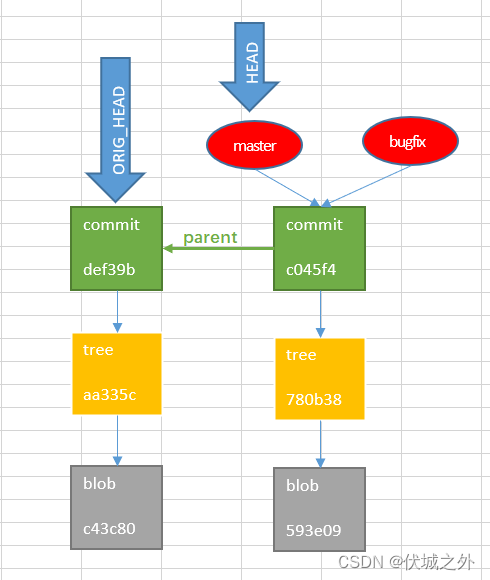
我们可以使用 git reset ORIG_HEAD 来实现master分支的合入撤销

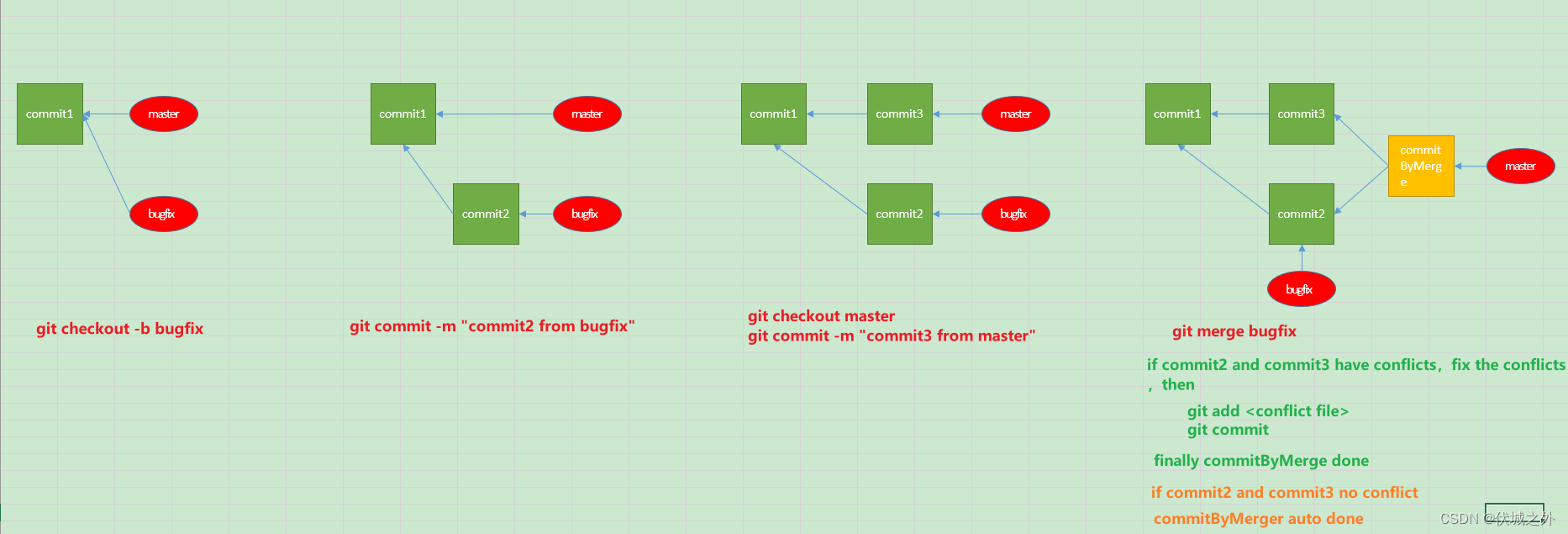
git merge - 3 way merge
我们合并分支代码到主干时,还可能遇到一种情况,那就是此时主干代码也发生了更新。

初始化仓库,并在master提交一次更新。

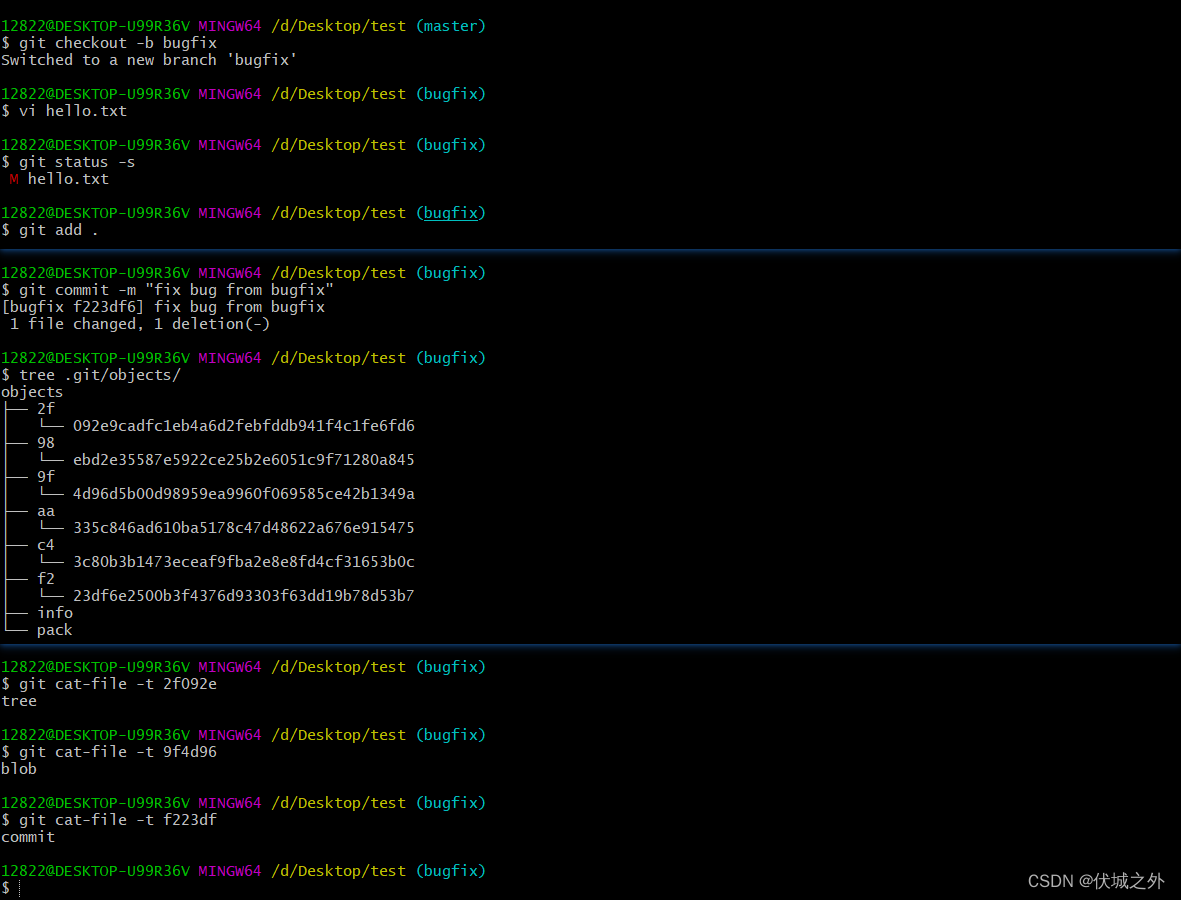
新建bugfix分支,并切换到该分支,然后在该分支上提交一次更新


再切换回master分支,并在master分支上进行一次修改(不与bugfix分支修改冲突)
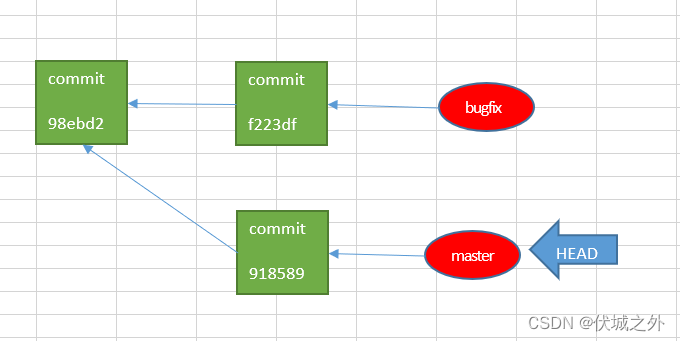
那么此时将bugfix分支代码合入master会发生什么呢?还会是fast forward那样直接将master指向指向bugfix指向的commit吗?显然不应该是这样,因为这样master的second commit就会丢失。
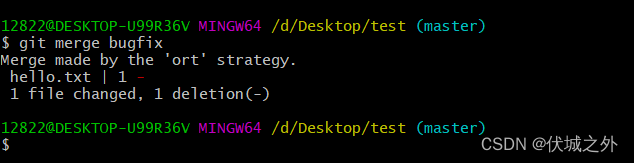
在master分支执行git merger bugfix后,进入如下vim编辑界面

该界面意思是,请输入commit message解释为啥此次merger是必须的。也就是说这个vim界面的输入会作为一次commit的message信息。
当我们确认默认message信息后,:wq推出vim编辑,即执行完git merger bugfix
我们从git log中检查下master是否真的多了一次commit
 发现master上确实多了一次commit。
发现master上确实多了一次commit。
我们检查下多出来的这个commit,发现它有两个parent,且分别是bugfix分支的最后一次commit,和master分支ORIG_HEAD

