
- 1Git 版本控制/项目迭代_git为什么那么多版本
- 2gitee最多上传多大文件_H5移动端图片压缩上传,基于Jquery的前端,实现拍照上传,选择相册
- 3VCam虚拟摄像头_vcam替换了本地摄像头
- 4详解PHP json_decode的TURE_json_decode true
- 5毕业设计 基于51单片机的晾衣架控制系统的设计_基于51单片机智能晾衣架创新点
- 6[手机]termux安装使用记录_pkg install termux-am
- 7刚拒了拼多多的Offer,不吐不快!
- 8Nginx配置性能优化之worker配置教程_worker_processes设置多少
- 9Android 13.0 SystemUI增加低电量弹窗功能_android 低电量弹框
- 10kafka 管理工具 Offset Explorer 使用_offsetexplorer3 客户端配置
Hadoop集群入坑——突然看不到yarn的node了_hadoop java.io.ioexception: version mismatch (expe
赞
踩
在服务器上搭建了许久的Hadoop集群,以前也没有注意过到底Web页面有什么问题,最近在使用Flink的时候,突然发现datanode和nodes of the cluster没有节点的信息

查看日志,啥都没有显示

去每个节点的nodemanager的web页面查看log信息


Version Mismatch (Expected: 28, Received: 768 ) at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.readOp
版本不匹配,但是ClusterID是一致的

再往上看日志

Registered with ResourceManager as localhost:5006 with total resource of <memory:8192, vCores:4>
发现nodemanager向ResourceManager注册的竟然是localhost:5006,不应该是hadoop02:5006吗,这里的5006是我修改过的IPC端口。因为服务器被限制住了。

查看映射
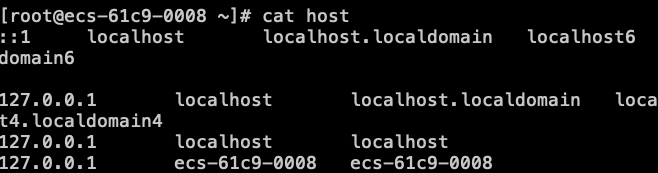

我刚开始的映射是上面两个图片映射的,注意,因为是在阿里云服务器上,所以我们的网络配置,本地的要配置成内网IP。虽然这样还有问题。
就是服务器默认带有第一张图片127.0.0.1到localhost的映射,就是这个原因,当datanode或者nodemanager返回心跳给namenode和ResourceManager的时候,导致先是找到hdfs或者yarn里面配置的机器名,比如配置的是hadoop02,而这个hadoop02又会去找到对应的IP,即本机器内网IP,然后在根据内网IP映射到了localhhost,最终返回的主机名也是localhost,按理说应该是hadoop02的,结果所有的datanode和nodemanager都返回localhost,导致ResourceManager只能看到一个节点。而且是祝节点。


