- 1一文了解AIGC与ChatGPT_aigc和open ai
- 2Windows预览体验计划空白等一些问题的解决办法_此电子邮件地址未注册为 windows 预览体验成员
- 3CVPR2022 ReID方向接收论文_augmented geometric distillation for data-free inc
- 4phpStudy点击phpadmin出404窗口的解决办法_phpstudy pro的phpadmin进不去
- 5mysql和redis常见面试题_redis相关面试题
- 6Mybatis-plus 动态条件查询QueryWrapper的使用
- 72024~LLM发展方向
- 8ELF文件解析和加载(附代码)_elf头文件解析
- 9SpringBoot的缓存管理_springboot 缓存
- 10Spring+SpringMVC+Mybatis+redislayui做无限级左侧导航。_左侧导航如何无限层级
基于python的外卖数据分析-计算机毕业设计源码+LW文档_从计算机角度解释外卖
赞
踩
一、 选题的背景与意义
(一)课题研究来源
拙笔所值新世纪第二个十年的尾声,距离上世纪九十年代以TCP/IP协议的数据传输过程为基础的互联网信息技术的崛起的时间点己经经过了三十年的时间,距离上世纪六十年代互联技术问世的时间点己经有六十年。时至今日,随着移动终端(如手机、平板电脑等便携式微型数据处理计算机)技术的成熟以及其以日渐平民化的价格、趋同的处理速度、优秀的功能集成度等优势逐渐代替pc端的硬件产业革命,互联网技术可以说在新世纪第二个十年达到了前所未有的普及广度。这种普及广度无涉于用户的性别、年龄、职业、国别等非功能性因素,甚至在听觉或视觉功能上有一定缺陷的病患者也几乎全部加入至互联网用户的大军之中。据2018年12月1日调查显示,我国己有至少8.02亿网民,互联网普及率为57.7%,其普及程度可见一般。同时,互联网技术对人类社会的渗透深度也同等强大。借力于物联网工程的基础设施建设、高集成化的智能电子芯片以及云计算技术的成熟,人类社会的具体目的性行为几乎无法远离互联网技术。如定位导航系统之于出行;电子商务平台之于购物;社交软件之于沟通,其凭借强大的功能与传播力使得人类社会对其依赖度越来越高,甚至可以说是不可或缺的程度。
(二)课题研究的目的
随着信息时代的发展和编程技术的普及,搜索引擎成为了使用互联网的常用工具。搜索引擎大多使用爬虫技术作为核心模块,通过关键词返回用户查询的结果。但是网络信息呈现爆炸式的增长,使得信息的查找和定位也变得困难。为解决上述困境,研究借助Python语言。它是为了编写自动化脚本(shell)而设计的胶水语言,是面向对象的动态类型语言。Python语言经过不断地改进及增加新功能,慢慢地被很多独立的、复杂的软件系统用于开发。Python作为一门程序设计语言被越来越多的人所喜爱。
(三)课题研究的意义
本论文实现的基本方式为:以开源的Python语言系统为基础利用,同时借鉴、粘连其他编程语言的抽象构建方式,从而构建一个实现能力强大的Web crawler系统程序,同时保障其具有较强的拓展性。
