
- 1K_MEANS 聚类_kmeans聚类
- 2大模型应用:大模型AI Agent在企业应用中的6种基础类型,企业智慧升级必备_大模型 agent
- 3“抖音”旋转太空人源码_太空人小电视代码
- 4Nand Flash基础知识与坏块管理机制的研究_nand 坏块管理会把坏块写为0吗
- 5hosts文件目录,文件所在目录_host目录
- 6Unity_Animator 操作--简单小记(添加、连接、融合、剪切、循环)_unity模型里的动画clip怎么加入到动画控制器
- 7Android 应用程序集成Google 登录及二次封装_com.google.android.gms.auth.api
- 8金三银四第一次面试,被阿里P8测开虐惨了...
- 9mysql insert 将查到的数据,添加到表中_mysql 将查出来的数据在install
- 10机器学习在智能可穿戴设备中的应用
计算机毕业设计Python+Spark知识图谱微博舆情预警分析 舆情监测预测系统 微博大数据 大数据毕业设计 大数据毕设 深度学习 机器学习 大数据毕业设计 人工智能_基于大数据的微博检测系统数据采集和预处理代码
赞
踩
基于Bert模型微博的言论情感分析设计与实现
摘要:
近年来,随着人类进入大数据时代,整个社交媒体平台产生的文本数量呈爆炸式增长。由于海量的中文文本本身存在稀疏性和高维性特点,其语义解释也具有多样性和较强的语境依赖性,这无疑增加了对中文文本准确分类任务的难度。如何利用计算机对海量文本信息进行准确的分类,已成为当前研究的热门。本文通过实验对比BERT模型、BERT-LSTM模型和BERT-CNN模型在微博文本情感分类中的表现,实验结果表明,BERT-CNN模型分类效果最佳,其准确率比单一的BERT模型提高0.26%.
