
- 1封装自己的代码为类库在Unity中调用_如何让自己写的类出现在unity编辑器里
- 2AIGC技术发展和应用方向_aigc5总结和未来展望
- 3vue3 中Element Plus的el-select 样式(包括更换小图标样式)_vue
- 4mysql libs 5.5_解决 mysql-libs-5.1 conflicts with file from package MySQL-server-5.5
- 5nginx部署vue项目(包括一个nginx部署多个vue项目)_nginx vue
- 6antdv a-form的校验方式(手把手 附送上传boundary二进制流方法)_a-form-item 如何进行深层对象校验
- 7C++课设字符动画转换器(opencv,easyx)学习路线_opencv easyx
- 8身份认证系统Oauth2介绍_/oauth2/authorize
- 9&" href="/w/IT小白/article/detail/93560" target="_blank">解决VBox中CentOS的增强功能安装问题 及 vbox centos安装增强功能总结_error: kernel configuration is invalid.";\ echo >&
- 10centos7挂载光盘_centos7怎么挂载光盘
【论文阅读】Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation_animate anyone:用于角色动画的一致且可控的图像视频合成技术
赞
踩
动画化Anyone:用于角色动画的一致且可控的图像到视频合成。
paper:https://arxiv.org/abs/2311.17117
code:还没开源
1摘要
角色动画,通过驱动信号从静止图像生成角色视频。 扩散模型在图像->视频领域仍然存在挑战,保持时序与角色细节信息的一致性是一个艰巨的问题。 在本文中,作者利用扩散模型的力量,提出了一种为角色动画量身定制的新颖框架。
- 为了保持复杂外观特征的一致性,根据参考图像,作者设计ReferenceNet通过空间注意力合并细节特征。
- 为了确保可控性和连续性,作者引入pose guider姿势引导器来指导角色的运动,并采用时间建模方法来确保视频帧之间平滑的帧间过渡。
- 通过扩展训练数据,作者的方法可以对任意角色进行动画处理,与其他图像到视频方法相比,在角色动画方面产生更好的结果。 【提升泛化性】
- 作者还根据时尚视频和人类舞蹈合成的基准评估了他们的方法,取得了最先进的结果。
2前言
角色动画,是将源角色图像按照所需的姿势序列建模为逼真视频。
DreamPose专注于时尚图像到视频的合成,扩展了稳定扩散并提出了一个适配器模块来集成图像中的CLIP和VAE特征。 然而,DreamPose 需要对输入样本进行微调以确保结果一致,从而导致运行效率不佳。 DisCo探索人类舞蹈的生成,类似地修改稳定扩散,通过CLIP集成角色特征,并通过ControlNet合并背景特征。 然而在保留人物细节方面存在缺陷,并且存在帧间抖动问题。
此外,目前对角色动画的研究主要集中在特定的任务和基准上,导致泛化能力有限。一些研究将文本到视频的方法扩展到图像到视频的方法。 然而无法从图像中捕获复杂的细节,可以提供更多多样性但缺乏精度,特别是当应用于角色动画时,导致角色外观的细粒度细节随时间变化。 此外,当处理大量的角色动作时,这些方法很难产生一致稳定和连续的过程。 目前,还没有观察到的同时实现通用性和一致性的角色动画方法。
(以上的方案跟这个文章的方案有一以贯之的思路:采用CLIP类似的框架,来特征融合,相对来说是目前较好的方案,因为CLIP展现出的高迁移性足以说明这种设计的稳定性)