本次课题所构建Web crawler系统程序所针对、解决的现实问题不仅仅局限于本次课题的问题领域,也就是说,本次课题所构建Web crawler系统程序可以嫁接于其他种类的网站信息提取捕获类系统,进而实现多种多样的抓取功能,也会在一定程度上对网络用户自身利用或者今后的语言编程开发人员的开发、研究提供具有一定程度利用价值的素材。
(四)研究现状
(1)互联网技术的普及
时至今日,随着移动终端(如手机、平板电脑等便携式微型数据处理计算机)技术的成熟以及其以日渐平民化的价格、趋同的处理速度、优秀的功能集成度等优势逐渐代替pc端的硬件产业革命,互联网技术可以说在新世纪第二个十年达到了前所未有的普及广度。这种普及广度无涉于用户的性别、年龄、职业、国别等非功能性因素,甚至在听觉或视觉功能上有一定缺陷的病患者也几乎全部加入至互联网用户的大军之中。据2018年12月1日调查显示,我国己有至少8.02亿网民,互联网普及率为57.7%,其普及程度可见一般。同时,互联网技术对人类社会的渗透深度也同等强大。借力于物联网工程的基础设施建设、高集成化的智能电子芯片以及云计算技术的成熟,人类社会的具体目的性行为几乎无法远离互联网技术。如定位导航系统之于出行;电子商务平台之于购物;社交软件之于沟通,其凭借强大的功能与传播力使得人类社会对其依赖度越来越高,甚至可以说是不可或缺的程度。
(2)传统信息渠道的“萎靡”
相较于互联网技术的方兴未艾,传统信息获取渠道早已呈现出天壤之别的劣势,并且其稳定受众的数量仍在持续走低。据世界报业协会2018年趋势报告中指出,在过去的五年中,全球报纸总发行量每年平均减少900万份,以平均降幅为2%的速度逐年下降;同时,诸多国际知名杂志的运营商因长年被互联网挤压市场占有率而宣布破产(如美国的“阁楼")。尤其对于年龄在18-45岁之间的年轻受众群体而言,几乎已经不再选择报纸、杂志、广播等传统信息渠道获取信息来指导日常生活,他们无时无刻不生活在网络之中。
二、 课题研究内容及创新
首先,若要实现本课题所指向的系统结构并达到预期效果,认知、熟悉乃至.于在某一方面精通Python语言体系是非常必要的。同时,就开源库来讲,本课题将高频的利用SCRAPY结构作为本课题系统结构的框架。
本次课题的实现是研究者本身亲力亲为的构建、编写Web crawler原始构成框架,这个过程中将有助于前沿网络程序编写能力的提高,并且将自身对网络技术与目的搭载实现方式进行全面、系统的升级。其次,本次课题所构建Webcrawler系统程序所针对、解决的现实问题不仅仅局限于本次课题的问题领域,也就是说,本次课题所构建Webcrawler系统程序可以嫁接于其他种类的网站信息提取捕获类系统,进而实现多种多样的抓取功能,也会在一定程度上对网络用户自身利用或者今后的语言编程开发人员的开发、研究提供具有一定程度利用价值的素材。
数据收集
收集外卖平台的订单数据,包括订单编号、下单时间、商家名称、商品名称、商品数量、商品单价、收货地址、支付方式、订单状态等信息。
数据清洗
对收集到的数据进行清洗,包括去重、缺失值处理、异常值处理等,保证数据的准确性和完整性。
