
- 1C语言实现植物大战僵尸(完整版)_植物大战僵尸源码
- 2一个基于预训练的DenseNet121模型的人脸年龄分类系统
- 3IntelliJ IDEA使用git命令_idea中如何使用git命令
- 4警告 [http-nio-8080-exec-4] org.springframework.web.servlet.DispatcherServlet
- 5IOT(阿里云)-智慧花卉 - 1,利用阿里云对上传和下发数据进行云流转_自动浇花系统感知层
- 6Python 深度学习 第2版 中文目录_python深度学习第2版 pdf
- 7git 某个分支代码回滚到某次push的步骤_git回滚到某个提交 push
- 8苹果iOS18将引入ChatGPT;美国AI禁令再升级;微软首发Phi-3多模态模型 | AI头条_ios18 chatgpt
- 9Linux环境安装MATLAB_linux安装matlab
- 10Rviz:三维可视化显示平台_rvizs可视化
q learning简单理解_如何用简单例子讲解 Q learning 的具体过程?
赞
踩
想了解更多好玩的人工智能应用,请关注公众号“机器AI学习 数据AI挖掘”,”智能应用"菜单中包括:颜值检测、植物花卉识别、文字识别、人脸美妆等有趣的智能应用。。

一、Bandit算法回顾,MDP简单介绍
首先,我们指出在bandit算法中主要有两类流行的算法,一类是贪心算法(如uniform exploration, 
覃含章:在线学习(MAB)与强化学习(RL)[2]:IID Bandit的一些算法zhuanlan.zhihu.com
话又说回来,在经典bandit算法当中,我们要做的无非就是通过一类pull arm的策略,尽快找到比较好的“arm”(reward较高的arm),然后尽可能多的去拉这些比较好的arm就是了。贪心算法无非就是永远以当前对每个arm的reward的估计直接作为依据,而UCB算法则是考虑了置信度的问题,因此考虑的是每个arm reward的置信区间的上界。
那么这个思想推广到更一般的马尔科夫决策过程问题中,可不可以呢?答案自然也是可以的。具体来说,我们考虑一般的episodic Markov decision process, 












注意,我们这边考虑的是一个episodic MDP,也就是说这个MDP允许被重复很多个episodes。这也很好理解,比如我们如果要训练AlphaGo,那么每个episode就可以看作一局棋,我们势必要重复下很多盘棋才可能对一个比较好的下棋“策略”(policy)有所了解,而如果只下一盘或者很少盘数的棋,我们可能都没有办法对于怎么下棋这件事情,和不同的下棋策略赢的几率,有一个好的exploration。
那么我们就发现有两个核心的概念:
策略:policy的概念。在MDP中,我们定义一个policy
是
。也就是说,在每一步
,在不同的state下我们应该选择哪个action。
价值函数:value function的概念。这里我们需要定义著名的
function和
function。我们称
这个函数是在step
。至于
这个函数是在step
本节最后说明,在我们的epsiode MDP setting,每个episode一开始,我们可以不失一般性地认为 
二、基于UCB算法的Q-learning
我们注意到,因为只是考虑有限的状态空间和行动空间,所以最优policy是一定存在的(这是DP的经典结果)。那么用 



注意这里我们用了简化的notation:


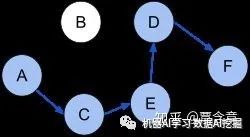
说明这一点更简单的例子见上图,即所谓的最短路(shortest path)问题。这个问题显然也可以看成是episodic MDP,在每个episode我们都想找到这个固定的图上的最短路,假设每两个节点之间我们事先不知道要花多少时间,而它符合某些随机变量的分布。那么,这个问题的最优policy显然就是满足tail optimality的,这是因为,如果我找到了一套走最短路的方法,那么很显然,即使我走到了途中某个节点,比如B,那么我从B走到F的最短路一定可以通过B->C + C->F的最短路(最优policy给出) 或者 B->D + D->F的最短路(最优policy给出)来比较得到。
那么说到这里,Q-learning的想法也就呼之欲出了。因为我们知道,如果我们能知道 


所以核心问题就是如何去估计这个 


他们的算法有两个形式,但其实大同小异,区别在于通过不同的集中不等式所需要的不同形式的upper confidence bound。简单来说,Bernstein不等式相比Hoeffding不等式还有对二阶矩的精细控制(即Algorithm 2中的 
不过我们这里因为只是谈一下大概的思想,所以后面只会具体提及Algorithm 1相关的分析思路。毕竟大的思想其实是一样的。这边我们看Algorithm 1,思路就如前面所说,是很直接的,算法中第7行就是如何对Q函数进行估计,一共有两项组成,第一项可以看成是优化算法中的momentum项,第二项就是核心的UCB bound迭代。这里我们注意到置信区间的长度,忽略log项,大概是 





三、一些分析
好了,本节我们就稍微具体看下Algorithm 1为什么可以work。尤其比如说步长为什么要选成 
这边先重申下regret的定义(其实是expected regret,或者按照上次的说法是pseudo regret),很简单,就是

其中 



这边需要用一个额外的notation来说。我们让 



这个式子其实更能反应算法的本质:这也是Q-learning利用多个episode学习的关系式。对于分析来说,我们就希望能说明利用合适的步长 

对于步长,我们再定义这样一些量:

那么我们可以进一步把上面的式子展开,得到

这边我们令 



那么这边就有张图,画出了取不同 


具体来说,我们容易验证当 


那么之后的analysis都基于前面的式子,简单来说我们需要能够用 

忽略log项,Algorithm 1可以得到 


之后再提一下他们得到的其它一些结果。主要还有两个:
1.他们构造了一个MDP的例子并说明 
2.他们也给了一个一般情形的lower bound,对任意算法,存在一个 

最后多说一句,其实bandit文献里面经常需要自己去”造“一些特殊的不等式然后算法配合之达到比较好的regret bound,这往往都是因为只控制一阶矩不够精细,需要引入二阶矩的一些精确估计才ok。当然可能有些人会觉得这些纯属是在玩bound,不过在bandit领域里应该都算是共识了。。。