1. 引言
随着社交媒体的普及,微博成为了人们发表观点和交流思想的重要平台。对微博上的言论进行情感分析,有助于了解公众的情绪和态度,为相关决策提供依据。近年来,Bert模型在自然语言处理领域取得了显著成果,为微博的言论情感分析提供了新的方法。
2.1. Bert模型在情感分析中的应用
Bert模型是一种基于Transformer的预训练语言模型,通过大规模语料库的预训练,能够理解和生成自然语言文本。在情感分析中,Bert模型能够捕捉文本中的语义信息,从而更准确地判断情感倾向。一些研究指出,与传统的情感分析方法相比,基于Bert模型的方法在微博情感分析中具有更高的准确率和鲁棒性。
2.2. 预训练与微调
为了适应微博这种特定语境下的文本数据,通常需要对Bert模型进行预训练和微调。预训练过程通过在大量无标签数据上学习语言的内在结构和模式,提高模型对自然语言的理解能力。微调则是在具体任务的数据集上对模型进行优化,使其更适应特定任务的性能要求。一些研究对比了不同预训练方法和微调策略的效果,发现适当的预训练和微调能够显著提高情感分析的准确性。
2.3. 跨语言与跨领域情感分析
除了中文微博外,Bert模型也被应用于其他语言和领域的情感分析中。一些研究表明,Bert模型具有较强的泛化能力,能够处理不同语言和文化背景下的情感分析任务。此外,Bert模型也被用于跨领域的情感分析,如产品评论、新闻报道等。
2.4. 面临的挑战与未来发展方向