所以本次git merge后,示意图如下,另外我们也可以通过git log --graph打印出二维图
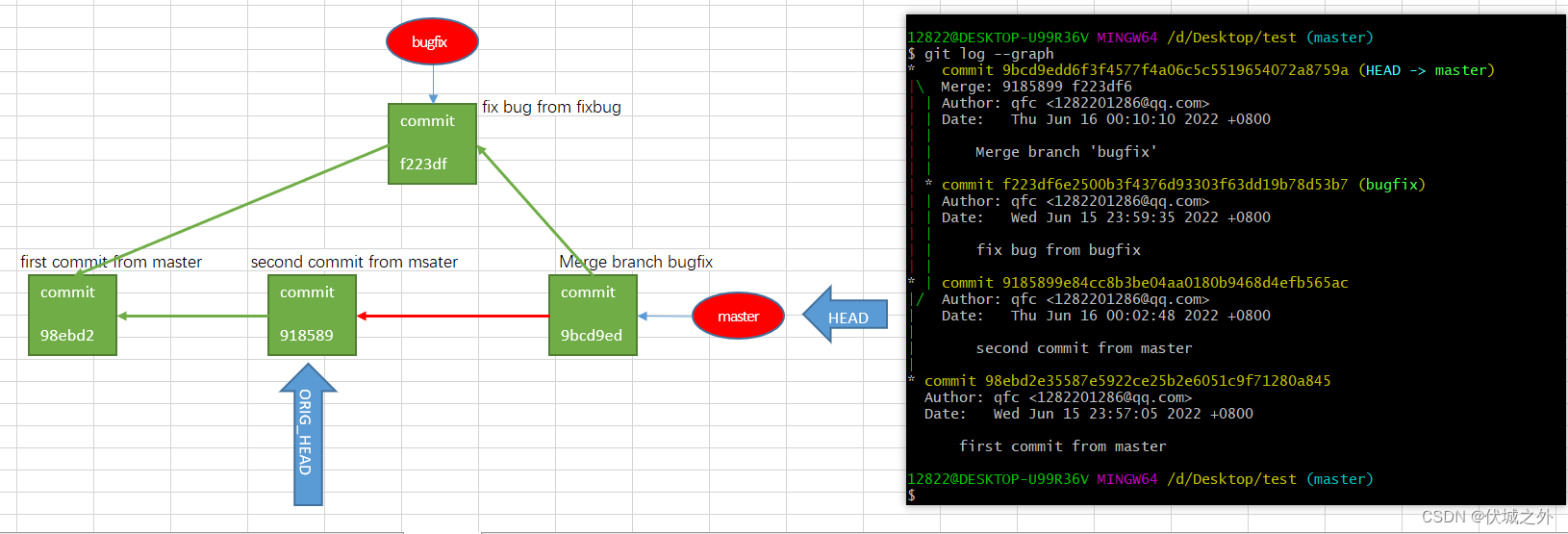 其中红色线commit是git merge后,Git自动完成的,绿色线commit是我们手动git commit完成的。
其中红色线commit是git merge后,Git自动完成的,绿色线commit是我们手动git commit完成的。
对于git merge后自动产生的commit,并且该commit对象的parent有两个的情况,我们称为 3 way merge。
git merge - 3 way merge with conflict
如果我们从主干创建了一个bugfix分支修改了hello.txt,而同时刻其他人也从主干创建了一个分支并同样修改了hello.txt,并且先于bugfix分支合入了主干,此时bugfix合入主干就会产生冲突。
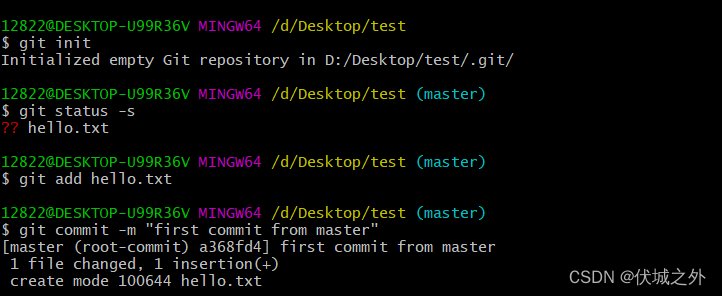
初始化仓库,并提交hello.txt到master分支。

创建并切换到新分支bugfix,并修改hello.txt后提交。
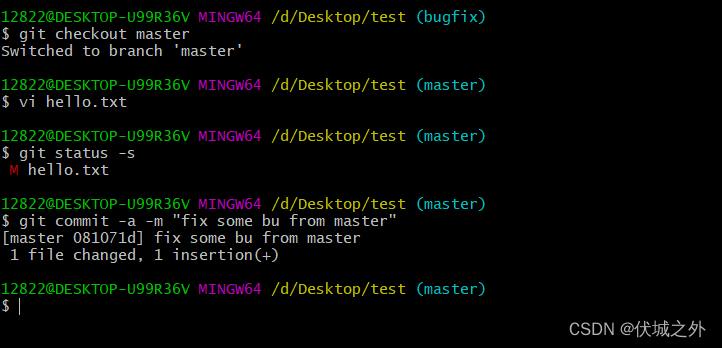
切换回master分支,但是不选择立即合入bugfix,而是先修改hello.txt,并提交到master。
此时示意图如下
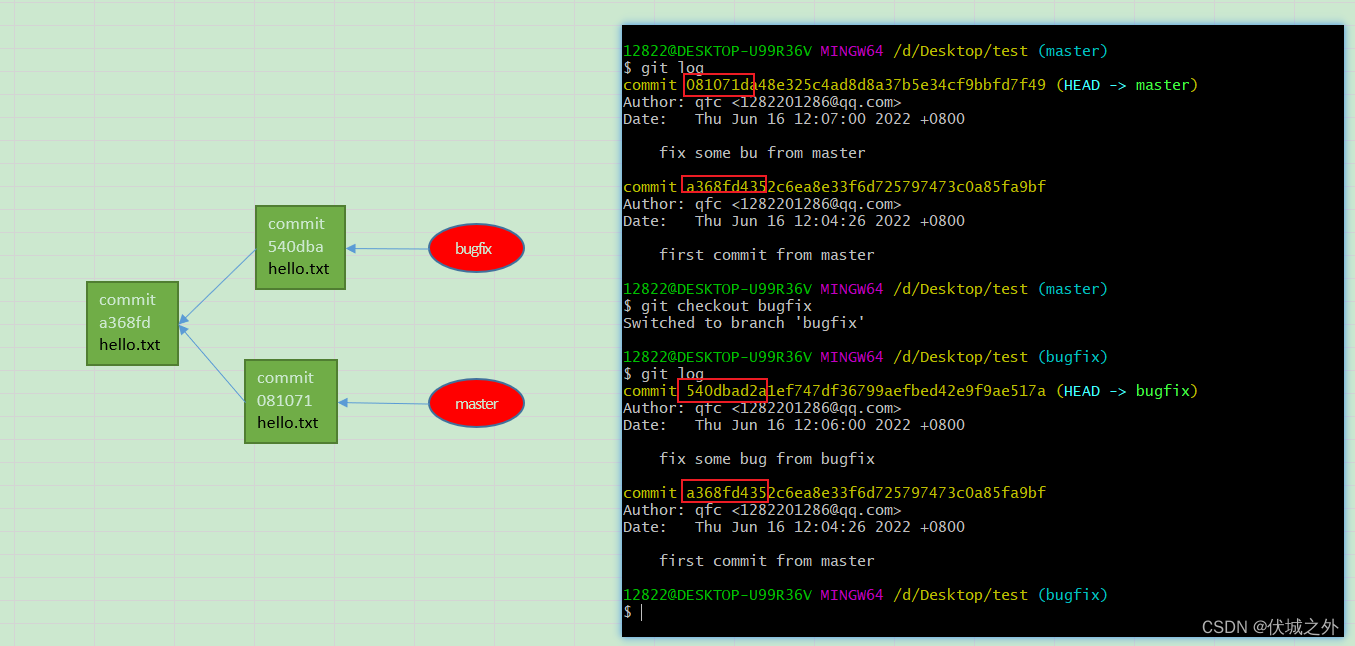 注意此时master分支的缓存区索引只有1个
注意此时master分支的缓存区索引只有1个

而bugfix分支的缓存区索引也只有一个

当我在master分支上尝试合入bufix时,提示合入失败,原因是:在hello.txt中存在一个合入冲突,我们需要解决冲突然后才能提交结果。

此时我们查看master分支缓存区索引,发现有三个索引,三个hello.txt,而实际上应该只有一个hello.txt

我们再查看master分支工作区的hello.txt内容,发现它的内容其实就是上面三个索引指向的hello.txt内容的合并。
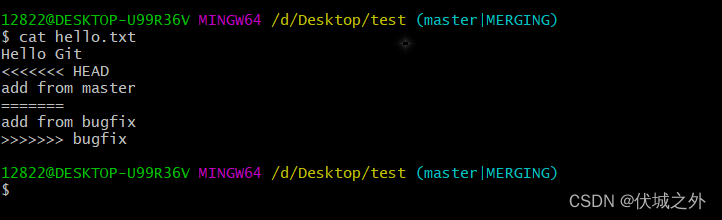
此时我们需要处理上面内容,一般我们可以借助IDE工具处理,如VSCode

VSCode对于冲突的处理有四个选择:
Accept Current Change:保留当前分支(master)的修改,去除合入分支(bugfix)的修改
Accept Incoming Change:保留合入分支(bugfix)的修改,去除当前分支(master)的修改
Accept Both Change:两个修改都保留
Compare Changes:对比两个修改,然后自定义选择保留哪个修改
比如,我们下选择Accept Both Change,
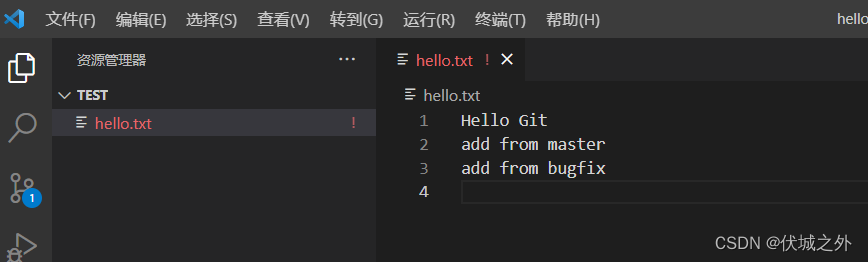
然后git status检查状态

当我们解决conflict后,可以需要先运行git add <file>,然后“git commit”提交修改

此时进入一个vim编辑窗口,提示我们输入commit message
输入完后,我们检查git log,发现master上多了一次commit,该commit是合并了 081071d 540dbad这俩次commit



git rebase
fast-forward-merge
3-way-merger
对比发现,fast-forward-merge最终master分支的提交记录是线性的,而3-way-merge最终master分支的提交记录是分叉的。
很明显,线性的提交记录更容易让人理解,不会混乱。那么有没有办法,让3-way-merge变成线性提交记录呢?
我们可以将bugfix分支的commit分为两部分:
- 在master分支上执行git branch bugfix时,继承自master的commit。
- bugfix分支自己提交的commit。
想要git merge时,实现fast-forward模式,则bugfix分支上的commit要包含master分支上的commit。

如果不能包含,则说明master分支在合入bugfix分支前,又产生了新的commit,造成了bugfix分支无法包含master分支新增的commit
此时我们只要让bugfix分支的commit包含进master分支新增的commit,即可进行fast-forward-merge。
Git提供了git rebase <branch_name>命令(在bugfix分支中执行git rebase master)来实现更新某分支(如bugfix)继承自另一分支(如master)的commit。
我们设计了如下实际案例,来进一步说明git rebase命令的使用。
当前项目中有一个hello.txt文件,其中有两处bug,分别是bug1,bug2

bug1是小明搞出来的,小明会从master分支上拉一个bugfix1分支解决

bug2是小红搞出来的,小红也会从master分支上拉一个bugfix2分支解决
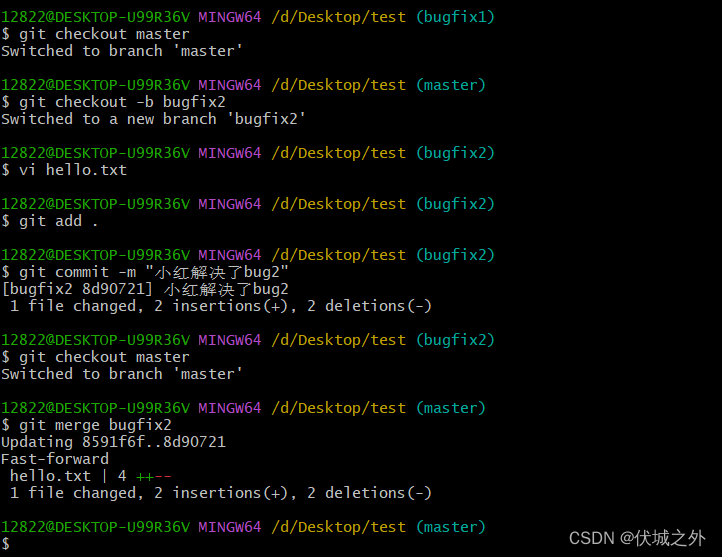
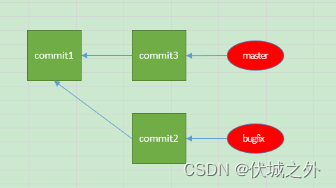
并且小红修复完bug2后,立马就将bugfix2分支的代码合入了master,此时master的hello.txt如下

