
【语义分割】unet结构和代码实现_unet代码
赞
踩
前言
Unet是2015年诞生的模型,它几乎是当segmentation项目中应用最广的模型。
Unet已经成为大多做医疗影像语义分割任务的最基础的网络结构。也启发了大量研究者去思考U型语义分割网络。即使在自然影像理解方面,也有越来越多的语义分割和目标检测模型开始关注和使用U型结构
Unet能从更少的训练图像中进行学习。当它在少于 40 张图的生物医学数据集上训练时,IOU 值仍能达到 92%。
其姊妹篇 linknet的学习,敬请期待
1.语义分割的UNET网络结构
1.1 结构
U-net网络非常简单,前半部分作用是特征提取,后半部分是上采样。在一些文献中也把这样的结构叫做编码器-解码器结构。由于此网络整体结构类似于大写的英文字母U,故得名U-net。
U-net与其他常见的分割网络有一点非常不同的地方:U-net采用了完全不同的特征融合方式:拼接(tf.concat)U-net采用将特征在channel维度拼接在一起,形成更厚的特征。而FCN融合时使用的对应点相加,并不形成更厚的特征。
语义分割网络在特征融合时有两种办法:
- FCN式的对应点相加,对应于TensorFlow中的tf.add()函数;
- U-net式的channel维度拼接融合,对应TensorFlow的tf.concat()函数,比较占显存。
1.2 特点
1、网络对图像特征的多尺度特征识别。
2、上采样部分会融合特征提取部分的输出,这样做实际上是将多尺
度特征融合在了一起,以最后一个上采样为例,它的特征既来自第一
个卷积block的输出(同尺度特征),也来自上采样的输出(大尺度特征),
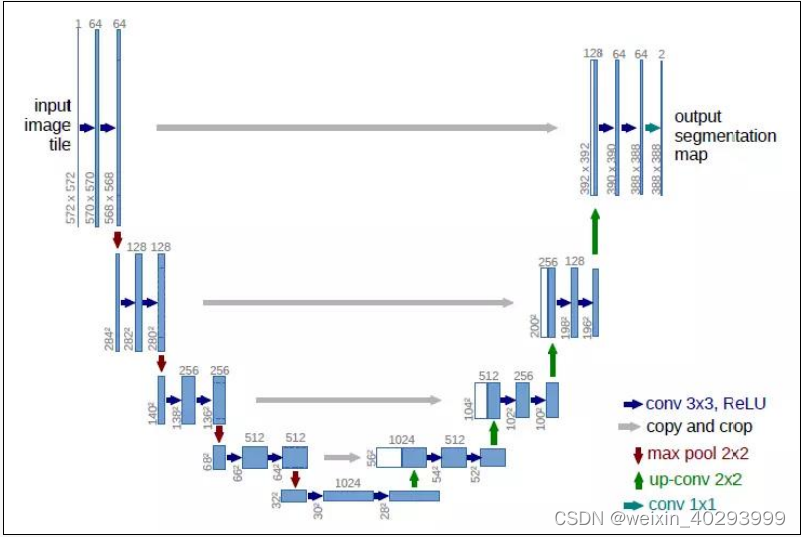
Unet的左侧是convolution layers,
右侧则是upsamping layers,
convolutions layers中每个pooling layer前输出值
会concatenate到对应的upsamping层的输出值中。
注意是concatenate,而FCN是add
2. 代码实现
2.1 数据初探
用的是香港中文大学的数据
# 显示1张图片
res = Image.open(r'F:\hk\training\00001.png')
res
- 1
- 2
- 3

标签:
pil_img = Image.open(r'F:\hk\training\00001_matte.png')
np_img = np.array(pil_img)
plt.imshow(np_img)
plt.show()
- 1
- 2
- 3
- 4
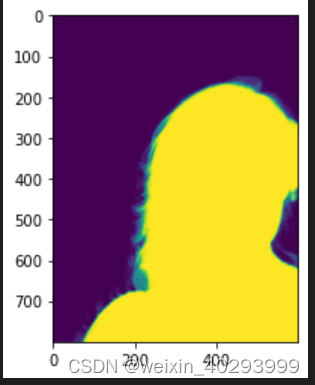
查看原图像有多少像素值
np.unique(np_img)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77,
78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90,
91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103,
104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116,
117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129,
130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142,
143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155,
156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168,
169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181,
182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194,
195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207,
208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220,
221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233,
234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246,
247, 248, 249, 250, 251, 252, 253, 254, 255], dtype=uint8)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2.2 构建数据集
# 构建训练集, 测试集
all_pics = glob.glob(r'F:\hk\training\*.png')
all_pics[:5]
['F:\\hk\\training\\00001.png',
'F:\\hk\\training\\00001_matte.png',
'F:\\hk\\training\\00002.png',
'F:\\hk\\training\\00002_matte.png',
'F:\\hk\\training\\00003.png']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
区分出 图片和label,可以看到一共1700张
images= [p for p in all_pics if 'matte' not in p]
annotations = [p for p in all_pics if 'matte' in p]
len(annotations)
1700
- 1
- 2
- 3
- 4
打乱顺序,为保证可以复现,用一个固定的随机种子
# 随便取出一张来
np.random.seed(2023)
index = np.random.permutation(len(images))
index
