
- 1vmware安装android系统_vmware安装安卓系统安装教程
- 2请收藏!2023年全栈开发人员实战进阶指南终极版_程序员 2023技术栈
- 3什么是表达能力?如何提高表达能力?_如何增强网络特征表示能力
- 4Windows桌面图标的快捷键_桌面图标不固定 快捷键是什么
- 5GitHub中文排行榜,帮助你发现高分优秀中文项目(二)-Java_git 中文排行
- 6一文搞懂Transformers—01(Transformers机制)_transformers 残差
- 7跨语言评测数据集之XNLI介绍
- 8短信登录session-redis
- 9科研宝藏网站,赶紧看过来!学术GPT!!!_改英文论文好用的网站editgpt
- 10Git Submodule入门与实践_git submodule工程实践
深度学习进阶篇[8]:对抗神经网络GAN基本概念简介、纳什均衡、生成器判别器、解码编码器详解以及GAN应用场景_gan详解
赞
踩

【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等

专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等
本专栏主要方便入门同学快速掌握相关知识。后续会持续把深度学习涉及知识原理分析给大家,让大家在项目实操的同时也能知识储备,知其然、知其所以然、知何由以知其所以然。
声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)
专栏订阅:深度学习入门到进阶专栏
对抗神经网络GAN基本概念简介:generative adversarial network
1.博弈论
博弈论可以被认为是两个或多个理性的代理人或玩家之间相互作用的模型。
理性这个关键字,因为它是博弈论的基础。我们可以简单地把理性称为一种理解,即每个行为人都知道所有其他行为人都和他/她一样理性,拥有相同的理解和知识水平。同时,理性指的是,考虑到其他行为人的行为,行为人总是倾向于更高的报酬/回报。
既然我们已经知道了理性意味着什么,让我们来看看与博弈论相关的其他一些关键词:
-
游戏:一般来说,游戏是由一组玩家,行动/策略和最终收益组成。例如:拍卖、象棋、政治等。
-
玩家:玩家是参与任何游戏的理性实体。例如:在拍卖会的投标人、石头剪刀布的玩家、参加选举的政治家等。
-
收益:收益是所有玩家在获得特定结果时所获得的奖励。它可以是正的,也可以是负的。正如我们之前所讨论的,每个代理都是自私的,并且想要最大化他们的收益。
2.纳什均衡
纳什均衡(或者纳什平衡),Nash equilibrium ,又称为非合作博弈均衡,是人工智能博弈论方法的“基石”。
所谓纳什均衡,指的是参与者的一种策略组合,在该策略上,任何参与人单独改变策略都不会得到好处,即每个人的策略都是对其他人的策略的最优反应。换句话说,如果在一个策略组合上,当所有其他人都不改变策略时,没有人会改变自己的策略,则该策略组合就是一个纳什均衡。
经典的例子就是囚徒困境:
**背景:**一个案子的两个嫌疑犯A和B被警官分开审讯,所以A和B没有机会进行串供的;
**奖惩:**警官分别告诉A和B,如果都不招供,则各判3年;如果两人均招供,均判5年;如果你招供、而对方不招供,则你判1年,对方10年。
**结果:**A和B都选择招供,各判5年,这个便是此时的纳什均衡。
从奖惩说明看都不招供才是最优解,判刑最少。其实并不是这样,A和B无法沟通,于是从各自的利益角度出发:
嫌疑犯A想法:
-
如果B招供,如果我招供只判5年,不招供的话就判10年;
-
如果B不招供,如果我招供只判1年,不招供的话就判3年;
所以无论B是否招供,A只要招供了,对A而言是最优的策略。
同上,嫌疑犯B想法也是相同的,都依据各自的理性而选择招供,这种情况就被称为纳什均衡点。
3.GAN生成器的输入为什么是噪声
GAN生成器Generator的输入是随机噪声,目的是每次生成不同的图片。但如果完全随机,就不知道生成的图像有什么特征,结果就会不可控,因此通常从一个先验的随机分布产生噪声。常用的随机分布:
-
高斯分布:连续变量中最广泛使用的概率分布;
-
均匀分布:连续变量x的一种简单分布。
引入随机噪声使得生成的图片具有多样性,比如下图不同的噪声z可以产生不同的数字:
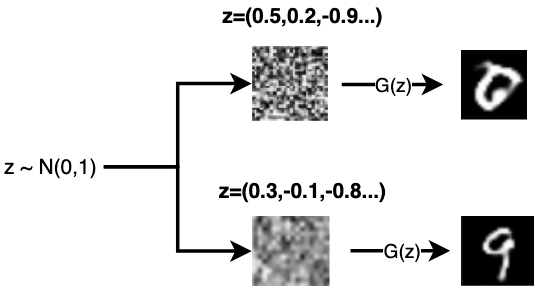
4.生成器Generator
生成器G是一个生成图片的网络,可以采用多层感知机、卷积网络、自编码器等。它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。通过下图模型结构讲解生成器如何一步步将噪声生成一张图片:

1)输入:100维的向量;
2)经过两个全连接层Fc1和Fc2、一个Resize,将噪声向量放大,得到128个7*7大小的特征图;
3)进行上采样,以扩大特征图,得到128个14*14大小的特征图;
4)经过第一个卷积Conv1,得到64个14*14的特征图;
5)进行上采样,以扩大特征图,得到64个28*28大小的特征图;
6)经过第二个卷积Conv2,将输入的噪声Z逐渐转化为12828的单通道图片输出,得到生成的手写数字。
Tips:全连接层作用:维度变换,变为高维,方便将噪声向量放大。因为全连接层计算量稍大,后序改进的GAN移除全连接层。
Tips:最后一层激活函数通常使用tanh():既起到激活作用,又起到归一作用,将生成器的输出归一化至[-1,1],作为判别器的输入。也使GAN的训练更稳定,收敛速度更快,生成质量确实更高。
5.判别器Discriminator
判别器D的输入为真实图像和生成器生成的图像,其目的是将生成的图像从真实图像中尽可能的分辨出来。属于二分类问题,通过下图模型结构讲解判别器如何区分真假图片:
-
输入:单通道图像,尺寸为28*28像素(非固定值,根据实际情况修改即可)。
-
输出:二分类,样本是真或假。
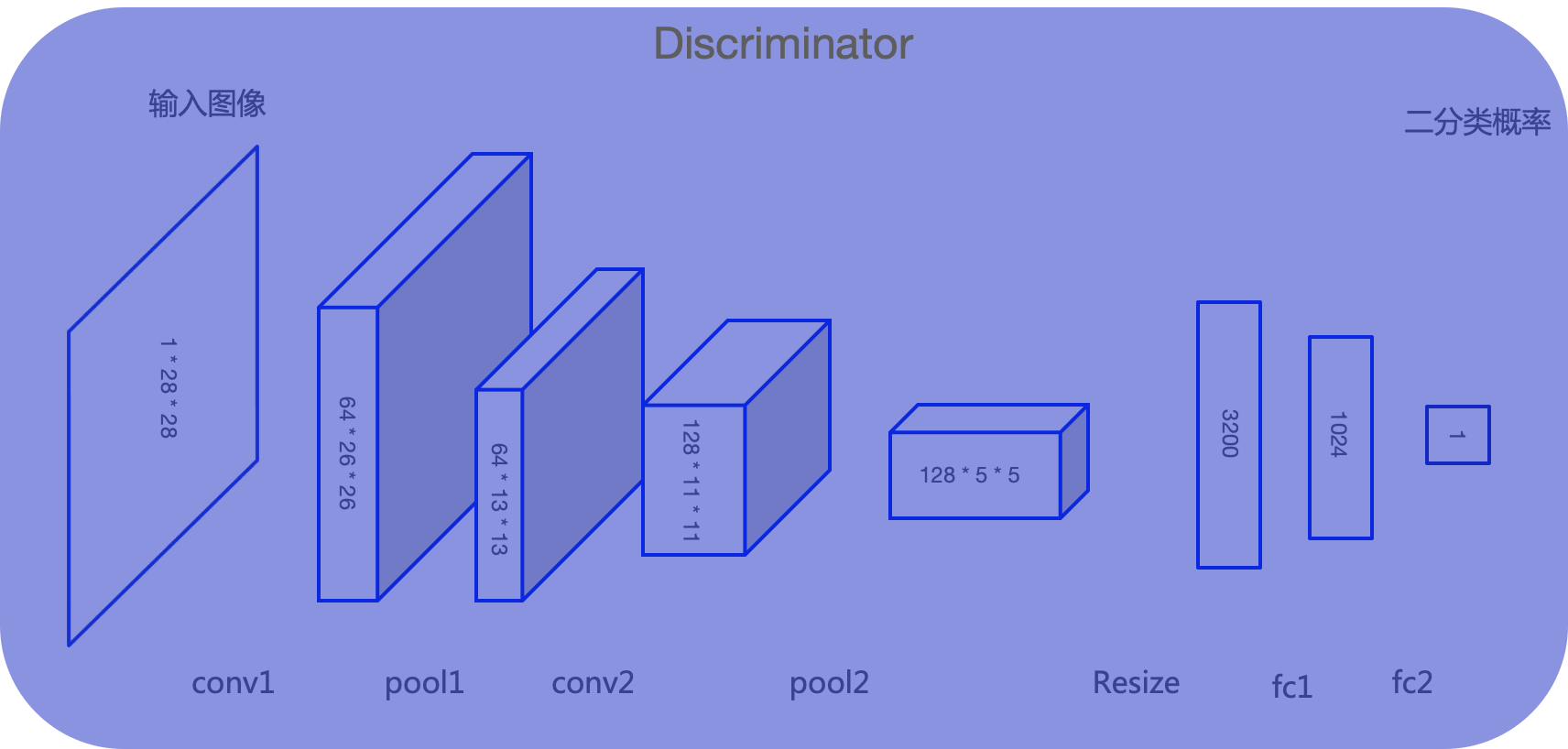
1)输入:28281像素的图像;
2)经过第一个卷积conv1,得到64个2626的特征图,然后进行最大池化pool1,得到64个1313的特征图;
3)经过第二个卷积conv2,得到128个1111的特征图,然后进行最大池化pool2,得到128个55的特征图;
4)通过Resize将多维输入一维化;
5)再经过两个全连接层fc1和fc2,得到原始图像的向量表达;
6)最后通过Sigmoid激活函数,输出判别概率,即图片是真是假的二分类结果。
6.GAN损失函数
在训练过程中,生成器G(Generator)的目标就是尽量生成真实的图片去欺骗判别器D(Discriminator)。而D的目标就是尽量把G生成的图片和真实的图片区分开。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
用公式表示如下:
m
i
n
G
m
a
x
D
V
(
D
,
G
)
=
E
x
∼
p
d
a
t
a
(
x
)
[
log
D
(
x
)
]
+
E
z
∼
p
z
(
z
)
[
log
(
1
−
D
(
G
(
z
)
)
)
]
(1)
公式左边V(D,G)表示生成图像和真实图像的差异度,采用二分类(真、假两个类别)的交叉熵损失函数。包含minG和maxD两部分:
m a x D V ( D , G ) \mathop{max}\limits_{D}V(D,G) DmaxV(D,G)表示固定生成器G训练判别器D,通过最大化交叉熵损失V(D,G)来更新判别器D的参数。D的训练目标是正确区分真实图片x和生成图片G(z),D的鉴别能力越强,D(x)应该越大,右边第一项更大,D(G(x))应该越小,右边第二项更大。这时V(D,G)会变大,因此式子对于D来说是求最大(maxD)。
m i n G m a x D V ( D , G ) \mathop{min}\limits_{G}\mathop{max}\limits_{D}V(D,G) GminDmaxV(D,G)表示固定判别器D训练生成器G,生成器要在判别器最大化真、假图片交叉熵损失V(D,G)的情况下,最小化这个交叉熵损失。此时右边只有第二项有用, G希望自己生成的图片“越接近真实越好”,能够欺骗判别器,即D(G(z))尽可能得大,这时V(D, G)会变小。因此式子对于G来说是求最小(min_G)。
-
x ∼ p d a t a ( x ) x\sim p_{data}(x) x∼pdata(x):表示真实图像;
-
z ∼ p z ( z ) z\sim p_{z}(z) z∼pz(z):表示高斯分布的样本,即噪声;
-
D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
等式的右边其实就是将等式左边的交叉商损失公式展开,并写成概率分布的期望形式。详细的推导请参见原论文Generative Adversarial Nets。
7.模型训练
GAN包含生成器G和判别器D两个网络,那么我们如何训练两个网络?

