
- 1[论文简述+翻译]Bi-PointFlowNet: Bidirectional Learning for Point Cloud Based Scene Flow Estimation_bfp模块
- 2【OpenBMC 系列】2.OpenBMC镜像编译流程以及如何加速编译_openbmc编译
- 3Vscode设置滚轮进行字体大小的调节
- 4【活动回顾】CSDN 成都城市开发者社区年度聚会 - 圆满结束!
- 5【C++学习记录】多态:动态多态、静态多态_静态多态和动态多态的优势与劣势
- 6在微信小程序中使用ercharts_echart er图
- 7[ HIT - CSAPP ] 哈尔滨工业大学 - 计算机系统 - 期末大作业“Hello‘s P2P’”_题目描述 有 n 台机器,初始时刻为 0. 在前 bi 秒(包括第 bi 秒),第 i 台机器每整
- 8Adobe全新AI工具引关注,Adobe firefly助力创作更高效、更有创意_adobe firefly csdn
- 9小米AI实验室多模态图片翻译论文入选自然语言处理领域顶级会议ACL 2023
- 10MSTP协议_mstp master端口
Windows 环境下 Hadoop 的安装和配置_windows安装hadoop及配置
赞
踩
Windows 环境下 Hadoop 的安装和配置
平台及版本
- Windows10
- JDK1.8.0_192
- Hadoop2.7.3
安装 Java1.8,并配置环境变量
首先要安装好Java。没装的先搜索安装Java的教程吧。
这里我已经安装好了,需要配置好环境变量,Hadoop的安装会用到。
路径:C:\Program Files\Java\jdk1.8.0_192
环境变量:HAVA_HOME,值:C:\Program Files\Java\jdk1.8.0_192
安装 Hadoop2.7.3
- 从hadoop-2.7.3下载hadoop-2.7.3.tar.gz,解压后放到C盘根目录下:
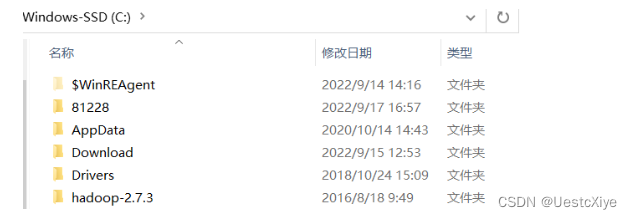
- 原版的Hadoop不支持Windows系统,我们需要修改一些配置方便在Windows上运行,需要从网上搜索下载hadoop对应版本的windows运行包hadooponwindows-master.zip。解压后,复制解压开的bin文件和etc文件到hadoop-2.7.3文件中,并替换原有的bin和etc文件。
hadooponwindows-master.zip下载:
链接:https://pan.baidu.com/s/1M2i8prhEPFOIROG_EIYhJw
提取码:acif
-
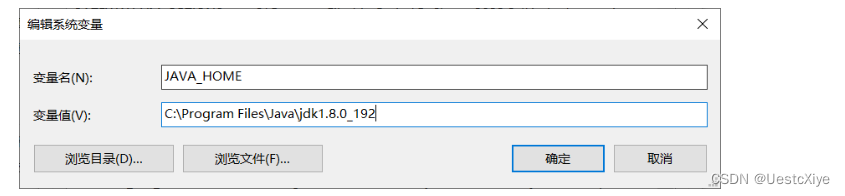
并在Path系统变量中加上:%JAVA_HOME%\bin;
-
配置Hadoop环境变量:
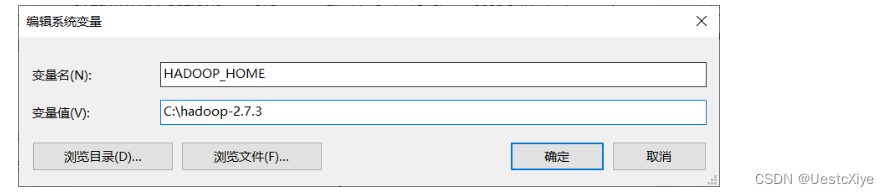
并在Path系统变量中加上:%HADOOP_HOME%\bin;
-
使用编辑器打开C:\hadoop-2.7.3\etc\hadoop\hadoop-env.cmd,找到set JAVA_HOME,将等号右边的值改成自己Java jdk的路径(如果路径中有Program Files,则将Program Files改为 PROGRA~1)。

-
配置好上面所有操作后,win+R 输入cmd 打开命令提示符,然后输入hadoop version,按回车,如果出现如图所示结果,则说明安装成功:

Hadoop 核心配置文件
在hadoop-2.7.3根目录下新建data文件夹和tmp文件夹,再在data文件夹里面新建datanote和namenote文件夹:

