
- 1c语言之贪吃蛇源码,C语言之贪吃蛇经典源码
- 2grafana报错This panel requires Angular (deprecated)
- 3c 字符串数组 复制操作_c语言输入字符串保存到数组中,将奇数位上的字符串复制到另一个数组并输
- 4Android:如何从源码编译OpenCV4Android库_android ndk 编译opencv4.8.1
- 5对Redis的安装及使用,idea上的配置--保姆级教程_idea中 redis
- 6平平科技工作室-其他-QQ消息轰炸机
- 7使用Python完成简单登录系统_python用户登录(输入用户名和密码)
- 8对话AI大模型:Prompts提示指南与应用探索_promptes ai
- 9自从知道了这10个chatGPT网站以后,我就成了同学们眼中的AI大神,关键免费还好用_海螺ai和chatgpt哪个好
- 10Vue3+vite搭建基础架构(5)--- 使用vue-i18n_vite-plugin-vue-i18n
论文阅读--Search to Distill
赞
踩
Abstract
Standard Knowledge Distillation (KD) approaches distill the knowledge of a cumbersome teacher model into the parameters of a student model with a pre-defined architecture. However, the knowledge of a neural network, which is represented by the network’s output distribution conditioned on its input, depends not only on its parameters but also on its architecture. Hence, a more generalized approach for KD is to distill the teacher’s knowledge into both the parameters and architecture of the student. To achieve this, we present a new Architecture-aware Knowledge Distillation (AKD) approach that finds student models (pearls for the teacher) that are best for distilling the given teacher model. In particular, we leverage Neural Architecture Search (NAS), equipped with our KD-guided reward, to search for the best student architectures for a given teacher.Experimental results show our proposed AKD consistently outperforms the conventional NAS plus KD approach, and achieves state-of-the-art results on the ImageNet classification task under various latency settings. Furthermore, the best AKD student architecture for the ImageNet classification task also transfers well to other tasks such as million level face recognition and ensemble learning.
翻译:
标准的知识蒸馏(KD)方法将笨重的教师模型的知识蒸馏到具有预定义架构的学生模型的参数中。然而,神经网络的知识,即网络在给定输入条件下的输出分布,不仅取决于其参数,还取决于其架构。因此,对于KD的一种更广义的方法是将教师的知识蒸馏到学生的参数和架构中。为了实现这一点,我们提出了一种新的基于架构的知识蒸馏(AKD)方法,该方法找到最适合蒸馏给定教师模型的学生模型(对于教师来说是珍珠)。具体来说,我们利用带有我们的KD引导奖励的神经架构搜索(NAS)来搜索最适合给定教师模型的学生架构。实验结果表明,我们提出的AKD方法在不同延迟设置下始终优于传统的NAS加KD方法,并在ImageNet分类任务上取得了最先进的结果。此外,针对ImageNet分类任务的最佳AKD学生架构也很好地转移到其他任务,例如百万级人脸识别和集成学习。
Introduction
相同任务和数据集上训练的不同教师模型的最佳学生架构可能不同,所以利用NAS自主搜索最佳架构
Motivated by these observations, this paper proposes a new generalized approach for KD, referred to as Architecture-aware Knowledge Distillation (AKD), which finds best student architectures for distilling the given teacher model. The proposed approach (Fig 3) searches for student architectures using a Reinforcement Learning (RL) based NAS process [43] with a KD-based reward function. Our results show that the best student architectures obtained by AKD achieve state-of-the-art results on the ImageNet classification task under several latency settings (Table 7) and consistently outperform the architectures obtained by conventional NAS [34] (Table 5). Surprisingly, the optimal architecture obtained by AKD for the ImageNet classification task generalizes well to other tasks such as million-level face recognition (Table 9) and ensemble learning (Table 10). Our analysis of the neural architectures show that the proposed AKD and conventional NAS [34] processes select architectures from different regions of the search space (Fig 5). In addition, our analysis also verifies our assumption that the best student architectures for different teacher models differ (Fig 6). To the best of our knowledge, this is the first work to investigate and utilize structural knowledge of neural architectures in KD on largescale vision tasks.
翻译:
受到这些观察的启发,本文提出了一种新的广义KD方法,称为基于架构的知识蒸馏(AKD),用于找到最适合蒸馏给定教师模型的学生架构。所提出的方法(图3)利用基于强化学习(RL)的NAS过程[43],并采用基于KD的奖励函数来搜索学生架构。我们的结果表明,AKD获得的最佳学生架构在多个延迟设置下在ImageNet分类任务上取得了最先进的结果(表7),并且始终优于传统NAS[34]得到的架构(表5)。令人惊讶的是,AKD在ImageNet分类任务中获得的最佳架构在其他任务(如百万级人脸识别(表9)和集成学习(表10))上也具有很好的泛化性能。我们对神经架构的分析表明,提出的AKD和传统NAS[34]过程选择了搜索空间的不同区域中的架构(图5)。此外,我们的分析还验证了我们的假设,即针对不同教师模型的最佳学生架构是不同的(图6)。据我们所知,这是第一项在大规模视觉任务中研究和利用神经架构的结构知识进行KD的工作。
Knowledge distillation