训练时先训练鉴别器D 将真实图片打上真标签1和生成器G生成的假图片打上假标签0,一同组成batch送入判别器D,对判别器进行训练。计算loss时使判别器对真实图像输入的判别趋近于真,对生成的假图片的判别趋近于假。此过程中只更新判别器的参数,不更新生成器的参数。
然后再训练生成器G 将高斯分布的噪声z送入生成器G,将生成的假图片打上真标签1送入判别器D。计算loss时使判别器对生成的假图片的判别趋近于真。此过程中只更新生成器的参数,不更新判别器的参数。
注意:训练初期,当G的生成效果很差时,D会以高置信度来拒绝生成样本,因为它们与训练数据明显不同。因此,log(1−D(G(z)))饱和(即为常数,梯度为0)。因此我们选择最大化logD(G(z))而不是最小化log(1−D(G(z)))来训练G,和公示(1)右边第二项比较。
8模型训练不稳定
GAN训练不稳定的原因如下:
-
不收敛:很难使两个模型G和D同时收敛;
-
模式崩溃:生成器G生成单个或有限模式;
-
慢速训练:生成器G的梯度消失。
训练GAN的时候,可以采取以下训练技巧:
1)生成器最后一层的激活函数用tanh(),输出归一化至[-1, 1];
2)真实图像也归一化到[-1,1]之间;
3)学习率不要设置太大,初始1e-4可以参考,另外可以随着训练进行不断缩小学习率;
4)优化器尽量选择Adam,因为SGD解决的是一个寻找最小值的问题,GAN是一个博弈问题,使用SGD容易震荡;
5)避免使用ReLU和MaxPool,减少稀疏梯度的可能性,可以使用Leak Re LU激活函数,下采样可以用Average Pooling或者Convolution + stride替代。上采样可以用PixelShuffle, ConvTranspose2d + stride;
6)加噪声:在真实图像和生成图像中添加噪声,增加鉴别器训练难度,有利于提升稳定性;
7)如果有标签数据,尽量使用标签信息来训练;
8)标签平滑:如果真实图像的标签设置为1,我们将它更改为一个较低的值,比如0.9,避免鉴别器对其分类过于自信 。
9.编码器Encoder
Encoder目标是将输入序列编码成低维的向量表示或embedding,映射函数如下:
V
→
R
d
(1)
即将输入V映射成embedding z i ∈ R d z_i\in R^{d} zi∈Rd,如下图所示:

Encoder一般是卷积神经网络,主要由卷积层,池化层和BatchNormalization层组成。卷积层负责获取图像局域特征,池化层对图像进行下采样并且将尺度不变特征传送到下一层,而BN主要对训练图像的分布归一化,加速学习。(Encoder网络结构不局限于卷积神经网络)
以人脸编码为例,Encoder将人脸图像压缩到短向量,这样短向量就包含了人脸图像的主要信息,例如该向量的元素可能表示人脸肤色、眉毛位置、眼睛大小等等。编码器学习不同人脸,那么它就能学习到人脸的共性:
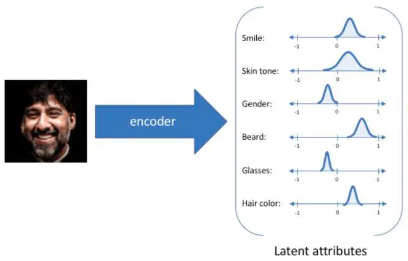
10.解码器Decoder
Decoder目标是利用Encoder输出的embedding,来解码关于图的结构信息。

输入是Node Pair的embeddings,输出是一个实数,衡量了这两个Node在中的相似性,映射关系如下:
R
d
∗
R
d
→
R
+
.
(1)
Decoder对缩小后的特征图像向量进行上采样,然后对上采样后的图像进行卷积处理,目的是完善物体的几何形状,弥补Encoder当中池化层将物体缩小造成的细节损失。
以人脸编码、解码为例,Encoder对人脸进行编码之后,再用解码器Decoder学习人脸的特性,即由短向量恢复到人脸图像,如下图所示:

11.GAN应用
一起来看看GAN有哪些有趣的应用:
-
图像生成
图像生成是生成模型的基本问题,GAN相对先前的生成模型能够生成更高图像质量的图像。如生成逼真的人脸图像

-
超分辨率
将图像放大时,图片会变得模糊。使用GAN将32*32的图像扩展为64*64的真实图像,放大图像的同时提升图片的分辨率。

-
图像修复
将残缺的图像补全、也可以用于去除纹身、电视logo、水印等。

-
图像到图像的转换
根据一幅图像生成生成另一幅风格不同图像,比如马变成斑马图、航拍地图变成地图

-
风景动漫化
将风景图转化为动漫效果

-
漫画脸
将人脸图生成卡通风格

-
图像上色
黑白影像上色

-
文本转图像
根据文字描述生成对应图像

GAN的应用常用非常广泛,远远不止上述几种。