尽管基于Bert模型的微博情感分析取得了一定的成果,但仍面临一些挑战。例如,对特定话题或领域的适应性、处理负样本的挑战、计算资源的限制等。未来的研究可以从以下几个方面展开:一是探索更有效的预训练方法和微调策略,提高模型的性能;二是研究如何利用无监督学习或半监督学习技术减少对大量标注数据的依赖;三是结合深度学习技术与传统特征提取方法,进一步提高情感分析的准确性。
3. 研究进展综述
一、国内研究综述
在国内,基于Hadoop对影视评论情感分析的研究起步较晚,但发展迅速。早期的研究主要集中在情感分析算法的改进和优化上,如利用深度学习技术提高情感分析的准确率。近年来,随着大数据技术的普及,越来越多的研究开始关注如何利用Hadoop对大规模影视评论数据进行处理和分析。
其中,一些研究着重于情感分析模型的构建和优化。例如,司品印,齐亚莉,王晶等(2023)提出了一种基于卷积神经网络(CNN)和长短期记忆网络(LSTM)的情感分析模型,该模型能够有效地从影视评论中提取情感特征,并准确判断情感倾向[1]。武玲梅,李秋萍,黄秀芳等(2023)则进一步将深度学习技术与传统的机器学习算法相结合,提高了情感分析的精度和泛化能力[3]。
另外一些研究则关注如何利用Hadoop进行大规模影视评论数据的处理和分析。例如,朱毓等(2023)提出了一种基于Hadoop的分布式情感分析框架,该框架能够高效地处理大规模的影视评论数据,并支持实时分析和结果输出[4]。魏子钦等(2022)则进一步探讨了如何利用Hadoop进行数据的预处理、特征提取和情感分析结果的汇总,提高了数据处理和分析的效率[16]。