在hadoop-2.7.3\etc\hadoop中找到以下几个文件用文本编辑器打开。
-
打开 hadoop-2.7.3/etc/hadoop/core-site.xml, 复制下面内容粘贴到最后并保存:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>- 1
- 2
- 3
- 4
- 5
- 6
-
打开hadoop-2.7.3/etc/hadoop/mapred-site.xml, 复制下面内容粘贴到最后并保存:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>- 1
- 2
- 3
- 4
- 5
- 6
-
打开hadoop-2.7.3/etc/hadoop/hdfs-site.xml, 复制下面内容粘贴到最后并保存:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/C:/hadoop-2.7.3/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/C:/hadoop-2.7.3/data/datanode</value> </property> </configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
打开hadoop-2.7.3/etc/hadoop/yarn-site.xml,复制下面内容粘贴到最后并保存:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
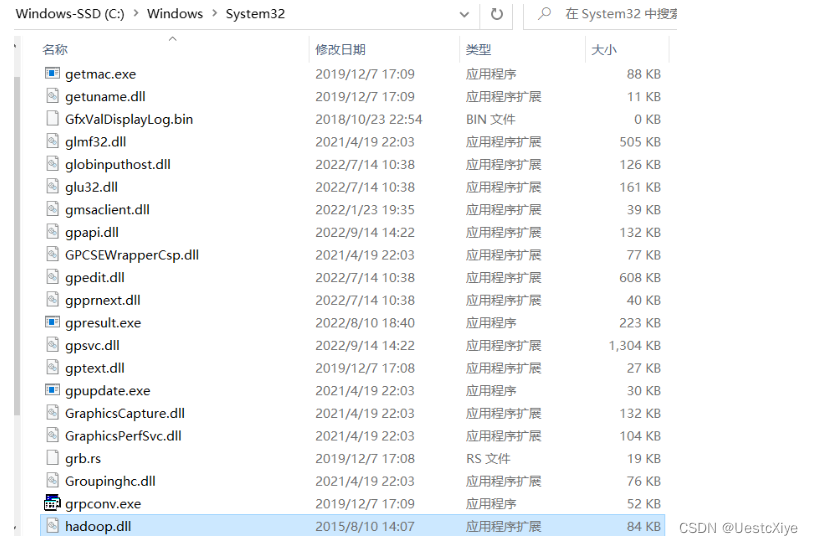
从C:\hadoop-2.7.3\bin下拷贝hadoop.dll到 C:\Windows\System32 ,不然在window平台使用MapReduce测试时报错:
启动 Hadoop 服务
到C:\hadoop-2.7.3\bin下,按下Win+R进入命令行窗口,输入hdfs namenode -format,执行结果如下图所示:
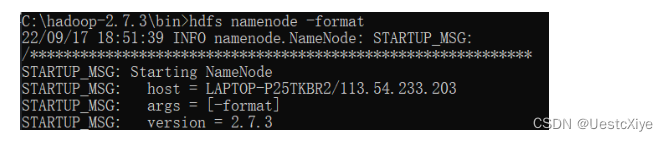
格式化之后,namenode文件夹里会自动生成一个current文件,说明格式化成功:

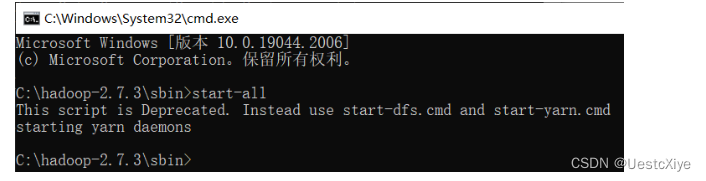
到C:\hadoop-2.7.3\sbin下,按下Win+R进入命令行窗口,输入start-all,启动Hadoop集群:
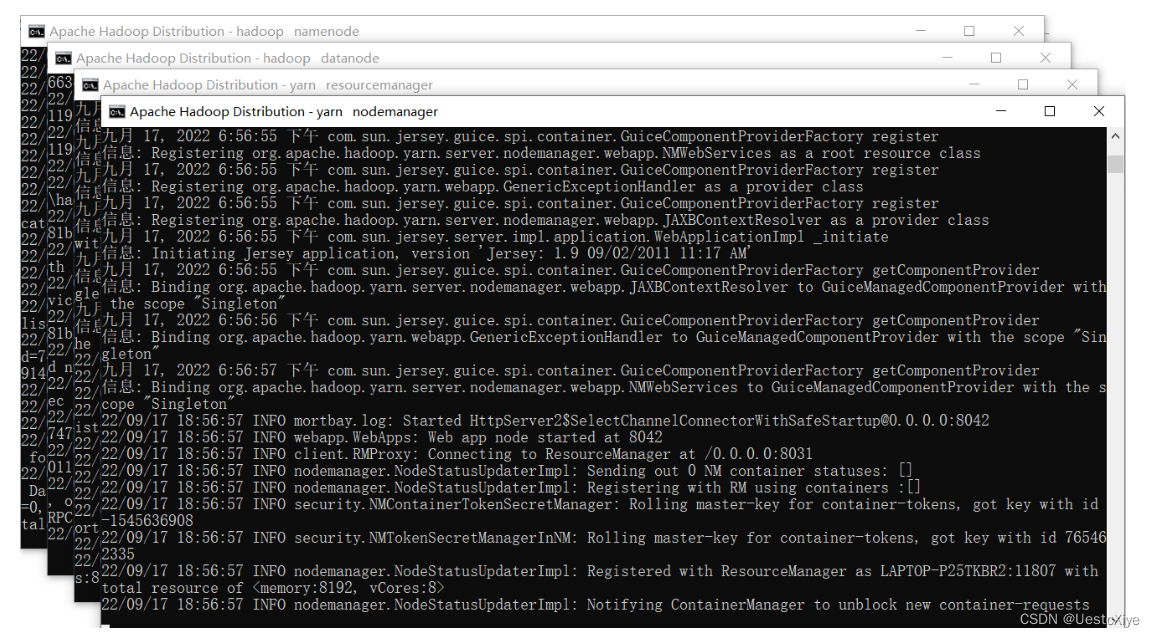
出现下面四个窗口表示启动Hadoop集群成功:
在同命令行窗口下输入start-all(或运行start-all.cmd),启动Hadoop服务,等待他启动完成。
完成之后,输入jps,可以查看运行的所有服务:

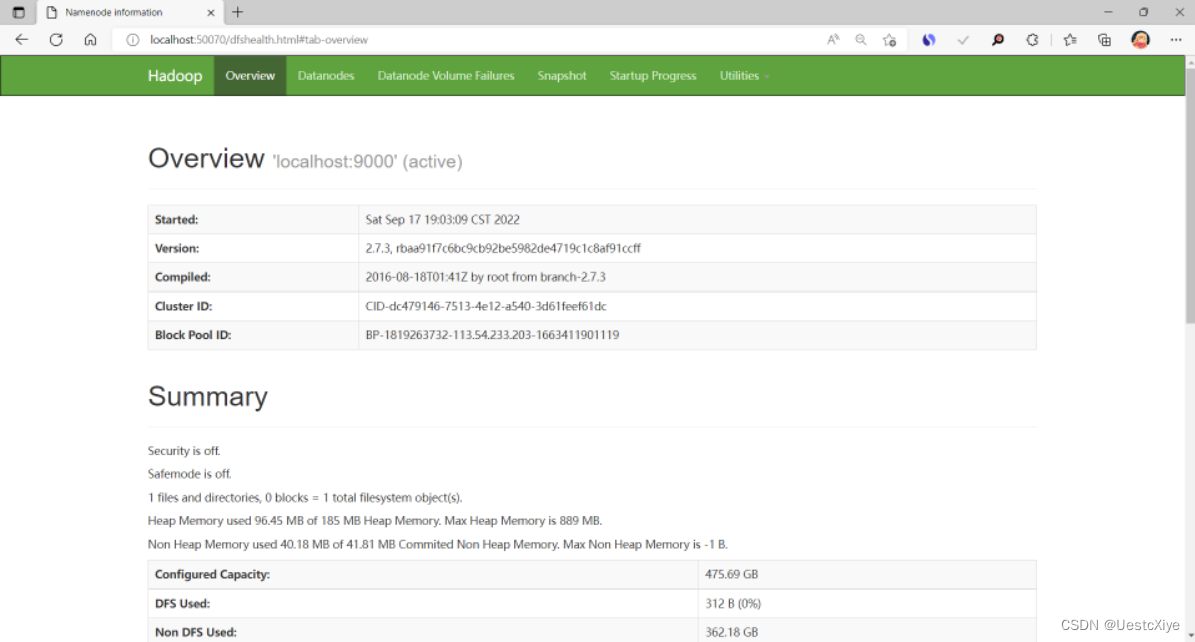
访问http://localhost:50070,这是Hadoop的管理页面:
访问http://localhost:8088,这是yarn的Web界面:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nKm4aKoZ-1663553603228)(C:\Users\81228\AppData\Roaming\Typora\typora-user-images\image-20220917192604677.png)]](https://img-blog.csdnimg.cn/3aaf6c69b70a443782fd1c865db725aa.png)
在同命令行窗口下输入stop-all(或运行stop-all.cmd),关闭Hadoop服务。