对于小红来说,它的合入是fast-forward-merge。
此时压力来到了小明这边,它合入bugfix1到master必然会产生冲突,如果选择直接git merge的话,则会破坏master分支的线性commit记录。所以小明选择在bugfix2分支上进行git rebase master,来更新bugfix2继承自master的commit。

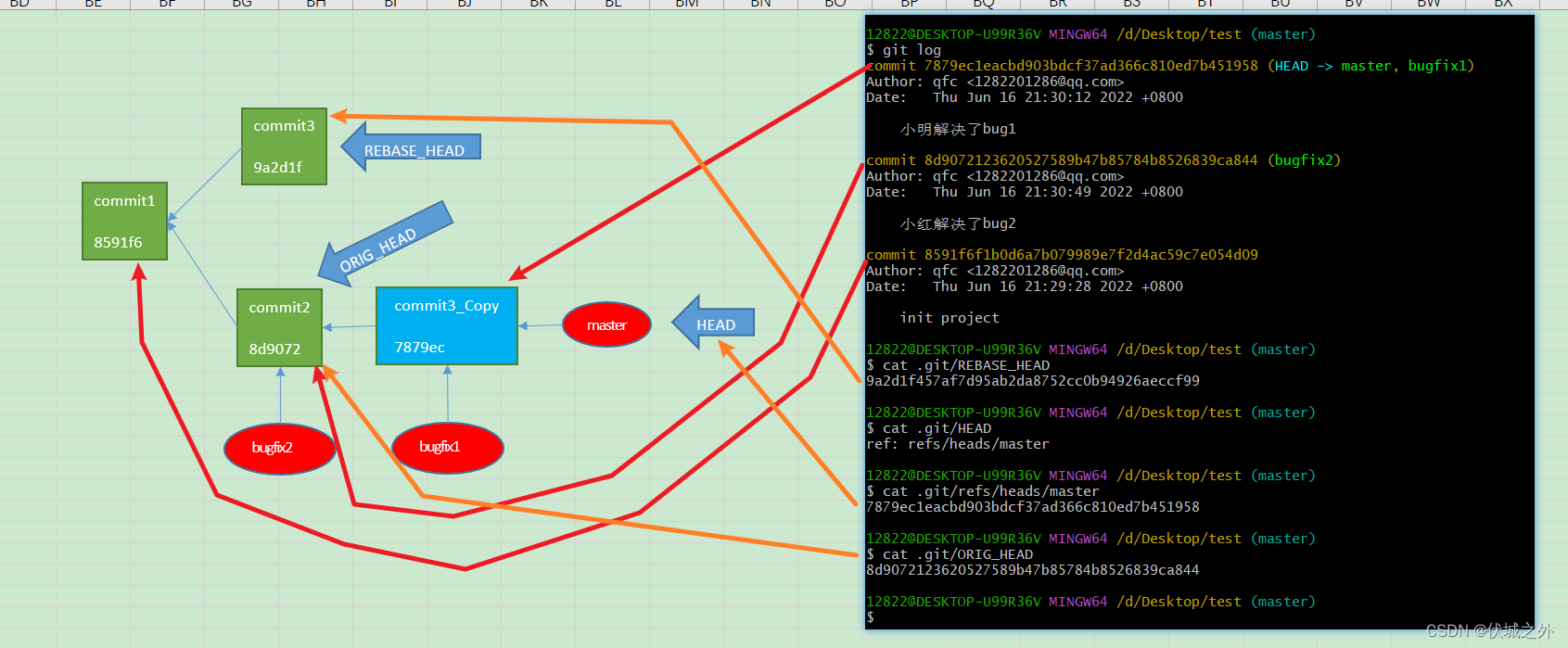
此时 git rebase报错,说hello.txt存在一个冲突,需要小明手动解决这个冲突,然后git add 冲突文件,之后再git rebase --continue。
对比冲突修改,发现很奇怪,冲突点并不是 bug2 和 fixed bug2,而是多了一行Hello Git
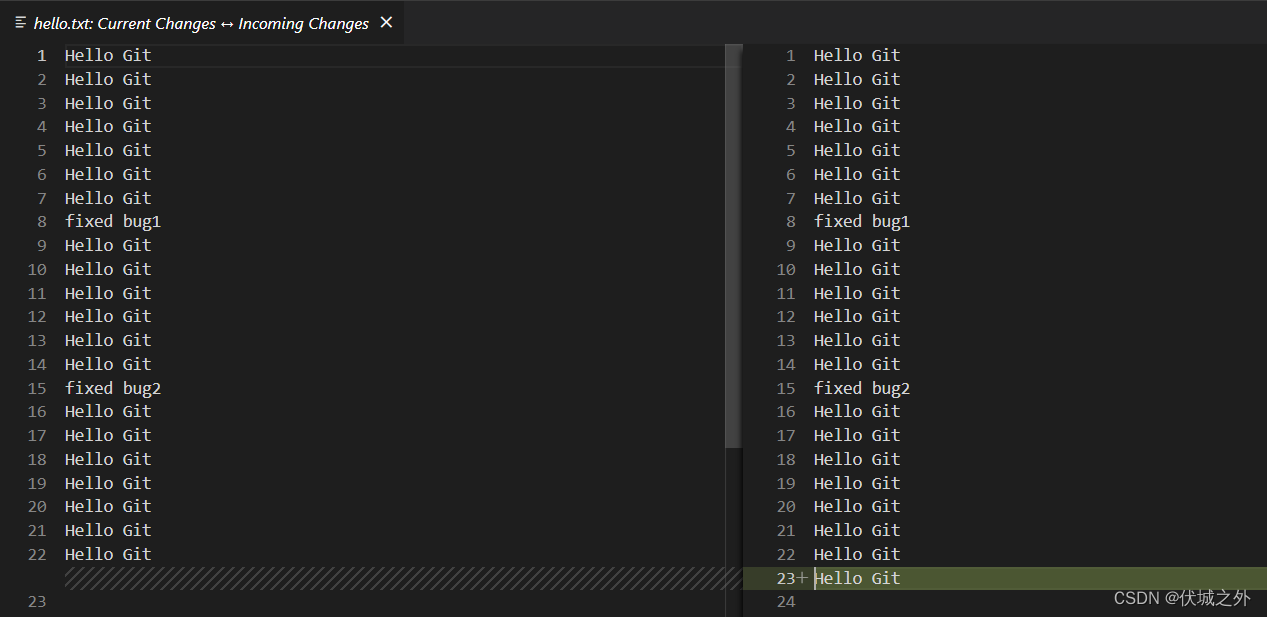
另外当前的工作分支也很奇怪,叫 bugfix1|REBASE 1/1,感觉是一个临时分支

虽然很奇怪,但是我们只要修改冲突,变成我们希望的既可以了
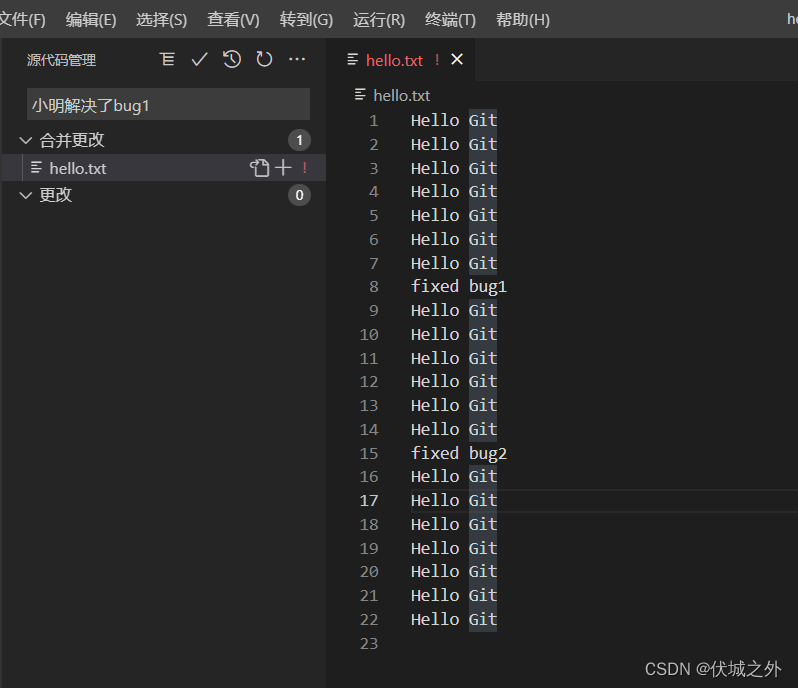
修改完冲突后,进行git add冲突文件,再git rebase --continue

另外需要注意的是,此时,bugfix1的自己的commit已经更新了commit的HASH值名字
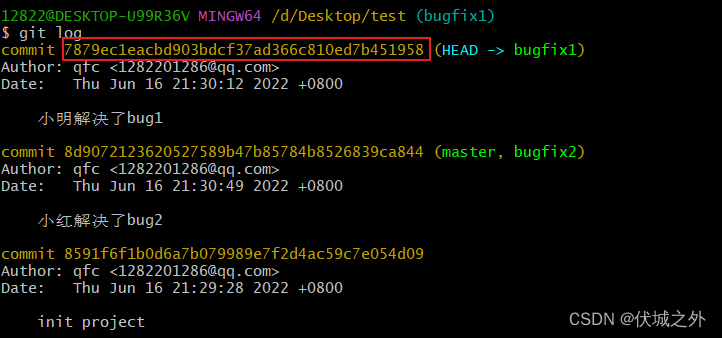
rebase之前的bugfix1自己的commit的名字缓存在了.git/REBASE_HEAD中

确认git rebase无误后,切到master分支,进行git merge bugfix1

可以发现,此时将bugfix1合入master,已经是fast-forward模式了。并且commit记录中,不会包含已经被覆盖的bugfix的commit。
流程示意图如下




git rebase的作用仅仅是让分支提交记录呈现线性,使之相较于3-way-merge形成的交叉形提交记录更加清晰,但是我们需要慎用git rebase,因为他会更改提交记录。
如果上面例子中,bugfix1是一个公共分支,大家都在用,则小明进行rebase后,会影响所有使用bugfix1分支的人的提交记录。
git tag
git tag的作用是给所在分支上的某个commit打tag,tag内容一般是版本信息,如v1.0.0这种。
| 创建tag | git tag <tag_name> | 为了所在分支的最新的commit打上tag |
| git tag -a <tag_name> -m <tag_message> | 为了所在分支的最新的commit打上tag,并设置tag message,和git commit -m 的效果差不多 | |
| git tag -a <tag_name> <commit_SHA1_value> | 为所在分支的指定commit,打上tag | |
| 查看tag | git tag | 查看tag |
| 删除tag | git tag -d <tag_name> | 删除指定名字的tag |
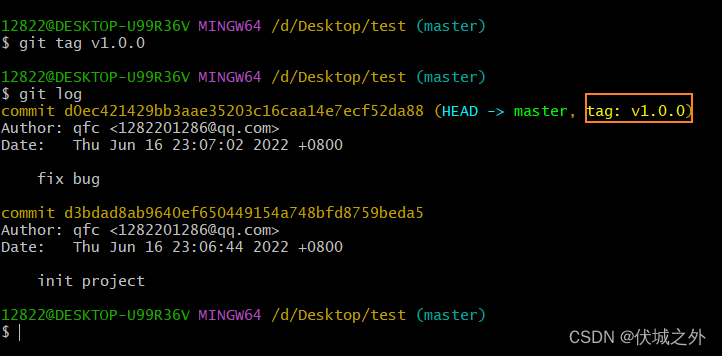
初始化一个git仓库,并提交两次代码

