
- 1docker错误 download failed after attempts=6 :net/http :tls handshake timeout_docker: error pulling image configuration: downloa
- 2[附源码]java+ssm计算机毕业设计医院药品进销存系统【源码+数据库+LW+部署】_公立医院的进销存数据需要本地部署吗?
- 3Netbeans的编译和打包ant脚本----英文版_netbeans ant
- 4操作系统内核概念
- 5关于计算机如何区分有符号数与无符号数_有符号数和无符号数的区别
- 6mybatis动态SQL对数据库执行增删改查学习笔记_getusercountbyroleid为根据角色id查询该角色下是否有用户信息。返回该角色id下的
- 7西南科技大学数字电子技术实验一(数字信号基本参数与逻辑门电路功能测试及FPGA 实现)FPGA部分_大学数电实验
- 8SAP HR 工资核算异常的一些处理方式_sap 重新入职人员工资核算 报错期间开始 2023.10.01 早于最早可能的 ra 运行日期
- 9Windows 源码编译 MariaDB_mariadb odbc 驱动源码 windows 下 如何编译
- 10报错:The installer has encountered an unexpected error installing this package 使用超管运行安装文件
flink尚硅谷
赞
踩
flink
1 flink基础使用
flink是一种分布式任务处理引擎
事件驱动:有数据来才进行处理,不来就不动。程序一旦开始就会一直运行
现在使用的是datastreamsource作为数据源
demo:


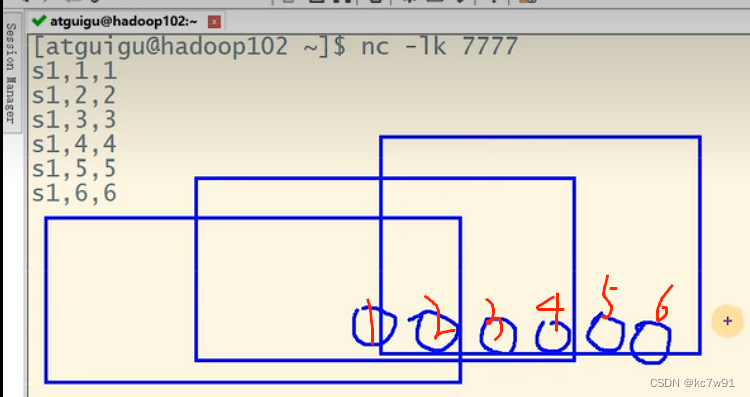
读socket这种无界流:
发送数据端:
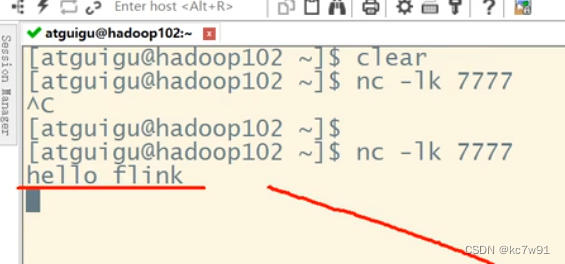
flink端绑定一个无界数据源:

1.1 角色
三种角色:客户端、job manager、task manager
客户端提交job给job manager
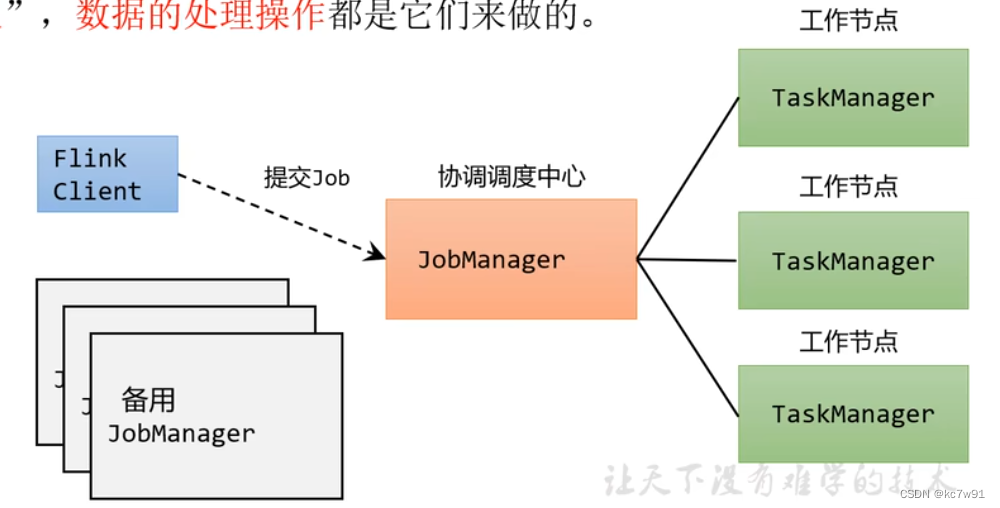
1.2 部署模式(抽象)
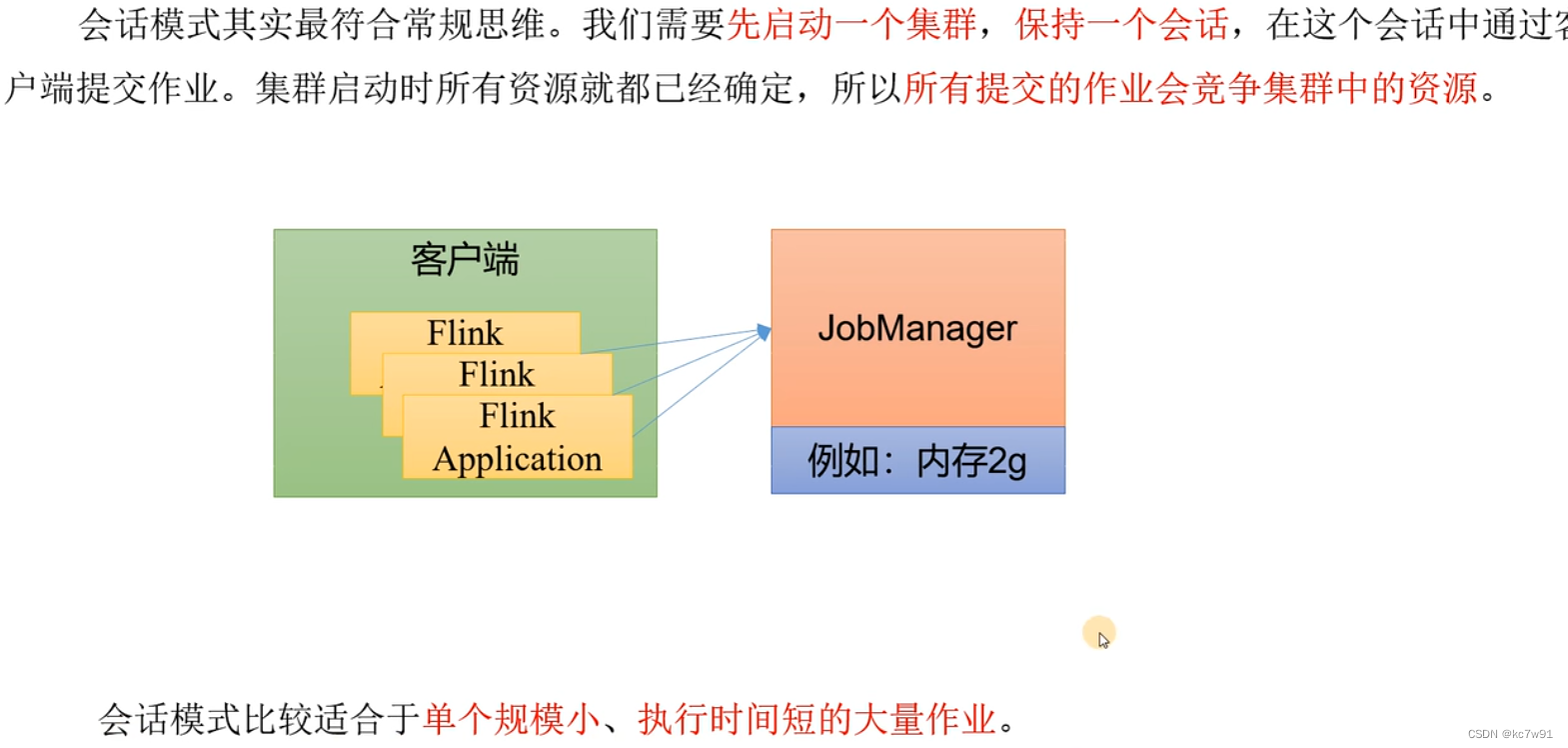
1.2.1 会话模式
提前启动一个flink集群,一旦提交一个任务就交给这个集群做
1.2.2 单作业模式
不提前启动集群,一个作业提交了,为这个作业单独启动一个集群【每个作业都是隔离的,业务场景首选】
这种方式在flink1.17之后已经快要被淘汰了
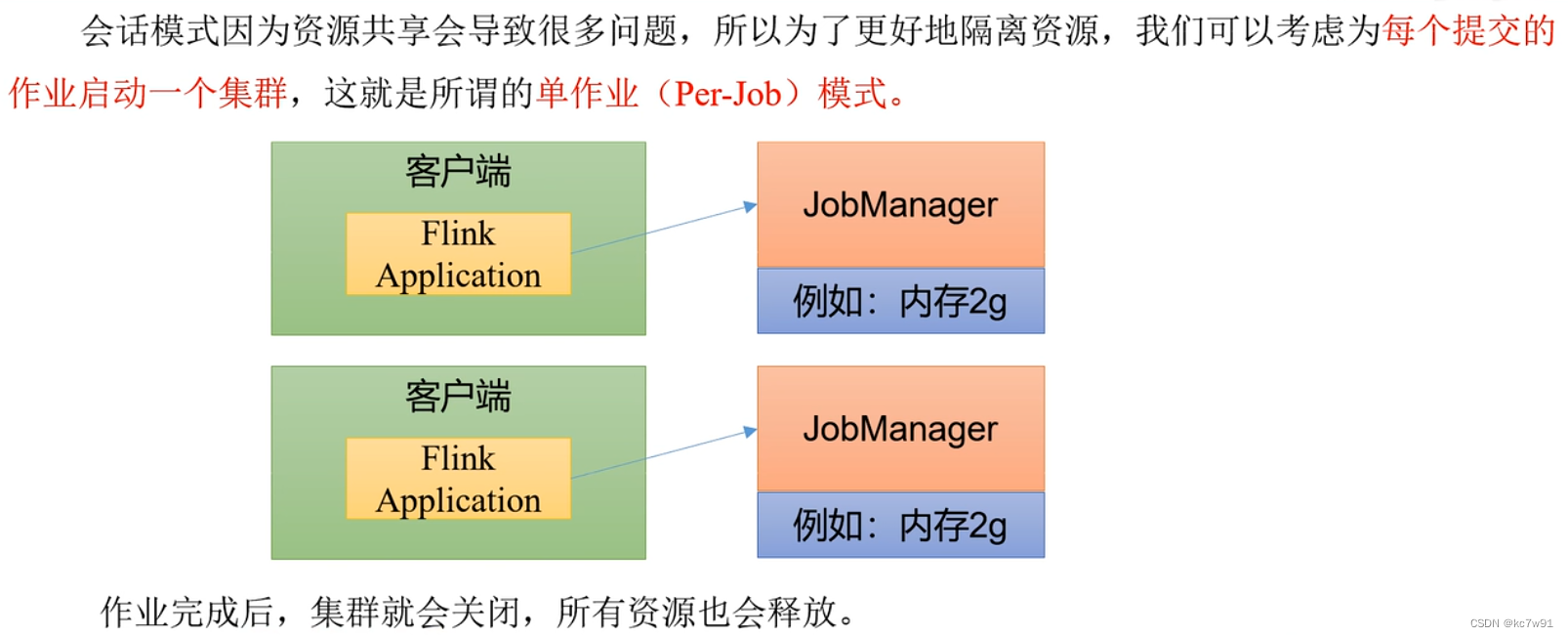
需要注意的是,Flik本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如YARN、Kubernetes(K8S)
1.2.3 应用模式
与(2)相比,代码在客户端解析==>代码在job manager解析,其余一致

