
- 1软件工程填空题_具有较明显的输入部分和变换(或称主加工)部分之间的界面、变换部分和输出部分之间
- 2使用阿里巴巴同步工具DataX实现Mysql与ElasticSearch数据同步_mysql数据同步到elasticsearch工具 阿里巴巴
- 3RichEditor——一款基于RecyclerView实现的富文本编辑器实现方案(支持图文、转义生成MarkDown、粗体、斜体、下划线、删除线、超链接、标题...
- 4网络编程--socket_socket(af_inet,sock_stream,0)
- 5C/C++获取cpu的id和名字_c获取设备id
- 6JS中的File, FileReader, Blob, ArrayBuffer, TypedArray, DataView, URL用法_bolb转dataview
- 7云原生 - Kubernetes基础知识学习
- 8mixamo骨骼_[蛮牛教程]不用建模软件,给心仪的模型绑骨骼!
- 9winsock recv函数使用注意
- 10c#验证参数sql注入和防止xxs脚本攻击_c# 正则判断,杜绝sql注入xss攻击
生成式对抗网络GAN研究进展(五)——Deep Convolutional Generative Adversarial Nerworks,DCGAN_context of images是什么意思
赞
踩
【前言】
本文首先介绍生成式模型,然后着重梳理生成式模型(Generative Models)中生成对抗网络(Generative Adversarial Network)的研究与发展。作者按照GAN主干论文、GAN应用性论文、GAN相关论文分类整理了45篇近两年的论文,着重梳理了主干论文之间的联系与区别,揭示生成式对抗网络的研究脉络。
本文涉及的论文有:
- Goodfellow Ian, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in Neural Information Processing Systems. 2014: 2672-2680.