git tag v1.0.0 会给所在分支的最新commit打上tag

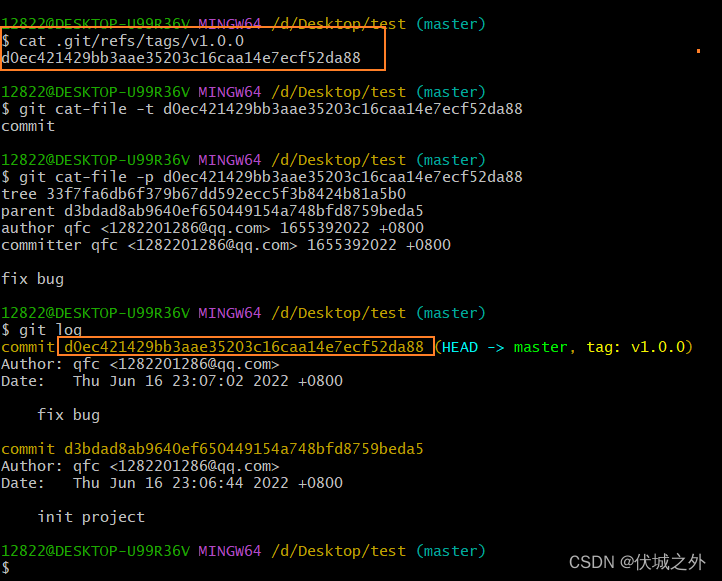
tag的本质是一个指向commit对象的指针.git/refs/tags/v1.0.0
git tag -d v1.0.0
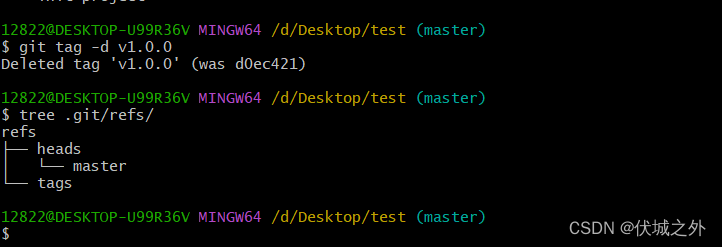
删除tag,其实就是删除.git/refs/tags中的tag指针
git tag -a v1.0.0 -m "打了一个tag v1.0.0"

此时不仅多了一个tag指针,而且还多了一个tag对象

tag对象中内容描述了 tag对应commit对象,以及tag名字,tag创作人,tag message。
git tag -a <tag_name> <commit_SHA1_value>

可以给指定的commit打上tag
此时也会产生tag对象

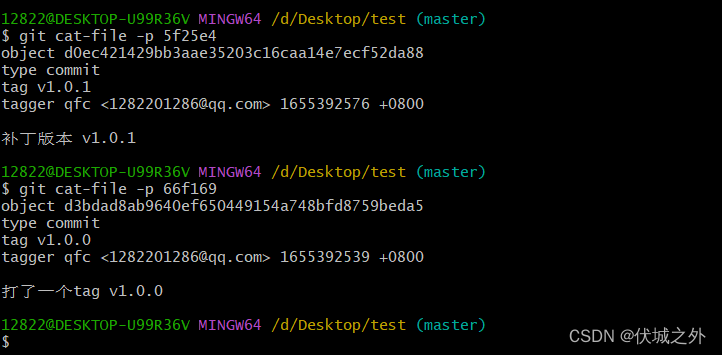
另外需要注意的是,git tag -d 只删除 .git/refs/tags中的指针,而不会删除.git/objects中的tag对象

此时可以借助git prune命令删除哪些空悬的object

tag和branch很类似,我们git branch <branch_name>会创建一个指针指向commit对象,而git tag <tag_name>也是如此。
但是branch总是指向最新的commit,而tag可以指向指定的commit。
branch更多的是一种线性,是多个commit
tag只是点性,是单个commit。
本地分支和远程分支
我们知道在本地创建一个git仓库的方式有两种:
- git init 初始化一个本地仓库
- git clone 克隆一个远程仓库为本地仓库
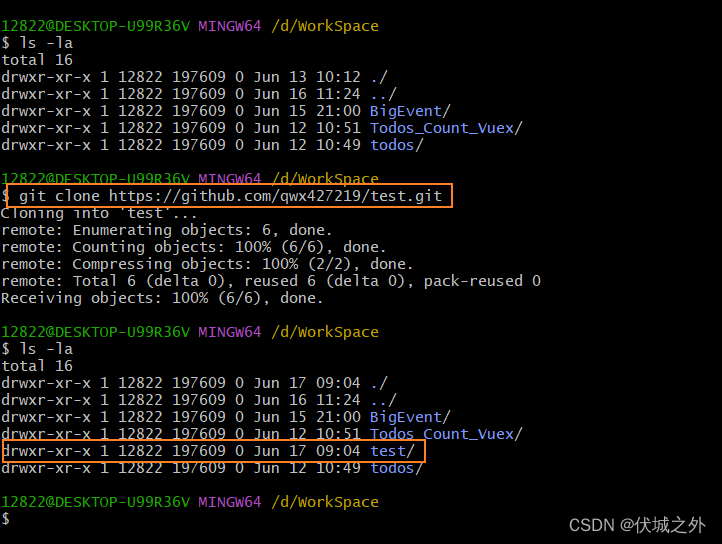
而当我们git clone一个远程仓库为本地仓库后,在本地仓库中就会出现两种分支:
- git clone命令会自动为我们创建一个本地仓库的分支main,简称本地分支 main

- 检查git log可以发现,还有克隆自远程仓库的分支origin/main,简称远程分支 origin/main

我们可以通过git branch -r 命令来查看本地仓库中克隆自远程仓库的所有分支

或者通过git branch -a 命令查看本地仓库的所有分支(包括本地分支和远程分支)

其实无论是本地分支,还是远程分支,其实本质都是本地仓库上的分支。远程分支并非真实的远程仓库上的分支,而是远程仓库上分支的拷贝。
检查本地仓库.git目录

可以发现.git/refs/remotes下有远程仓库origin,并且有一个HEAD指针,该HEAD指针指向了远程分支origin/main,但是.git/refs/remotes/origin下面并没有main分支信息。
原因是,远程仓库会在本地git clone请求发生时,会将远程分支信息全部压缩存储到.git/packed-refs文件中,以加快传输速度。
如果本地仓库需要使用远程分支origin/main,会先去.git/refs/remotes/origin/main中找,如果没有则去.git/packed-refs文件中找

检查发现.git/packed-refs中存储的确实是origin/main远程分支信息。
如果此时,远程仓库上origin/main分支发生了新的提交,则本地仓库上的origin/main分支不会实时更新的。

 注意此时,远程仓库上的main分支已经指向了新的commit:189e762
注意此时,远程仓库上的main分支已经指向了新的commit:189e762
我们再来查看本地仓库的远程分支origin/main指向的commit
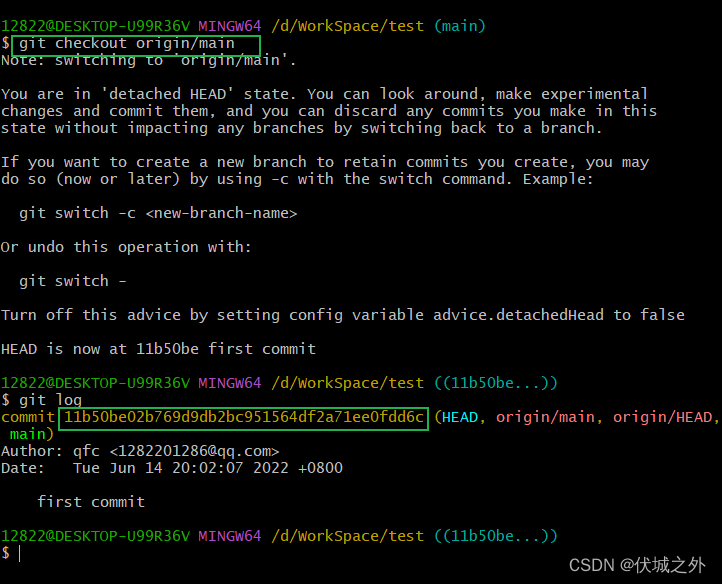
我们切换到远程分支origin/main,发现其commit还是11b50be,而不是最新的189e762。
这其实说明了本地仓库的远程分支origin/main其实并非真实的远程仓库上分支,而只是我们git clone远程仓库,对应时刻远程仓库main分支的拷贝。
git remote
我们可以通过git remote相关命令来查看远程仓库的一些信息
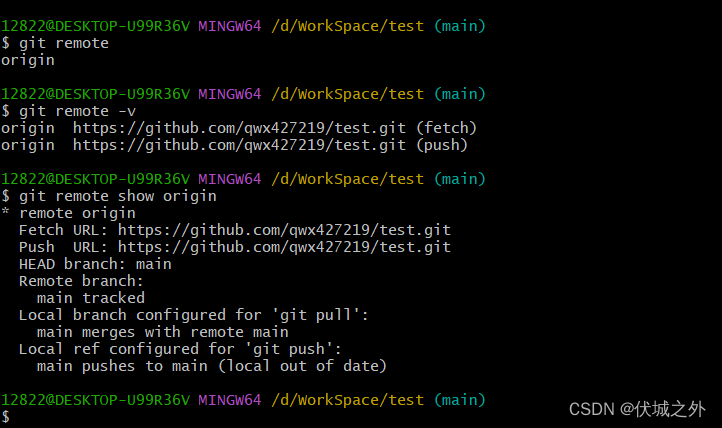
git remote 远程仓库的名字
git remote -v 远程仓库的地址
git remote show origin 通过联网,实时查看远程仓库的信息(如:地址,远程仓库的分支跟踪情况)

如上图的意思就是,远程仓库的main分支已被当前本地仓库跟踪。
更新远程分支 git fetch
当远程仓库的分支,如main,发生新的提交时,本地仓库的远程分支origin/main是无法自动跟随更新的,此时我们需要借助git fetch命令来手动将远程仓库的main分支 更新到 本地仓库的远程分支origin/main

这里意思是,远程仓库的main分支的最新commit 189e762更新到了本地仓库的远程分支origin/main上。
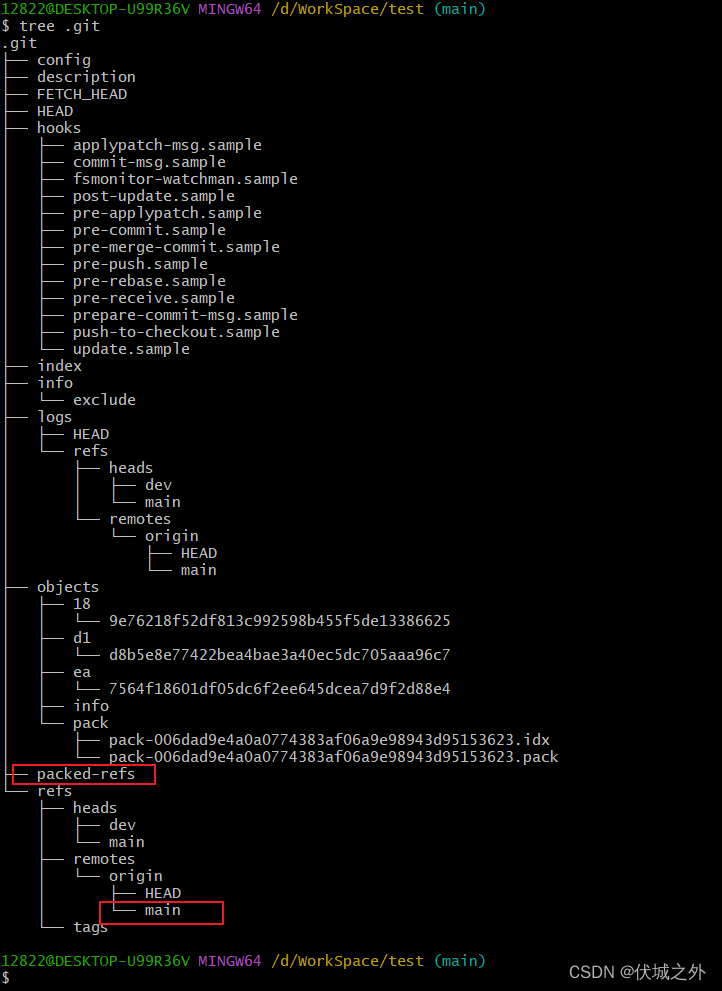
此时,git fetch的更新的main分支的信息会保存在本地仓库的.git/refs/remotes/main中,而不是压缩进.git/packed-refs中。