1.3 运行模式(实际 谁来管理资源)
1.3.1 Stand alone

(1)通过会话模式部署:
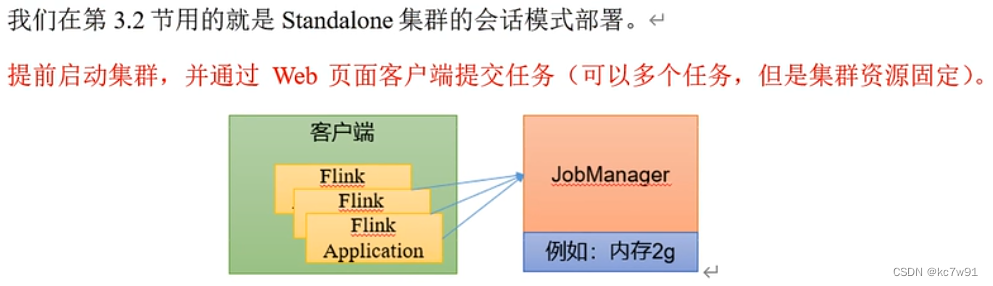
(2)不支持单作业模式部署:

(3)通过应用模式部署
按照如下命令启动job manager

查看,发现应用模式部署成功

创建task manager:

1.3.2 YARN运行模式(重点)

可以通过三种部署模式实现YARN部署,区别在于起flink的指令参数不同
推荐应用模式部署
跟hdfs联合使用,先把文件传输到hdfs
2. 运行时架构
2.1 系统架构

客户端提交的一个job对应一个job master,job manager相当于进程,job master相当于线程
job manager中三大组件:分发器、job master、资源管理器
请求slot相当于请求资源
节点之间通过actor通讯系统进行沟通
2.2 核心概念
2.2.1 并行度
一个算子:指一种操作,比如sum/map/apply,每个操作都算是一个算子
keyby不算算子,只是一种转换操作
一个算子包含多个子任务:指一个算子的活让多个人去干,n个子任务干,并行度就叫n
一个流程的并行度是流程中每个步骤的并行度取max
默认并行度是cpu核数的二倍
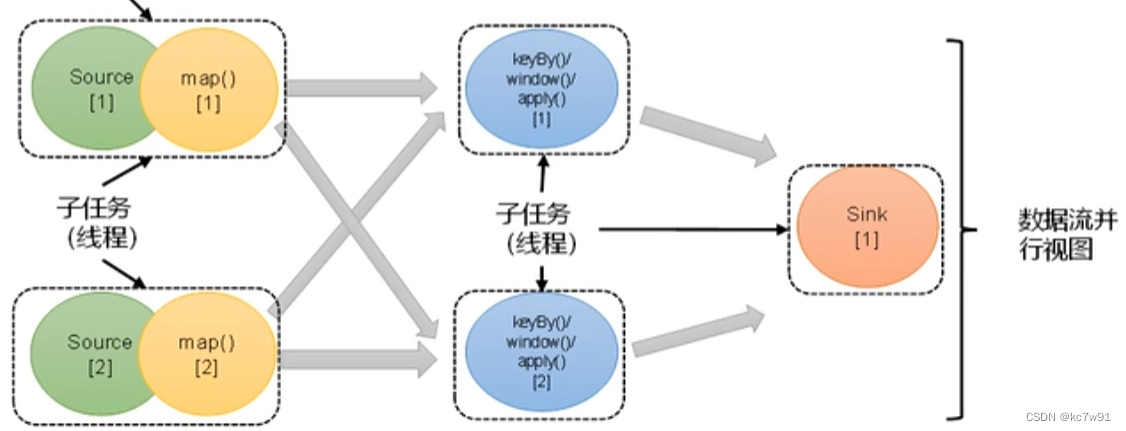
2.2.2 算子链

上图中,每一列是一个算子,每个圆圈是一个任务
前置知识-算子之间的两种传输关系:


数据重分区可能是由并行度引起的,也可能是由keyby分组引起的(keyby导致数据重分区)
引入算子链:

并行度相同+一对一

针对某个算子前后禁用算子链:
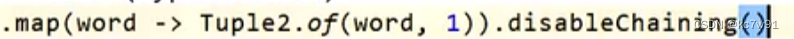
从当前算子开始新链:

实际应用:两个重量级算子不应该串在一起,断开算子链还能帮助定位错误
2.2.2 任务槽

注意:slot大小是固定的,能够均分隔离内存,但是不能隔离cpu
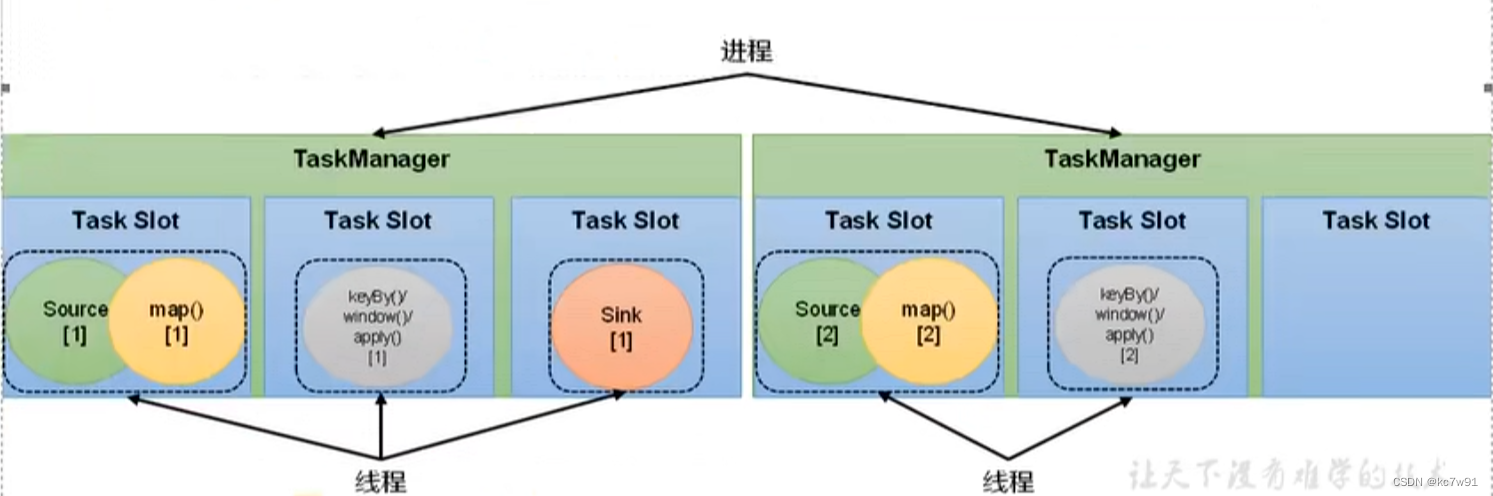
一个 TaskManager 可以同时执行多个任务的子任务,这些子任务可以是不同的算子或操作符
不同算子的子任务才能处于同一个槽中,同一个槽里的三个任务同时进行,处理数据批次的进度不同
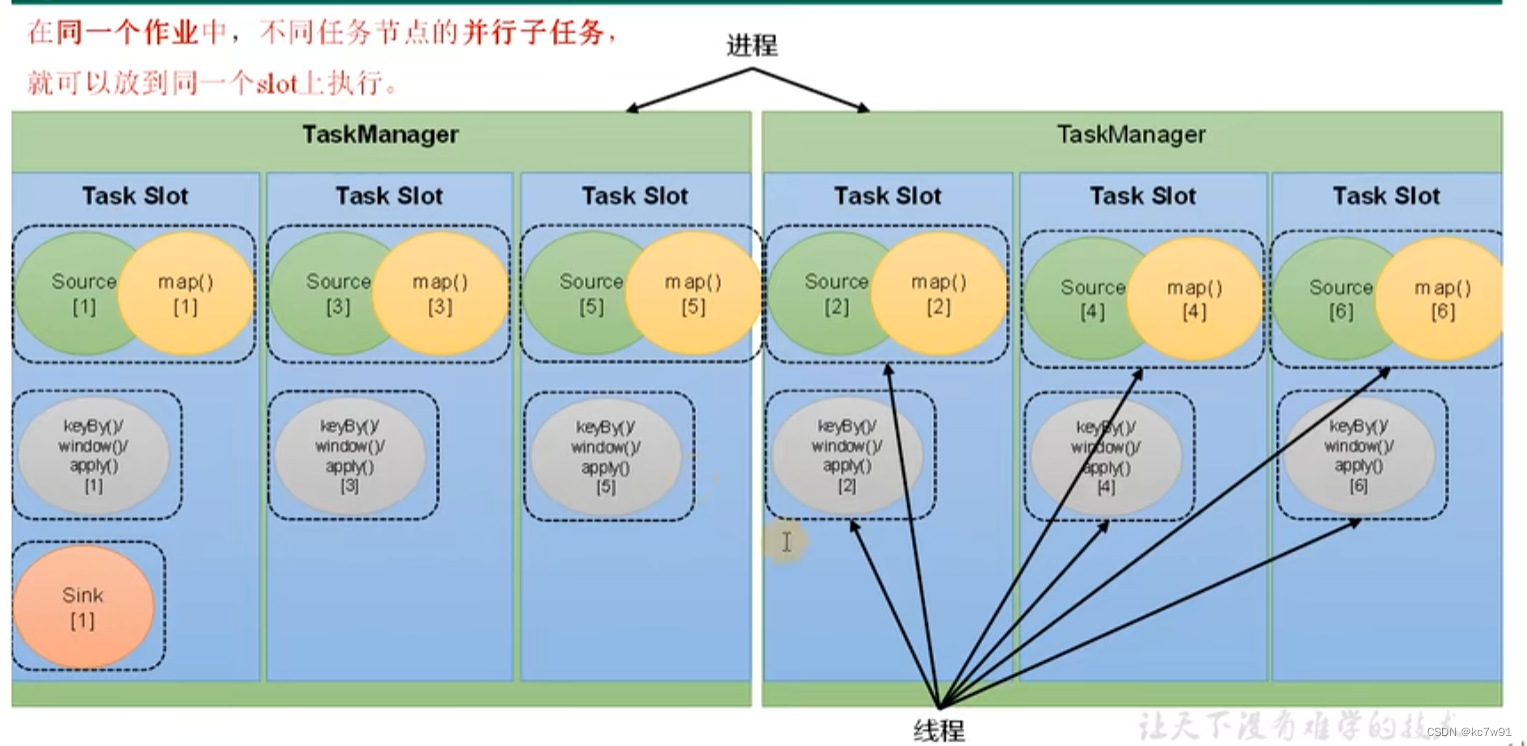

总结:

3 DataStream api
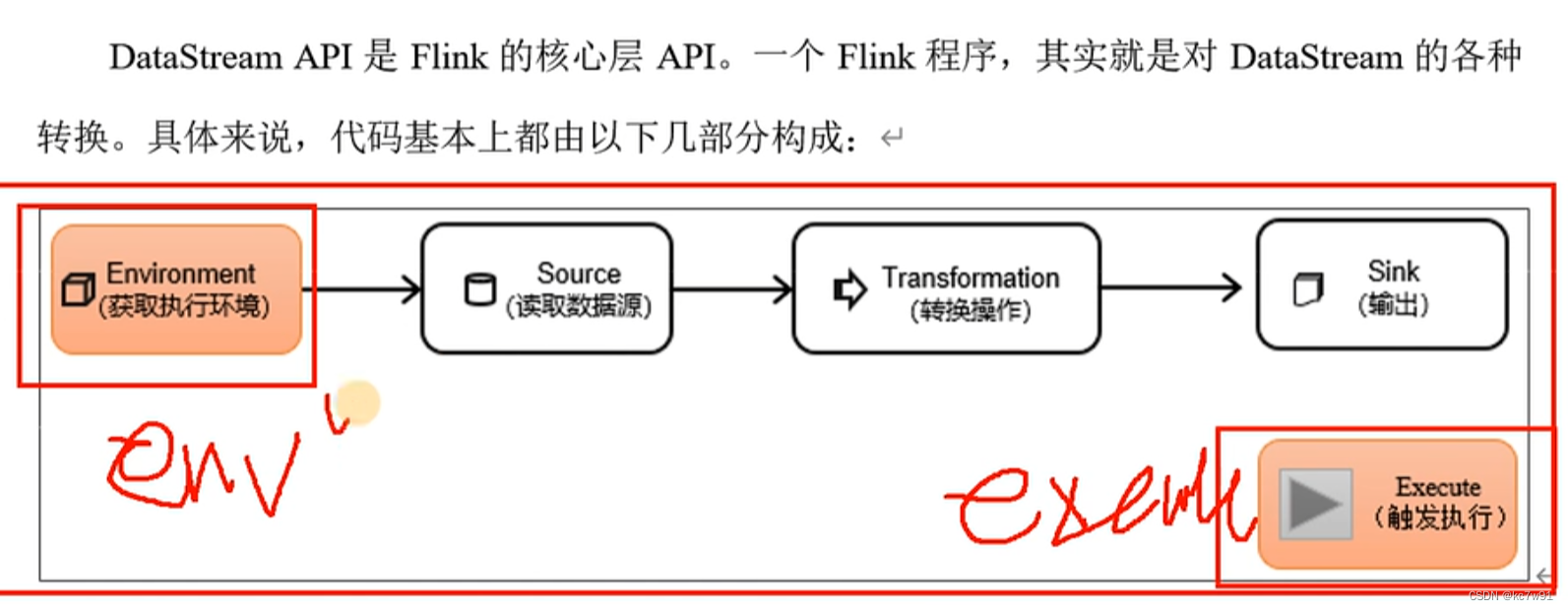
3.1 创建环境
StreamExecutionEnvironment.getExecutionEnvironment(conf)
自动分析是远程集群还是本地idea环境
最后触发执行:env.execute()执行当前flink job
如果想在一个main中执行多个job【不建议】:env.executeAsync() 异步执行获取结果
流处理:一直来一直处理;批处理:一批到全了开始处理
3.2 source 读取数据源【源算子】
// 从集合读
DataStreamSource sc = env.fromCollection(array);
//从文件读 依赖于FileSource
DataStreamSource sc = env.fromSource(source的实现类(FileSource build出来的),watermark,名字);
//从socket读数据
DataStream sc = env.socketTextStream("localhost", 7777);
- 1
- 2
- 3
- 4
- 5
- 6
从Kafka读:第三方件
3.3 转换算子 transform
map
一进一出
实现mapfunction接口

filter
对每个元素进行判断,true保留反之丢弃
实现filterfunction接口

flatmap
扁平映射,一进多出
实现flatmapfunction接口
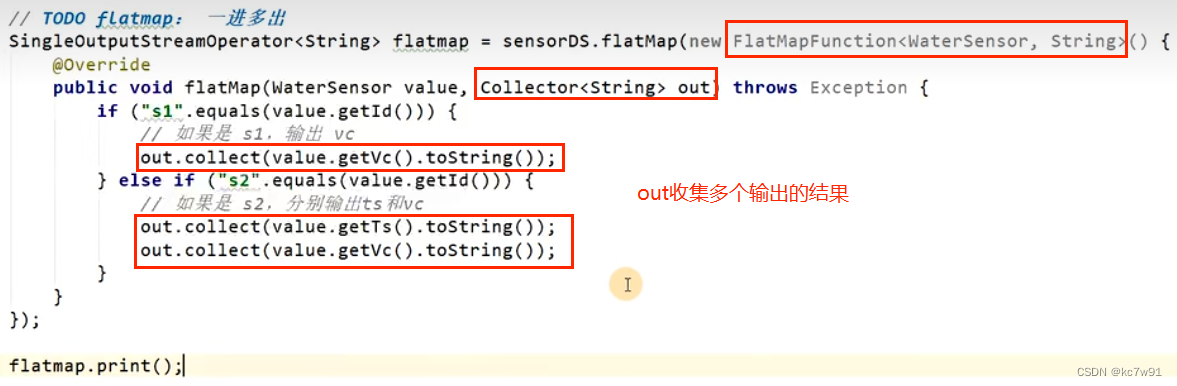
辨析:与map区别:
map使用return控制一进一出
flatmap没有返回值 使用collector来收集输出
3.4 聚合算子
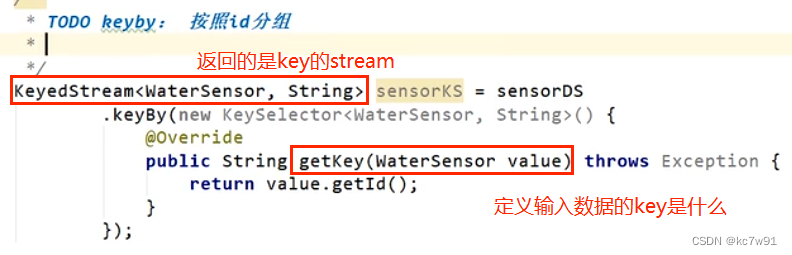
keyby
经过keyby才有后面的聚合算子,保证相同key发往同一个分区(即同一个子任务),但是不同key也可能在同一个分区
实现keySelector接口
keyby不是转换算子,因此不能设置并行度,只是对数据进行重分区
keyby之后得到keyedStream
sum/min/max/minby/maxby
keyby之后调用的
max:取比较字段最大值,非比较字段取第一次的值
maxby:取比较字段最大值,非比较字段取最大值字段所在数据行的数值

reduce
keyby之后调用的,输入输出类型需要保持一致,内部聚合逻辑比较灵活
reduce方法用于所有数据两两结合,前面累计的结果作为reduce函数的第一个参数,现在来的数据作为第二个参数
实现reduce Function接口

richMapFunction
为什么rich?多了生命周期管理方法,提供了子任务开启与关闭前的操作函数open、close,多了运行时上下文,获取运行时的环境信息

