
- 1一步一步教你如何在GitHub上上传自己的项目_c# github在线上传文件
- 2C++_STL---list
- 3kafka发送消息至指定分区_kafka 发送消息到指定分区
- 4这些免费、可商用的图片素材网站,绝对不能错过_stocksnap官网免费素材
- 5秋招力扣刷题——从前序与中序遍历序列构造二叉树
- 6Vue2.5学习笔记(二)深入了解组件_vue2.5获取组件实例
- 7一文带你全面体验八种状态管理库
- 8Pytorch使用VGG16模型进行预测猫狗二分类_pytorch vgg16
- 9自然语言处理在营销中的应用场景_nlp 营销应用
- 10什么是分布式锁?为什么要用分布式锁_分布式锁理论以及在各种场景下的实践路线
浅尝KNN(K-Nearest Neighbors,K近邻算法)_最近邻算法是k近邻算法的特例,这种算法容易产生过拟和还是欠拟和为什么
赞
踩
前言
当下,机器学习已经成为了一个非常热门的领域,其中分类算法是机器学习中最常见的问题之一。KNN(K-Nearest Neighbors,K近邻算法)是一种基本的分类和回归算法,它的核心思想是基于样本之间的距离度量来进行分类或回归,是一种常用的监督学习方法。
一、KNN的原理(近朱者赤,近墨者黑)
正如本章标题所说,近朱者赤,近墨者黑,通俗易懂。
具体文字说明:对于一个新的给定的测试样本,KNN 算法首先计算该样本与训练数据集中所有样本的距离(或者其它某种度量),然后选择与该样本距离最近的 K 个样本(即 K 个最近邻),并根据这 K 个样本的类别标签来预测该样本的类别,即这K个样本中出现最多的类别标记作为预测结果。其中,K是由n_neighbors参数来调节。
在回归任务中可使用“平均法”,即将这个k个样本的实值输出标记的平均值作为预测结果。还可以基于距离远近进行加权平均,距离越近的样本权重越大。
下面用图示再说明knn的算法原理:
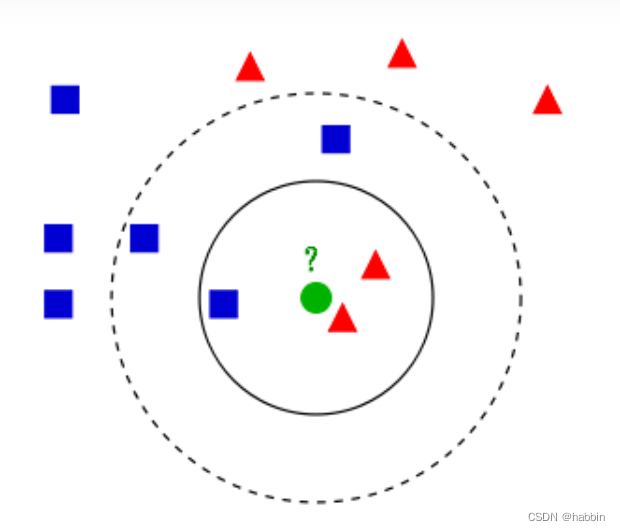
如上图所示,有两类不同的样本数据,蓝色正方形和红色三角形两个分类,现要用knn判定绿色的圆(即待分类的数据)属于什么分类。
当取k=3时(第一个圆的范围),绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,近红色的三角形,判定绿色的这个待分类点属于红色的三角形一类。
当取k=5时(第二个圆的范围),绿色圆点的最邻近的5个点是2个红色小三角形和3个蓝色小正方形,少数从属于多数,近蓝色的正方形,判定绿色的这个待分类点属于蓝色的正方形一类。
KNN 算法的原理非常简单,它不需要进行模型训练,因此非常适合小规模数据集的分类。
二、K值的选取
上述原理我们已经懂了。看似简单,然而k值的选取却并不简单。KNN 算法对于样本之间的距离度量和 K 值的选择非常敏感。
举个例子,倘若我们选取K=1,此时就出现了“一叶障目,不见泰山”的现象,这个邻居可能是一个孤立的点,它的分类可能是错误的。这种情况下,算法容易受到噪声的影响,导致分类错误率较高。
另一方面,如果我们选取的K值过大,比如K=100,那么算法会选择很多邻居,这些邻居可能包含了来自不同类别的数据点,导致分类结果不够准确。在这种情况下,算法容易受到过拟合的影响,导致分类错误率也较高。
总结一下,K值的大小决定了模型的复杂度。k太小,模型会过于关注局部的细节,可能会导致模型过于复杂,容易受到噪声的干扰,从而出现过拟合容易过拟合拟合;k太大,算法会选择更多的邻居来进行分类,这可能会导致模型过于简单,出现欠拟合的情况。具体来说,当K值很大的时候,模型会过于关注全局的特征,而忽略了样本之间的局部差异,从而导致模型泛化能力较差,无法很好地适应训练集以外的数据。
因此,K值的选取需要根据具体的数据集和问题来确定,需要在准确性和鲁棒性之间进行权衡。
实践中,我们通常需要通过交叉验证等方法来选择合适的K值,以获得更好的模型性能。
三、样本距离度量的选择
在K近邻算法中,样本距离度量的选择对分类结果有很大的影响。不同的距离度量方法会导致不同的距离计算方式,进而影响到K近邻算法的预测精度和鲁棒性。
以下是几种常见的距离度量方法及其影响:
-
欧氏距离:欧氏距离是最常用的距离度量方法,它是基于欧几里得空间中两点之间的距离计算的。欧氏距离对于数据空间的分布较为均匀的情况下表现较好,但对于不均匀分布的数据则可能导致分类错误。公式如下:
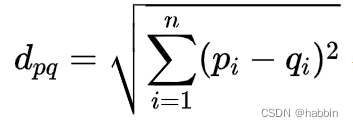
-
曼哈顿距离:曼哈顿距离是基于曼哈顿街区中两点之间的距离计算的。它可以在某些情况下比欧氏距离更为准确,尤其是在高维空间中。但在某些数据集上,曼哈顿距离可能表现不佳。
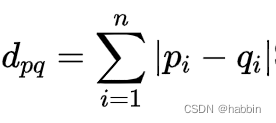
-
切比雪夫距离:切比雪夫距离是基于两点坐标轴上距离的最大值计算的。它对于处理高维数据和稀疏数据具有很好的性能,但在处理密集数据时可能不如欧氏距离表现好。
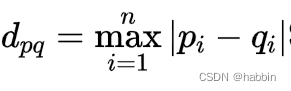
-
余弦相似度:余弦相似度是一种基于向量之间的夹角计算的距离度量方法。它对于处理文本分类和图像分类等任务具有很好的性能,但不适用于处理具有方向性的数据。
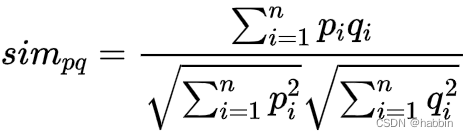
因此,选择合适的距离度量方法对于K近邻算法的性能至关重要。在实践中,我们通常需要根据具体的数据集和问题来选择合适的距离度量方法。