作者挑了8个模型作为teacher

这5个student模型是从 MNAS 的搜索空间搜出来的

Teacher - a 和 Teacher - b 是分布比较接近的,但是其对应的学的好的 student 模型却完全不一样
上述的分析都是说明 structural knowledge 对 KD 的重要性,如果我们像标准KD那样只使用预定义的学生架构来提取知识,它可能会迫使学生牺牲自己的参数来学习老师的架构,这最终会得到一个非最优解
Architecture-aware knowledge distillation
KD-guided NAS
Inspired by recent mobile NAS works [34, 35], we employ a reinforcement learning (RL) approach to search for latency-constrained Pareto optimal solutions from a large factorized hierarchical search space. However, unlike previous NAS methods, we add a teacher in the loop and use knowledge distillation to guide the search process. Fig. 3 shows our overall NAS flow, which consists of three major components: an RL agent for architecture search, a search space for sampling student architectures, and a training environment for obtaining KD-guided reward.
翻译:
受最近移动NAS工作的启发[34, 35],我们采用了一种强化学习(RL)方法,从一个大型的分层搜索空间中搜索受延迟约束的帕累托最优解。然而,与以往的NAS方法不同的是,我们在搜索过程中加入了一个教师,并利用知识蒸馏来指导搜索过程。图3显示了我们的整体NAS流程,包括三个主要组件:用于架构搜索的RL代理,用于采样学生架构的搜索空间,以及用于获取KD引导奖励的训练环境。

AKD与传统NAS的搜索空间是不同的,传统NAS搜索空间更大
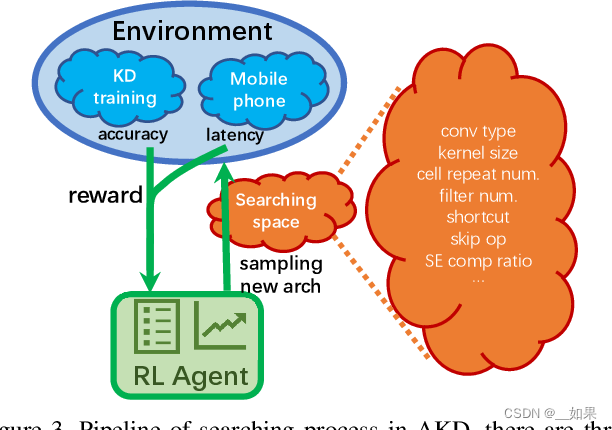
RL agent
Similar to other RL-based approaches [43, 45, 34], we use a RNN-based actor-critic agent to search for the best architecture from the search space. Each RNN unit determines the probability of different candidates for a search option. The RNN weights are updated using PPO algorithm [30] by maximizing the expected KD-guided reward.
翻译:
与其他基于RL的方法[43, 45, 34]类似,我们使用基于RNN的actor-critic代理从搜索空间中搜索最佳架构。每个RNN单元确定了搜索选项的不同候选项的概率。通过最大化预期的KD引导奖励,使用PPO算法[30]更新RNN权重。
Search Space
Similar to [34], our search space consists of seven predefined blocks, with each block contains a list of identical layers. Our search space allows us to search for the number of layers, the convolution and skip operation type, conv kernel size, squeeze-and-excite ratio, and input/output filter size, for each block independently.
翻译:
与[34]类似,我们的搜索空间包括七个预定义的块,每个块包含一个相同层的列表。我们的搜索空间允许我们独立地为每个块搜索层数、卷积和跳过操作类型、卷积核大小、压缩激活比率以及输入/输出滤波器大小。
KD-guided reward
Given a sampled student architecture from our search space, we train it on a proxy task to obtain the reward. Unlike prior NAS works, we perform KD training with a teacher network to obtain KD-guided accuracy. Meanwhile, we also measure the latency on mobile devices, and use the same weighted product of accuracy and latency in [34] as the final KD-guided reward to approximate Pareto-optimal solutions.
翻译:
在我们的搜索空间中给定一个采样的学生架构,我们对其进行代理任务训练以获得奖励。与以往的 NAS 工作不同,我们使用一个教师网络进行 KD 训练以获取 KD 引导的准确性。与此同时,我们还在移动设备上测量延迟,并使用与[34]中相同的准确性和延迟的加权乘积作为最终的 KD 引导奖励,以近似 Pareto 最优解。
Understanding the searching process
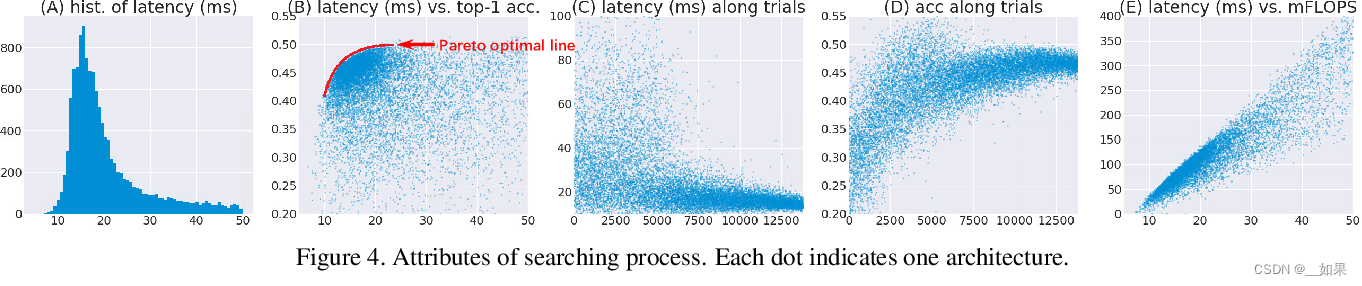
(A):target latency 是 15 ms,可以看出采样比较多的地方都集中在 15 ms附近;
(B):latency-accuracy 之间的权衡,x轴越大,latency 越高,准确率越高。因此搜索的最优解就是在画出来的那条红线附近;
(C,D):随着采样时间的增加,latency 越来越接近 15 ms,Acc 也越来越高;
(E):模型的 latency 和 FLOPS 之间的关系,大致是成线性相关的。

