
热门标签
热门文章
- 1Vue鼠标移动跟随特效(开箱即用)_vue鼠标特效
- 2Tomcat的最大并发数
- 3ruoyi登录流程_若依登录流程
- 4docker的ADD命令和COPY 命令的区别和连续_docker add copy
- 5keras使用gpu训练(tensor1.15 + cuda10.2)
- 6Tomcat之Web项目部署_tomcat部署web项目
- 7《Spring Cloud 微服务架构进阶》读书笔记_微服务架构分层 bootstrap模块 client模块 common controller dao
- 8git安装步骤
- 9通过BIM、GIS、IOT技术的有效融合智慧城市的规建管一体化CIM平台_基于bim+gis技术的智慧建造平台
- 10java-Websocket demo_java websocket demo
当前位置: article > 正文
书生浦语大模型实战营第四次课笔记
作者:2023面试高手 | 2024-02-15 20:07:47
赞
踩
书生浦语大模型实战营第四次课笔记

1.简介
1.1 XTuner简介
xtunner 是一个大语言模型微调工具箱,它提供了各种功能来帮助用户快速、轻松地微调大语言模型。这些功能包括:
- 数据预处理: xtunner 提供了一系列数据预处理工具,可以帮助用户将数据转换为适合大语言模型训练的格式。这些工具包括分词、词干提取、停用词去除等。
- 模型选择: xtunner 提供了多种预训练的大语言模型供用户选择,包括 BERT、GPT-3、T5 等。用户还可以根据自己的需求选择不同的模型架构和参数。
- 微调任务: xtunner 支持多种微调任务,包括文本分类、文本生成、机器翻译、问答等。用户可以根据自己的需求选择不同的微调任务。
- 微调过程: xtunner 提供了一个直观、易用的微调过程,用户可以轻松地调整模型的超参数、训练数据和训练时间等。
- 模型评估: xtunner 提供了多种模型评估指标,可以帮助用户评估模型的性能。这些指标包括准确率、召回率、F1 分数等。
- 模型部署: xtunner 提供了一系列模型部署工具,可以帮助用户将微调好的模型部署到生产环境中。这些工具包括模型导出、模型压缩等。
xtunner 的主要优点包括:
- 易用性: xtunner 提供了一个直观、易用的界面,即使是没有任何机器学习经验的用户也可以轻松地使用它来微调大语言模型。
- 灵活性: xtunner 支持多种预训练的大语言模型、微调任务和模型评估指标,用户可以根据自己的需求选择不同的配置。
- 可扩展性: xtunner 可以轻松地扩展到大型数据集和复杂的微调任务上,用户可以利用它来微调大规模的大语言模型。
1.2 Fintune简介

示例:

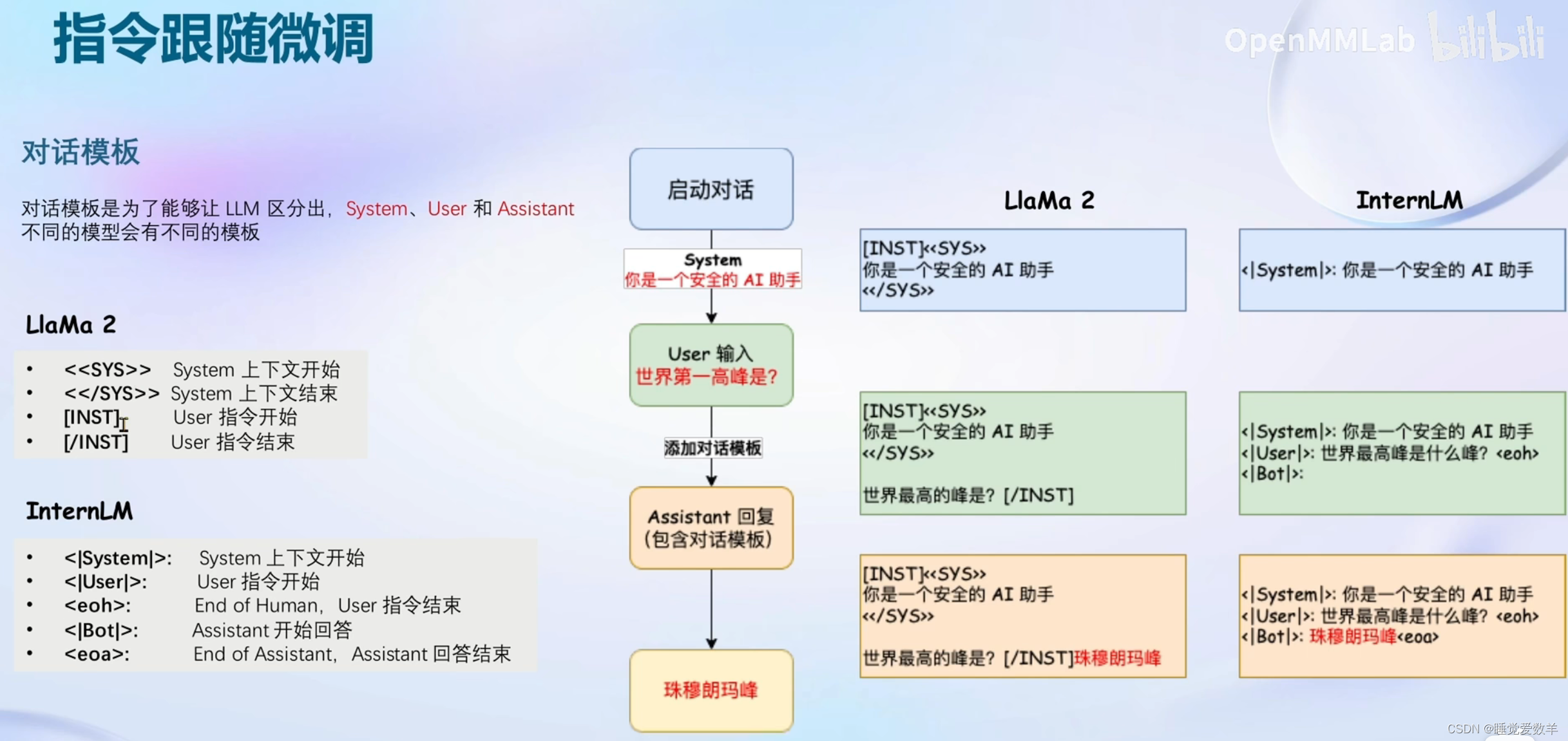
1.3 指令跟随微调

1.4 增量预训练微调

1.6 LoRA & QLoRA


1.7 Xtuner

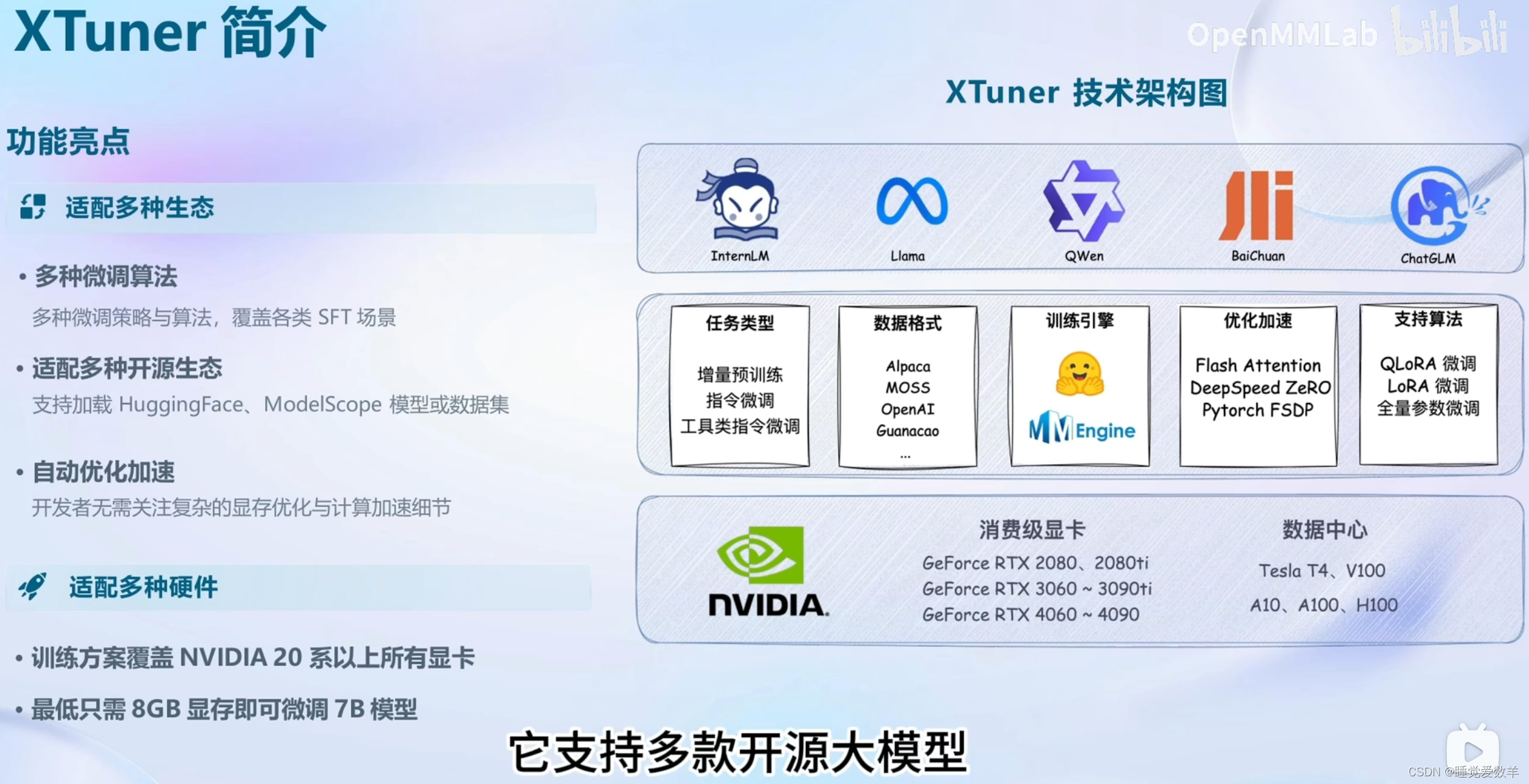
2. demo
2.1 安装XTuner

2.2 准备数据集和配置文件
OASST1数据集
OpenAssistant Conversations(OASST1),这是一个人工生成的、人工注释的辅助风格对话语料库,由35种不同语言的161443条消息组成,注释了461292个质量评级,产生了超过10000个完全注释的对话树。该语料库是涉及13500多名志愿者的全球众包活动的产物。
根据教程直接复制即可
2.3 开始训练
2.4 将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹

2.5 将 HuggingFace adapter 合并到大语言模型

有一个error,不知道有没有影响
demo: 略
2.6 自定义微调
以 Medication QA 数据集为例
基于 InternLM-chat-7B 模型,用 MedQA 数据集进行微调,将其往医学问答领域对齐。
2.6.1 训练

2.6.2 将得到的 PTH 模型转换为 HuggingFace 模型
修改为自己的配置文件和模型:
2.6.3 将 HuggingFace adapter 合并到大语言模型