四、KNN的具体实现步骤
KNN 算法的实现步骤如下:
1.选择 K 值。K 值表示选择多少个最近邻,通常需要通过交叉验证等方法进行调参。
2.计算新样本与训练数据集中所有样本之间的距离。常见的距离度量方法包括欧氏距离、曼哈顿距离等。
3.选择与新样本距离最近的 K 个样本。这里需要对距离进行排序,选取距离最近的 K 个样本。
4.根据这 K 个样本的类别标签来预测新样本的类别或数值。在分类问题中,可以使用投票法来确定新样本的类别;在回归问题中,可以使用平均法来预测新样本的数值。
五、KNN算法的Python实现
假设我们有一个训练集包含x_train和y_train,其中x_train是特征向量的列表,y_train是相应的标签列表。我们想要预测一个测试样本x_test的标签。
import numpy as np class KNN: def __init__(self, k): self.k = k def fit(self, x_train, y_train): self.x_train = x_train self.y_train = y_train def predict(self, x_test): y_pred = [] for i in range(len(x_test)): distances = [] for j in range(len(self.x_train)): dist = np.linalg.norm(x_test[i] - self.x_train[j]) distances.append((dist, self.y_train[j])) distances.sort() neighbors = distances[:self.k] classes = {} for neighbor in neighbors: label = neighbor[1] if label in classes: classes[label] += 1 else: classes[label] = 1 y_pred.append(max(classes, key=classes.get)) return y_pred

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
在这个实现中,我们首先定义了一个KNN类,它有一个k参数,表示我们要考虑的最近邻居的数量。在fit方法中,我们简单地将训练集保存下来。在predict方法中,我们首先遍历所有测试样本,对于每个测试样本,我们计算它与所有训练样本的距离,并将距离及其对应的标签保存在distances列表中。然后我们对distances列表按距离进行排序,并选取前k个最近的邻居。接下来,我们统计这些邻居属于哪些类别,选取出现次数最多的类别作为预测标签,并将其保存在y_pred列表中。最后,我们返回y_pred列表作为预测结果。
这是一个简单的KNN实现,它可以用于分类问题。如果我们想要用KNN进行回归问题,需要对predict方法进行修改,例如使用平均值来预测输出。
下面是一个使用KNN算法进行手写数字分类的Python代码示例:
from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # 加载手写数字数据集 digits = load_digits() # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size=0.2, random_state=42) # 创建KNN分类器并拟合训练集 knn = KNeighborsClassifier(n_neighbors=5) knn.fit(X_train, y_train) # 在测试集上进行预测 y_pred = knn.predict(X_test) # 计算准确率 accuracy = knn.score(X_test, y_test) print("Accuracy:", accuracy)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
在这个代码中,我们首先使用sklearn.datasets中的load_digits函数加载手写数字数据集。然后,我们使用sklearn.model_selection库中的train_test_split函数将数据集划分为训练集和测试集。接下来,我们创建了一个KNeighborsClassifier对象,设置k值为5,并使用fit方法拟合训练集。然后,我们使用predict方法在测试集上进行预测,并使用score方法计算准确率。最后,我们输出准确率。
注意:这个例子中的KNN算法使用了sklearn中的实现,这个实现比上面的手动实现更加高效和准确,因为它使用了KD树或球树等数据结构来加速最近邻查找。
六、KNN的优缺点总结
KNN 算法的优点在于它简单、直观,易于理解和实现,是一个非常经典而且原理十分容易理解的算法。另外,KNN 算法不需要进行模型训练,因此对于小规模数据集来说,它的计算速度非常快。但是,KNN 算法也有一些缺点,例如需要存储全部的训练数据,对于大规模数据集来说存储开销较大;另外,KNN 算法对于样本之间的距离度量和 K 值的选择非常敏感,需要进行仔细的调参。KNN在实际使用当中会有很多问题,例如对数据集进行认真地预处理、对规模超大的数据集拟合的时间较长、对高维数据集拟合欠佳,以及对于稀疏数据集束手无策等。