合入远程分支到本地分支
我们需要理解本地仓库的远程分支,如origin/main,他虽然实际上可以当作本地仓库的一个本地分支,但是我们并不能基于它进行开发,因为它相当于一个桥梁,远程分支,总是用于接收远程仓库对应分支的更新,总是用于将更新后的内容合入本地分支。
我们知道 本地分支main 是和 远程分支origin/main关联的,那么远程分支通过git fetch发生了更新,关联的本地分支main也会同步更新吗?
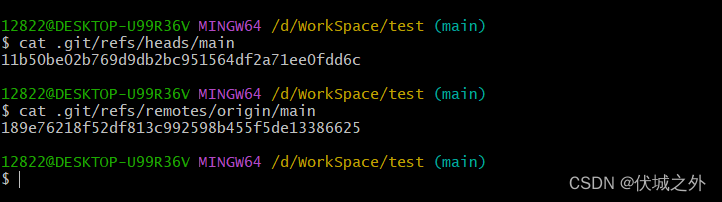
答案是:并不会
我们需要手动将 远程分支origin/main的更新合入本地分支main
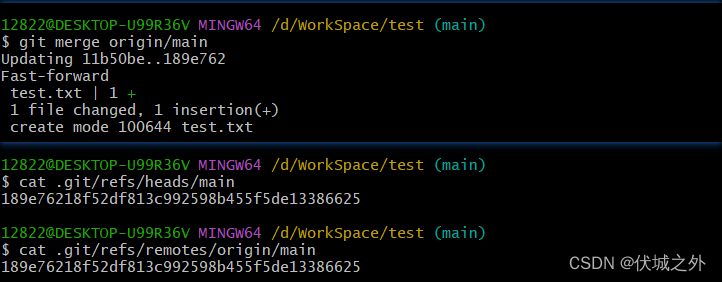
手动git merge后,本地分支main就合入了远程origin/main的最新commit

此时本地分支main,远程分支origin/main,远程仓库的分支main将保持一致
git fetch命令详解
我们已经知道了git fetch命令适用于跟新本地仓库的远程分支,那么它会在远程仓库发生哪些变化时更新呢?
- 远程仓库[被本地仓库远程分支跟踪]的分支发生新的commit时
- 远程仓库产生新的分支时
第一种情况,前面已经演示过了。
第二种情况,我们在远程仓库中新增一个分支dev

此时本地可以通过git remote show origin查看远程仓库的的情况
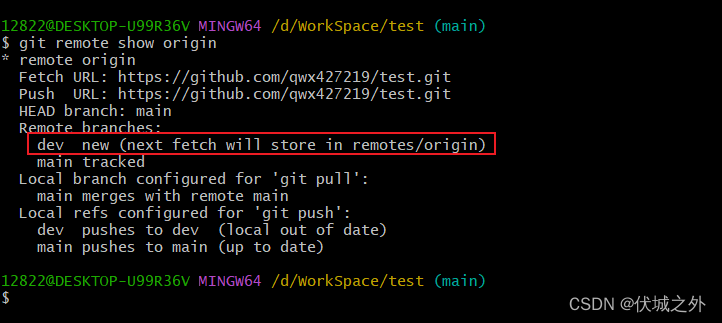
可以发现,远程仓库的main分支是tracked状态,即已被跟踪。而远程仓库的dev分支,是new状态,说明还没有被本地仓库跟踪。我们可以使用git fetch命令来跟踪它

上面git fetch提示信息的意思是,远程仓库的dev分支已经被同步到给了本地仓库的origin/dev分支。

此时本地仓库.git/refs/remotes/origin下就有了一个dev分支。
如果远程仓库删除了dev分支,那么本地仓库git fetch会进行同步删除吗?
答案是不会。
因为git fetch只会将“本地仓库没有的,但是远程仓库有的分支”,更新到本地仓库;
对于“远程仓库没有的,而本地仓库有的”,git fetch不会执行删除本地仓库多出来的分支。
如下例所示
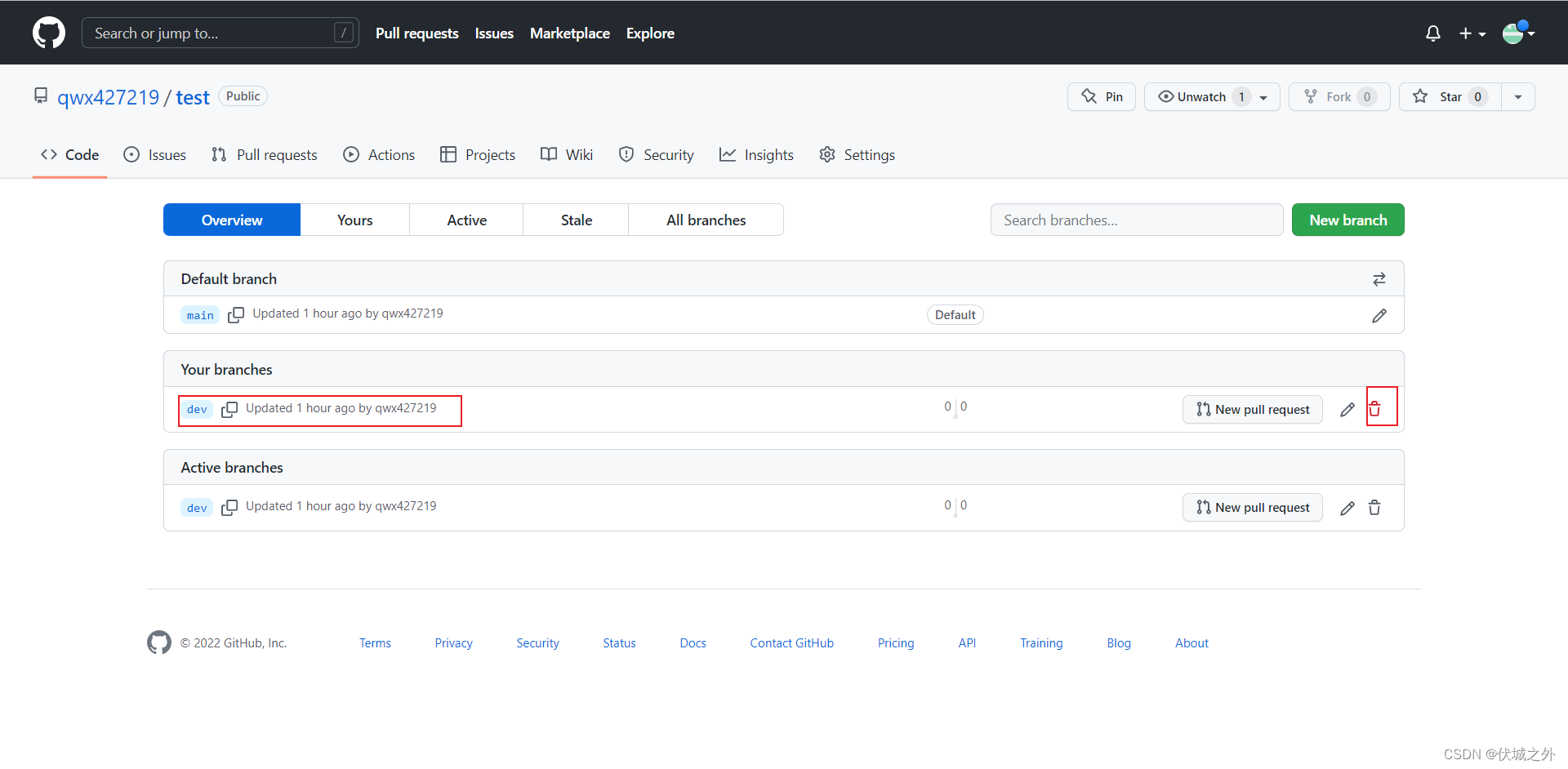 删除远程仓库的dev分支,此时远程仓库就只剩一个main分支了。
删除远程仓库的dev分支,此时远程仓库就只剩一个main分支了。
如果此时,我们在本地仓库执行git fetch,并不会删除本地仓库的远程分支dev
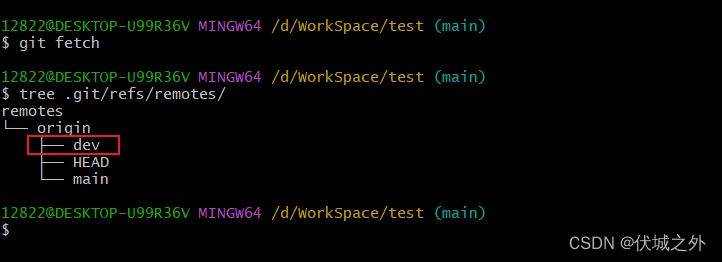
我们继续在本地查看远程仓库信息

发现,远程分支origin/dev已经是stale状态,即过期状态,此时我们可以使用 git remote prune命令来删除这个过期的远程分支。

这个命令的意思是,如果本地仓库的远程分支,并不存在于远程仓库origin的分支列表中,则删除本地的远程分支。
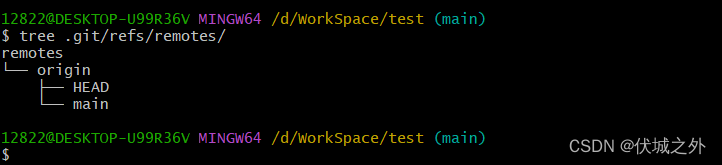
此时远程分支origin/dev就被删除了。
或者如果你想要在git fetch时,就删除掉本地已经过时的远程分支,则直接使用命令
git fetch --prune这个命令的意思,同步远程仓库分支到本地的同时,删除本地过时的远程分支。
我们重新在远程仓库创建dev分支后,git fetch到本地,然后再删除远程仓库的dev分支
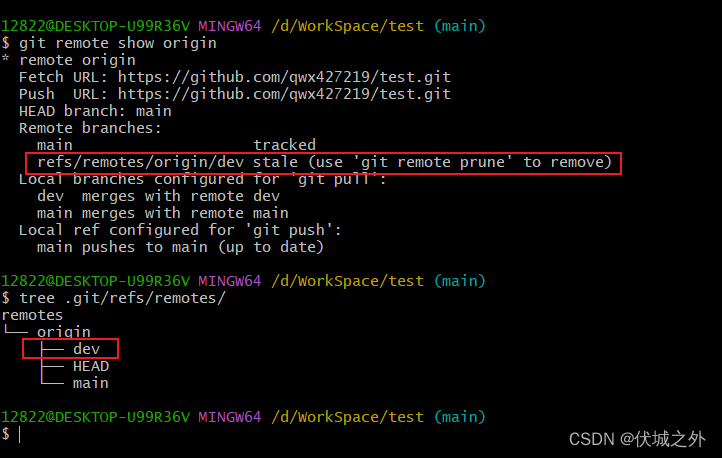
然后执行 git fetch --prune