- Denton E L, Chintala S, Fergus R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks[C]//Advances in neural information processing systems. 2015: 1486-1494.
- Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv preprint arXiv:1511.06434, 2015.
5. 深度卷积生成式对抗网络,Deep Convolutional Generative Adversarial Nerworks
5.1 DCGAN的思想
DCGAN[1]这篇论文的提出看似并没有很大创新,但其实它的开源代码现在被使用和借鉴的频率最高。这一切必须归功于这篇工作中比 LAPGAN [2]更 robust 的工程经验分享。也就是说,DCGAN,Deep Convolutional Generative Adversarial Networks,这个工作[1],指出了许多对于GAN这种不稳定学习方式重要的架构设计和针对CNN这种网络的特定经验。重点来看:
比如他们提出既然之前已经被提出的strided convolutional networks 可以从理论上实现和有pooling的 CNN一样的功能和效果,那么strided convolutional networks作为一个可以 fully differentiable的generator G,在GAN中会表现得更加可控和稳定。
又比如,本来 Facebook的LAPGAN中指出Batch Normalization(BN)被用在 GAN 中的D上会导致整个学习的collapse ,但是DCGAN中则成功将 BN 用在了 G 和 D 上。这些工程性的突破无疑是更多人选择DCGAN 这一工作作为 base 的重要原因。
另一方面,他们在 visualize generative models 也有许多贡献。比如他们学习了 ICLR 2016 论文《Generating Sentences From a Continuous Space》中的 interpolate space 的方式,将生成图片中的 hidden states 都 show 了出来,可以看出图像逐渐演变的过程。