作者提出了 Animate Anybody,能够将角色图像转换为由所需姿势序列控制的动画视频。继承了稳定扩散(SD)的网络设计和预训练权重,并修改了Denoising UNet以适应多帧输入。
- 为了解决保持外观一致性的挑战,作者引入了 ReferenceNet,专门设计为对称UNet结构,用于捕获参考图像的空间细节。
- 在UNet 块的每个相应层,作者使用空间注意力将 ReferenceNet 的特征集成到Denoising UNet 中。 这种架构使模型能够在一致的特征空间中全面学习与参考图像的关系,这对外观细节保留的改进做出了显着贡献。
- 为了确保姿态可控性,作者设计了一种轻量级姿态引导器,以有效地将姿态控制信号集成到去噪过程中。
- 为了实现时间稳定性,作者引入时间层来对多个帧之间的关系进行建模,从而保留视觉中的高分辨率细节质量,同时模拟连续且平滑的时间运动过程。
作者的模型是在5K字符视频剪辑的内部数据集上进行训练的。 图1显示了各种角色的动画结果。 与以前的方法相比,作者的方法具有几个显着的优点。
- 首先,有效地保持了视频中人物外观的空间和时间一致性。
- 其次,生成的高清视频不会出现时间抖动或闪烁等问题。
- 第三,能够将任何角色图像动画化为视频,不受特定领域的限制。 【因为加了pose guider和reference image】
作者在两个特定的人类视频合成基准(UBC时尚视频数据集和 TikTok 数据集)上评估,在实验中仅使用每个基准的相应训练数据集,取得了最先进的结果。 作者还将他们的方法与在大规模数据上训练的一般图像到视频方法进行比较,作者的方法在角色动画方面展示了卓越的能力。 作者设想Animate Anybody可以作为角色视频创作的基础解决方案,激发更多创新和创意应用程序的开发。
3方案
作者的目标是角色动画的姿势引导图像到视频合成。 给定描述 角色外观 和 姿势序列 的参考图像,模型会生成该角色的动画视频。 方法的流程如图2所示。
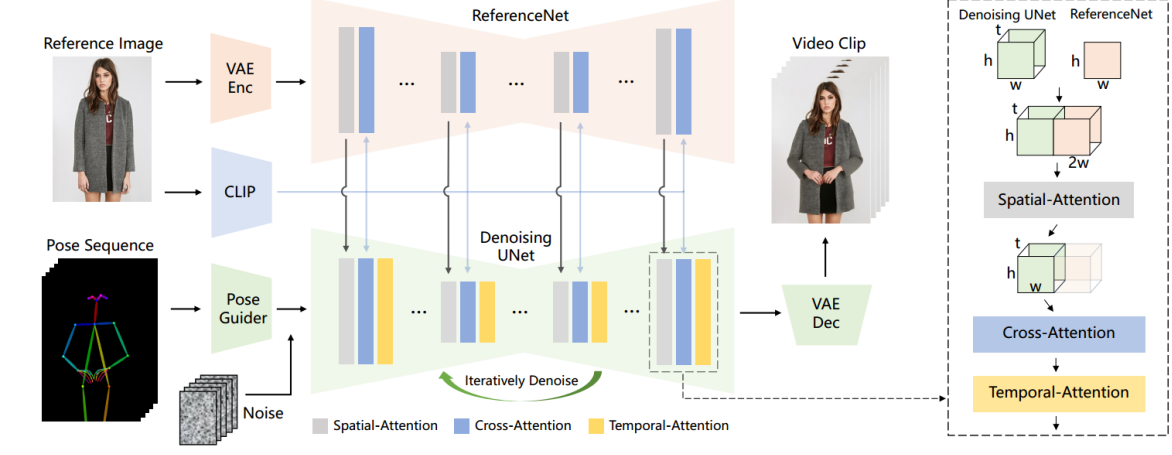
图 2.作者的方法的概述。 姿势序列用 Pose Guider 编码,并与多帧噪声融合,形成新的加了噪声的特征。然后由 Denoising UNet 去噪。最后,VAE解码器将结果解码为图像序列。Denoising UNet 的计算模块由 Spatial-Attention、Cross-Attention 和 Temporal-Attention 组成,如右侧虚线框所示。
参考图像的集成涉及两个方面。 首先,ReferenceNet提取详细特征,用于空间注意力。 其次, CLIP 图像编码器提取语义特征,进行交叉注意力。 然后将交叉注意力出来的结果做时间注意力计算。
Denoising UNet基于SD,采用相同的框架和块单元,并继承了SD的训练权重。 方法包含三个关键组成部分:
- ReferenceNet,对参考图中的角色的外观特征进行编码;【就是用Spatial-Attention将空间信息引入到Denoising UNet中】
- Pose Guider,编码运动控制信号,实现可控的角色动作;
- Temporal层,对时间关系进行编码,保证角色运动的连续性。
(典型的diffusion是通过CLIP来文字编码,得到引导性的特征,然后拿一个噪声图片,在Unet结构的网络下,用引导特征和噪声图片,通过该网络多次处理,获得一个可以体现文字语义特征的新的特征矩阵,然后用解码器,将该特征矩阵恢复为图像。本文模仿SD思路,将pose guider出来的特征和noise相结合,然后丢给Unet结构模型去噪(复原出相应的语义特征)。跟SD不同的是,还另外采用了CLIP和VAE+referencenet,作为另一种语义特征,也加入到了Unet的计算过程。Unet的计算也做了改进,使用了spatial attention、cross attention、temporal attention的方式计算。)