关联本地分支和远程分支
当我们git clone远程仓库到本地后,该命令会自动帮本地仓库创建一个main分支,并且自动将本地分支main 关联到 远程分支 origin/main上
我们可以使用 git branch -vv 命令来查看 本地分支和远程分支的关联关系

而我们使用git branch <branch_name>命令创建的本地仓库是默认不关联任何远程分支的

我们需要借助命令
- git checkout 本地分支
- git branch -u 远程分支

来建立起本地分支和远程分支的关联。
或者使用命令
git branch --set-upstream-to=远程分支 本地分支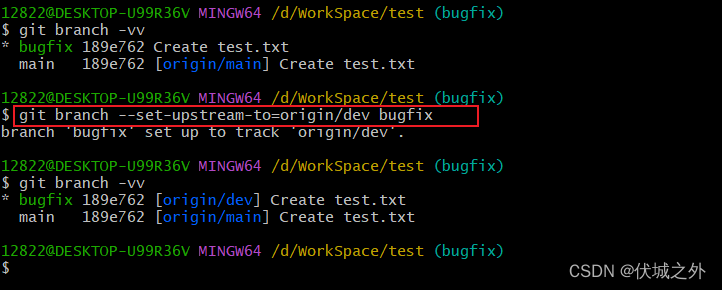
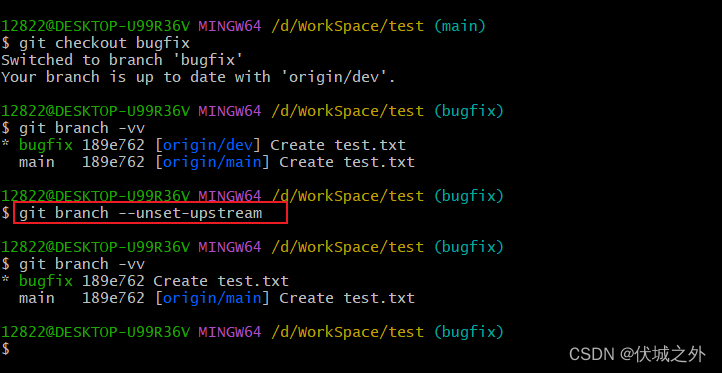
我们可以使用命令来解除本地分支和远程分支的关联
- git checkout 本地分支
- git branch --unset-upstream
那么建立本地分支和远程分支关联的作用是啥呢?
当我们需要拉取远程仓库的代码到本地分支时,需要先将远程仓库的代码fetch到本地仓库的远程分支,然后再将远程分支的代码merge到本地分支。
当我们需要推送本地仓库的代码到远程仓库时,需要先将本地分支的代码merge到远程分支,然后由远程分支将代码push到远程仓库。
这是一个非常麻烦的过程,如果我们可以直接将 本地分支的代码 push 到 远程仓库,将远程仓库的代码 pull 到本地分支,流程将变得非常简化,此时就需要将本地分支与远程分支进行关联,而远程分支也默认与远程仓库的分支建立了关联,所以是可以将远程分支的相关操作底层化的。
git pull
git pull命令相当于,先进行了一次 git fetch,再在本地分支上进行一次 git merge 远程分支
我们可以在远程仓库的dev分支上新建一次commit
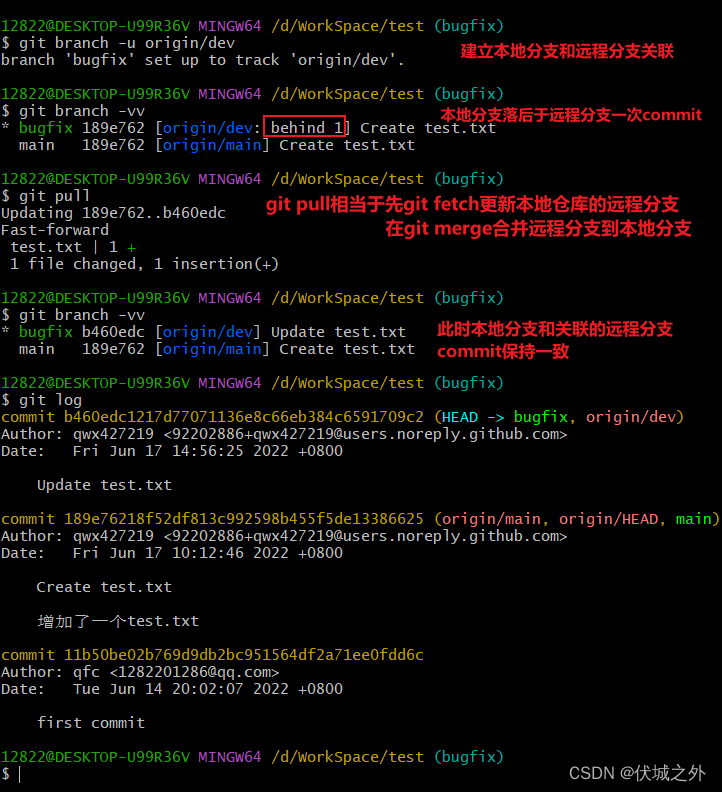
git pull命令执行的前提是,本地分支已经与远程分支建立了关联。
git pull和git fetch的区别以及使用时机
我们使用图示的方式解释下git fetch。
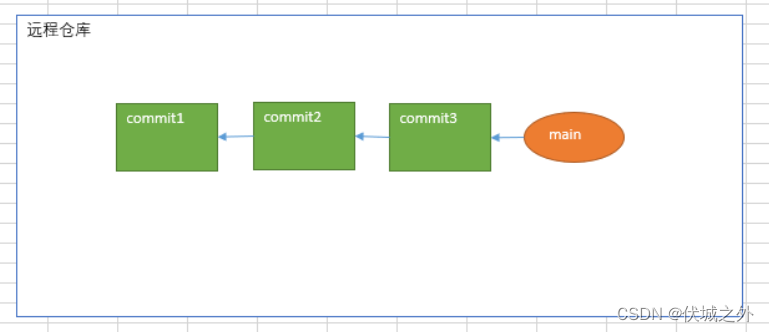
1、一开始只有远程仓库,没有本地仓库,在远程仓库有一个main分支
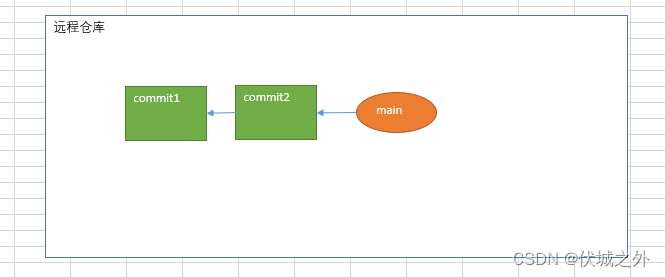
2、之后在本地git clone该远程仓库,则本地会创建一个本地仓库,并且自动创建一个本地main分支,和一个与远程仓库main分支关联的本地仓库远程分支origin/main

3、 之后远程仓库main分支发生了一次新的commit
4、 本地仓库通过git fetch命令来更新本地仓库的远程分支origin/main
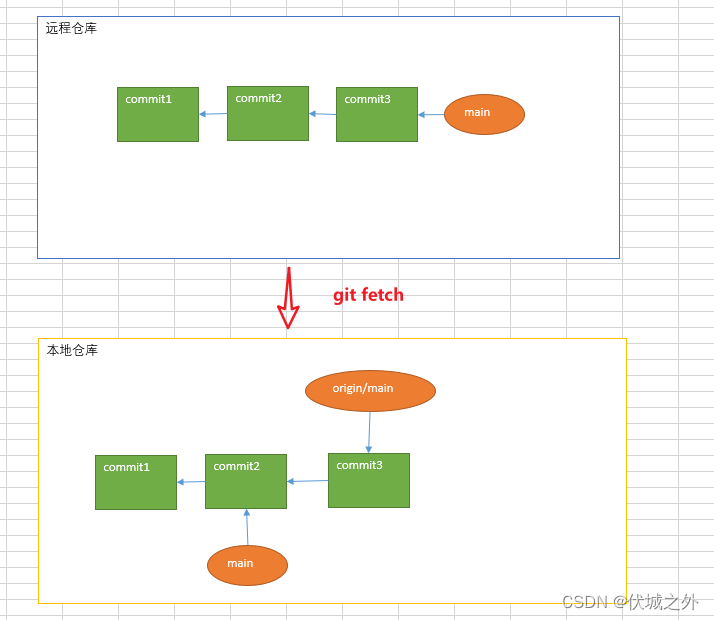
5、当本地仓库的远程分支更新后,就会造成本地分支main和远程分支origin/main代码不一致,此时我们可以直接在本地main分支上 git merge origin/main ,实现fast-forward-merge
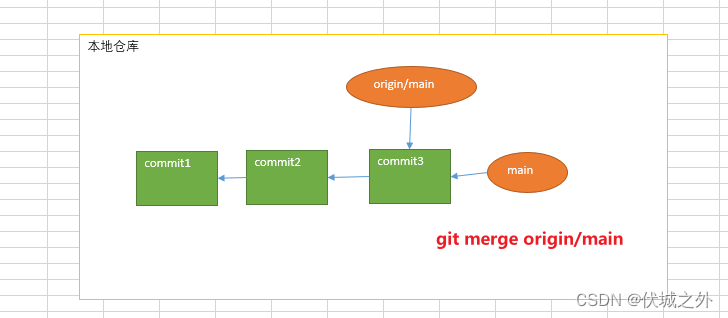
而git pull的作用就是,将上面4、5两步效果整合,一步到位。
4、git pull 表现为将远程仓库main分支代码直接拉取到本地仓库的本地分支main上,实质上,是先进行了git fetch更新本地仓库的origin/main分支,再进行git merge origin/main分支

这就是 git pull 和 git fetch的区别。
而对于上面这个 fast-forward-merge的情况,使用git pull非常适合。但是,如果遇到 3-way-merge的情况,且可能遇到冲突的情况,git pull就不太合适了。
我们以下面例子来解释:

然后远程仓库main分支发生了一次新的commit

同时本地仓库main分支也发生了一次新的commit

此时在本地仓库main分支上git pull,则会出现如下情况
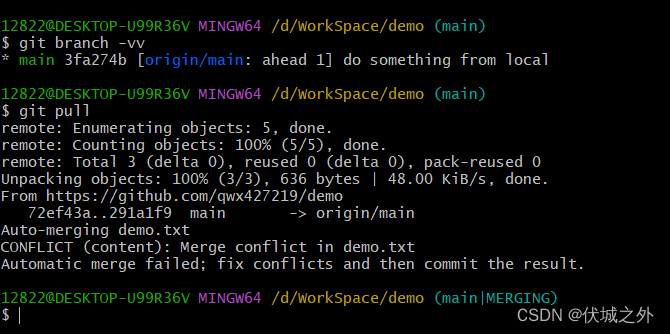
提示自动merge失败,原因是demo.txt中存在冲突,需要手动解决冲突,然后提交。
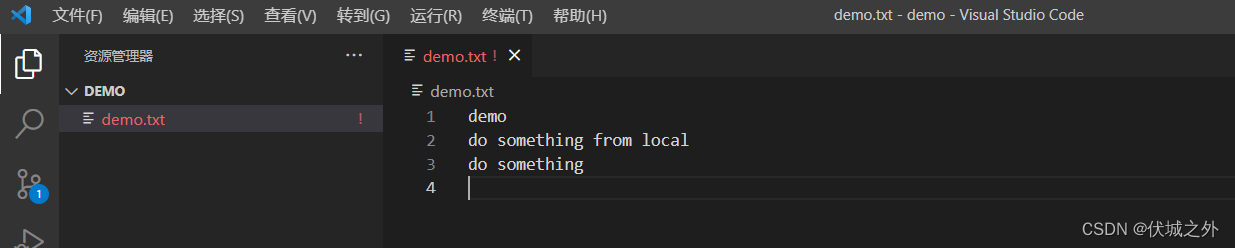
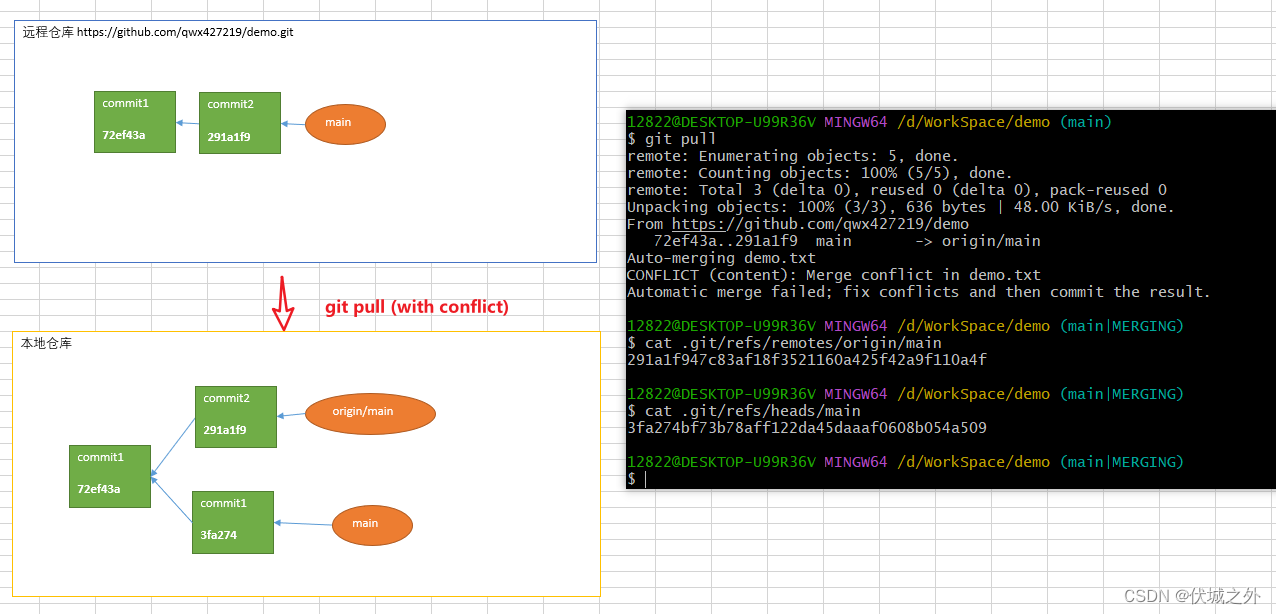 解决冲突
解决冲突
继续提交fixed conflict
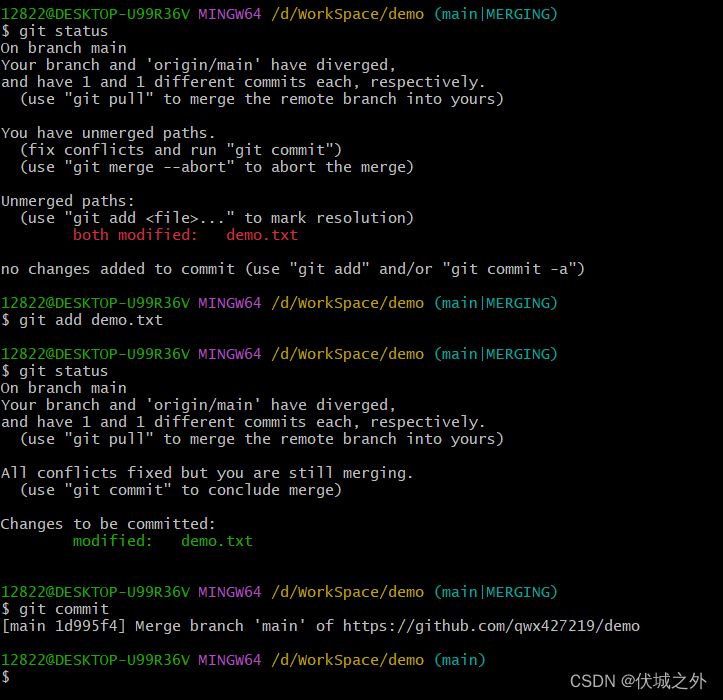

其实我们只要理解 git pull 是 git fetch + git merge,就可以理解为啥会出现merge conflict了。如果不了解git pull原理的人,可能就会对产生的merge conflict产生疑惑。
FETCH_HEAD
当我们在本地仓库首次执行git fetch后,在.git目录下就会自动创建一个FETCH_HEAD文件。
下图是尚未执行git fetch前的.git目录

当执行git fetch后,就会在.git目录下自动创建一个FETCH_HEAD文件

检查下FETCH_HEAD文件的内容,发现是远程仓库main分支的信息


我们需要思考一下,git fetch 如何判定本地仓库的远程分支落后 于 远程仓库的分支了呢?
其实就是靠的FETCH_HEAD,git fetch命令会对FETCH_HEAD做两件事:
- 本地仓库首次git fetch时,先会在.git目录下创建一个FETCH_HEAD文件,然后将远程仓库的分支信息(最新commit)记录进FETCH_HEAD文件中
- 本地仓库非首次git fetch时,会先取出.git/FETCH_HEAD中记录的上一次远程仓库的分支的commit和 本次远程仓库的分支的最新commit对比,看是否一致,若一致,则不进行更新,若不一致,则进行更新,并将最新的远程仓库的分支信息记录到本地FETCH_HEAD中
关于FETCH_HEAD还有另一个注意点:
那就是FETCH_HEAD是服务于git fecth的,而git fetch完成后,我们一般需要git merge,所以git fetch执行时,会判断我们所在的分支是否为需要进行merge的分支,
比如我们在本地分支main上执行git fetch,则FETCH_HEAD会记录其关联的远程分支origin/main需要被merge,而其不关联的远程分支就不需要被merge。
比如我们新建一个本地dev分支,并切换到dev分支 ,然后在dev分支执行git fetch

由于此时本地dev分支没有关联远程分支,所以FETCH_HEAD中没有需要merge的远程仓库的分支
所以,FETCH_HEAD中远程仓库的分支main会被记录为not-for-merge。
如果我们再切换到本地main分支上执行git fetch,则此时FETCH_HEAD中远程仓库的分支main会被记录为for-merge了,而for-merge是不写的。
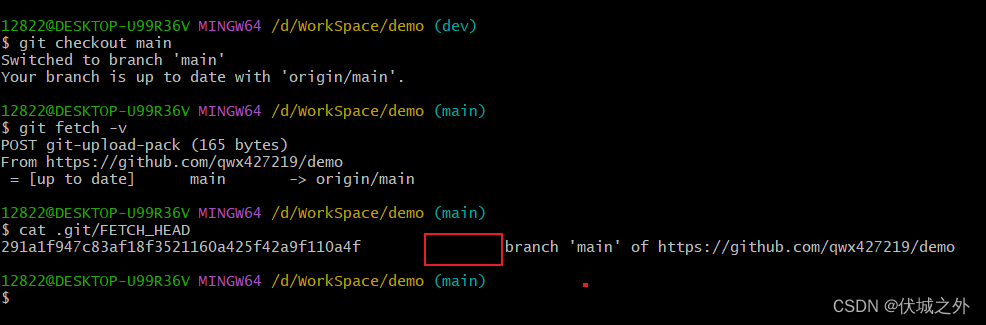
我们需要注意的是,每次git fetch后,FETCH_HEAD中只有一个远程仓库的分支会被标记为for-merge,其余的都会标记为not-for-merge,此时标记为for-merge的会被放在FETCH_HEAD文件的第一行。
而git fetch给FETCH_HEAD中远程仓库的分支打上for-merge or not-for-merge的标记的这一行为,将帮助git pull命令完成其功能。
git pull命令的内部工作机制是:先进行git fetch,更新所有远程分支,然后git merge 所在分支对应的远程分支。
那么 git pull的内部merge行为是如何知道要merge哪个的远程分支的呢?
我猜测是借助了FETCH_HEAD文件的for-merge or not-for-merge的标记。
git push
git push命令用于将本地分支推送到远程仓库,如果本地分支在远程仓库没有对应的分支,则会在远程仓库创建对应分支。
情况一:本地分支有对应的(远程分支) 远程仓库的分支