array([ 630, 1065, 14, ..., 454, 1561, 855])
- 1
- 2
- 3
- 4
- 5
测试集同理:
# test 和 train 是平行的
# 构建训练集, 测试集
all_test_pics = glob.glob(r'F:\hk\testing\*.png')
test_images = [p for p in all_test_pics if 'matte' not in p]
test_anno = [p for p in all_test_pics if 'matte' in p]
- 1
- 2
- 3
- 4
- 5
resize & 转tensor, 转tensor的同时,它会把特征调到0-1范围内,并且增加c维度, 构成 c,h,w的形式
transform = transforms.Compose([
transforms.Resize((256,256)),
transforms.ToTensor(),
])
- 1
- 2
- 3
- 4
构建dataset
# 这个方法很有用, 让训练集和测试集有了 切片的功能
class Portrait_dataset(data.Dataset):
def __init__(self, img_paths, anno_paths) -> None:
super().__init__()
self.imgs = img_paths
self.annos = anno_paths
def __getitem__(self, index):
img = self.imgs[index]
anno = self.annos[index]
pil_img = Image.open(img)
img_tensor = transform(pil_img)
anno_img = Image.open(anno)
anno_tensor = transform(anno_img)
anno_tensor = torch.squeeze(anno_tensor).type(torch.long)
anno_tensor[anno_tensor>0] = 1
return img_tensor, anno_tensor
def __len__(self):
return len(self.imgs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
构建测试集训练集
train_dataset = Portrait_dataset(images, anno)
test_dataset = Portrait_dataset(test_images, test_anno)
BATCH_SIZE = 12
train_dl = data.DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_dl = data.DataLoader(
test_dataset,
batch_size=BATCH_SIZE,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
看一张长得什么样子
imgs_batch, annos_batch = next(iter(train_dl))
img = imgs_batch[0].permute(1,2,0).numpy()
anno = annos_batch[0].numpy()
plt.subplot(1,2,1)
plt.imshow(img)
plt.subplot(1,2,2)
plt.imshow(anno)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

2.3 构建网络
分三部分, 下采样,上采样 和全体网络
class Downsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Downsample, self).__init__()
self.conv_relu = nn.Sequential(
nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels,
kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
self.pool = nn.MaxPool2d(kernel_size=2)
def forward(self, x, is_pool=True):
if is_pool:
x = self.pool(x)
x = self.conv_relu(x)
return x
class Upsample(nn.Module):
def __init__(self, channels):
super().__init__()
self.conv_relu = nn.Sequential(
nn.Conv2d(2*channels,channels,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channels,channels,kernel_size=3,padding=1),
nn.ReLU(inplace=True)
)
self.upconv_relu = nn.Sequential(
nn.ConvTranspose2d(
channels,
channels//2,
kernel_size=3,
stride=2,
padding=1,
output_padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv_relu(x)
x = self.upconv_relu(x)
return x
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.down1 = Downsample(3, 64)
self.down2 = Downsample(64, 128)
self.down3 = Downsample(128, 256)
self.down4 = Downsample(256, 512)
self.down5 = Downsample(512, 1024)
self.up = nn.Sequential(