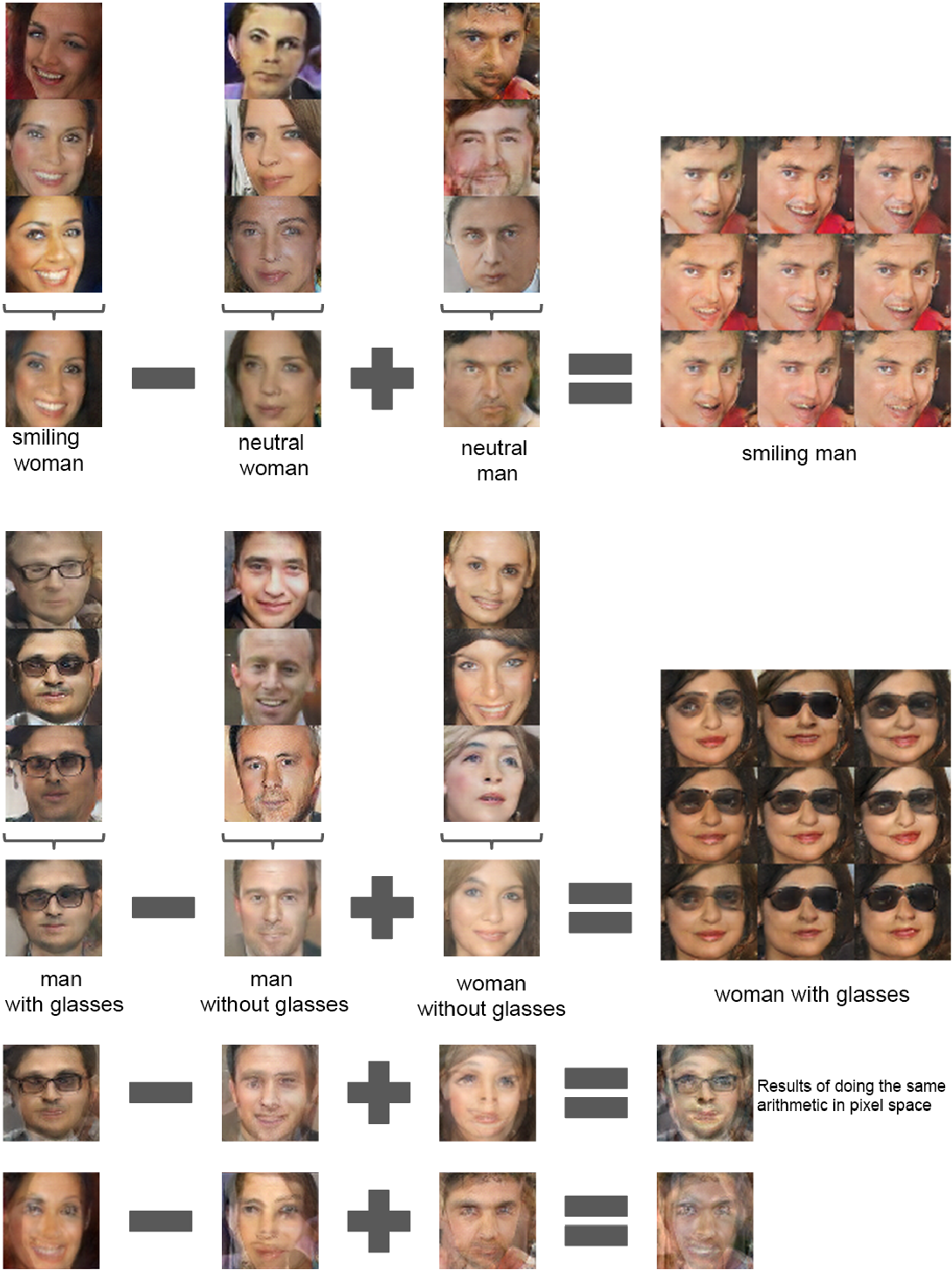
与此同时,他们也讲 Vector Arithmetic 运用在了图像上,得到了如下的一些结果:
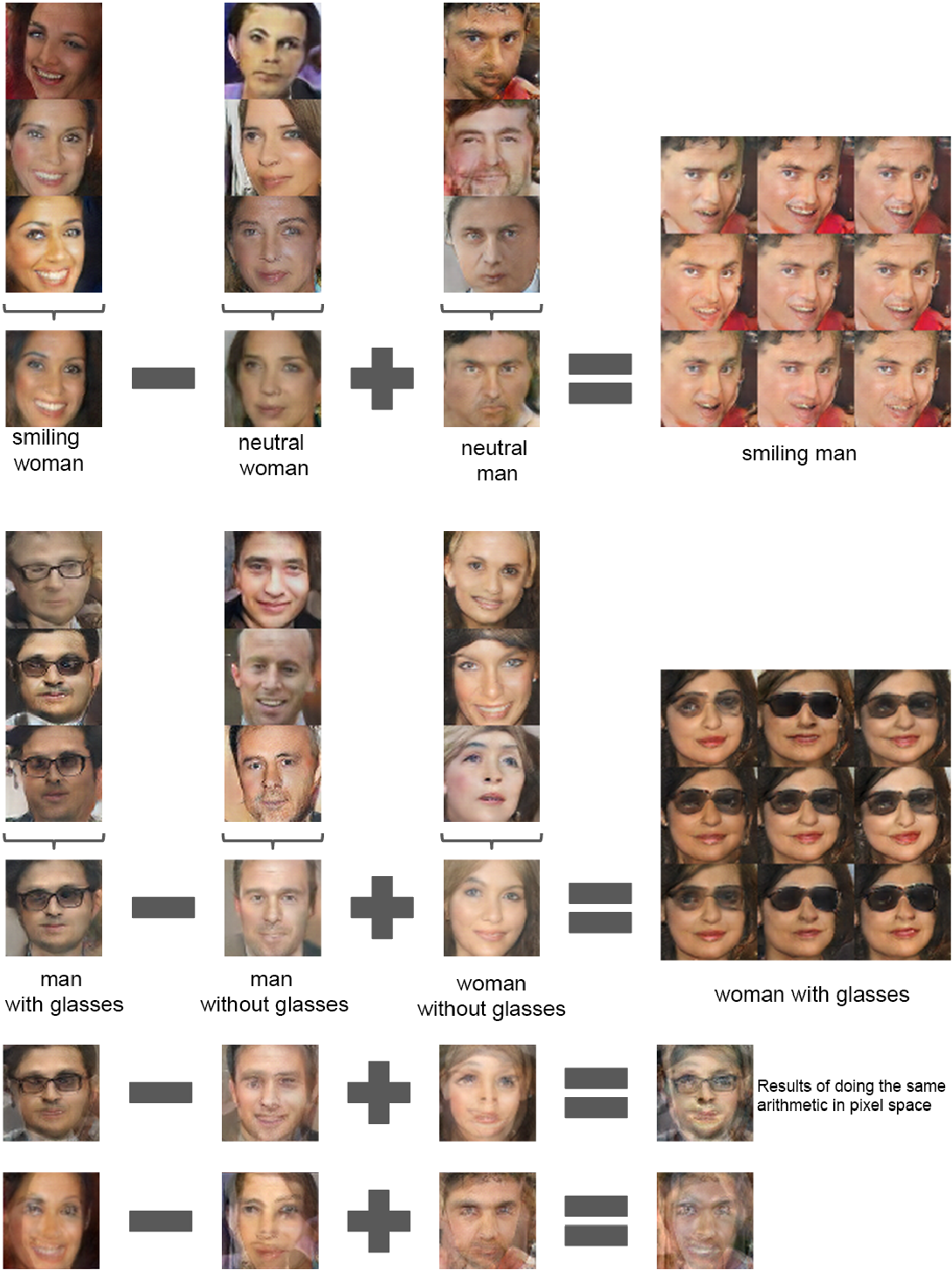
5.2 UNSUPERVISED R EPRESENTATION L EARNING WITH D EEP C ONVOLUTIONAL GENERATIVE A DVERSARIAL N ETWORKS
5.2.1 Introduction
相较有监督学习,CNN在无监督学习上的进展缓慢。本文结合CNN在有监督学习的成功和无监督学习,提出一类被称为“深度卷积生成对抗网络(DCGANs)”使用生成模型和判别模型,从物体物件到场景图像,学习到一种层次的表征。最后,使用学习到的特征实现新任务——阐明它们可以用于生成图像的表征。
无监督地学习表征,用于有监督学习。
通过GAN构建表征,然后重用部分生成模型、判别模型作为有监督学习的特征提取器。
GAN是“最大似然方法”的一个有吸引力的替代方法。
对于表征学习,无需启发式损失函数是有吸引力的。
GAN有一个通病:训练过程的unstable : 经常导致生成器产出无意义的输出。目前在试图理解和可视化GANs学到什么以及多层GANs的中间层标准方面研究非常有限。
这篇文章主要贡献:
- 我们提出和评估了一系列卷积GANs在结构拓扑方面约束条件,让其更加稳定。我们将其命名为深度卷积生成式对抗网络Deep Convolutional GANs
- 使用训练好的判别模型用于图像分类,和其他无监督方法的结果具有可比较性。
- 可视化了卷积核
- 生成模型具有向量算是运算性能
5.2.2 RELATED WORK
Representation Learning from Unlabeled Data
无监督表征学习是一个CV领域中相当好的研究问题
经典的无监督表征学习方法:聚类分析;利用聚类的簇改善分类性能
In the context of images
- Do hierarchical clustering of image patches (Coates & Ng, 2012) to learn powerful image representations.