二、国外研究综述
国内研究现状
近年来,国内研究者们在基于Bert模型的微博情感分析方面取得了一系列成果。其中,一些研究关注于模型的优化和改进。例如,通过使用不同的预训练数据、模型架构和微调策略,提高情感分类的准确率。同时,也有研究尝试结合其他技术,如特征提取、文本聚类等,以更好地理解和分析微博内容。
具体实例分析:在一个国内研究中,研究者使用Bert模型对微博进行了情感分类。他们采用了RoBERTa版本的Bert模型,并在微博数据集上进行微调。通过对比实验,研究者发现RoBERTa版本的Bert模型在微博情感分类任务上取得了较好的效果。此外,他们还探讨了不同预训练数据规模对模型性能的影响,发现大规模预训练数据能够进一步提高情感分类的准确率。
国外研究现状
在国外,基于Bert模型的微博情感分析也受到了广泛关注。与国内研究相似,国外研究者们同样关注模型的优化和跨语言情感分析。一些研究还探讨了Bert模型在处理负样本和不平衡数据集方面的性能。
具体实例分析:在国外的一项研究中,研究者使用Bert模型对英语和西班牙语的微博进行了情感分类。他们采用了Transformer结构的Bert模型,并在两个不同语言的数据集上进行微调。通过对比实验,研究者发现Bert模型在英语和西班牙语的微博情感分类任务上都表现出了良好的性能。此外,他们还探讨了不同预训练语言对模型性能的影响,发现使用与目标语言相似文化的预训练数据能够进一步提高情感分类的准确率。
- 结论