2.6.4 测试
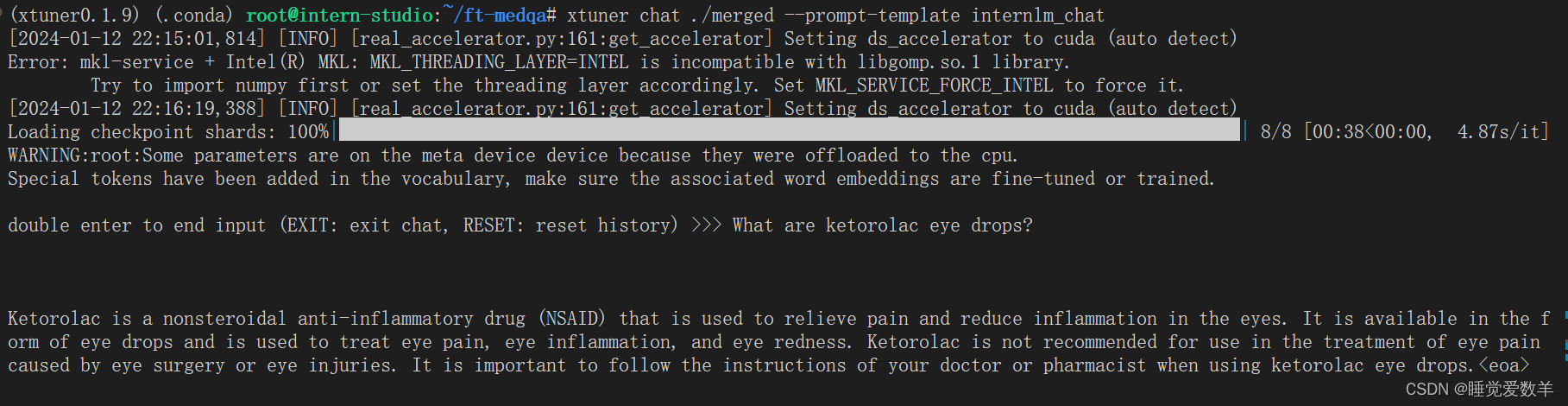
微调后:
无微调:
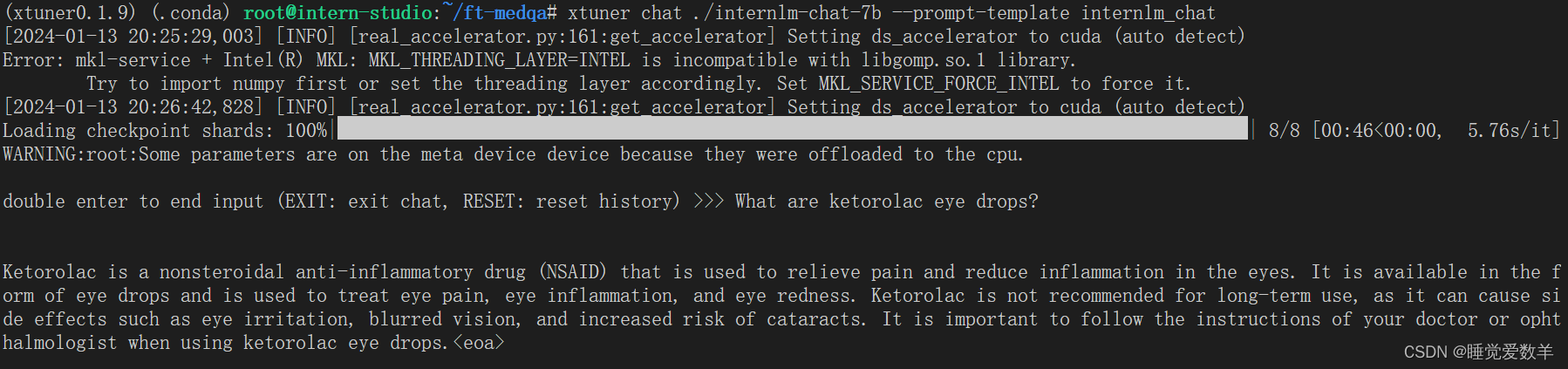
竟然没有任何区别,不知道为啥,可能是训练还没收敛?
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/86583
推荐阅读
相关标签