- Train auto-encoders (convolutionally, stacked (Vincent et al., 2010), separating the what and where components of the code (Zhao et al., 2015), ladder structures (Rasmus et al., 2015)) that encode an image into a compact code, and decode the code to reconstruct the image as accurately as possible.
- Deep belief networks (Lee et al., 2009) have also been shown to work well in learning hierarchical representations.
Generating natural images
分为参数生成模型 和 非参生成模型
Non-parametric models
The non-parametric models often do matching from a database of existing images, often matching patches of images.
Parametric models
A variational sampling approach to generating images (Kingma & Welling, 2013)
Another approach generates images using an iterative forward diffusion process(Sohl-Dickstein et al., 2015)
Generative Adversarial Networks (Goodfellow et al., 2014) generated images suffering from being noisy and incomprehensible.
A laplacian pyramid extension to this approach (Denton et al., 2015) showed higher quality images, but they still suffered from the objects looking wobbly because of noise introduced in chaining multiple models.
A recurrent network approach (Gregor et al., 2015) and a deconvolution network approach (Dosovitskiy et al., 2014) have also recently had some success with generating natural images, not leveraged the generators for supervised tasks
5.2.3 DCGAN网络模型
历史上使用CNN扩展GANs模型不是很成功(这里的“扩展”含义是什么?原始的GAN和LAPGAN都有用卷积网络作为生成模型/判别模型?)
这驱使LAPGAN[2]的作者开发一种替代方法:迭代地升级低分辨率图像
Attempting to scale GANs using CNN architectures commonly used in the supervised literature
试图使用文献中提及的通常用于有监督学习的CNN架构扩展GANs时遇到了困难。最终找到了一类结构,可以在多种数据集上稳定地训练,并且产生更高分辨率的图像:深度卷积生成网络(DCGAN)。
Core to our approach is adopting and modifying three recently demonstrated changes to CNN architectures.
方法的核心:采用、修改了三种最近CNN结构的改进:
All convolutional net (Springenberg et al., 2014) 全卷积网络
- 判别模型:使用带步长的卷积(strided convolutions)取代了的空间池化(spatial pooling),容许网络学习自己的空间下采样(spatial downsampling)。
- 生成模型:使用微步幅卷积(fractional strided),容许它学习自己的空间上采样(spatial upsampling)。
在卷积特征之上消除全连接层
- e.g. Global average pooling which has been utilized in state of the
art image classification models (Mordvintsev et al.). - 全局平均pooling有助于模型的稳定性,但损害收敛速度
输入:服从均匀分布的噪声向量,100维;
输出:并输出一个64x64x3 的RGB图像。 - 激活函数:
生成模型:输出层用Tanh函数,其它层用ReLU激活函数。
判别模型:所有层使用LeakyReLU
Batch Normalization 批标准化
解决因糟糕的初始化引起的训练问题,使得梯度能传播更深层次。
Batch Normalization证明了生成模型初始化的重要性,避免生成模型崩溃:生成的所有样本都在一个点上(样本相同),这是训练GANs经常遇到的失败现象。
This proved critical to get deep generators to begin learning, preventing the generator from collapsing all samples to a single point which is a common failure mode observed in GANs.