3.5 分区
分区算子 shuffle/rebalance(数据倾斜时使下游消费数据时是均匀的)/rescale(局部组队)


自定义分区器,自己实现分区逻辑:
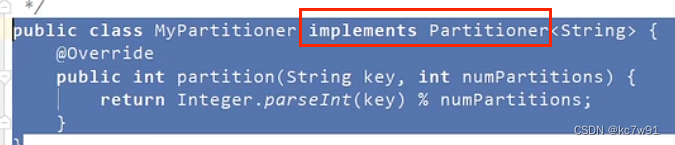

简化后:

3.6 分流、合流
分流:将数字分为奇数流和偶数流
没有合适算子,就用最底层的process算子
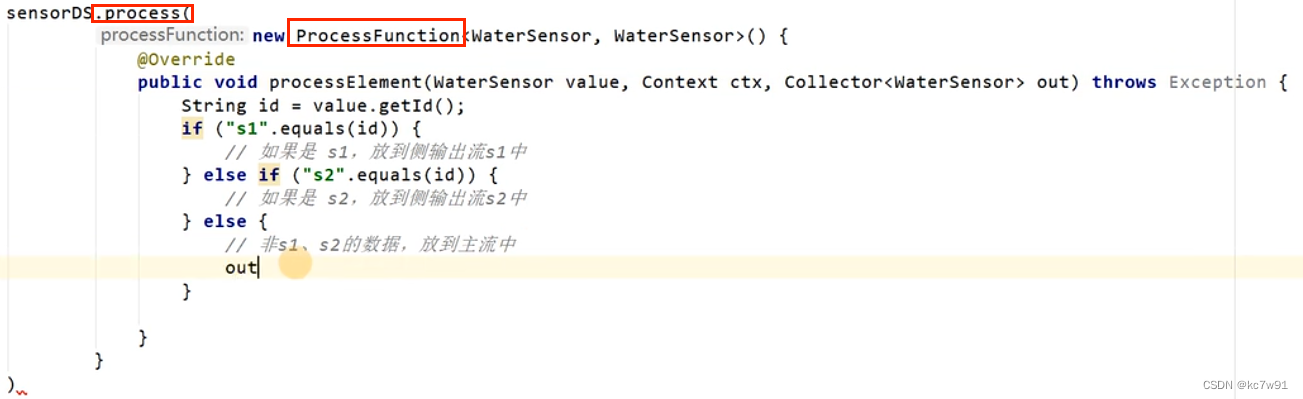
数据分流逻辑需要依赖支流的tag,这样才能标记往哪里放:

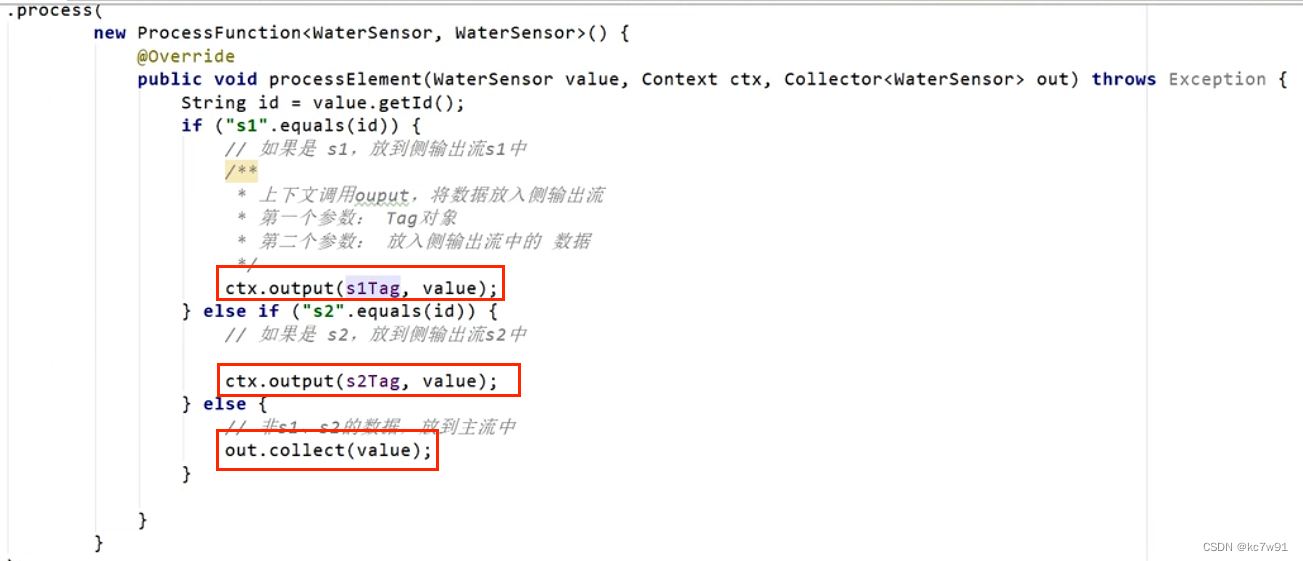

辨析:filter与分流方式的区别:前者几条流就要处理几遍,分流只需处理数据一遍

数据类型相同才能合流:
union合并多个流
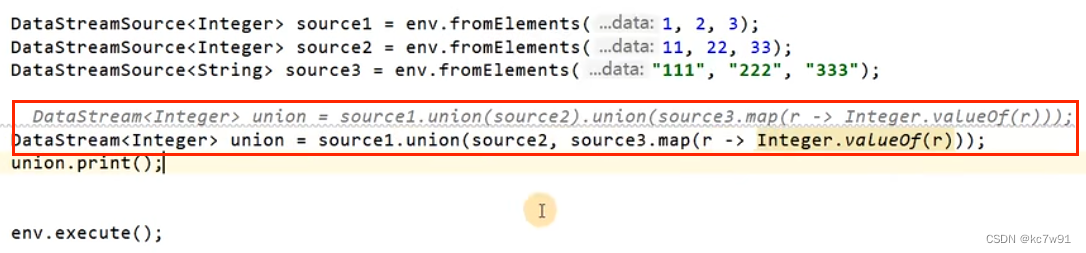
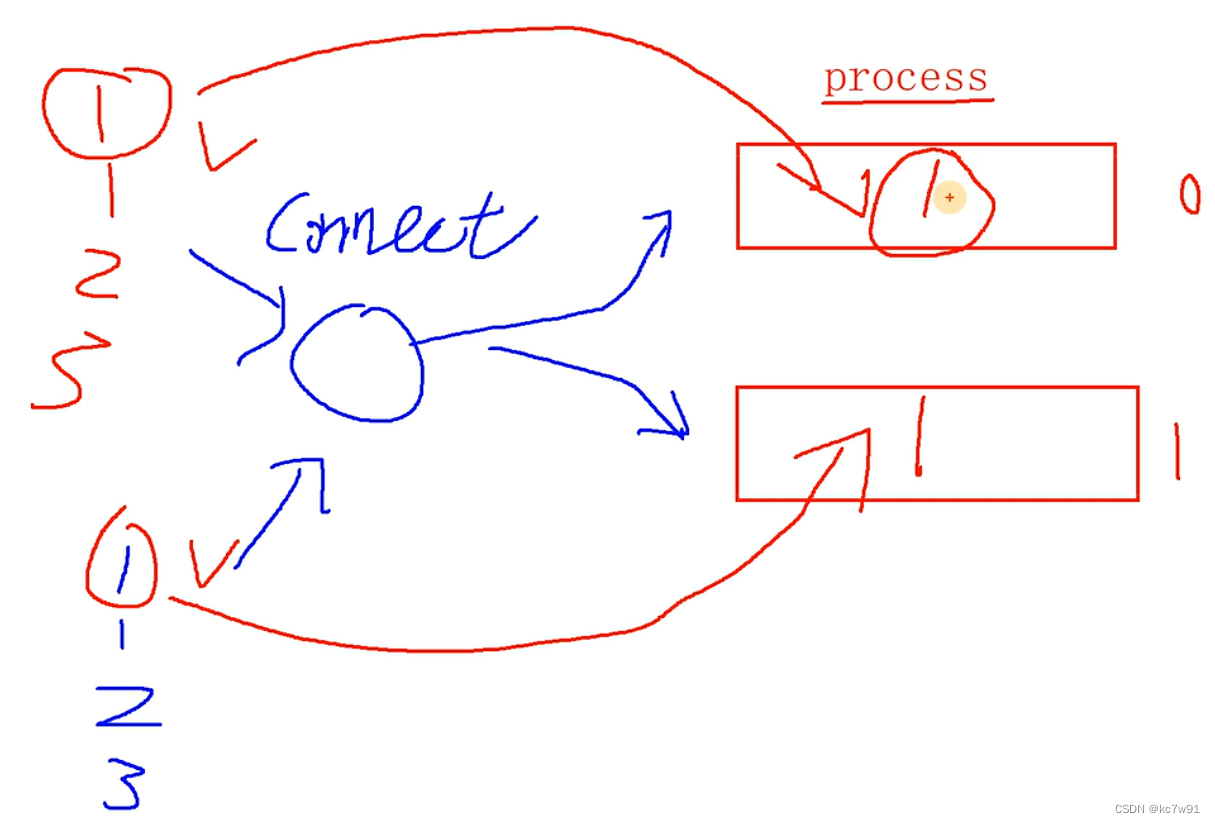
connect合并两个流(工作场景常用)
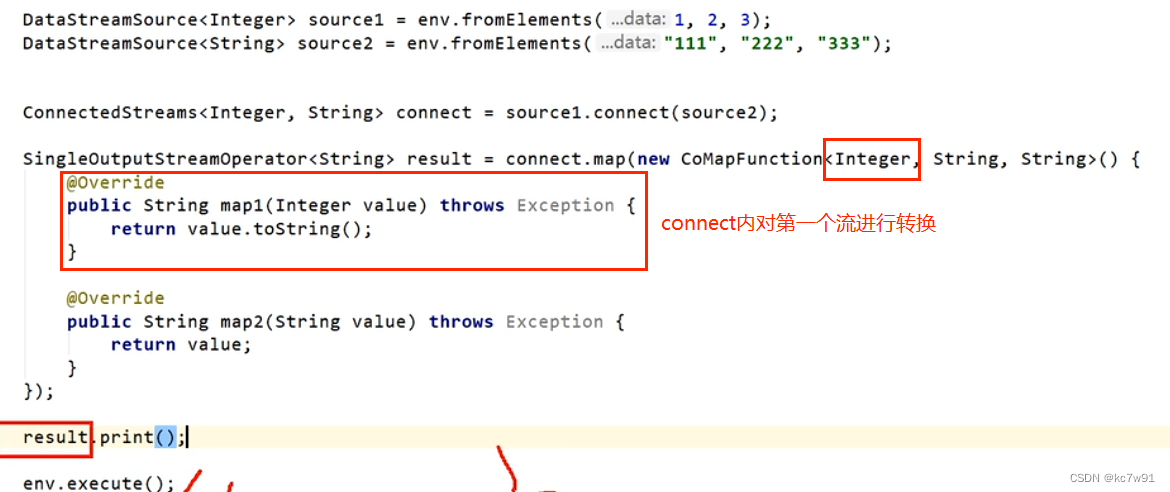
可编辑程度更高的demo,多并行度的情况下必须结合keyby使用:
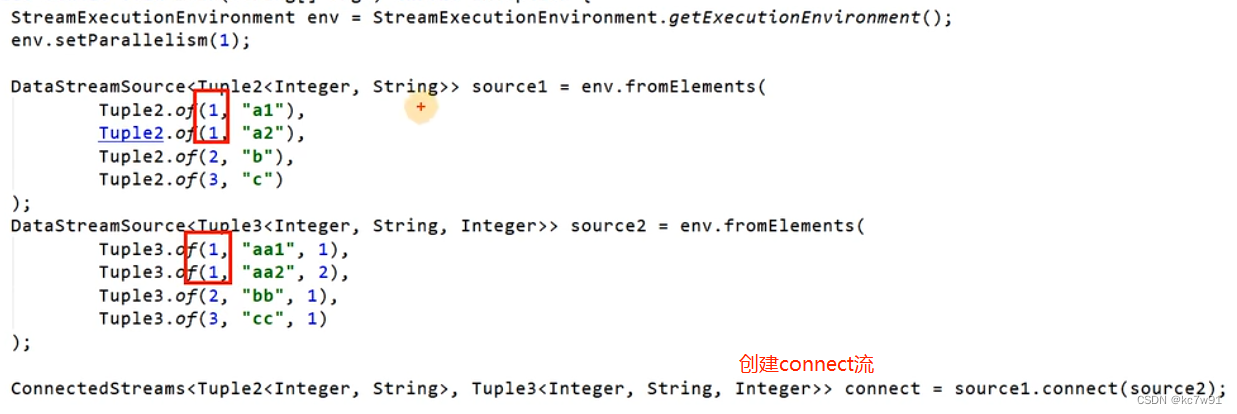

如果多并行度下没有结合keyby,会导致应该关联在一起的记录没有分在同一个分区(子任务):
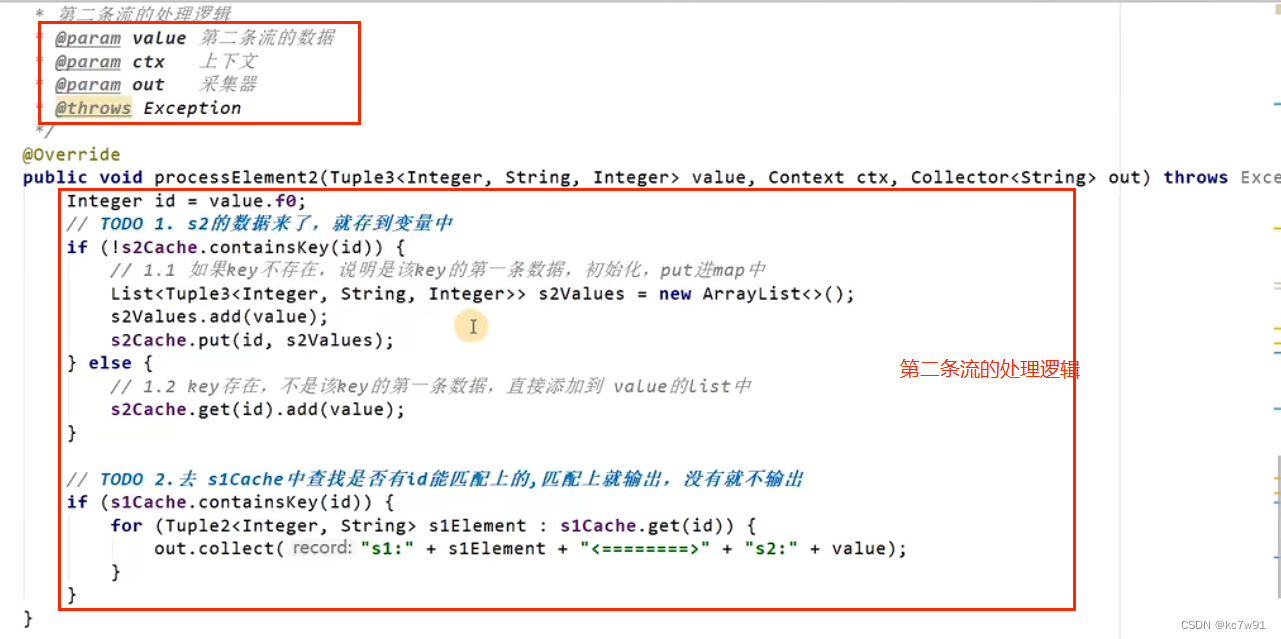
添加keyby操作:

3.7 输出算子
输出到文件:
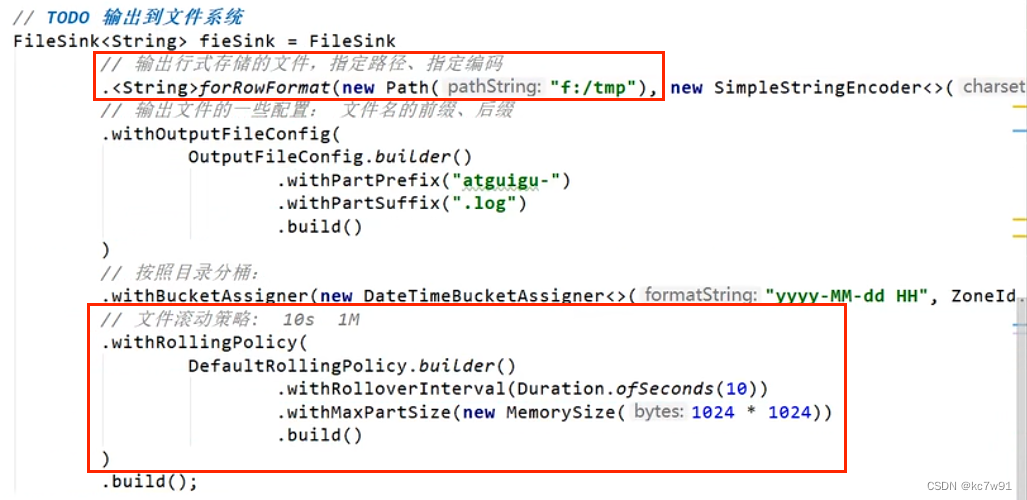

红框为必须设置,文件滚动策略表示达到标准后文件就结束
输出到Kafka:


输出到MySQL:
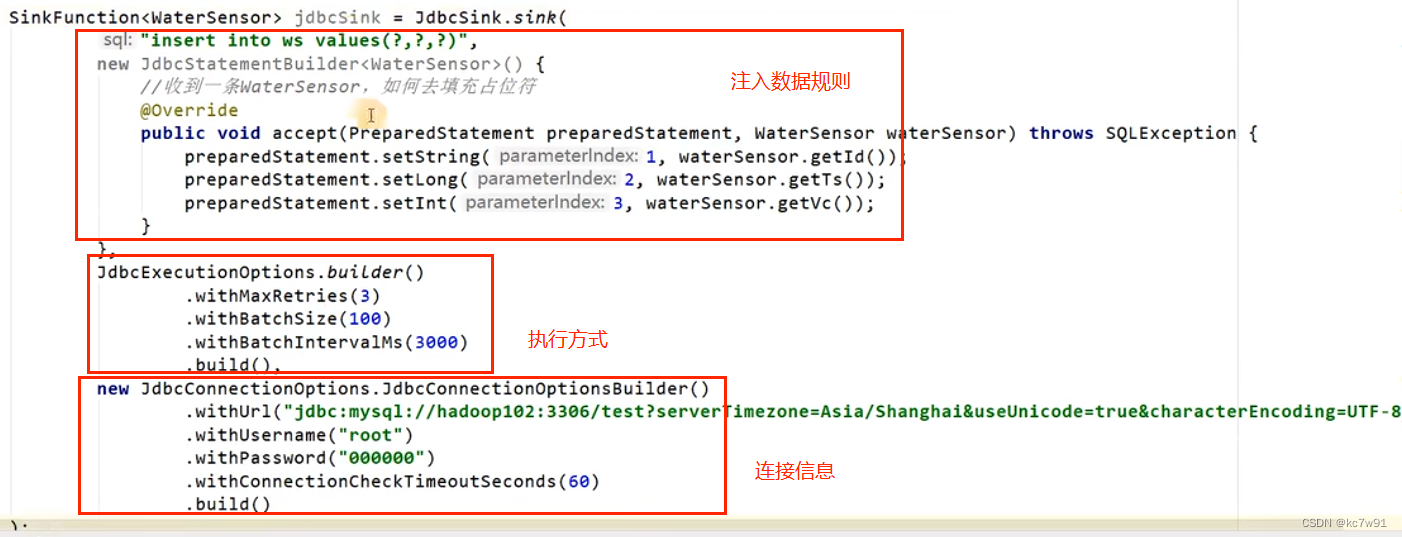
自定义sink逻辑:

RichSinkFunction带来的open与close方法是子任务开启/关闭时调用的
4. 窗口
分类:时间窗口,计数窗口
滚动窗口(固定大小,窗口无重叠)、滑动窗口(可以重叠,设置滑动步长)、会话窗口(只能基于时间,指定时间内没有数据来,则当前窗口关闭)
4.1 窗口分配器
这里进行窗口的定义

经过keyby的窗口:每个key单开一个窗口

没有keyby的窗口,所有数据不分流,公用一个窗口:


窗口划分后的stream类型转换:
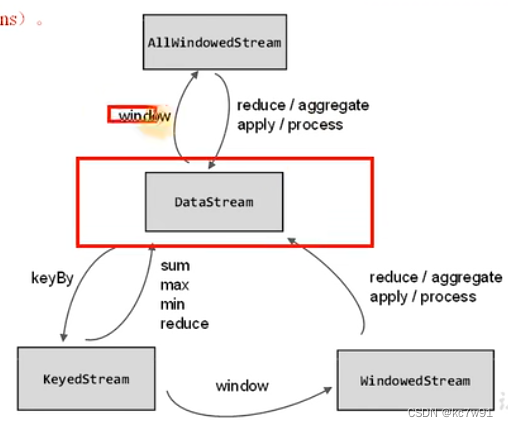
4.2 计算逻辑
4.2.1 增量聚合
reduce(强制输入类型、中间变量类型和输出类型全都保持一致):
demo:滚动窗口,5s一个

aggregate:(比reduce更灵活)


4.2.2 全窗口聚合
窗口内统一计算,可以获取上下文context
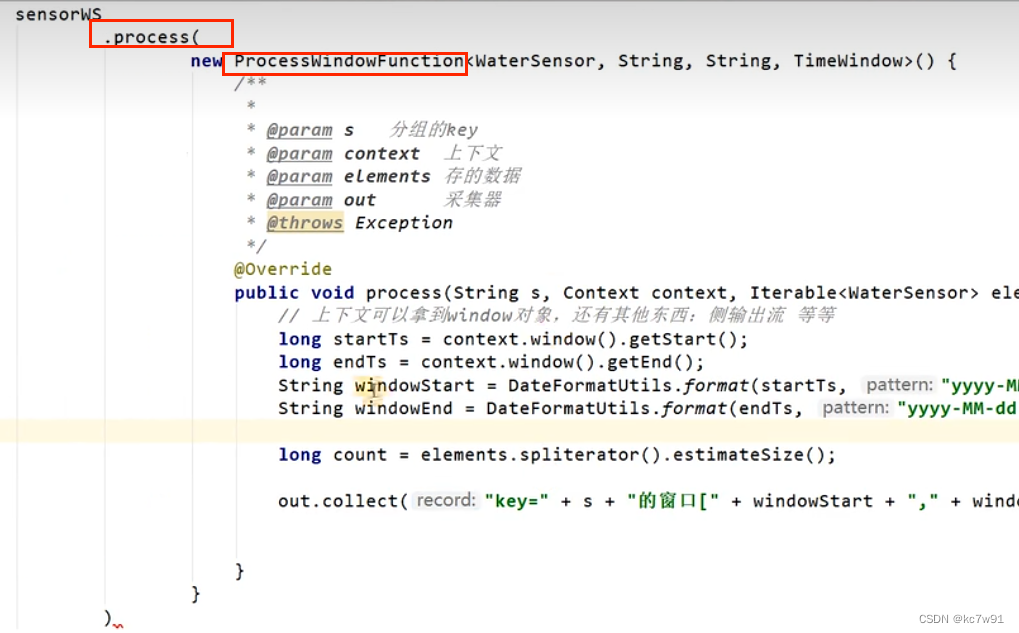
4.2.3 二者结合

既有增量(来一个处理一个节省空间)又有全量(上下文)

第一个参数是aggregateFunction(接口),第二个参数是processWindowFunction(接口)

4.3 关于按照数量的滑动窗口辨析
以长度为5步长为2的计数窗口举例:
每经过一个步长,都有一个窗口触发输出,第一次输出在第二条数据来的时候(想象前面有三个空数据)
第一条数据不代表是第一个窗口的起始,12两条数据是第一个窗口的结尾
4.4 触发器和移除器
触发器:

4.5 窗口的实现细节

5. 水位线 watermark(针对事件时间)
两种时间语义:事件时间&处理时间
水位线是插入到数据流中的一个标记,可以认为是特殊的数据。主要内容就是一个时间戳,用于表示当前事件时间的进展(必须单调递增)
watermark计算方式:当前最大事件时间 - 等待时间
水位线的制作:
理想状态,数据量小,来一条生产一条水位线
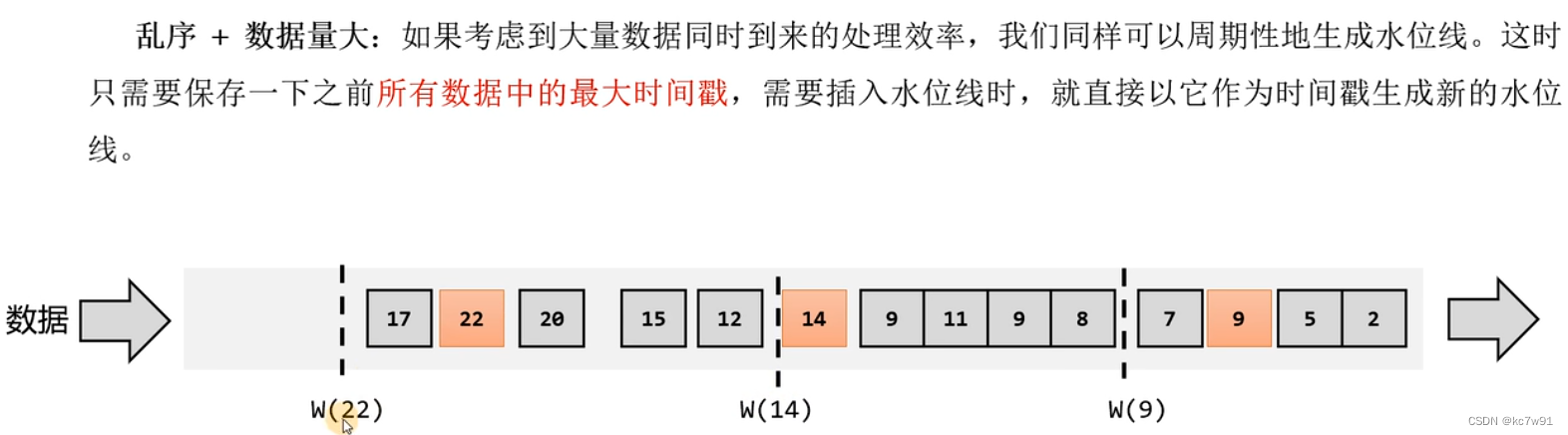
数据量大,隔一段时间生成一个水位线
乱序流:

乱序+数据量小:

乱序+数据量大:
取当前数据中最大时间戳
乱序流+允许迟到:
eg. 窗口长度为10,允许迟到两秒,当第10秒生成的数据到来时并不会触发窗口的关闭,因为等待机制会将当前时间视为10-2=8
当第12秒生产的数据来的时候才会触发窗口关闭,因为等待机制下当前时间为12-2=10
5.1 关于窗口与水位线的正确理解
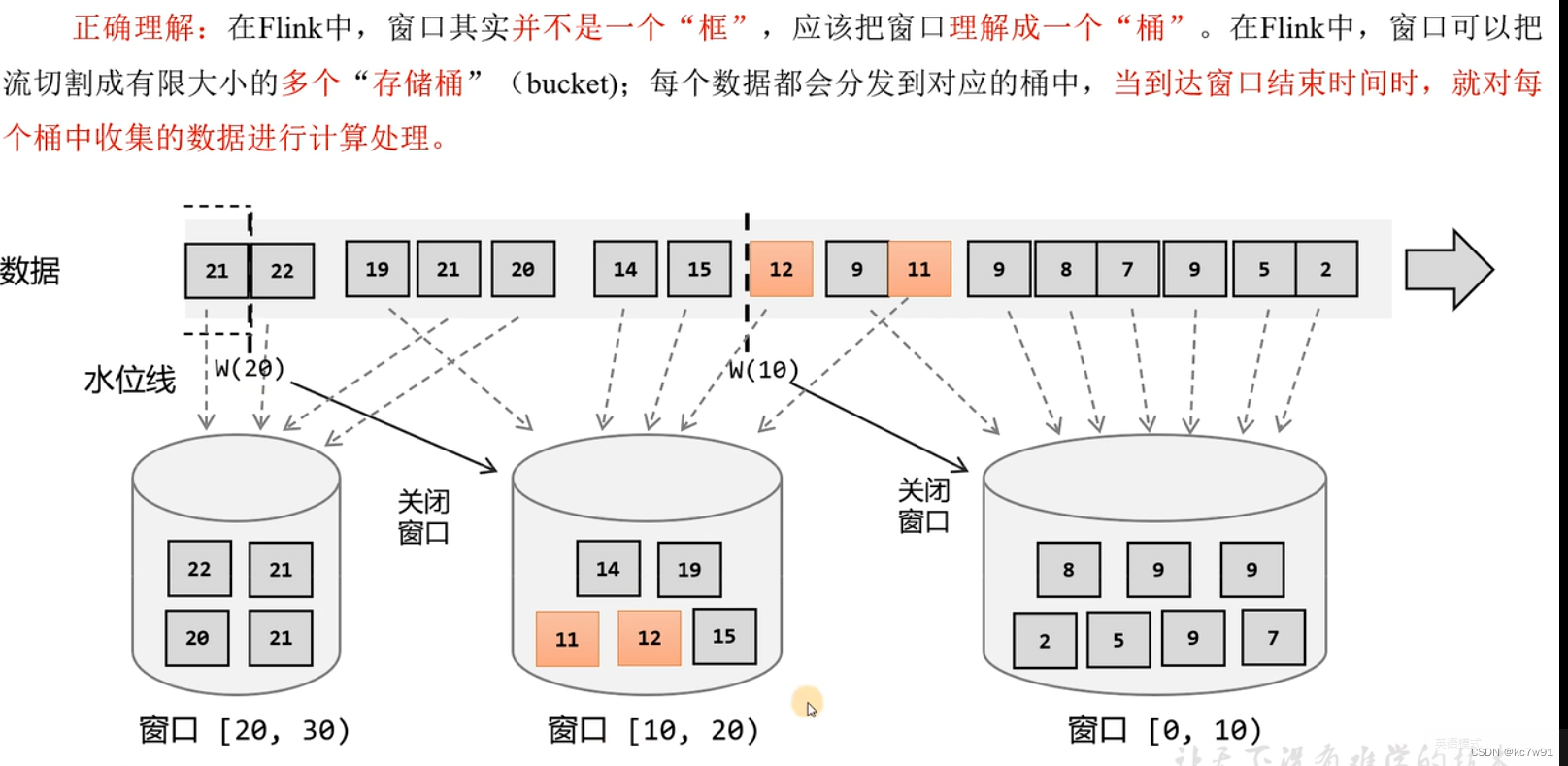
某一时刻可能存在多个窗口桶,水位线是用于控制窗口的关闭的
5.2 水位线生成策略

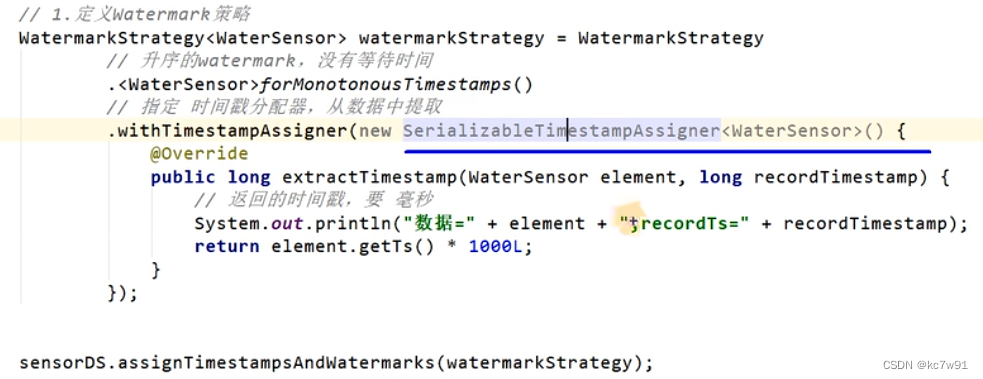
有序流demo:

乱序流demo:有等待时间
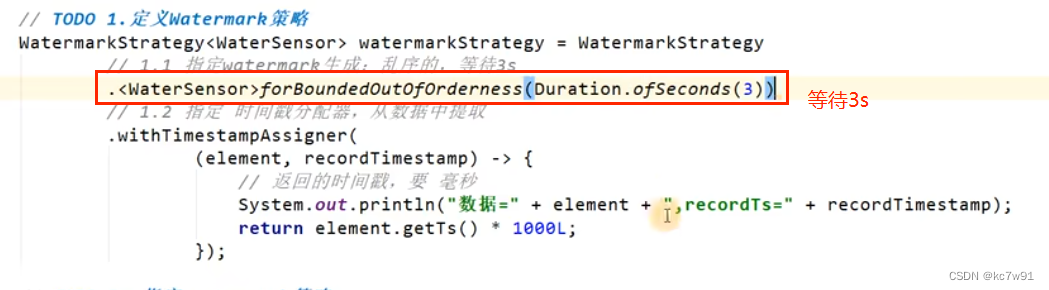
也可以在数据源阶段就指定水位线

5.3 水位线的传递
当一个子任务上游有多个子任务(水位线各不相同,即数据处理进度各不相同),取上游子任务最小的水位线作为当前子任务的水位线,再广播给所有需要的下游
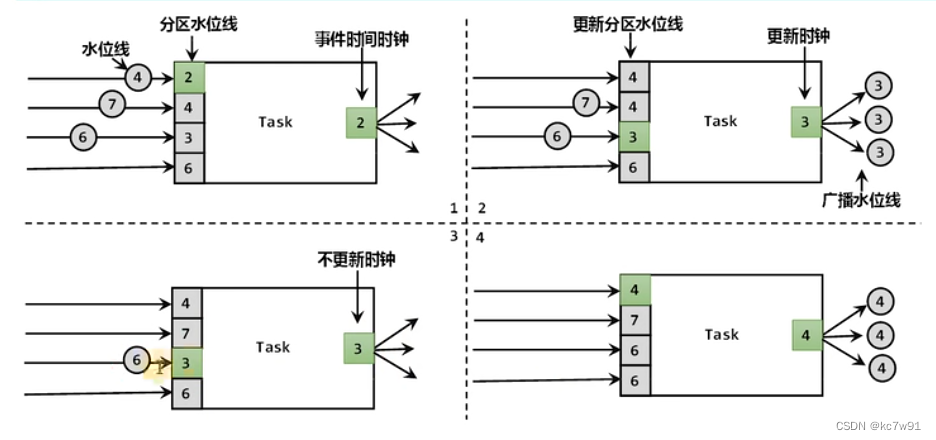

超过等待时间,则不把这个上游子任务的水位线作为当前水位线的min候选集

forMonotonousTimestamps() 只能有序数据,水位线也是升序的,没有等待时间
forBoundedOutOfOrderness(3) 允许乱序数据,设置等待时间
5.4 迟到数据处理
允许窗口晚关窗,晚到的数据额外处理,关窗后再来的数据不再处理:

辨析:window晚关窗和watermark等待有什么区别?

侧输出流(基于tag):

5.5 window join
合并两个流,将两条流的对应窗口内的内容两两合并
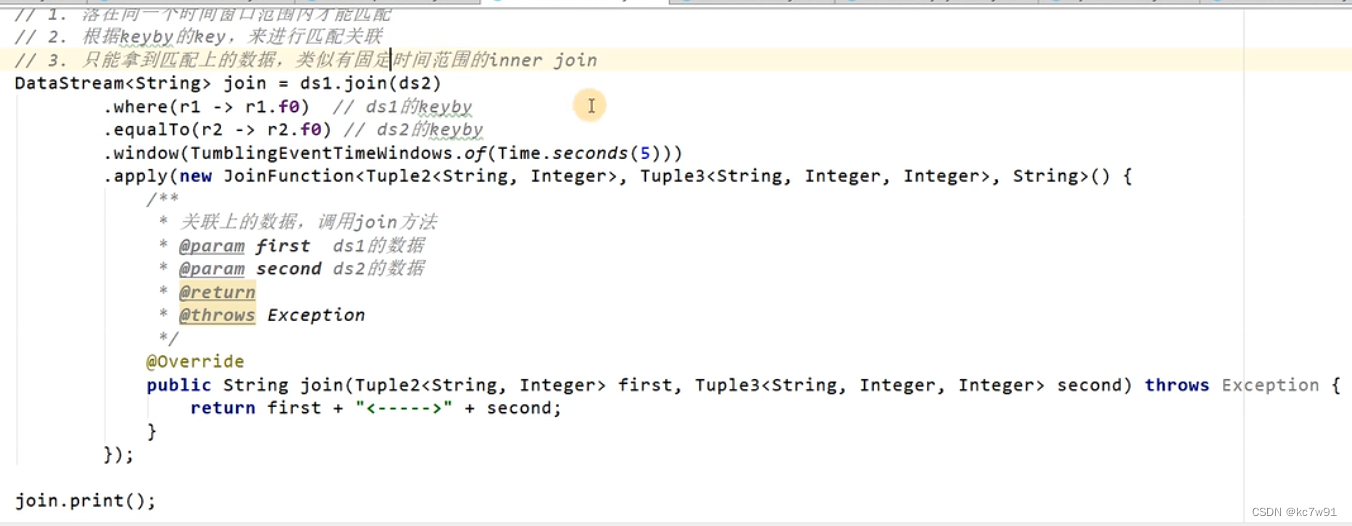
5.6 interval join
只支持事件时间语义
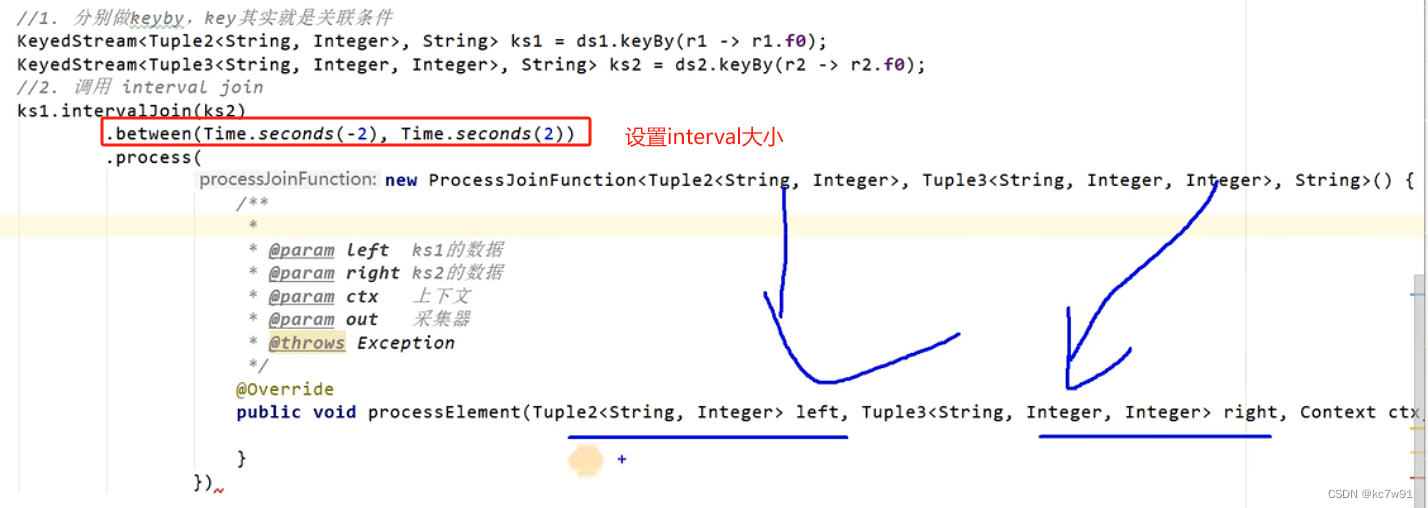
迟到数据处理逻辑:


5.7 关于水位线生成-1ms
乱序流中生成的水位线的时间戳,其实是当前数据中 最大时间戳 – 延迟时间 – 1ms

6 处理函数 process算子
是最底层算子,自由度最高
6.1 定时器
只有keyed之后的数据流才能定义定时器

-
注册定时器: 时间达到阈值后会触发指定事件。这个时间阈值可以是事件时间也可以是处理时间。同key定时器会去重。

-
定义具体事件

6.2 窗口处理函数
以topn问题为例:

-
方法一: 定义10s的事件滑动窗口(可重叠),滑动步长为5s+windowall全窗口函数(不能key分区)

自己实现处理所有窗口的接口

-
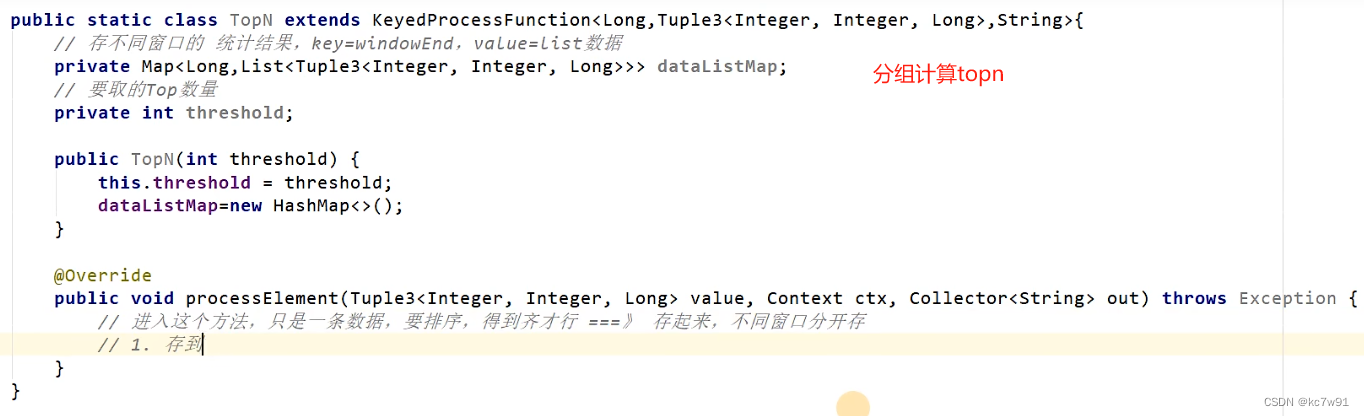
方法二:使用keyedProcessFunction实现
增量计算+全量打标签
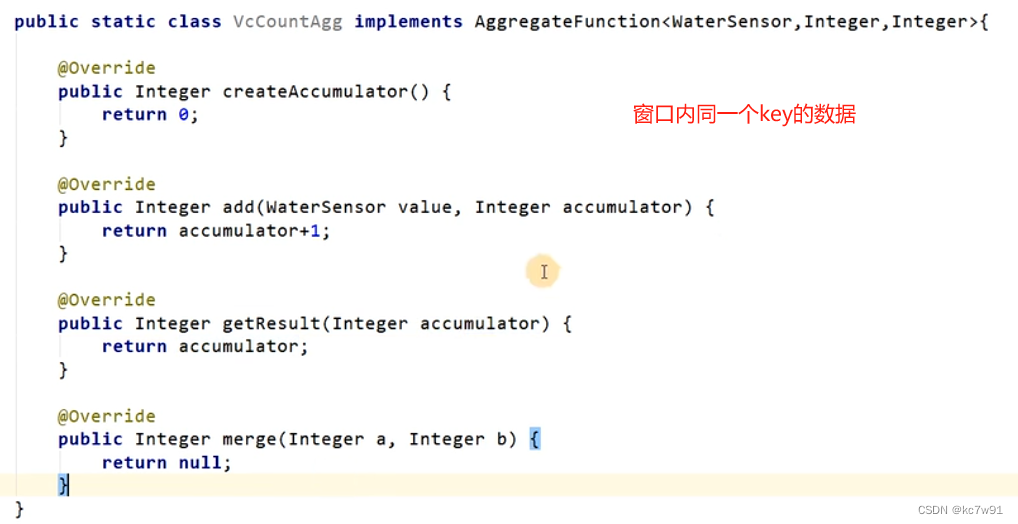
增量:来一个数据计算一次,三种类型可不同(输入类型,中间类型,输出类型)
AggregateFunction 是用于执行聚合操作的接口。它允许您定义如何将一个输入值序列聚合为一个输出值。
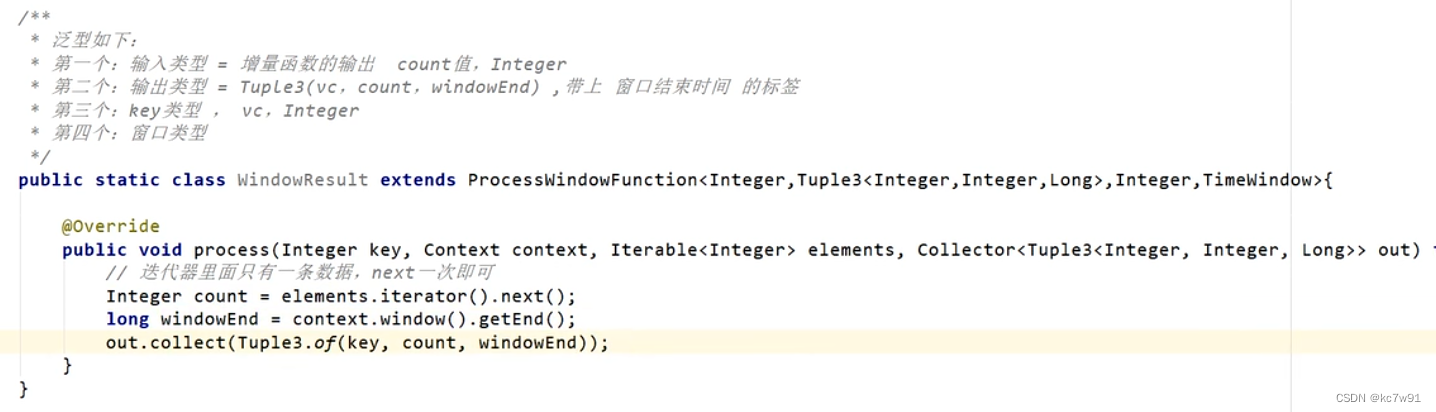
全窗口函数:处理窗口内的统计性结果
ProcessWindowFunction 会接收窗口中的所有元素,并允许您在窗口关闭时执行自定义的处理逻辑。
调用以上两个方法:

定义window内部处理函数:

process里放下面这个topn方法
KeyedProcessFunction 是窗口无关的,它是用于处理基于键控流的自定义处理函数
方法二总结:


