
- 1Spring boot集成RocketMQ_springboot集成rocketmq最新
- 2使用jscpd统计项目中的代码重复度
- 3Python生成依赖性应用的DAG(有向无环图)拓扑_随机生成有向无环图python
- 4蓝桥杯python组练题第8天——递增序列(暴力)——蓝桥杯官网题库(国赛)_nnzvlp
- 5树的搜索问题2——分支界限和A*算法(多阶段图问题、人员安排问题和旅行商问题)_a star算法属不属于分支界限算法
- 6AtCoder Beginner Contest 193 C-Unexpressed_at coder 100000 99634
- 7C# 获取QQ会话聊天信息
- 8【漏洞复现-solr-命令执行】vulfocus/solr-cve_2019_17558
- 9封装自己专属的真正的纯净版Windows系统过程记录(2)——使用习惯设置,软件安装与优化设置_ltsc优化设置
- 10Win11 25188.1000补丁包介绍及下载地址_win11大版本升级补丁
42个Python实用小例子[内附200+代码地址]python小程序200例_python精彩编程200例
赞
踩
前言
经常有同学苦恼,学了python基础之后找不到合适的练手机会。为此,有位热心人创建了一个项目,搜集整理了一堆实用的python代码小例子。这些小例子包括但不限于:Python基础、Web开发、数据科学、机器学习等方向,短小精炼,力争让你60秒学会一个小例子。
项目分享出来后,又得到了很多小伙伴的积极响应。现在,这个库里已经有了200多个小例子。
今天我们就挑了其中的42个例子分享给大家。

一、基本操作
1 链式比较
i = 3
print(1 < i < 3) # False
print(1 < i <= 3) # True
- 1
- 2
- 3
- 4
2 不用else和if实现计算器
from operator import *
def calculator(a, b, k):
return {
'+': add,
'-': sub,
'*': mul,
'/': truediv,
'**': pow
}[k](a, b)
calculator(1, 2, '+') # 3
calculator(3, 4, '**') # 81
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3 函数链
from operator import (add, sub)
def add_or_sub(a, b, oper):
return (add if oper == '+' else sub)(a, b)
add_or_sub(1, 2, '-') # -1
4 求字符串的字节长度
def str_byte_len(mystr):
return (len(mystr.encode('utf-8')))
str_byte_len('i love python') # 13(个字节)
str_byte_len('字符') # 6(个字节)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5 寻找第n次出现位置
def search_n(s, c, n):
size = 0
for i, x in enumerate(s):
if x == c:
size += 1
if size == n:
return i
return -1
print(search_n("fdasadfadf", "a", 3))# 结果为7,正确
print(search_n("fdasadfadf", "a", 30))# 结果为-1,正确
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6 去掉最高最低求平均
def score_mean(lst):
lst.sort()
lst2=lst[1:(len(lst)-1)]
return round((sum(lst2)/len(lst2)),2)
score_mean([9.1, 9.0,8.1, 9.7, 19,8.2, 8.6,9.8]) # 9.07
- 1
- 2
- 3
- 4
- 5
- 6
- 7
7 交换元素
def swap(a, b):
return b, a
swap(1, 0) # (0,1)
- 1
- 2
- 3
- 4
- 5
二、基础算法
1 二分搜索
def binarySearch(arr, left, right, x): while left <= right: mid = int(left + (right - left) / 2); # 找到中间位置。求中点写成(left+right)/2更容易溢出,所以不建议这样写 # 检查x是否出现在位置mid if arr[mid] == x: print('found %d 在索引位置%d 处' %(x,mid)) return mid # 假如x更大,则不可能出现在左半部分 elif arr[mid] < x: left = mid + 1 #搜索区间变为[mid+1,right] print('区间缩小为[%d,%d]' %(mid+1,right)) elif x<arr[mid]: right = mid - 1 #搜索区间变为[left,mid-1] print('区间缩小为[%d,%d]' %(left,mid-1)) return -1

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2 距离矩阵
x,y = mgrid[0:5,0:5]
list(map(lambda xe,ye: [(ex,ey) for ex, ey in zip(xe, ye)], x,y))
[[(0, 0), (0, 1), (0, 2), (0, 3), (0, 4)],
[(1, 0), (1, 1), (1, 2), (1, 3), (1, 4)],
[(2, 0), (2, 1), (2, 2), (2, 3), (2, 4)],
[(3, 0), (3, 1), (3, 2), (3, 3), (3, 4)],
[(4, 0), (4, 1), (4, 2), (4, 3), (4, 4)]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
三、列表
1 打印乘法表
for i in range(1,10):
for j in range(1,i+1):
print('{0}*{1}={2}'.format(j,i,j*i),end="\t")
print()
- 1
- 2
- 3
- 4
- 5
结果:
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2 嵌套数组完全展开
from collections.abc import *
def flatten(input_arr, output_arr=None):
if output_arr is None:
output_arr = []
for ele in input_arr:
if isinstance(ele, Iterable): # 判断ele是否可迭代
flatten(ele, output_arr) # 尾数递归
else:
output_arr.append(ele) # 产生结果
return output_arr
flatten([[1,2,3],[4,5]], [6,7]) # [6, 7, 1, 2, 3, 4, 5]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3 将list等分为子组
from math import ceil
def divide(lst, size):
if size <= 0:
return [lst]
return [lst[i * size:(i+1)*size] for i in range(0, ceil(len(lst) / size))]
r = divide([1, 3, 5, 7, 9], 2) # [[1, 3], [5, 7], [9]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4 生成fibonacci序列前n项
def fibonacci(n):
if n <= 1:
return [1]
fib = [1, 1]
while len(fib) < n:
fib.append(fib[len(fib) - 1] + fib[len(fib) - 2])
return fib
fibonacci(5) # [1, 1, 2, 3, 5]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5 过滤掉各种空值
def filter_false(lst):
return list(filter(bool, lst))
filter_false([None, 0, False, '', [], 'ok', [1, 2]])# ['ok', [1, 2]]
- 1
- 2
- 3
- 4
- 5
6 返回列表头元素
def head(lst):
return lst[0] if len(lst) > 0 else None
head([]) # None
head([3, 4, 1]) # 3
- 1
- 2
- 3
- 4
- 5
- 6
7 返回列表尾元素
def tail(lst):
return lst[-1] if len(lst) > 0 else None
print(tail([])) # None
print(tail([3, 4, 1])) # 1
- 1
- 2
- 3
- 4
- 5
- 6
8 对象转换为可迭代类型
from collections.abc import Iterable
def cast_iterable(val):
return val if isinstance(val, Iterable) else [val]
cast_iterable('foo')# foo
cast_iterable(12)# [12]
cast_iterable({'foo': 12})# {'foo': 12}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
9 求更长列表
def max_length(*lst):
return max(*lst, key=lambda v: len(v))
r = max_length([1, 2, 3], [4, 5, 6, 7], [8])# [4, 5, 6, 7]
- 1
- 2
- 3
- 4
- 5
10 出现最多元素
def max_frequency(lst):
return max(lst, default='列表为空', key=lambda v: lst.count(v))
lst = [1, 3, 3, 2, 1, 1, 2]
max_frequency(lst) # 1
- 1
- 2
- 3
- 4
- 5
- 6
11 求多个列表的最大值
def max_lists(*lst):
return max(max(*lst, key=lambda v: max(v)))
max_lists([1, 2, 3], [6, 7, 8], [4, 5]) # 8
- 1
- 2
- 3
- 4
- 5
12 求多个列表的最小值
def min_lists(*lst):
return min(min(*lst, key=lambda v: max(v)))
min_lists([1, 2, 3], [6, 7, 8], [4, 5]) # 1
- 1
- 2
- 3
- 4
- 5
13 检查list是否有重复元素
def has_duplicates(lst):
return len(lst) == len(set(lst))
x = [1, 1, 2, 2, 3, 2, 3, 4, 5, 6]
y = [1, 2, 3, 4, 5]
has_duplicates(x) # False
has_duplicates(y) # True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
14 求列表中所有重复元素
from collections import Counter
def find_all_duplicates(lst):
c = Counter(lst)
return list(filter(lambda k: c[k] > 1, c))
find_all_duplicates([1, 2, 2, 3, 3, 3]) # [2,3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
15 列表反转
def reverse(lst):
return lst[::-1]
reverse([1, -2, 3, 4, 1, 2])# [2, 1, 4, 3, -2, 1]
- 1
- 2
- 3
- 4
- 5
16 浮点数等差数列
def rang(start, stop, n):
start,stop,n = float('%.2f' % start), float('%.2f' % stop),int('%.d' % n)
step = (stop-start)/n
lst = [start]
while n > 0:
start,n = start+step,n-1
lst.append(round((start), 2))
return lst
rang(1, 8, 10) # [1.0, 1.7, 2.4, 3.1, 3.8, 4.5, 5.2, 5.9, 6.6, 7.3, 8.0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
四、字典
1 字典值最大的键值对列表
def max_pairs(dic):
if len(dic) == 0:
return dic
max_val = max(map(lambda v: v[1], dic.items()))
return [item for item in dic.items() if item[1] == max_val]
max_pairs({'a': -10, 'b': 5, 'c': 3, 'd': 5})# [('b', 5), ('d', 5)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2 字典值最小的键值对列表
def min_pairs(dic):
if len(dic) == 0:
return []
min_val = min(map(lambda v: v[1], dic.items()))
return [item for item in dic.items() if item[1] == min_val]
min_pairs({}) # []
r = min_pairs({'a': -10, 'b': 5, 'c': 3, 'd': 5})
print(r) # [('b', 5), ('d', 5)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3 合并两个字典
def merge_dict2(dic1, dic2):
return {**dic1, **dic2} # python3.5后支持的一行代码实现合并字典
merge_dict({'a': 1, 'b': 2}, {'c': 3}) # {'a': 1, 'b': 2, 'c': 3}
- 1
- 2
- 3
- 4
- 5
4 求字典前n个最大值
from heapq import nlargest
# 返回字典d前n个最大值对应的键
def topn_dict(d, n):
return nlargest(n, d, key=lambda k: d[k])
topn_dict({'a': 10, 'b': 8, 'c': 9, 'd': 10}, 3) # ['a', 'd', 'c']
5 求最小键值对
d={'a':-10,'b':5, 'c':3,'d':5}
min(d.items(),key=lambda x:x[1]) #('a', -10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
五、集合
1 互为变位词
from collections import Counter
# 检查两个字符串是否 相同字母异序词,简称:互为变位词
def anagram(str1, str2):
return Counter(str1) == Counter(str2)
anagram('eleven+two', 'twelve+one') # True 这是一对神器的变位词
anagram('eleven', 'twelve') # False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
六、文件操作
1 查找指定文件格式文件
import os
def find_file(work_dir,extension='jpg'):
lst = []
for filename in os.listdir(work_dir):
print(filename)
splits = os.path.splitext(filename)
ext = splits[1] # 拿到扩展名
if ext == '.'+extension:
lst.append(filename)
return lst
find_file('.','md') # 返回所有目录下的md文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
七、正则和爬虫
1 爬取天气数据并解析温度值
素材来自朋友袁绍
import requests
from lxml import etree
import pandas as pd
import re
url = 'http://www.weather.com.cn/weather1d/101010100.shtml#input'
with requests.get(url) as res:
content = res.content
html = etree.HTML(content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
通过lxml模块提取值,lxml比beautifulsoup解析在某些场合更高效
location = html.xpath('//*[@id="around"]//a[@target="_blank"]/span/text()')
temperature = html.xpath('//*[@id="around"]/div/ul/li/a/i/text()')
- 1
- 2
- 3
结果:
['香河', '涿州', '唐山', '沧州', '天津', '廊坊', '太原', '石家庄', '涿鹿', '张家口', '保定', '三河', '北京孔庙', '北京国子监', '中国地质博物馆', '月坛公
园', '明城墙遗址公园', '北京市规划展览馆', '什刹海', '南锣鼓巷', '天坛公园', '北海公园', '景山公园', '北京海洋馆']
['11/-5°C', '14/-5°C', '12/-6°C', '12/-5°C', '11/-1°C', '11/-5°C', '8/-7°C', '13/-2°C', '8/-6°C', '5/-9°C', '14/-6°C', '11/-4°C', '13/-3°C'
, '13/-3°C', '12/-3°C', '12/-3°C', '13/-3°C', '12/-2°C', '12/-3°C', '13/-3°C', '12/-2°C', '12/-2°C', '12/-2°C', '12/-3°C']
df = pd.DataFrame({'location':location, 'temperature':temperature})
print('温度列')
print(df['temperature'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
正则解析温度值
df['high'] = df['temperature'].apply(lambda x: int(re.match('(-?[0-9]*?)/-?[0-9]*?°C', x).group(1) ) )
df['low'] = df['temperature'].apply(lambda x: int(re.match('-?[0-9]*?/(-?[0-9]*?)°C', x).group(1) ) )
print(df)
- 1
- 2
- 3
- 4
详细说明子字符创捕获
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(group)。比如:^(\d{3})-(\d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码
m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
print(m.group(0))
print(m.group(1))
print(m.group(2))
# 010-12345
# 010
# 12345
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
最终结果
Name: temperature, dtype: object location temperature high low 0 香河 11/-5°C 11 -5 1 涿州 14/-5°C 14 -5 2 唐山 12/-6°C 12 -6 3 沧州 12/-5°C 12 -5 4 天津 11/-1°C 11 -1 5 廊坊 11/-5°C 11 -5 6 太原 8/-7°C 8 -7 7 石家庄 13/-2°C 13 -2 8 涿鹿 8/-6°C 8 -6 9 张家口 5/-9°C 5 -9 10 保定 14/-6°C 14 -6 11 三河 11/-4°C 11 -4 12 北京孔庙 13/-3°C 13 -3 13 北京国子监 13/-3°C 13 -3 14 中国地质博物馆 12/-3°C 12 -3 15 月坛公园 12/-3°C 12 -3 16 明城墙遗址公园 13/-3°C 13 -3 17 北京市规划展览馆 12/-2°C 12 -2 18 什刹海 12/-3°C 12 -3 19 南锣鼓巷 13/-3°C 13 -3 20 天坛公园 12/-2°C 12 -2 21 北海公园 12/-2°C 12 -2 22 景山公园 12/-2°C 12 -2 23 北京海洋馆 12/-3°C 12 -3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2 批量转化驼峰格式
import re
def camel(s):
s = re.sub(r"(\s|_|-)+", " ", s).title().replace(" ", "")
return s[0].lower() + s[1:]
# 批量转化
def batch_camel(slist):
return [camel(s) for s in slist]
batch_camel(['student_id', 'student\tname', 'student-add']) #['studentId', 'studentName', 'studentAdd']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
八、绘图
1 turtle绘制奥运五环图
结果:

2 turtle绘制漫天雪花
结果:

3 4种不同颜色的色块,它们的颜色真的不同吗?

4 词频云图
import hashlib import pandas as pd from wordcloud import WordCloud geo_data=pd.read_excel(r"../data/geo_data.xlsx") words = ','.join(x for x in geo_data['city'] if x != []) #筛选出非空列表值 wc = WordCloud( background_color="green", #背景颜色"green"绿色 max_words=100, #显示最大词数 font_path='./fonts/simhei.ttf', #显示中文 min_font_size=5, max_font_size=100, width=500 #图幅宽度 ) x = wc.generate(words) x.to_file('../data/geo_data.png')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

九、生成器
1 求斐波那契数列前n项(生成器版)
def fibonacci(n):
a, b = 1, 1
for _ in range(n):
yield a
a, b = b, a + b
list(fibonacci(5)) # [1, 1, 2, 3, 5]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2 将list等分为子组(生成器版)
from math import ceil
def divide_iter(lst, n):
if n <= 0:
yield lst
return
i, div = 0, ceil(len(lst) / n)
while i < n:
yield lst[i * div: (i + 1) * div]
i += 1
list(divide_iter([1, 2, 3, 4, 5], 0)) # [[1, 2, 3, 4, 5]]
list(divide_iter([1, 2, 3, 4, 5], 2)) # [[1, 2, 3], [4, 5]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
十、keras
1 Keras入门例子
import numpy as np from keras.models import Sequential from keras.layers import Dense data = np.random.random((1000, 1000)) labels = np.random.randint(2, size=(1000, 1)) model = Sequential() model.add(Dense(32, activation='relu', input_dim=100)) model.add(Dense(1, activation='sigmoid')) model.compile(optimize='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) model.fit(data, labels, epochs=10, batch_size=32) predictions = model.predict(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-END-
一、Python入门
下面这些内容是Python各个应用方向都必备的基础知识,想做爬虫、数据分析或者人工智能,都得先学会他们。任何高大上的东西,都是建立在原始的基础之上。打好基础,未来的路会走得更稳重。所有资料文末免费领取!!!
包含:
计算机基础
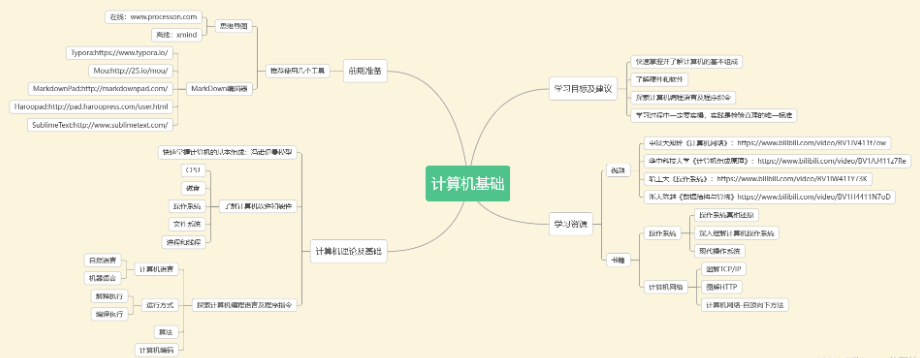
python基础

Python入门视频600集:
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
二、Python爬虫
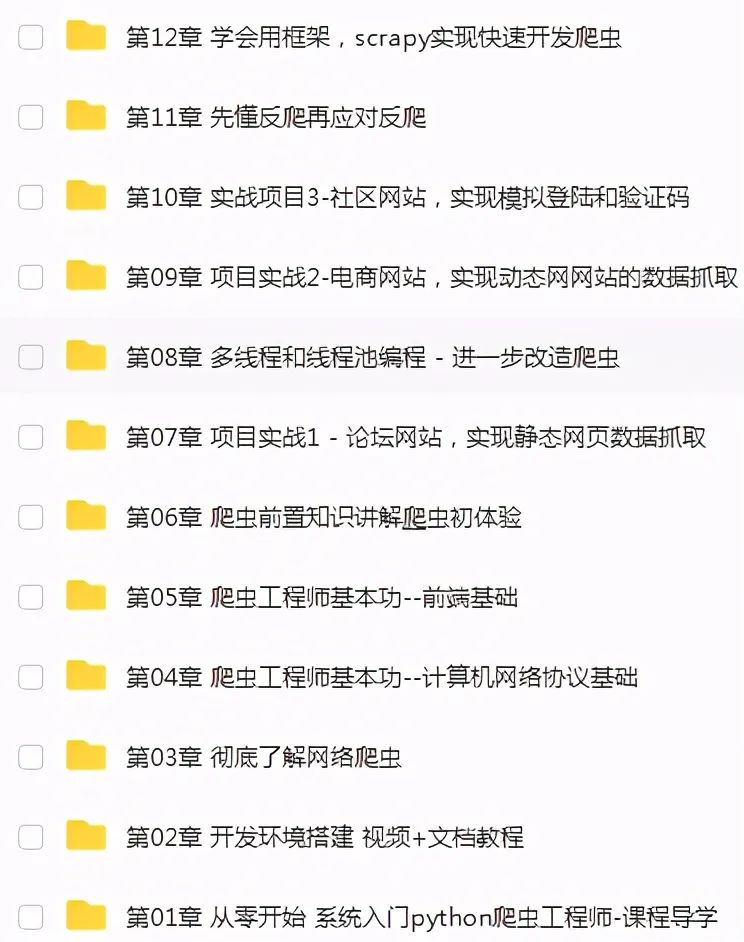
爬虫作为一个热门的方向,不管是在自己兼职还是当成辅助技能提高工作效率,都是很不错的选择。
通过爬虫技术可以将相关的内容收集起来,分析删选后得到我们真正需要的信息。
这个信息收集分析整合的工作,可应用的范畴非常的广泛,无论是生活服务、出行旅行、金融投资、各类制造业的产品市场需求等等,都能够借助爬虫技术获取更精准有效的信息加以利用。

Python爬虫视频资料
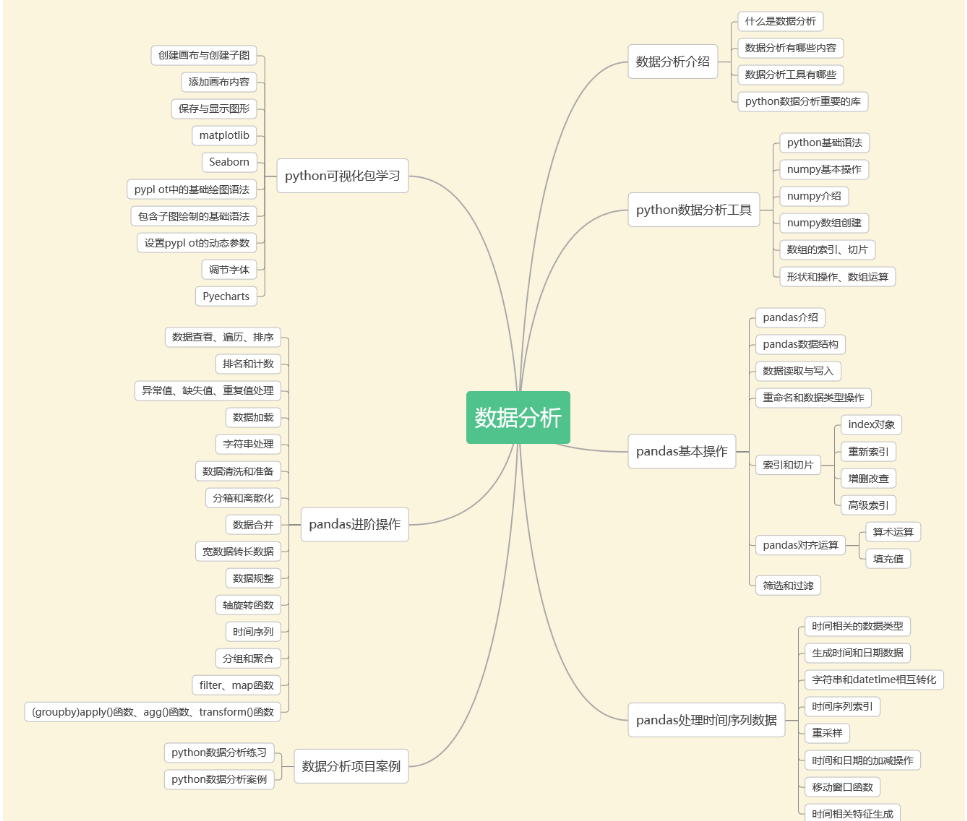
三、数据分析
清华大学经管学院发布的《中国经济的数字化转型:人才与就业》报告显示,2025年,数据分析人才缺口预计将达230万。
这么大的人才缺口,数据分析俨然是一片广阔的蓝海!起薪10K真的是家常便饭。
四、数据库与ETL数仓
企业需要定期将冷数据从业务数据库中转移出来存储到一个专门存放历史数据的仓库里面,各部门可以根据自身业务特性对外提供统一的数据服务,这个仓库就是数据仓库。
传统的数据仓库集成处理架构是ETL,利用ETL平台的能力,E=从源数据库抽取数据,L=将数据清洗(不符合规则的数据)、转化(对表按照业务需求进行不同维度、不同颗粒度、不同业务规则计算进行统计),T=将加工好的表以增量、全量、不同时间加载到数据仓库。
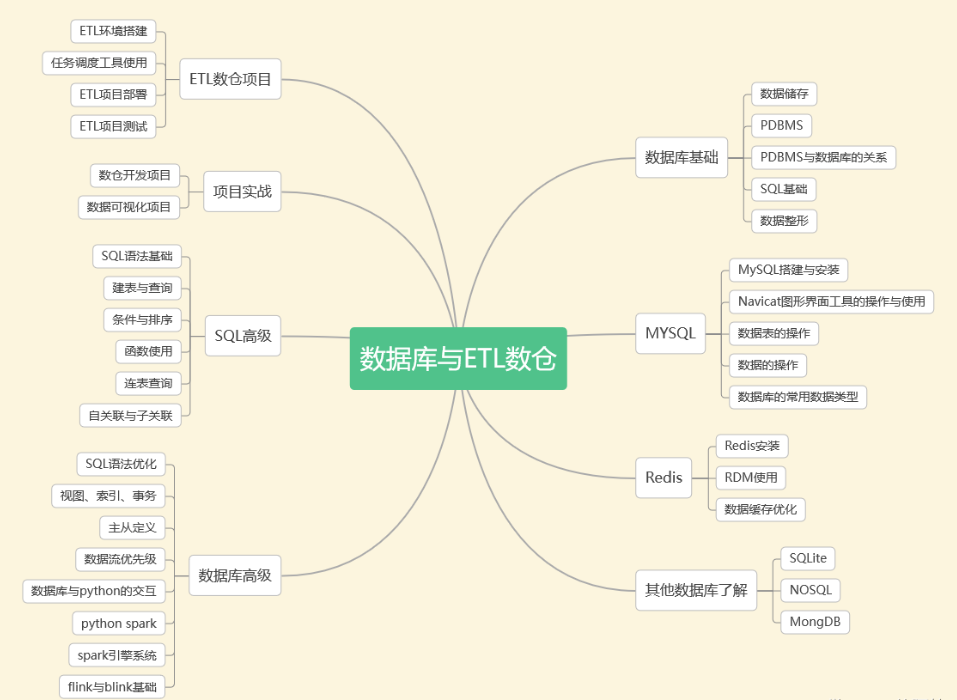
五、机器学习
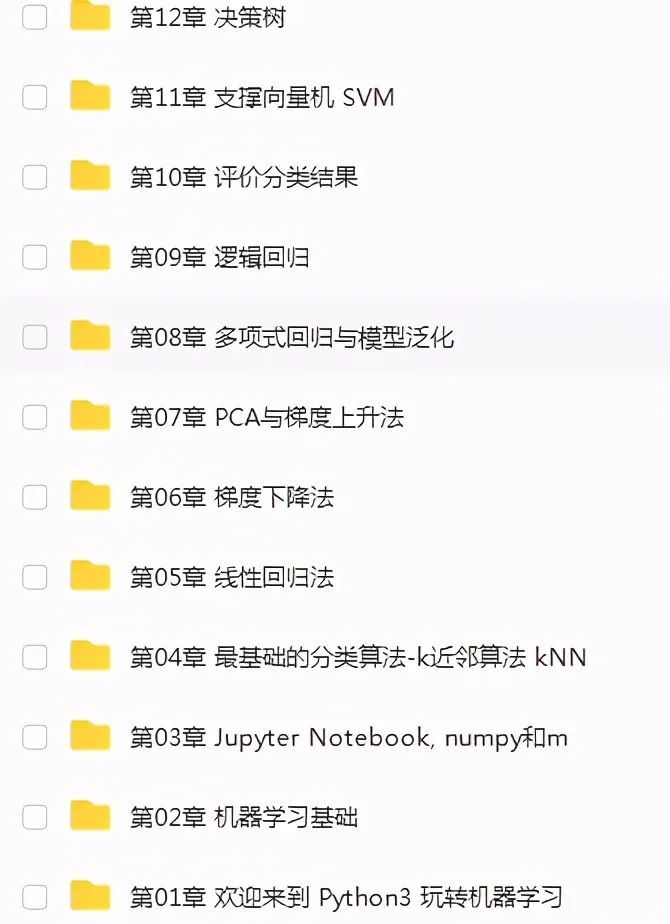
机器学习就是对计算机一部分数据进行学习,然后对另外一些数据进行预测与判断。
机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出决定或预测”。也就是说计算机利用以获取的数据得出某一模型,然后利用此模型进行预测的一种方法,这个过程跟人的学习过程有些类似,比如人获取一定的经验,可以对新问题进行预测。

机器学习资料:
六、Python高级进阶
从基础的语法内容,到非常多深入的进阶知识点,了解编程语言设计,学完这里基本就了解了python入门到进阶的所有的知识点。

到这就基本就可以达到企业的用人要求了,如果大家还不知道去去哪找面试资料和简历模板,我这里也为大家整理了一份,真的可以说是保姆及的系统学习路线了。
但学习编程并不是一蹴而就,而是需要长期的坚持和训练。整理这份学习路线,是希望和大家共同进步,我自己也能去回顾一些技术点。不管是编程新手,还是需要进阶的有一定经验的程序员,我相信都可以从中有所收获。
一蹴而就,而是需要长期的坚持和训练。整理这份学习路线,是希望和大家共同进步,我自己也能去回顾一些技术点。不管是编程新手,还是需要进阶的有一定经验的程序员,我相信都可以从中有所收获。
资料领取
上述这份完整版的Python全套学习资料已经上传网盘,朋友们如果需要可以微信扫描下方二维码输入“领取资料” 即可自动领取
或者
【点此链接】领取


