- 1JAVA编写AOP切面打印日志和自定义AOP注解_切面打印日志log空指针异常
- 2C语言/数据结构——每日一题(用栈实现队列)
- 3相机成像原理中世界坐标系,相机坐标系,像素坐标系,图像坐标系的转换(数学推导)_为什么要进行世界坐标系转相机坐标系
- 4Prompt范式产业实践分享!基于飞桨UIE-X和Intel OpenVINO实现跨模态文档信息抽取
- 5如何正确打开必应上的copilot?#超级详细,评论区有问必答_必应的copilot在哪?
- 6The Clean Architecture(干净的架构)_干净的抽象结构
- 7matlab怎么多重积分,多重积分的MATLAB实现
- 8SGP30传感器示例程序(基于51单片机、IO模拟I2C)_sgp30传感器中文数据手册
- 9国家开放大学如何找答案?四个大学生必备的搜题 #笔记#微信_国开大学的答案哪里找
- 10微信发卡小程序源码_关键词搜索领卡功能,带流量主
DGMIL:分布引导的WSI分类多实例学习_dgmil: distribution guided multiple instance learn
赞
踩
DGMIL: Distribution Guided Multiple Instance Learning for Whole Slide Image Classification
摘要
背景
多实例学习(MIL)被广泛用于组织病理学全玻片图像(WSI)的分析。然而,现有的MIL方法并没有明确地对数据分布进行建模,相反,它们只通过训练分类器来有区别地学习袋级或实例级的决策边界。
本文方法
一个用于WSI分类和正patch定位的特征分布引导的深度MIL框架
揭示了组织病理学图像数据的固有特征分布可以作为非常有效的指导,例如分类
提出了一种基于聚类条件的特征分布建模方法和一种基于伪标签的迭代特征空间细化策略,以便在最终的特征空间中可以容易地分离正实例和负实例
代码链接
本文方法
bag:是指同一张图像的patch集合(不重叠),标签为分类标签和是否为W(从W中提取的patch),每一个patch为实例
阴性bag中所有实例的标签都是阴性的,而阳性bag中至少有一个阳性实例,但哪些是阴性的是未知的
肿瘤组织和正常组织之间的细胞形态存在显著差异,因此,如果能够找到合适的潜伏空间,它们在特征空间中的分布也应该显著不同。在此基础上,我们的目标是对特征空间进行适当的建模,使负实例和正实例在特征空间中容易分离。由于我们的方法是基于实例的特征,因此我们在本文后面提到的实例都是指它们的特征向量。
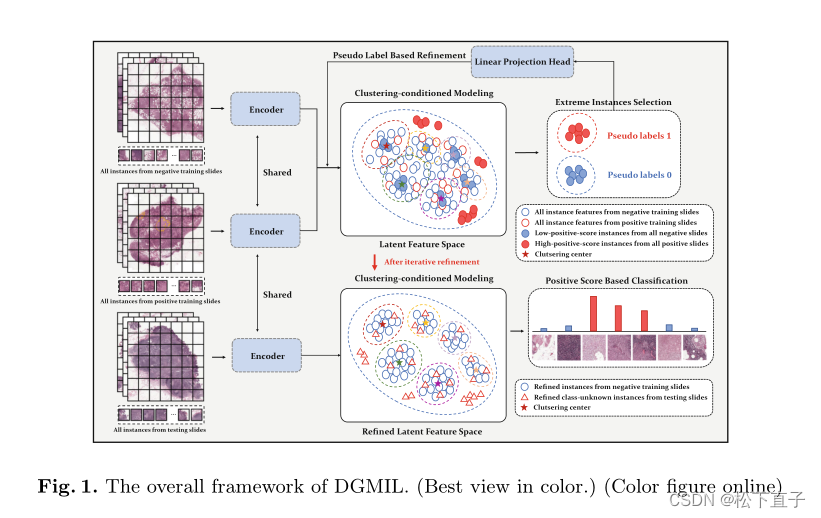
图1说明了我们提出的DGMIL的总体框架。具体来说,我们使用mask的自动编码器来执行自监督学习(MAE),以训练编码器将所有实例映射到初始潜在特征空间,该空间将被迭代细化。
在推理过程中,我们将WSI中的测试实例映射到细化的潜在特征空间,并计算其实例级分类的正分数。对于Bag级分类,我们只使用简单的平均池化方法来聚合bag中所有实例的正分数。由于训练和推理都是基于每个独立的实例(即不使用幻灯片中的位置信息),因此我们的方法具有排列不变性。
Cluster-Conditioned Feature Distribution Modeling
我们提出了一种基于K-均值聚类和马氏距离的特征分布建模方法。具体来说,我们首先使用K-means算法将训练集中负WSI的所有实例聚类为M个聚类,其中每个聚类表示为Cm。接下来,我们使用训练集中负滑动和正滑动的所有实例的Mahalanobis距离计算正得分si,j

Pseudo Label-Based Feature Space Refinement
基于MAE的初始特征空间的直接使用并不能很好地对正实例和负实例的分布建模,因为MAE的训练是完全自我监督的,并且没有利用袋级监督。
因此,我们进一步提出了一种基于伪标签的特征空间细化策略来对其进行细化。
这种特征空间细化策略是一个迭代过程。在每次迭代中,我们首先使用K-means算法对训练集中负面WSI中的所有实例进行聚类,并计算正面和负面WSI中所有实例的正分数。正WSI中具有最高正得分的实例的比例和负WSI中具有最低正得分的例子的比例被称为极端实例,并且它们分别被分配伪标签1和0。利用这些极端实例及其伪标签,我们以监督的方式训练了一个简单的二元分类器,该分类器由一个FC层线性投影头和一个FC级分类头组成。最后,我们利用线性投影头将当前实例特征重新映射到新的特征空间中,以实现特征空间的细化。上述特征空间细化过程进行迭代,直到收敛。
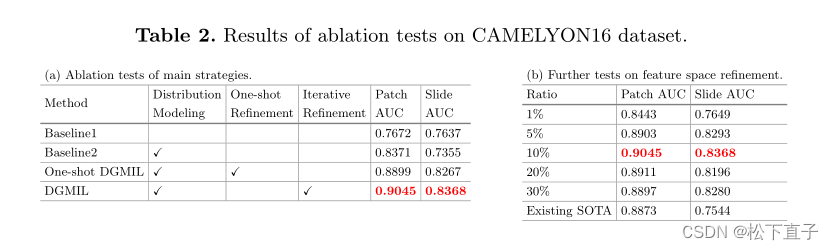
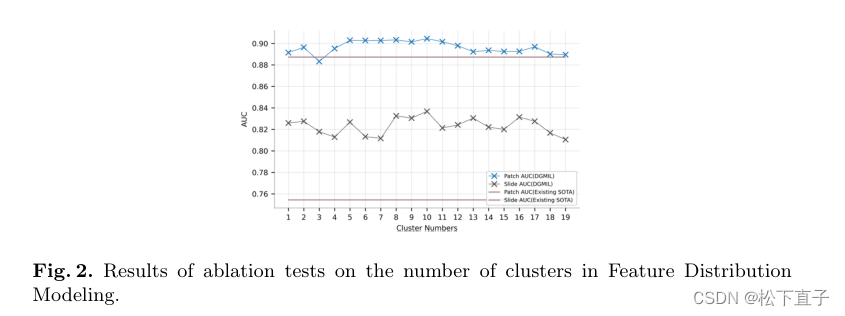
实验结果