可以发现,此时本地分支main,关联了远程分支origin/main,也就关联了远程仓库的分支main
此时在本地分支main上git push,则会将本地分支main(对应commit)推送到远程仓库的分支main
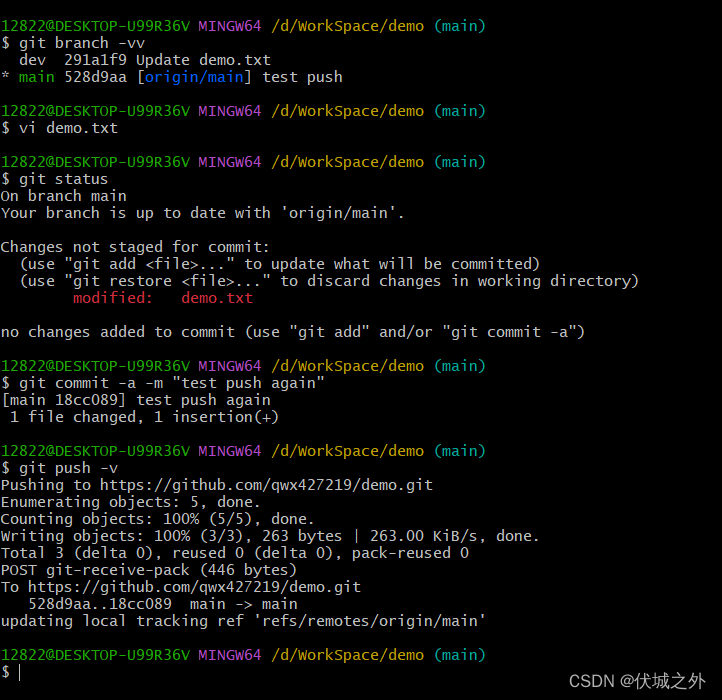
git push -v中的-v是显示详细日志信息,并非特殊参数,本质和git push没有区别。
git push其实是先将本地分支main 推送到了 远程分支origin/main,然后推送到了远程仓库main分支
情况二:本地分支没有对应的(远程分支)远程仓库的分支
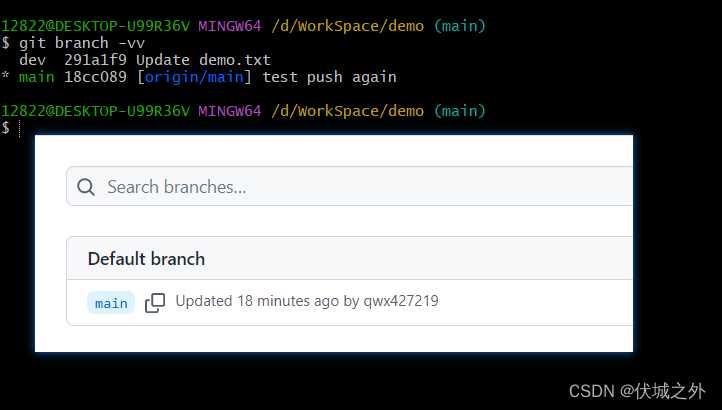
本地分支dev,没有关联的远程分支,远程仓库也没有对应分支。
此时我们期望git push会直接将本地dev分支推送到远程仓库,即在远程仓库上创建一个dev分支。
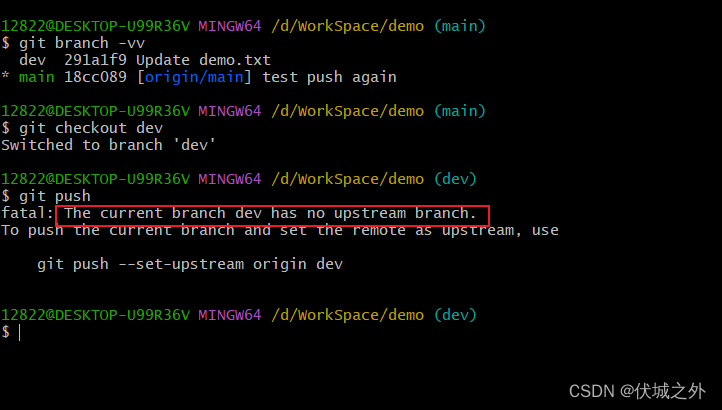
但是此时git push命令报错,提示当前的分支没有上游分支。意识其实是,本地分支没有对应的远程仓库分支信息。
其实很好理解,我们希望git push可以在远程仓库创建一个分支来接收本地分支的代码,但是git push需要知道在哪个远程仓库,创建什么名字的分支。
git push 远程仓库 即将创建的分支的名字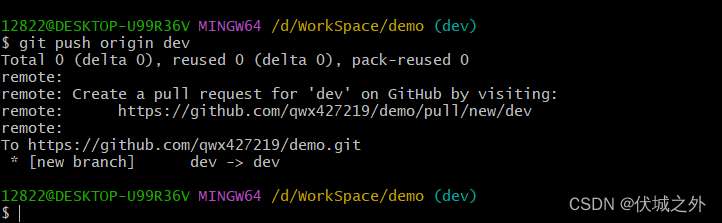
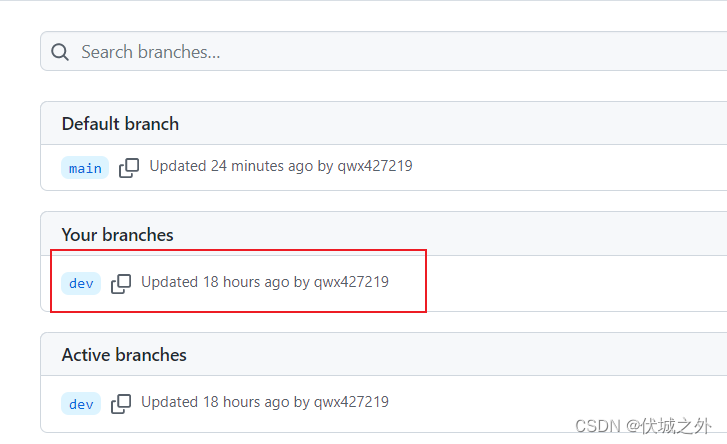
此时远程仓库就有了一个dev分支。
但是,这个命令并没有建立其本地分支dev,和远程仓库的dev分支的关联关系,这意味着每次本地分支dev push代码到远程仓库的dev分支都要指定远程仓库的名字和分支的名字

我们可以通过 git branch -vv来查看 本地分支与远程分支(远程仓库的分支)的关联关系

发现并没有建立关联。
我们可以通过
git branch -u 远程分支来建立本地分支和远程仓库的分支的关联

或者直接在git push时指定关联关系,使用如下命令
git push -u 远程仓库名 分支名
我们还可以借助git push命令来删除远程仓库上的分支
git push -d 远程仓库 分支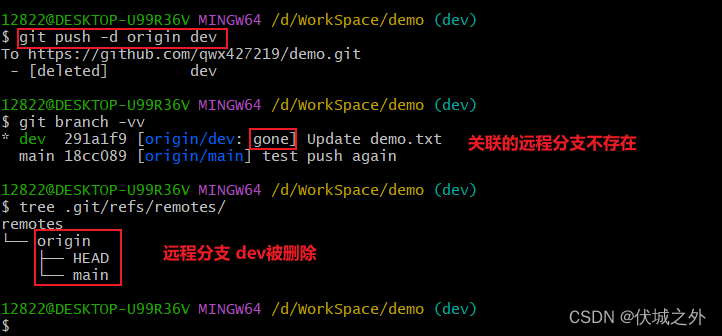

git stash
在实际开发中,我们经常会遇到如下情况:
我们正在某个分支上进行需求开发,开发到一半时,主管突然说线上出现了一个紧急bug,需要切回之前的版本分支进行修复,但是此时我们当前分支的代码还没开发完,还不满足提交的条件
我们有如下几种处理方式:
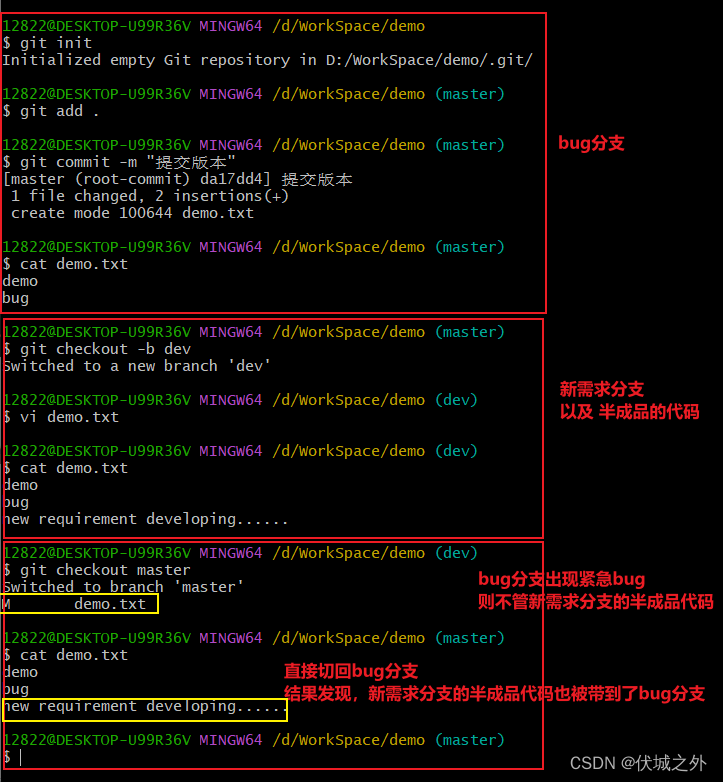
1、管他三七二十一,修复bug要紧,直接checkout到bug分支
此时你会发现,你的正在开发的代码 随着你的checkout动作,一起来到了bug分支
2、先将新需求分支的开发的半成品代码提交,然后切换回bug分支修复bug

但是这种提交半成品代码的行为是很危险的,万一不小心将其push到远程仓库,则会阻塞新需求分支上开发代码的其他的人的进度。
Git考虑到了这种情况,提供了git stash命令
当我们在当前分支上,开发一些半成品代码,但是遇到一些不可抗力,需要切换到其他分支时,我们可以选择git stash将当前分支的半成品代码暂存。
git stash会记录当前分支的工作区文件状态,以及暂存区索引状态。


当我们运行git stash命令前,.git/refs目录如下

当我们运行git stash命令后,.git/refs目录下会多出一个文件stash

检查.git/refs/stash文件内容,发现是一个commit对象


可以看出,stash其实是将半成品代码对应的文件进行了快照记录
当我们git stash pop,将半成品载入时,对应的.git/refs/stash就被清除了,但是它的commit对象并没有被删除

我们可以使用git prune删除这些悬空的commit。
git stash的常用命令如下:
| git stash / git stash push | 暂存当前分支的工作区文件状态和暂存区索引状态 |
| git stash list | 查看stash暂存列表 |
| git stash pop | 弹出stash暂存列表头部第一个修改到当前分支 |
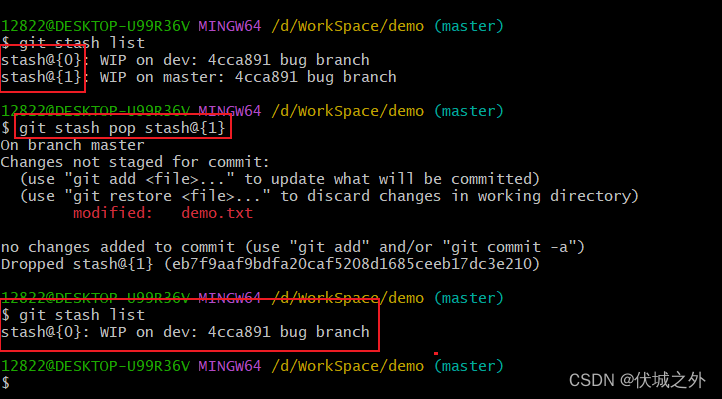
| git stash pop stash@{0} | 弹出指定stash,到当前分支 |
| git stash apply | 不弹出,仅使用stash头部修改到当前分支 |
| git stash clear | 清空stash |
stash可以看出一个栈结构,它服务于本地仓库的所有分支,所有分支上修改都可以暂存进stash中。
如下例子:
在master分支上stash一个修改

然后在dev分支上,stash一个修改
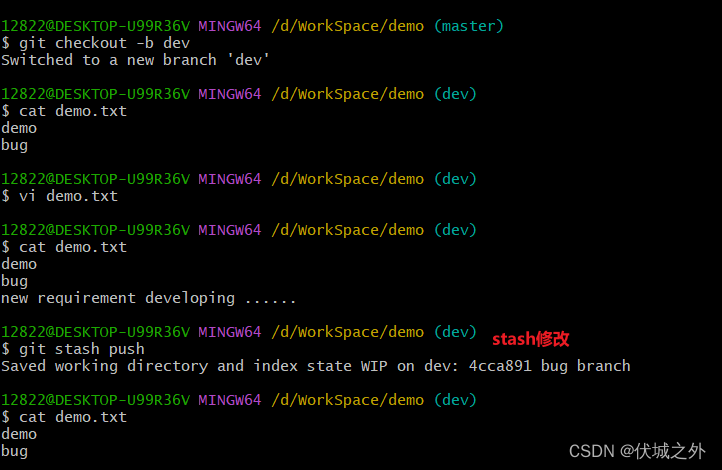
此时stash中有两个修改,且dev分支的修改在stash栈头部

然后我们切回master分支,git stash pop,发现dev分支的修改被恢复到了master分支中

这是因为git stash pop只会将stash栈头部修改恢复到当前分支
而且一旦git stash pop后,在stash栈中就失去了被弹出的修改

为了解决这两个问题:

git stash apply 命令不会弹出stash栈头部的修改,只是使用stash栈头部修改到当前分支。
git stash pop 和 git stash apply 可以携带参数 stash栈的序号,来恢复指定的修改到当前分支