ReferenceNet
在文本-视频的任务中,文本提示阐明了高级语义,只需要与生成的视觉内容具有语义相关性即可。 然而,在图像-视频的任务中,图像封装了更多低级细节特征,要求生成的结果具有精确的一致性。 在之前专注于图像驱动生成的研究中,大多数方法都采用CLIP图像编码器作为交叉注意力中文本编码器的替代品。 然而,这种设计未能解决与细节一致性相关的问题。 造成这种限制的原因之一是 CLIP 图像编码器的输入包含低分辨率 (224×224) 图像,导致大量细粒度细节信息丢失。 另一个因素是CLIP被训练来匹配文本的语义特征,强调高级特征匹配,从而导致特征编码中细节特征的缺失。
因此,作者设计了一种参考图像特征的提取网络——ReferenceNet。 采用与Denoising UNet 相同的框架,但不包括时间层。 ReferenceNet继承了原始SD的权重,并且每个权重更新都是独立进行的【指的是ReferenceNet和Denoising UNet的权重是分开更新的】。
然后将ReferenceNet中的特征集成到Denoising UNet中。 具体来说,如图2所示,将自注意力层替换为空间注意力层。 给定一个来自Denoising UNet的特征图![]() 和来自ReferenceNet的特征
和来自ReferenceNet的特征![]() 。首先将 x2 复制 t 次,并将其与 x1 沿 w 维度连接起来。 然后执行空间注意力并提取特征图的前半部分作为输出。(这里不太懂,要看代码)
。首先将 x2 复制 t 次,并将其与 x1 沿 w 维度连接起来。 然后执行空间注意力并提取特征图的前半部分作为输出。(这里不太懂,要看代码)
这种设计有两个优点:首先,ReferenceNet 可以利用原始 SD 中预先训练的图像特征建模功能,从而产生良好初始化的特征。 其次,由于ReferenceNet和Denoising UNet之间本质上相同的网络结构和共享的初始化权重,Denoising UNet可以选择性地从ReferenceNet中学习在同一特征空间中相关的特征【仅仅在初始化的时候,有这个增益】。 此外,使用 CLIP 图像编码器采用交叉注意力。 利用与文本编码器共享的特征空间,它提供参考图像的语义特征,作为有益的初始化来加速整个网络训练过程。
referenceNet同controlnet比较:
controlnet通过零卷积将额外的控制特征引入到去噪UNet中。然而,控制信息,比如深度和边缘,是与目标图像在空间上对齐的,而参考图像和目标图像在空间上相关但不对齐。因此,ControlNet 不适合直接应用。(含时的操作,随着时间推延,controlNet的方案所造成的误差会越来越大,这里有一个controlNet和该方法的对比,可以看到controlNet的结果图像相对于参考图像已经发生面部表情的变化,这就说明了这里controlNet参考图和目标图相关但不对齐)
虽然ReferenceNet引入了与去噪UNet相当数量的参数,在基于扩散的视频生成中,所有视频帧都要经过多次去噪,而ReferenceNet在整个过程中只需提取一次特征。因此,在推理过程中,这不会导致计算开销显著增加。

图7。只有ReferenceNet确保了角色外观细节的一致。
pose guider
由于Denoising UNet需要进行微调,作者选择不加入额外的控制网络,以防止计算复杂度显着增加。相反,作者采用了一个轻量级的姿势引导器。