为了更好地展示 AKDNet 和 NASNet 的区别,作者把他们两个采样的点随着采样时间的增加的变化可视化的出来。可以看出越到后面的时候,两种方法采样的点完全分开了
Understanding the structural knowledge
问题1: 如果两个相同的 RL Agent 用不同的 teacher model 提供 award,他们会收敛到搜索空间的相同点上吗?
答案是这两个 Agent 会收敛到完全不同的点,如下图所示

问题2: 如果两个不同的 RL Agent 用相用的 teacher model 提供 award,他们会收敛到搜索空间的相同点上吗?
结论是会收敛到的位置会非常相似,如下图。作者认为这样就验证了 KD 过程中存在 structural knowledge 的假设

Conclusion & further thought
This paper is the first that points out the significance of structural knowledge of a model in KD, motivated by the inconsistent distillation performance between different student and teacher models. We raise the presumption of structural knowledge and propose a novel RL based architectureaware knowledge distillation method to distill the structural knowledge into students’ architecture, which leads to surprising results on multiple tasks. Further, we design some novel approach to investigate the NAS process and experimentally demonstrate the existence of structural knowledge.
The optimal student models in AKD can be deemed as the most structure-similar to the teacher model. This implies a similarity metric of the neural network may occur but never be discovered. It is interesting to see whether we can find a new metric space that can measure the similarity between two arbitrary architectures. If so, it would nourish most of the areas in machine learning and computer vision.
翻译:
本文是首次指出模型结构知识在知识蒸馏中的重要性,受到不同学生模型和教师模型之间的不一致蒸馏性能的启发。我们提出了结构知识的假设,并提出了一种基于强化学习的结构感知知识蒸馏方法,将结构知识蒸馏到学生的架构中,这在多个任务上产生了令人惊讶的结果。此外,我们设计了一些新的方法来研究 NAS 过程,并通过实验证明了结构知识的存在。
AKD 中的最佳学生模型可以被视为与教师模型最相似的模型。这意味着神经网络的相似性度量可能存在但从未被发现。有趣的是,我们是否可以找到一个新的度量空间,可以衡量任意两个架构之间的相似性。如果是这样,它将有助于机器学习和计算机视觉领域的大部分领域的发展。