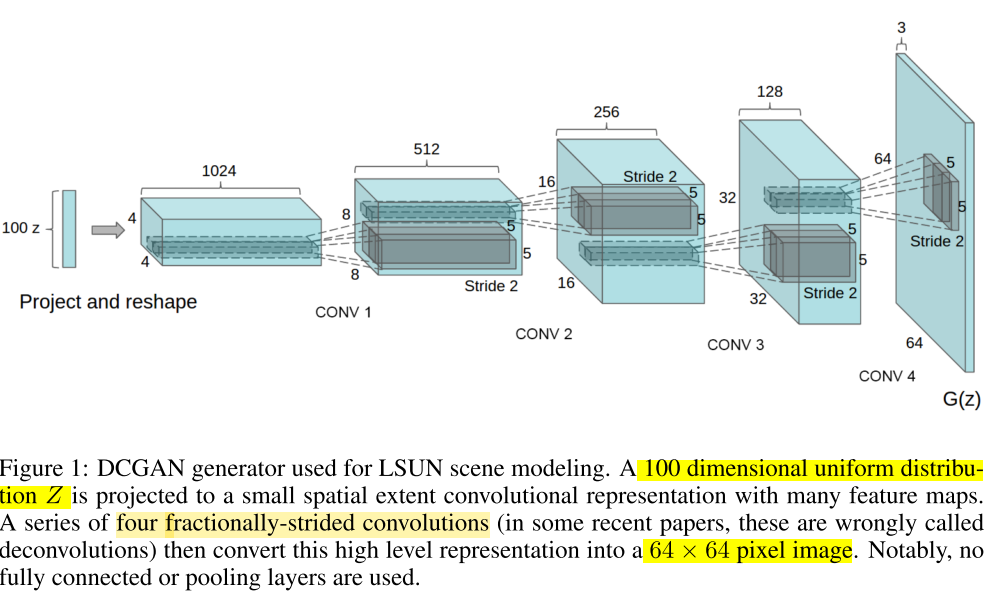
100维的噪声被投影到一个小空间幅度的卷积表征中。有四个微步幅卷积(在一些论文中,它们被误称为反卷积deconvolutions),然后将这些高层表征转换到64 * 64像素的RGB三通道图片。没有全连接层,没有池化层。
原文对DCGAN的网络结构介绍的不是很清楚,Semantic Image Inpainting with Perceptual and
Contextual Losses这篇文章使用了DCGAN进行图像修复,对网络结构和参数介绍的比较清楚(图中判别网络D的各层卷积操作的通道数应该和生成网络G一样,但是图中是不同的,怀疑是不是判别网络D的通道数(卷积核数目)画错了?)。如下图所示:
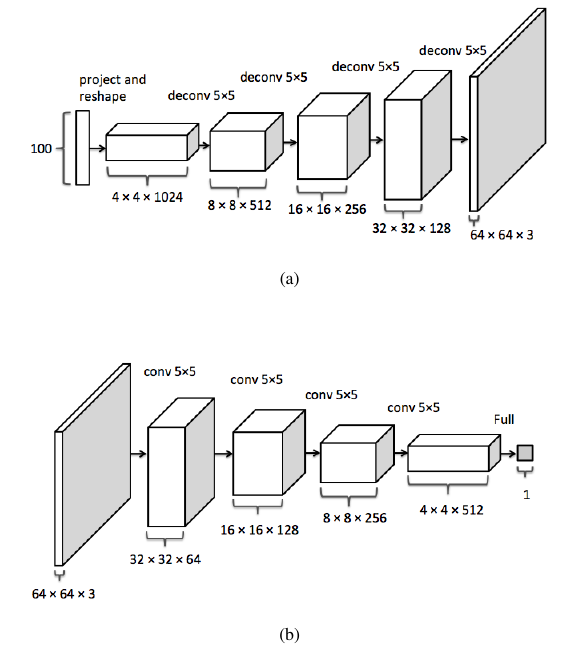
上图a是生成模型G:输入(100 维噪声向量Z)到第一个层:全连接 100 —> 1024,然后再把1024的一维向量reshape成1024个通道的4*4的feature map。基本规律是生成网络的每一个下一层是反卷积层,通道数减半,图像尺寸加倍。
下图b判别模型D:就是一个没有pooling的全卷积网络,输出是一个标量,表示输入数据属于训练数据而非生成样本的概率。
5.3 实验
在LSUN卧室数据集上训练DCGAN,生成的图像非常逼真:

We demonstrate that an unsupervised DCGAN trained on a large image dataset can also learn a hierarchy of features that are interesting.
Using guided backpropagation as proposed by (Springenberg et al., 2014), we show in Fig.5 that the features learnt by the discriminator activate on typical parts of a bedroom, like beds and windows.

Vector arithmetic for visual concepts
Reference
[1] Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv preprint arXiv:1511.06434, 2015.
[2] Denton E L, Chintala S, Fergus R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks[C]//Advances in neural information processing systems. 2015: 1486-1494.