nn.ConvTranspose2d(1024,
512,
kernel_size=3,
stride=2,
padding=1,
output_padding=1),
nn.ReLU(inplace=True)
)
self.up1 = Upsample(512)
self.up2 = Upsample(256)
self.up3 = Upsample(128)
self.conv_2 = Downsample(128, 64)
self.last = nn.Conv2d(64, 2, kernel_size=1)
def forward(self, x):
x1 = self.down1(x, is_pool=False)
x2 = self.down2(x1)
x3 = self.down3(x2)
x4 = self.down4(x3)
x5 = self.down5(x4)
x5 = self.up(x5)
x5 = torch.cat([x4, x5], dim=1) # 32*32*1024
x5 = self.up1(x5) # 64*64*256)
x5 = torch.cat([x3, x5], dim=1) # 64*64*512
x5 = self.up2(x5) # 128*128*128
x5 = torch.cat([x2, x5], dim=1) # 128*128*256
x5 = self.up3(x5) # 256*256*64
x5 = torch.cat([x1, x5], dim=1) # 256*256*128
x5 = self.conv_2(x5, is_pool=False) # 256*256*64
x5 = self.last(x5) # 256*256*3
return x5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
2.4 训练网络
model = Net()
if torch.cuda.is_available():
model.to('cuda')
loss_fn = nn.CrossEntropyLoss()
from torch.optim import lr_scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
def fit(epoch, model, trainloader, testloader):
correct = 0
total = 0
running_loss = 0
model.train()
for x, y in trainloader:
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
exp_lr_scheduler.step()
epoch_loss = running_loss / len(trainloader.dataset)
epoch_acc = correct / (total*256*256)
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad():
for x, y in testloader:
if torch.cuda.is_available():
x, y = x.to('cuda'), y.to('cuda')
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / (test_total*256*256)
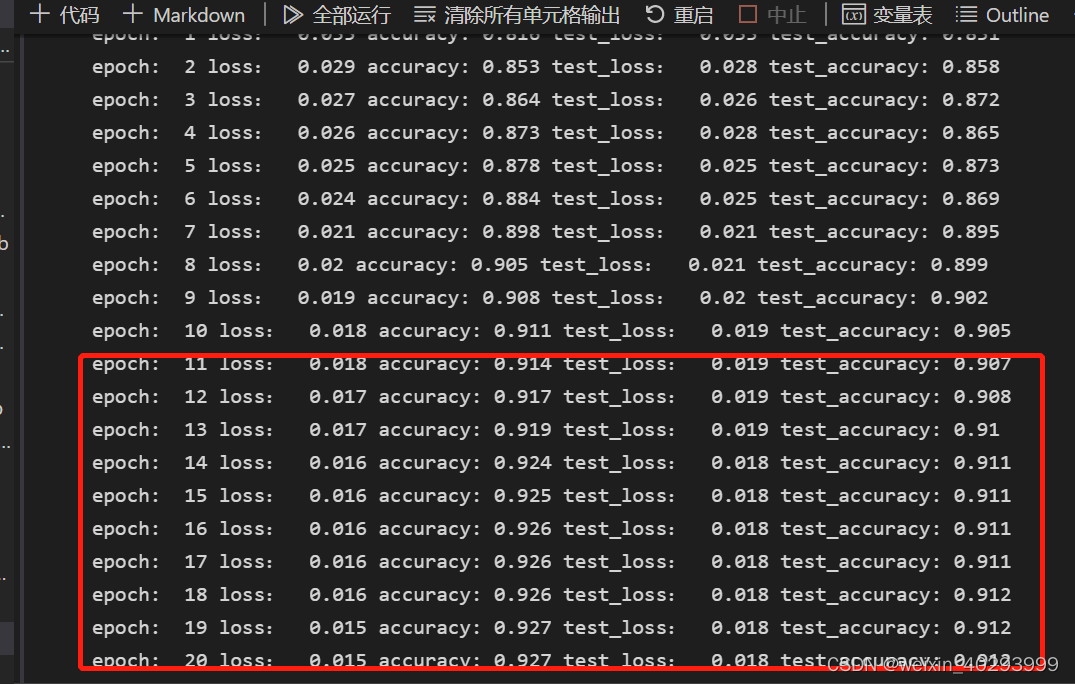
print('epoch: ', epoch,
'loss: ', round(epoch_loss, 3),
'accuracy:', round(epoch_acc, 3),
'test_loss: ', round(epoch_test_loss, 3),
'test_accuracy:', round(epoch_test_acc, 3)
)
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,
model,
train_dl,
test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
后面10轮次的正确率已经不提高了,所以应该用earlier stop 策略
2.5 保存模型 & 测试
保存模型
PATH = 'unet_model.pth'
torch.save(model.state_dict(), PATH)
- 1
- 2
测试模型
my_model = Net()
my_model.load_state_dict(torch.load(PATH))
num=3
image, mask = next(iter(test_dl))
pred_mask = my_model(image)
plt.figure(figsize=(10, 10))
for i in range(num):
plt.subplot(num, 3, i*num+1)
plt.imshow(image[i].permute(1,2,0).cpu().numpy())
plt.subplot(num, 3, i*num+2)
plt.imshow(mask[i].cpu().numpy())
plt.subplot(num, 3, i*num+3)
plt.imshow(torch.argmax(pred_mask[i].permute(1,2,0), axis=-1).detach().numpy())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

3. 总结
语义分割训练的过程很慢,因为对每一个像素分类的原因。
earily stop 是必须使用的。
他的结构,downsample 和 upsample的代码,以及融合代码要反复琢磨,还没完全学会。
4.补充 20230113
代码在这里:https://github.com/justinge/learn_pytorch/blob/main/UNET%E5%9B%BE%E5%83%8F%E8%AF%AD%E4%B9%89%E5%88%86%E5%89%B2.ipynb