该姿势引导器利用四个卷积层(4×4 kernels,2×2 strides,使用 16,32,64,128 个channels,类似于ControlNet中的条件编码器)来对齐姿势图像,其分辨率与潜在噪声相同。 随后,将处理后的姿态图像添加到潜在噪声中,然后输入到Denoising UNet 中。 Pose Guider 使用高斯权重进行初始化,在最终的投影层中,作者采用零卷积。
Temporal Layer
许多研究建议将另外的时间层合并到文本到图像(T2I)模型中,以捕获视频帧之间的时间依赖性。 此设计有助于从基础 T2I 模型转移预训练的图像生成功能。遵循这一原则,我们的时间层集成在 Res-Trans 块内的空间注意力和交叉注意力组件之后。 时间层的设计灵感来自 AnimateDiff。
具体来说,对于特征图![]() ,首先重塑为
,首先重塑为 ![]() ,然后进行时间注意力,即沿着t维度的自注意力。 来自时间层的特征通过残差连接合并到原始特征中。 时间层专门应用于Denoising UNet 的 Res-Trans 块内。 对于ReferenceNet,它计算单个参考图像的特征,并且不参与时间建模。 由于姿势引导器实现了连续角色运动的可控性,实验表明时间层确保了外观细节的时间平滑性和连续性,从而无需复杂的运动建模。
,然后进行时间注意力,即沿着t维度的自注意力。 来自时间层的特征通过残差连接合并到原始特征中。 时间层专门应用于Denoising UNet 的 Res-Trans 块内。 对于ReferenceNet,它计算单个参考图像的特征,并且不参与时间建模。 由于姿势引导器实现了连续角色运动的可控性,实验表明时间层确保了外观细节的时间平滑性和连续性,从而无需复杂的运动建模。
Training
训练过程分为两个阶段。
在第一阶段,使用单独的视频帧进行训练。 在去噪 UNet 中,我们暂时排除时间层,模型将单帧噪声作为输入。 ReferenceNet 和 Pose Guider 也在此阶段进行训练。 参考图像是从整个视频剪辑中随机选择的。 我们根据 SD 的预训练权重初始化Denoising UNet 和 ReferenceNet 的模型。 Pose Guider 使用高斯权重进行初始化,最终投影层除外,它使用零卷积。 VAE的编码器和解码器以及CLIP图像编码器的权重都保持固定。 此阶段的优化目标是使模型在给定参考图像和目标姿态的条件下生成高质量的动画图像。
在第二阶段,我们将时间层引入到之前训练的模型中,并使用 AnimateDiff 中的预训练权重对其进行初始化。 模型的输入由 24 帧视频剪辑组成。 在此阶段,我们仅训练时间层,同时固定网络其余部分的权重。
思考:
- 第一阶段:训练referenceNet和pose guider,使得这两者可以有效获取对应的特征。只拿单一的一张图像计算。得到一个可以生成用于vae解码的图像特征工具;
- 第二阶段:只训练降噪unet中间时间注意力计算层,使得得到的结果能够在时间上平滑。
训练细节
训练数据集:5K角色视频剪辑(2-10秒长)。使用DWPose提取视频中人物的姿态序列,并按照OpenPose将其渲染为姿态骨架图像。实验在4个NVIDIA A100 gpu上进行。
在第一个训练阶段,对单个视频帧进行采样,裁剪到768×768的分辨率。训练3万步,批次大小为64。在第二个训练阶段,用24帧视频序列训练时间层10000步,批处理大小为4。两个学习率都设为1e-5。在推理过程中,重新调整驾驶姿态骨架的长度,以近似于参考图像中角色骨架的长度,并使用DDIM采样器进行20步去噪。采用 Edge:Editable dance generation from music. 中的时间聚合方法,将不同批次的结果连接起来生成长视频。
定性结果:

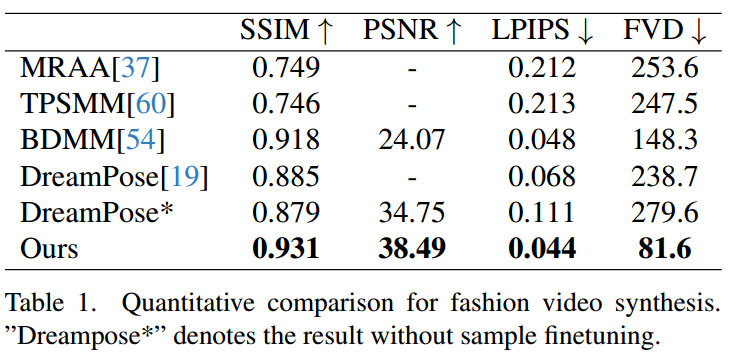
参考:


