
热门标签
热门文章
- 12021 年 Angular vs. React vs. Vue 前端框架对比_vue bom对比
- 2控制台打印心形_cmd打印爱心
- 32024年网络安全最全AWVS工具太顶了,漏洞扫描工具AWVS介绍及安装教程_qawvsq(1),2024年最新2024网络安全春招_awvs更新漏洞库
- 4swagger2 knife4j 集成配置_swagger2 配置 kneif4j
- 5Python字典(Dictionary)详细使用教程_python 用dictionary
- 6考研学习平台设计与实现(JSP+java+springmvc+mysql+MyBatis)_考研经验分享平台的设计与实现
- 7中小学居然也要开这门课程?普通人学Python有何用?_中小学为什么要学python
- 8【Transformer】一文搞懂Transformer | CV领域中Transformer应用_transformer在cv上的应用
- 9Kafka基础—3、Kafka 消费者API_kafka sarama创建消费组
- 10极光笔记丨Spark SQL 在极光的建设实践
当前位置: article > 正文
逻辑回归算法(二)-----SparkMLlib实现_spark mllib逻辑回归模型训练步骤
作者:2023面试高手 | 2024-06-01 21:29:26
赞
踩
spark mllib逻辑回归模型训练步骤
1.1 逻辑回归算法
1.1.1 基础理论
logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将最为假设函数来预测。g(z)可以将连续值映射到0和1上。
它与线性回归的不同点在于:为了将线性回归输出的很大范围的数,例如从负无穷到正无穷,压缩到0和1之间,这样的输出值表达为“可能性”才能说服广大民众。当然了,把大值压缩到这个范围还有个很好的好处,就是可以消除特别冒尖的变量的影响。
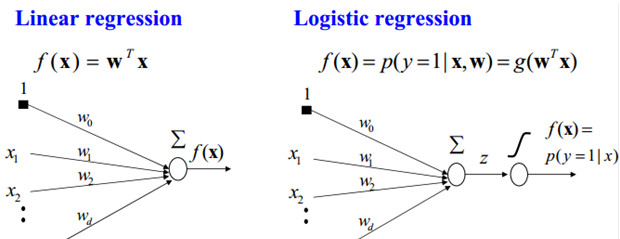 |
| Logistic函数(或称为Sigmoid函数),函数形式为: |
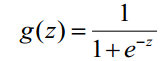 |
| Sigmoid 函数在有个很漂亮的“S”形,如下图所示: |
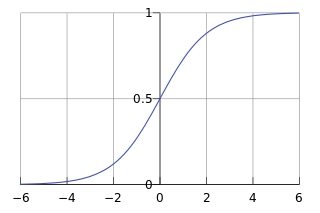 |
| 给定n个特征x=(x1,x2,…,xn),设条件概率P(y=1|x)为观测样本y相对于事件因素x发生的概率,用sigmoid函数表示为: |
 |
| 那么在x条件下y不发生的概率为: |
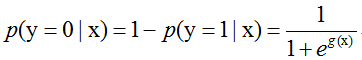 |
| 假设现在有m个相互独立的观测事件y=(y1,y2,…,ym),则一个事件yi发生的概率为(yi= 1) |
 |
| 当y=1的时候,后面那一项是不是没有了,那就只剩下x属于1类的概率,当y=0的时候,第一项是不是没有了,那就只剩下后面那个x属于0的概率(1减去x属于1的概率)。所以不管y是0还是1,上面得到的数,都是(x, y)出现的概率。那我们的整个样本集,也就是n个独立的样本出现的似然函数为(因为每个样本都是独立的,所以n个样本出现的概率就是他们各自出现的概率相乘): |
 |
| 然后我们的目标是求出使这一似然函数的值最大的参数估计,最大似然估计就是求出参数,使得 |
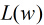 |
| 取得最大值,对函数取对数得到 |
|
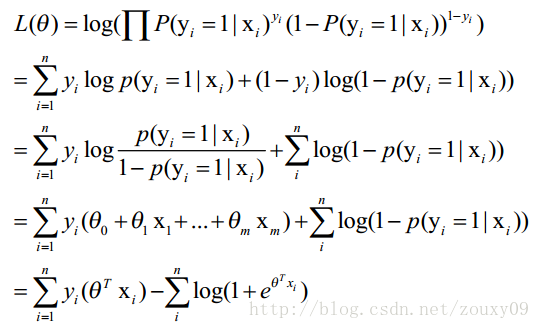 |
| 这时候,用L(θ)对θ求导,得到: |
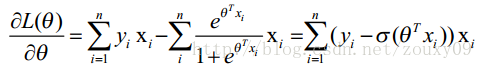 |
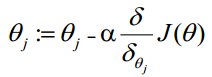 |
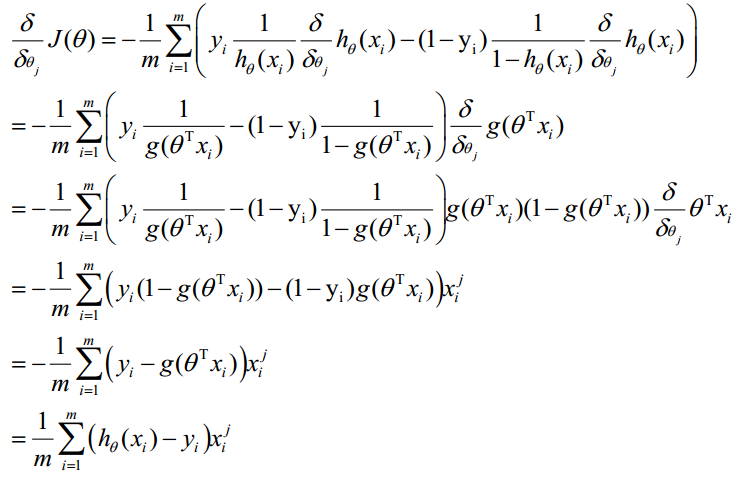 |
| θ更新过程可以写成: |
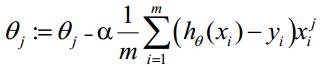 |
| 向量化Vectorization Vectorization是使用矩阵计算来代替for循环,以简化计算过程,提高效率。 如上式,Σ(...)是一个求和的过程,显然需要一个for语句循环m次,所以根本没有完全的实现vectorization。 下面介绍向量化的过程: 约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值: |
 |
| g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。由上式可知 |
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/659459
推荐阅读
相关标签

