
- 1python生成excel文件的三种方式_python 生成excel
- 22021Java高级面试题汇总解答,附面试题_java高级面试题附答案解析(2021年java高级面试题大汇总)
- 3SourceTree 提交报错 闪退_sourcetree打开马上被关闭
- 4KNN最近邻分类算法的简单过程_knn分类算法的计算过程
- 5MyBatis update语句 set标签的使用(xml形式)_mybatis update xml
- 6我用numpy实现了VIT,手写vision transformer, 可在树莓派上运行,在hugging face上训练模型保存参数成numpy格式,纯numpy实现...
- 7SpringAI如何集成Ollama开发AI应用_spring ai + ollama
- 8互联网公司社招还会问算法题么?_驱动开发社招考查算法题吗
- 9协同过滤算法深入解析:构建智能推荐系统的核心技术_协同过滤算法数据集
- 10fastadmin离线安装插件提示”请从官网渠道下载插件压缩包(code:1)(code:0)“
MySQL索引和事务_mysql事务和索引
赞
踩
目录
1.索引
1.1 索引的作用
索引对于数据库来说,类似于目录,它可以提高查找的效率,但是同时也会降低增删改的效率,在实际工作中,查找的情况相对于增删改的情况要多出很多,所以添加索引好处还是不少的
1.2 查看索引

操作语句: show index from 表名;
一个表中被主键(primary key)约束,或者被unique、外键(foreign key)约束的列会自动生成索引.
1.3 创建索引

操作语句: create index 索引名 on 表名(添加索引的列);
创建索引需要根据业务需求来添加
比如: 在学生表中经常用名字来查询,那么就可以给名字这一列添加索引
注意: 创建索引最好在创建包的时候就创建好,如果后期表中的数据量很多,创建索引就会花费很多时间,这这段时间内表是无法正常使用的,是比较危险的操作.
1.4 删除索引

操作语句: drop index 索引名 on 表名;
删除索引的操作和创建索引的情况类似,都是比较危险的操作.
1.5 索引背后的数据结构(重点、面试题)
索引的底层是一棵B+树。
什么是B树?
B树相对于是二叉搜索树的升级版,相对于二叉搜索树来说,B树是一颗N叉搜索树,它的每个节点中可以存在N个key,这N个key中可以划分出N+1个区间,每个区间都可以生成一个子节点,这样的数据结构相比二叉搜索树,很大程度上降低了树的高度,虽然在查找时的比较次数基本没有减少,但是节点的个数变少了,因为节点存放是在硬盘上的,所以读写硬盘的次数就减少了,也就提高了数据库的查找效率。
而B+树在B树的基础上做了更适合与数据库索引的修改,和B树相同的是,B+树也是一个N叉搜索树,每个节点中可以包含N个key,和B树不同的是,这N个key只可以划分出N个区间(它没有超过节点最大值的区间),每个区间都可以延伸出一个子节点,并且父节点的key会在子节点中重复出现,并且是以最大值的姿态出现,比如在B+树中有一个父节点里面的数据是2、5、8 ,根据上面的描述,它可以有三个子节点:它的左孩子节点就可以是1、2 ,中间孩子节点就可以是3、4、5,右孩子节点就可以是7、8。以此类推,它的叶子结点就包括了一个有序的数据全集,并且它的叶子节点会以一个类似于链表的方式连接起来,这样的数据结构不仅拥有了B树中减少读写硬盘次数的效果,还更适合范围查询,比如我要查询大于3并且小于10的数据,(假设里面有3和10)那么我只需要在被连接起来的叶子节点中去找到3和10,它们中间的数据就是范围里的数据,除此之外,它所有的查询都是落在叶子节点上的,无论查询哪个元素,中间比较的次数都差不多,查询操作的效率比较均衡。
因为所有的数据都会在叶子节点中体现,所以数据库不会在每个节点中存放表的真实记录(也就是数据行),而是将数据行只存储在叶子节点上,其他节点只存储索引列的值,因为非叶子节点中只存储了简单的数据,他们的占用空间会大大降低,有可能被放进缓存中,进一步降低了硬盘读写的次数。
上面提到的B+树在主键列中会自动生成索引,如果有其他列被手动生成了索引,会再生成一棵新的B+树,这棵B+树的非叶子节点仍然是只存储该索引列的数据,而为了不让数据重复存储,它的叶子节点里面存放并不是数据行,而是主键的索引。
所以使用主键列来查询时,就只需要访问一次主键的B+树,而非主键列的查询,要先在飞主键列的B+树中找到其主键列的索引,然后根据这些索引再在主键列的B+树中查找这些数据(这个操作也叫做“回表”)。
2.事务
2.1 什么是事务?
事务就是将多条SQL语句打包到一起.
2.2 事务的使用
2.2.1 回滚
(1)start transaction;
(2)SQL语句
(3)rollback;
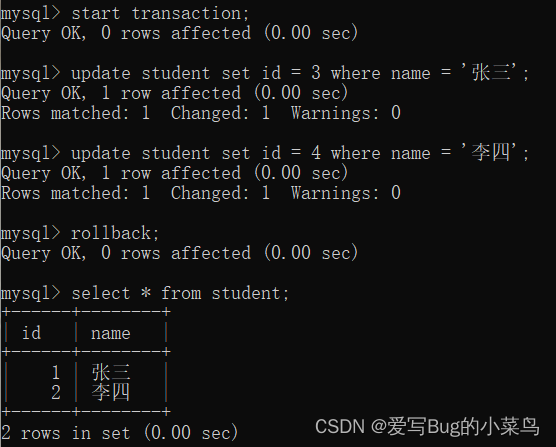
如上图
事务中SQL语句的操作为将name = '张三' 的 id 改为3,name = '李四' 的 id 改为4,最后进行回滚操作,那么所有的操作就会恢复到最开始的时候,修改的id也就会被还原
2.2.2 执行
(1) start transaction;
(2) 需要被执行的SQL语句
(3) commit;
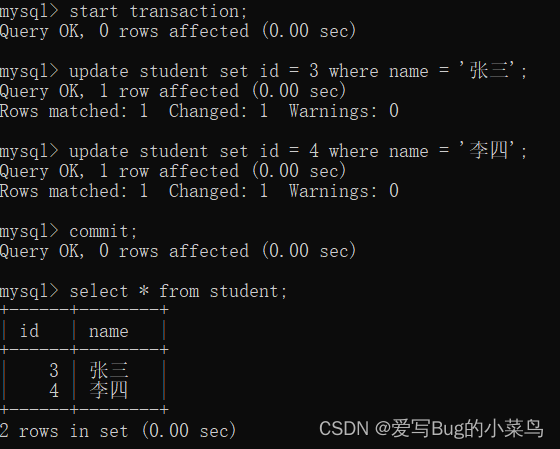
如上图
中间的操作和上面的回滚相同,使用commit则进行执行操作
2.3 事务的原子性(事务的初心)
在执行事务的多条SQL语句时,如果出现执行到一半中断的情况,会自动进行"回滚"操作。
回滚:将已经执行的SQL语句进行逆操作,比如:之前是插入,现在就是删除;之前是删除,现在就是插入;之前是修改,现在就改回去......
2.4 事务的一致性
事务执行前后,数据的状态都应该是合法的
2.5 事务的持久性
在事务中所做的修改都会体现在硬盘上,即使服务器重启,也会保证数据是有效的。
2.6 事务的隔离性(重点、面试题)
MySQL服务器要同时给多个客户端服务,这多个客户端之间可能会同时发起事务,而且这些事务在操作的是同一个数据库的同一个表的时候,很可能会引发一些问题,这个时候就体现了隔离性的重要了。
在MySQL中根据不同的隔离程度可以分为四种隔离级别
read uncommitted 级别 :事务之间是可以随意并发执行的
在这种隔离模式下,当不同的事务分别对同一个表进行读和写的时候,当写操作的事务对数据进行了删除或者修改时,读操作的事务也在进行读取,就有可能导致:读回去的数据是一个错误的数据,就会出现“脏读问题”。
read committed 级别 :对写操作加锁
对写操作加锁之后,读数据的操作就要等写操作把数据写完,才可以开始读的操作,很好的解决了“脏读问题”,增加了事务的隔离性,降低了事务的并发性,降低了事务的效率,提高了数据的准确性。但是只对写加锁并不会解决全部的问题,比如另一种情况:写操作语句结束了,读操作开始读的时候,写操作又回来对数据进行修改,这就导致在读数据时,前后两次读到的数据不一致,也就是出现了“不可重复读”的问题。
repeatable read 级别 :对读和写都加锁
对读和写加锁之后,写操作的时候不可以进行读操作,在读操作的时候不可以进行写操作,解决了“脏读问题”和“不可重复读”问题,隔离性进一步提高,并发性进一步降低,运行效率进一步降低,数据的准确性进一步提高。但是这里对读和写的加锁针对的是对同一个文件,在读操作进行的时候,其他的事务还可以去新增/删除其他的文件,这时当读操作结束后,发现文件的数量有变化了,就会出现“幻读问题”,也就是在同一个事务中,两次读到的结果集不同。
serializable 级别 :进行串行化,彻底舍弃并发
只要有人在读,其他的事务就只能摆烂,彻底将事务与事务隔离开,这个时候隔离性最高,并发性最低,运行效率最低,数据的准确性最高。
总结:隔离性越高,事务之间的并发程度就越低,执行效率就越慢,安全性就越高;
隔离性越低,事务之间的并发程度就越高,执行效率就越快,安全性就越低。
所以选择隔离程度要根据开发中不同的场景和不同的业务需求来选择。