数据探索
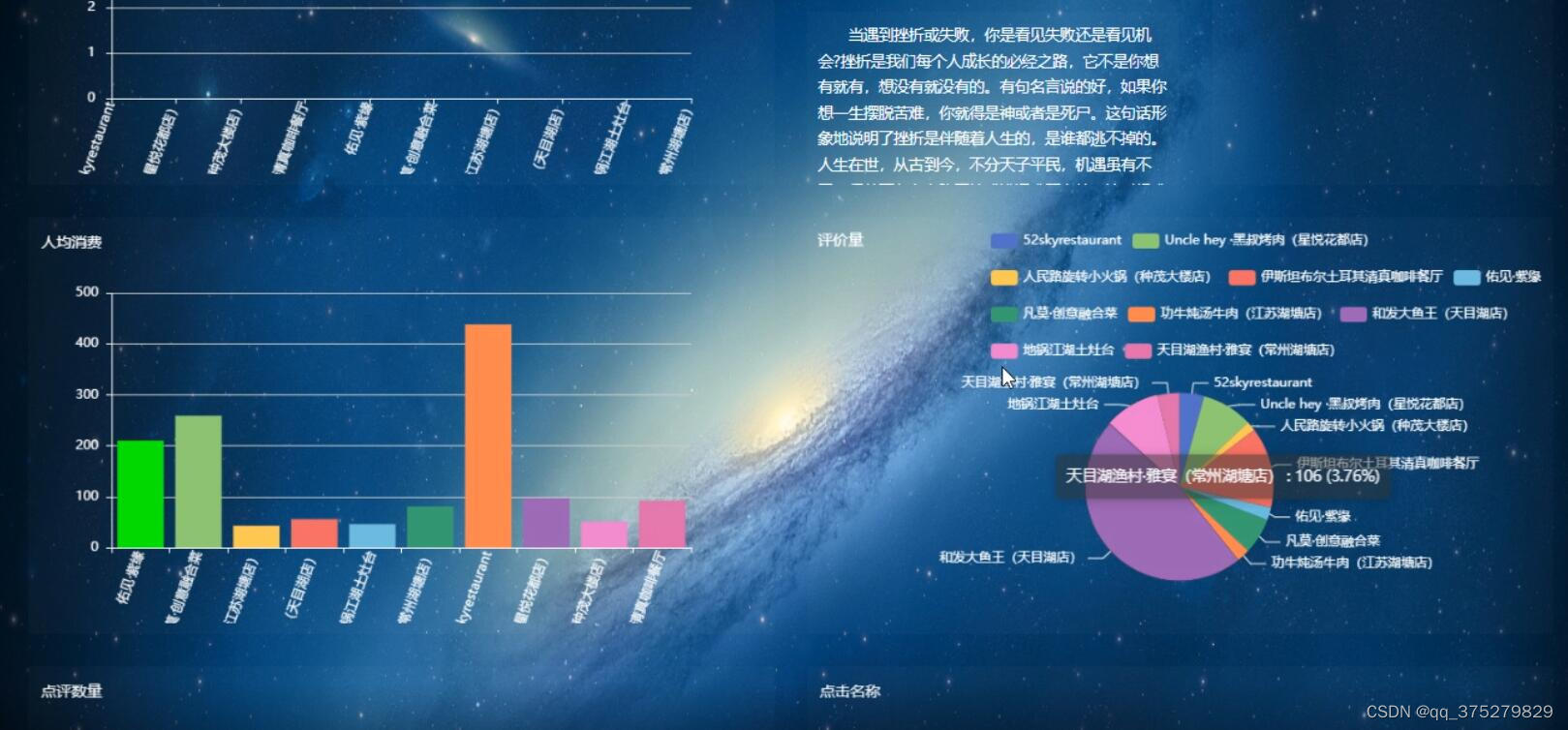
通过可视化工具对数据进行探索,包括订单量、销售额、商品销量、商家评分等指标的分析,找出数据中的规律和问题。
数据建模
利用机器学习算法对数据进行建模,预测销售额、商品销量、商家评分等指标,并优化外卖平台的运营策略。
和客户主要沟通内容:爬取网站不限定。
数据展示
将分析结果以可视化的形式展示出来,包括折线图、柱状图、饼状图等,使得数据结果更加直观和易于理解。
总结
通过外卖数据分析,可以帮助外卖平台了解用户需求,优化运营策略,提高用户体验和
平台收益。
三、 课题的研究方法:
(1)文献研究法
在正式开始撰写论文之前搜集整理大量文献资料,包括各类学术著作、期刊论文和相关媒体报道,在全面了解前人研究成果的基础上确定研究课题,理清研究思路。
本论文实现的基本方法为:以开源的Python语言系统为基础利用,同时借鉴、粘连其他编程语言的抽象构建方式,从而构建一个实现能力强大的Web crawler系统程序,同时保障其具有较强的拓展性。
四、 研究计划及预期成果:
第一阶段:2023.xx——2023.xx 阅读相关的文献,制定论文的研究计划和方案,收集资料;
第二阶段:2023.xx——2023.xx 拟定开题报告,构思论文框架,提交指导老师审批;
第三阶段:2023.xx——2023.xx 起草论文初稿,润色修改,提交指导老师初审;
第四阶段:2023.xx——2023.xx 根据指导老师意见,修改初稿;
第五阶段:2023.xx——2023.xx 基本定稿,编写论文答辩提纲;
第六阶段:2023.xx 以最佳状态参加答辩,完成答辩。
五、 参考文献:
[1]曹忠,赵文静、一种优化的网络爬虫的设计与实现[J].电脑知识与技术,
2008(35):2082-2083.
[2]胡岘.基于Unity桌面环境的搜索引擎设计与实现[D]国防科技大学,
2013:167-1 69.
[3]徐晓琳.主题搜索引擎中网络爬虫的搜索策略研究[J].数字化用
户,2013(23):4-4.
[4]吕俊宏,周江峰.深入解析Cookie技术[J]数字通信世界,2015(6):332-333.
[5]王凤红、简单分布式网络爬虫模型的设计与分析[J].中国现代教育装备,
2008(4):76-78.
[6]Menell PS.Google,PageRank,and Symbiotic Technological Change[J]UC
Berkeley Public Law Research Paper,2012:19-20.
[7]Rogers I.The Google Pagerank algorithm and how it works[J]2012:2-3.
[8]陈丽.Google搜索引擎架构研究[J]中国科技纵横,2013(2):56-56.
[9]许剑颖.搜索引擎发展趋势研究[J].现代情报,2011(1):51-55.
[10]何震苇,邹若晨钟伟彬,钟伟彬[J].中国经济和信息化,2004(24):49-50.