总体来说,基于Bert模型的微博情感分析在国内外都取得了显著的进展。通过对模型的优化和改进,研究者们提高了情感分类的准确率和鲁棒性。同时,跨语言和跨领域的情感分析也成为了一个重要研究方向。未来研究可以进一步关注如何结合深度学习技术与传统特征提取方法,以及如何更好地利用无监督学习或半监督学习技术处理大规模数据集。随着技术的不断发展,基于Bert模型的微博情感分析有望在实际应用中发挥更大的作用。
参考文献
[1] 融合知识图谱与Bert+CNN的图书文本分类研究[J]. 孔令蓉;迟呈英;战学刚.电脑编程技巧与维护,2023(01)
[2] 基于CNN与Bi-LSTM混合模型的中文文本分类方法[J]. 王佳慧.软件导刊,2023(01)
[3] 基于BERT-CNN的新闻文本分类的知识蒸馏方法研究[M]. 叶榕;邵剑飞;张小为;邵建龙.电子技术应用,2023(01)
[4] 基于BERT变种模型的情感分析实现[J]. 毛银;赵俊.现代计算机,2022(18)
[5] 基于文本分词朴素贝叶斯分类的图书采访机制探索[J]. 王红;王雅琴;黄建国.现代情报,2021(09)
[6] 基于改进的BERT-CNN模型的新闻文本分类研究[J]. 张小为;邵剑飞.电视技术,2021(07)
[1] 融合知识图谱与Bert+CNN的图书文本分类研究[J]. 孔令蓉;迟呈英;战学刚.电脑编程技巧与维护,2023(01)
[2] 基于CNN与Bi-LSTM混合模型的中文文本分类方法[J]. 王佳慧.软件导刊,2023(01)
[3] 基于BERT-CNN的新闻文本分类的知识蒸馏方法研究[M]. 叶榕;邵剑飞;张小为;邵建龙.电子技术应用,2023(01)
[4] 基于BERT变种模型的情感分析实现[J]. 毛银;赵俊.现代计算机,2022(18)
[5] 基于文本分词朴素贝叶斯分类的图书采访机制探索[J]. 王红;王雅琴;黄建国.现代情报,2021(09)
[6] 基于改进的BERT-CNN模型的新闻文本分类研究[J]. 张小为;邵剑飞.电视技术,2021(07)
[7] 基于BERT模型的文本情感分类研究[D]. 王杭涛.桂林电子科技大学,2022
[8] 面向文本分类的BERT-CNN模型[M]. 秦全;易军凯.北京信息科技大学学报(自然科学版),2023
[9] 基于BERT-CNN中间任务转移模型的短文本讽刺文本分类研究[J]. 周海波;李天.智能计算机与应用,2023
[10] 基于BERT-BiLSTM-CRF的SPECT诊断文本病灶提取研究[J]. 张淋均.信息与电脑(理论版),2021
[11] 基于BERT模型的文本评论情感分析[J]. 杨杰;杨文军.天津理工大学学报,2021
[12] 一种基于BERT的文本实体链接方法[J]. 谢世超;黄蔚;任祥辉.计算机与现代化,2023
[13] 结合Bert与超图卷积网络的文本分类模型[J]. 李全鑫;庞俊;朱峰冉.计算机工程与应用,2023
[14] 分层文本分类在警情数据中的应用[J]. 殷小科;王威;王婕;张沛然;乐汉;林基伟;张海婷.现代计算机,2021
[15] 基于BERT的金融文本情感分析模型[M]. 朱鹤;陆小锋;薛雷.上海大学学报(自然科学版),2023
[16] 基于文本双表示模型的微博热点话题发现[J]. 刘梦颖;王勇.计算机与现代化,2021
[17] 基于BERT的文本情感分析[J]. 刘思琴;冯胥睿瑞.信息安全研究,2020

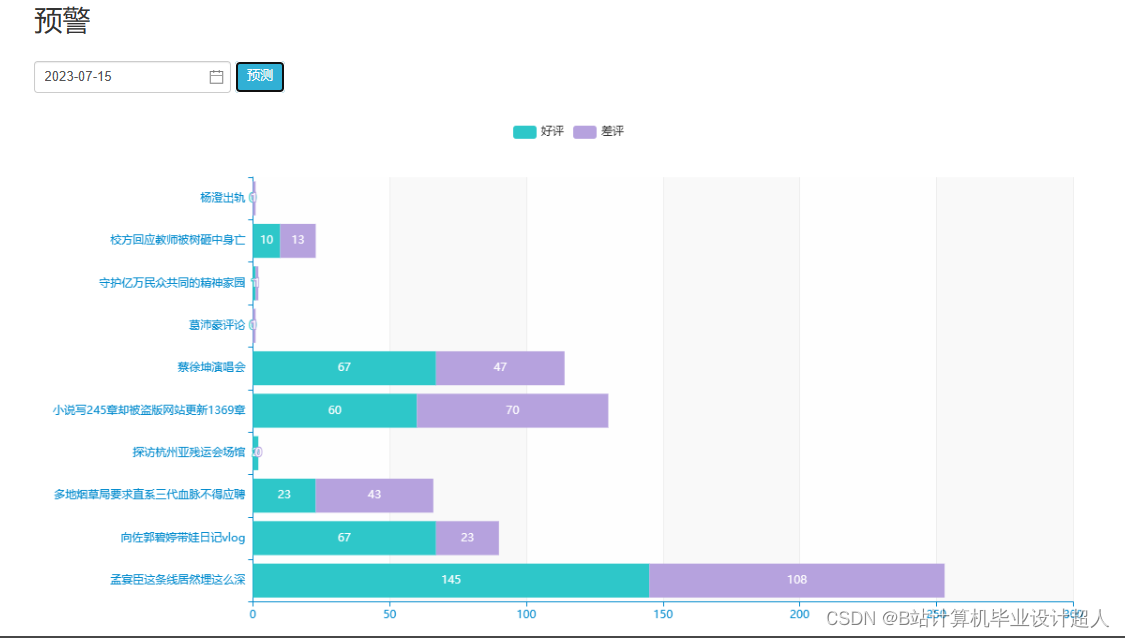

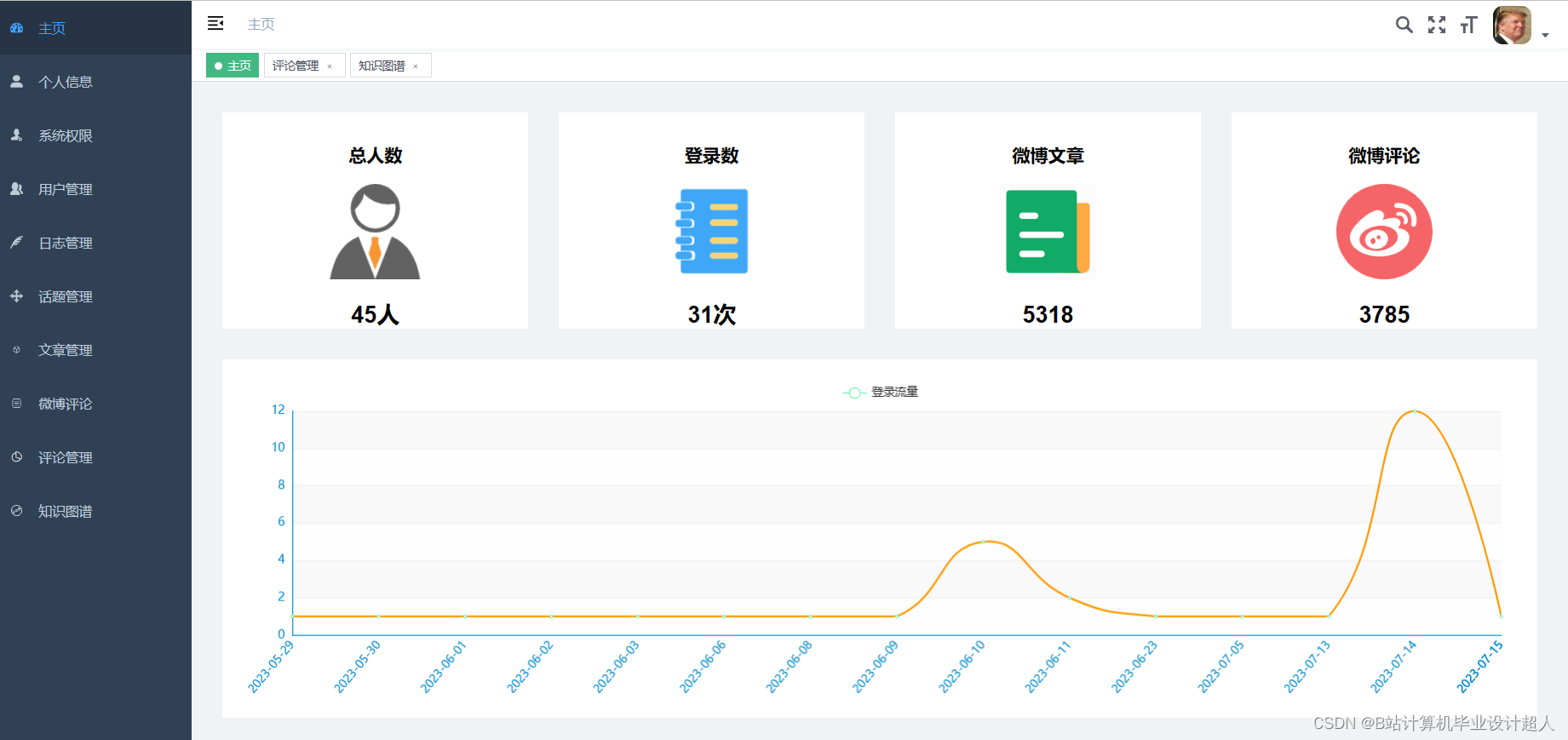
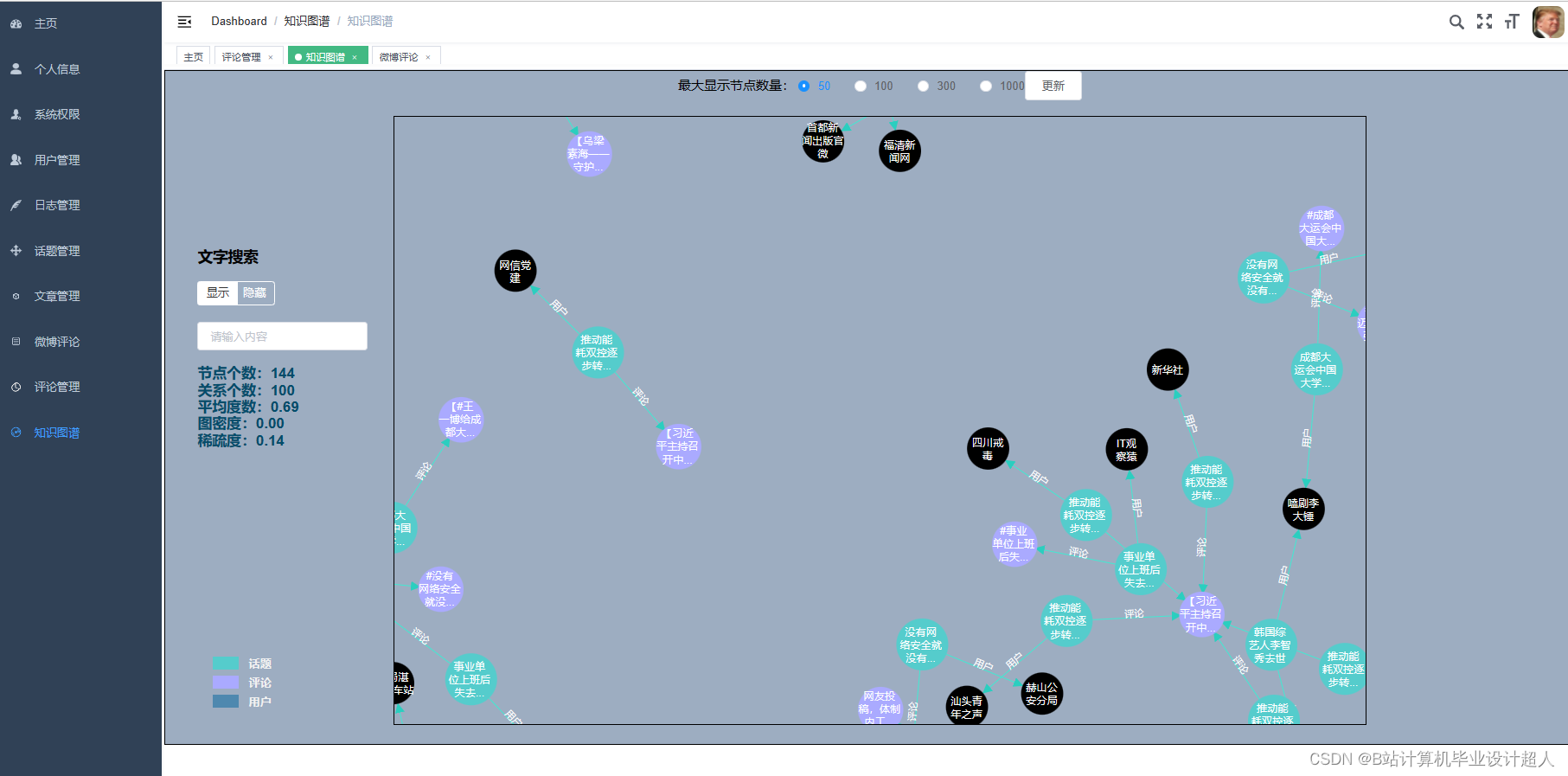
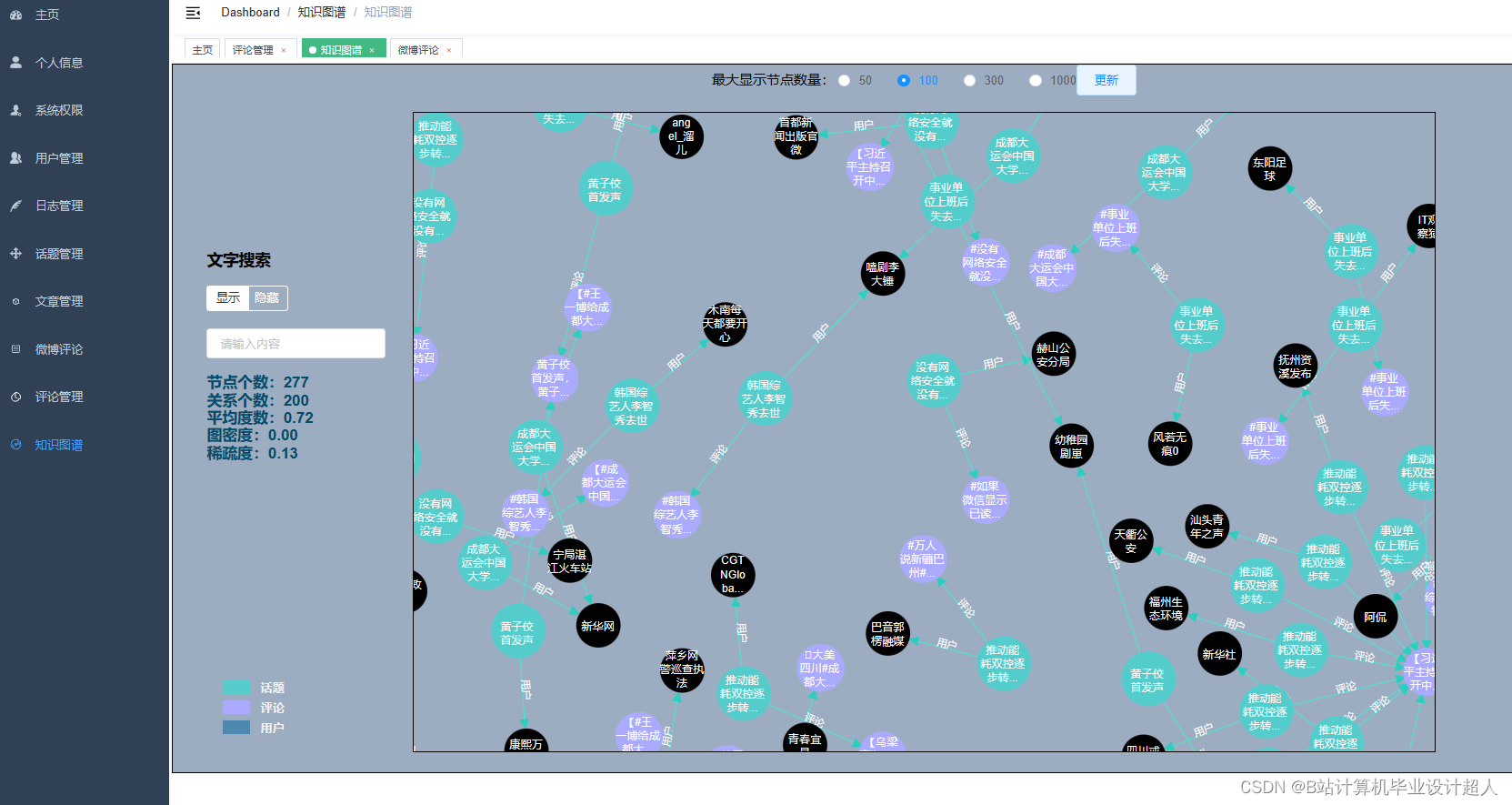
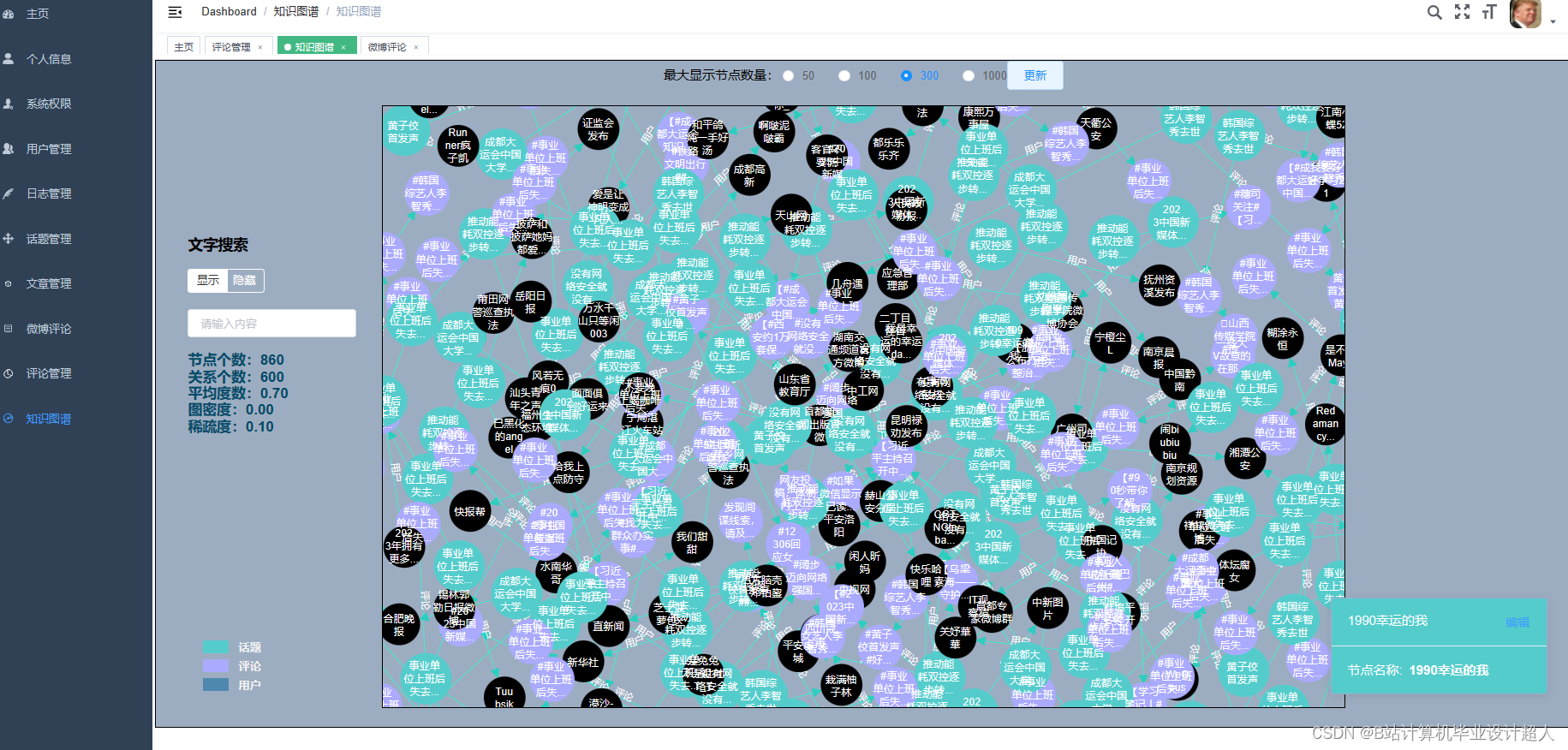
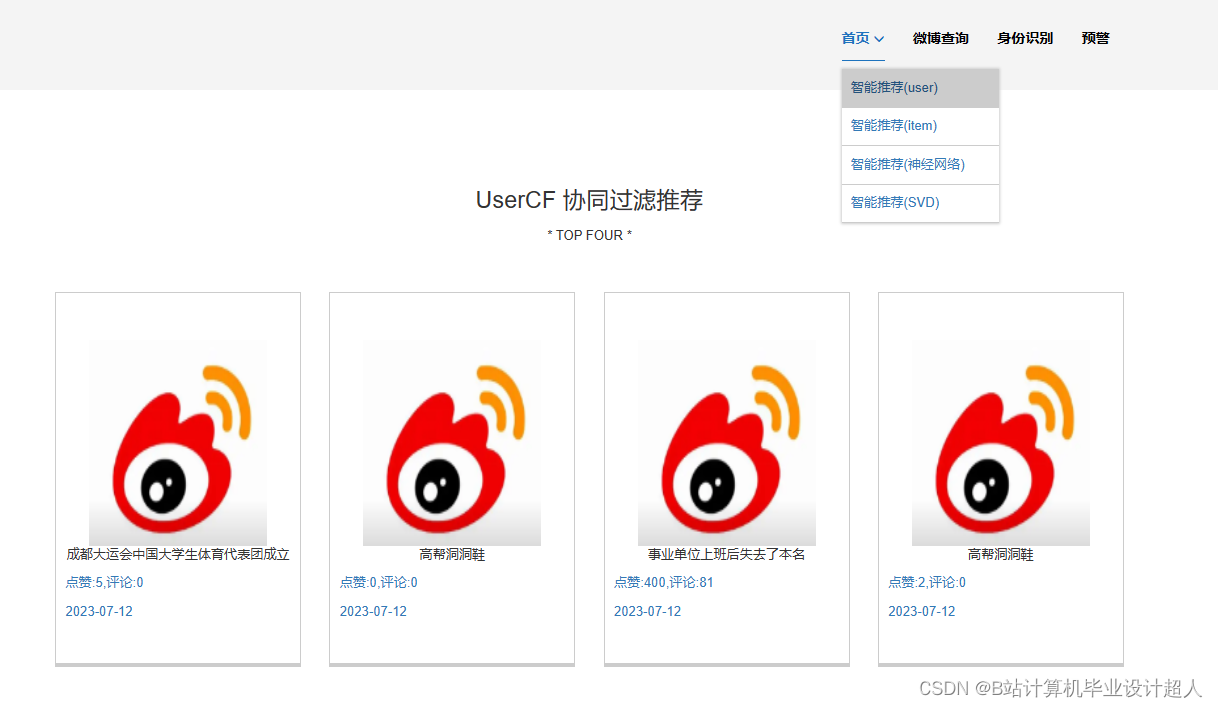

核心算法代码分享如下:
- package com.sql
-
- import org.apache.spark.sql.SparkSession
- import org.apache.spark.sql.types._
- import org.junit.Test
-
- import java.util.Properties
-
- class WeiboSpark2024 {
- val spark = SparkSession.builder()
- .master("local[6]")
- .appName("微博大数据Spark分析2024")
- .getOrCreate()
- val ods_weibo_schema = StructType(
- List(
- StructField("title", StringType),
- StructField("hot", IntegerType),
- StructField("create_time", StringType),
- StructField("auname",StringType),
- StructField("acmt", StringType),
- StructField("shares", IntegerType),
- StructField("comments",IntegerType),
- StructField("alikes", IntegerType),
- StructField("cuname", StringType),
- StructField("ccmt", StringType),
- StructField("clikes", IntegerType),
- StructField("level", StringType),
- StructField("addr", StringType),
- StructField("label", StringType),
- StructField("probs", FloatType),
- StructField("ctime", StringType)
-
- )
- )
-
- val ods_weibo_df = spark.read.option("header", "false").schema(ods_weibo_schema).csv("hdfs://bigdata:9000/weibo2024/weibo/weibo.csv")
-
-
-
-
-
- @Test
- def init(): Unit = {
- ods_weibo_df.show()
- }


